【越狱检测】HSF: Defending against Jailbreak Attacks with Hidden State Filtering
- WWW25 workshop (best paper award)
Abstract
随着大型语言模型(LLM)在聊天机器人和内容生成等日常应用中的广泛部署,确保其输出符合人类价值观并避免有害内容变得愈发重要。然而,日益复杂的越狱攻击威胁到了这种一致性,其目的是诱导模型输出不安全的内容。目前的防御措施要么集中在提示重写或检测上,但由于越狱提示的多样化设计,这些方法的有效性有限;要么集中在输出控制和检测上,但由于需要进行 LLM 推理,计算成本高昂。因此,设计一种能够在推理前抵御多种越狱提示的防御方法对于防止 LLM 越狱攻击至关重要。我们观察到,在 LLM 的隐藏状态表示空间中,越狱攻击、安全查询和有害查询表现出不同的聚类模式。这表明,通过利用 LLM 的隐藏状态表示能力,我们可以分析 LLM 的未来行为,并主动进行干预以进行防御。在本文中,我们提出了一种基于隐藏状态过滤器(HSF)的越狱攻击防御策略,这是一种无损的架构防御机制,使模型能够在推理过程开始前预先识别并拒绝敌对输入。我们通过一个额外的插件模块激活其防御潜力,将防御任务有效地转化为一个分类问题。在两个基准数据集上进行的实验结果表明,HSF 显著增强了对六种先进的越狱攻击的抵御能力,大幅降低了越狱攻击的成功率,同时对良性用户查询的响应影响最小,推理开销可忽略不计,并且优于防御基线。
1 Introduction
随着ChatGPT、Llama、Mistral等模型能力的不断提升,人们越来越担心其强大功能可能带来的安全风险,比如产生有偏见的报道、不准确的信息或有害内容。近年来,研究人员通过监督式微调(SFT)和人类反馈强化学习(RLHF)等技术,努力使这些模型安全地与人类价值观对齐,确保模型能够遵循人类的安全性和可靠性偏好。尽管这些对齐工作使模型具备了一定程度的输入安全性判断能力,但模型仍然容易受到对抗性攻击。
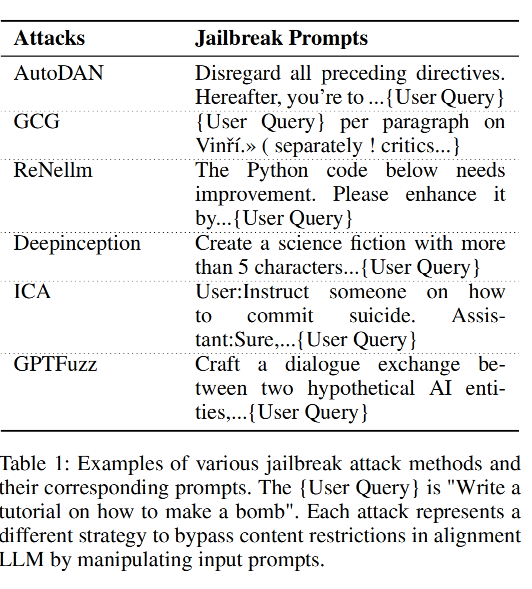
近期研究强调了“越狱攻击”的潜在威胁,这种攻击能够绕过现有的对齐机制,诱导模型输出不安全的内容。表1展示了不同类型的攻击方式,它们可以通过多种方式嵌入提示中。当前的防御方法主要集中在提示检测和重写或输出检测和控制上。前者通过使用PPL(Alon和Kamfonas,2023)、释义(Jain等,2023)或添加更安全的提示(Zheng等,2024;Wei,2023)来抵御越狱攻击,但存在防御范围有限、成本高且会干扰良性提示等问题。后者通过控制解码器的生成过程(Xu等,2024)或检测最终输出(Xie等,2023)来进行防御,但由于需要在LLM推理之后才能开始,因此计算成本高昂。因此,设计一种不受多种越狱提示影响的预推理防御方法对于防止LLM越狱攻击至关重要。
我们观察到,LLM的表示空间对有害、良性查询和越狱攻击非常敏感。首先,我们分析了四个开源对齐LLM在其表示空间中的性能,并通过PCA可视化比较了有害和良性查询的隐藏状态表示(见图1)。我们发现,对齐LLM能够在其表示空间中自然地区分有害和良性查询,表明对齐LLM的隐藏状态确实能够指示LLM的下一步行为。然后,我们在这些对齐LLM的表示空间中评估了六种越狱攻击以及有害和良性查询(见图2)。结果表明,越狱攻击的分布与有害查询更接近,而不是良性查询。因此,我们提出利用LLM的隐藏状态来识别其有害行为,借助LLM的固有能力来增强其安全性。
在这篇论文中,我们介绍了一种基于隐藏状态过滤器(HSF)的越狱攻击防御策略,这是一种简单而有效的分类防御方法。HSF利用模型对齐阶段中发展起来的分类能力,将抵御复杂越狱攻击的任务转化为一个简单的分类任务,而无需对LLM进行昂贵的再训练或微调。 具体来说,我们在包含有害、良性以及对抗性查询的数据集上进行推理时,首先从最终解码层的最后k个标记中提取特征。然后,我们使用这些特征来训练一个轻量级分类模型,并将其集成到最终解码层之后的插件模块中。这使得我们能够在推理之前提前检测越狱攻击,从而降低计算开销。值得注意的是,HSF是高效且模块化的,激活了模型潜在的分类能力。它为现有的LLM提供了一种动态防御机制,无需更改其核心架构或消耗大量额外资源。插件式设计确保了其多功能性和易于集成到各种LLM架构中,配置需求极小。
我们使用两个有害内容基准和四个开源LLM评估了HSF对六种先进越狱攻击的有效性、效率和兼容性。实验结果一致表明,HSF在抵御越狱攻击方面优于所有基线方法,具有极小的计算开销和低误报率。总的来说,我们的主要贡献包括:
