Jmeter元件 CSV Data Set Config详解
文章目录
- 一、元件作用
- 二、核心参数详解
- 1.参数解释
- 2.数据共享模式介绍
- 详细解析
- 2.1 All threads模式
- 2.2 Current thread group模式
- 2.3 Current thread模式
- 三、使用实例
- 1.创建 CSV文件,编码保存为UTF-8:
- 2.添加CSV配置元件,从CSV读取测试数据
- 3. 通过CSV配置元件设置的变量名在请求中引用测试数据
- 四、csv 编码介绍
- 1.使用 Excel 保存为 UTF-8 CSV
- 2.使用 Notepad++ 直接创建 UTF-8 CSV
- 五、高级使用技巧
- 1.跳过表头
- 2.处理包含逗号的数据
- 3.动态文件名
- 六、常见问题
- 六、最佳实践
一、元件作用
CSV Data Set Config 允许你:
- 从 CSV 文件读取测试数据(如用户名、密码、ID 等)
- 实现参数化测试,避免硬编码
- 支持多线程并发读取
- 适用于批量数据验证、性能测试等场景
二、核心参数详解
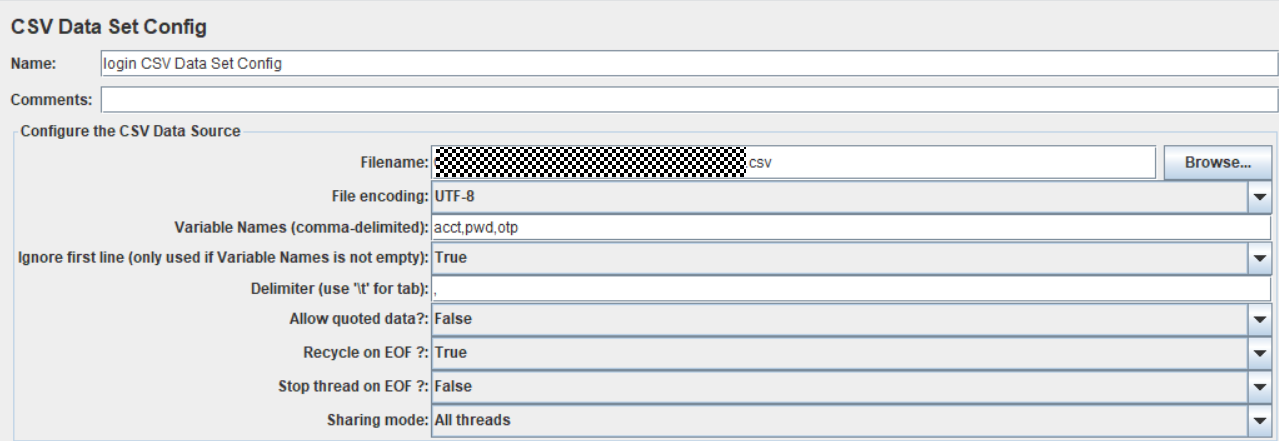
1.参数解释
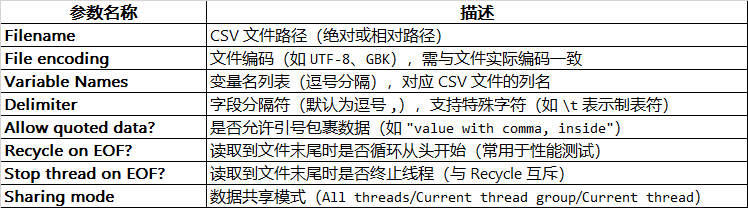
2.数据共享模式介绍
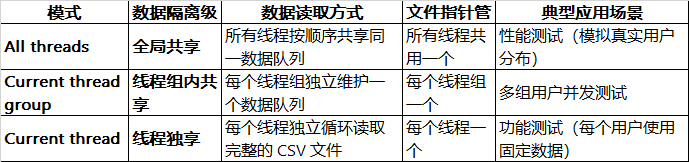
详细解析
假设CSV文件内容如下:
CSV:
user1,pass1
user2,pass2
user3,pass3
user4,pass4
user5,pass5
并配置 2 个线程组(TG1 和 TG2),每个线程组 2 个线程(共 4 个线程)。
2.1 All threads模式
所有线程共享同一数据队列,按顺序循环读取,确保全局数据不重复(适合模拟大量不同用户)
执行顺序:
线程1 (TG1-1) → user1
线程2 (TG1-2) → user2
线程3 (TG2-1) → user3
线程4 (TG2-2) → user4
线程1 (TG1-1) → user5
线程2 (TG1-2) → user1 (循环)
...
2.2 Current thread group模式
每个线程组独立维护数据队列,组内线程按顺序读取,适合多组不同类型用户的并发测试(如管理员组、普通用户组)
# 线程组1
线程1 (TG1-1) → user1
线程2 (TG1-2) → user2
线程1 (TG1-1) → user3
线程2 (TG1-2) → user4
线程1 (TG1-1) → user5
线程2 (TG1-2) → user1 (循环)# 线程组2
线程3 (TG2-1) → user1
线程4 (TG2-2) → user2
线程3 (TG2-1) → user3
...
2.3 Current thread模式
每个线程独立读取完整的 CSV 文件,每个线程使用相同的数据序列(可能导致数据重复)适合功能测试,确保每个线程使用固定的测试数据
线程1 (TG1-1) → user1 → user2 → user3 → user4 → user5 → user1 → ...
线程2 (TG1-2) → user1 → user2 → user3 → user4 → user5 → user1 → ...
线程3 (TG2-1) → user1 → user2 → user3 → user4 → user5 → user1 → ...
线程4 (TG2-2) → user1 → user2 → user3 → user4 → user5 → user1 → ...
三、使用实例
1.创建 CSV文件,编码保存为UTF-8:
2.添加CSV配置元件,从CSV读取测试数据
3. 通过CSV配置元件设置的变量名在请求中引用测试数据
四、csv 编码介绍
在 JMeter 中使用 CSV 文件时,确保文件编码为 UTF-8 至关重要,否则可能导致中文或特殊字符乱码。
1.使用 Excel 保存为 UTF-8 CSV
Excel 默认保存的 CSV 可能是 ANSI 或其他编码,需通过以下步骤转为 UTF-8:
1.另存为 CSV:
- 打开 Excel 文件 → 文件 → 另存为
- 选择 CSV (逗号分隔)(*.csv) 格式
- 点击 保存
2.编码转换:
- 使用文本编辑器(如 Notepad++)打开保存的 CSV 文件
- 编码 → 转为 UTF-8 无 BOM 格式
- 文件 → 保存
UTF-8编码:是一种多字节编码,支持全球范围内的几乎所有字符,是目前最常用的编码格式之一。在 UTF-8 编码中,英文字符占用 1 个字节,而其他字符可能占用 2 到 4 个字节,通常中文字符占用 3 个字节。Notepad++ 保存 UTF-8 编码文件时,默认会添加一个 3 字节的 BOM(字节顺序标记),用于标识文件的编码格式,但这可能会在某些情况下导致问题,比如在一些网络应用或特定的文本处理场景中。因此,Notepad++ 也提供了 “UTF-8 无 BOM” 的选项,即保存文件时不添加 BOM,这样可以节省 3 个字节的空间,但会使编码检测变得困难一些。
ANSI:严格来说,ANSI 并不是一种具体的编码,而是一系列本地化编码的统称。在 Windows 系统中,ANSI 编码通常对应着系统的默认本地编码,比如在中国通常是 GBK 编码。ANSI 编码适用于英文和部分欧洲语言,它是单字节编码,文件大小相对较小,但不支持其他语言的字符,处理非英文文本时可能会出现乱码。
2.使用 Notepad++ 直接创建 UTF-8 CSV
1.新建文件:
- 打开 Notepad++ → 文件 → 新建
2.设置编码:
- 编码 → UTF-8 无 BOM 格式
3.编辑内容:
- 按 CSV 格式输入内容,用逗号分隔字段
4.保存文件:
- 文件 → 保存 → 文件名 .csv → 保存类型: 所有文件
五、高级使用技巧
1.跳过表头
若 CSV 文件包含表头,可通过以下方式跳过:
- 在 CSV 文件首行添加注释符号(如 #)
- 使用 Ignore first line 选项(JMeter 5.0+ 支持)
2.处理包含逗号的数据
若数据中包含逗号,用双引号包裹,并设置 Allow quoted data 为true
csv
id,name,desc
1,John,“Engineer, Developer”
2,Alice,“Manager, Leader”
3.动态文件名
使用变量指定文件名:
<stringProp name="filename">${__property(dataDir)}/users.csv</stringProp>
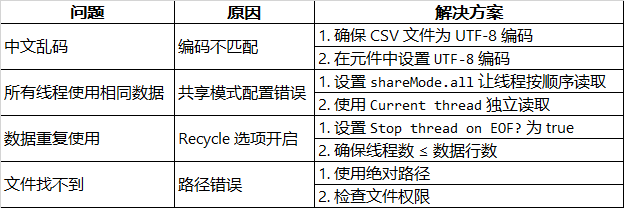
六、常见问题
六、最佳实践
1.文件组织:将 CSV 文件与 JMX 测试计划放在同一目录,使用相对路径
2.编码统一:始终使用 UTF-8 编码,避免中文乱码
3.数据隔离:
- 性能测试:使用 All threads 模式,确保数据不重复
- 功能测试:使用Current thread 模式,保证每个线程使用独立数据
4.调试方法:
- 添加 Debug Sampler 查看变量值
- 使用 View Results Tree 验证请求参数