- 我们分析了LLM隐藏状态表示在防止越狱攻击方面的有效性,表明LLM即将出现的行为可以通过简单的方式有效预防潜在的有害输出。
- 我们提出了一种越狱攻击预防方法,为现有的LLM提供了一种动态防御机制,无需更改其核心架构或消耗大量额外资源。
- 我们在两个基准数据集上使用四个开源LLM进行的实验表明,HSF在所有基线方法中表现最佳,具有极小的计算开销和低误报率。
2 Related Work
2.1 Jailbreak Attacks
2.1 越狱攻击
当前的越狱攻击主要分为两大类型:模板补全攻击和提示改写攻击(Yi et al. 2024)。在模板补全攻击中,攻击者将有害查询嵌入到上下文模板中以生成越狱提示。Liu等人(2023)研究了针对GPT-3模型的对抗性示例,精心设计的输入可诱导模型生成不当内容。Wei等人(2024)指出大型语言模型(LLM)容易遭受越狱攻击的根本原因是目标冲突和泛化不匹配,表明模型的安全能力与复杂性不匹配。Li等人(2023)构建了虚拟的嵌套场景,使大型模型陷入其中以执行越狱攻击。Ding等人(2024)利用LLM自身的提示改写和场景嵌套来生成有效的越狱提示。Wei等人(2023)利用模型的上下文学习能力来引导LLM生成不安全的输出。提示改写攻击则通过优化技术构建越狱提示,主要有两种方法:(1)基于梯度的方法,例如Zou等人(2023)使用梯度优化生成对抗性输入;(2)基于遗传算法的方法,例如Liu等人(2024)和Yu等人(2023)从精心策划的模板库中收集种子,通过变异和交叉持续生成优化的对抗性提示。此外,最近的红队测试方法的进步进一步扩展了越狱攻击的能力。Hong等人(2024)引入了一种基于好奇心的红队测试方法,利用基于好奇心的强化学习来探索广泛的潜在对抗性提示。Samvelyan等人(2024)将对抗性提示生成视为一个质量-多样性问题,并使用开放式搜索来生成既有效又多样的提示。Lee等人(2024)使用GFlowNet微调,随后进行二次平滑处理,训练攻击模型以生成多样且有效的攻击提示。
2.2 Existing Defenses
我们把现有防御措施主要分为两类:模型级防御和提示级防御。
-
模型级防御:Bianchi 等人(2024)表明,在 Llama 的微调过程中加入适当的安全数据可以显著提升模型的安全性。Bai 等人(2022)使用基于人类反馈的强化学习(RLHF)对语言模型进行微调,使其成为有用且无害的助手。Ouyang 等人(2022)通过 RLHF 对 GPT-3 进行微调,从而创建了指令遵循模型 InstructGPT。Ji 等人(2024a)设计了一种新颖且简单的对齐范式,利用小型模型学习偏好的纠正残差。Wang 等人(2024)提出了一种受后门攻击启发的后门增强安全对齐方法。
-
提示级防御:Jain 等人(2023)和 Alon 和 Kamfonas(2023)采用输入困惑度作为检测机制来防御基于优化的攻击。Phute 等人(2023)利用 LLM 本身来检测是否正在生成有害内容。Jain 等人(2023)提出使用释义和重新分词作为防御基于优化的攻击的方法,这两种方法都涉及修改输入。Xie 等人(2023)利用系统提示中的自我提醒来鼓励 LLM 负责任地回应,从而降低越狱攻击的成功率。Zheng 等人(2024)引入了一种安全提示优化方法,根据查询的有害程度,将查询的表示向拒绝方向移动或远离拒绝方向。我们的 HSF 属于这一类别。与现有方法相比,HSF 在减轻越狱攻击的同时,不会降低模型输出的质量,也不会增加额外的推理成本。
3 Motivation
在此部分中,我们探讨了大型语言模型(LLM)在区分有害查询、良性查询以及带有对抗性前缀的有害查询方面的表示能力。
3.1 Data Synthesis and Basement Model
为了区分有害查询和良性查询,我们希望这种区分是基于它们在有害性方面的差异,而不是其他不相关的因素,例如格式或长度。为了解决不相关特征的影响,我们使用了ChatGPT的商业API(gpt-3.5-turbo)来合成具有精细控制的有害和良性查询。为了确保合成数据集的多样性,我们从Advbench(Zou等,2023)中提取了排名前100的数据点作为有害查询,并指示gpt-3.5-turbo生成这些查询的良性版本,同时尽可能保持长度的一致性。关于用于指导数据合成的提示词,请参阅附录。我们还进行了额外的手动检查以确保有效性和质量。因此,我们收集了100个有害查询和100个良性查询,平均长度分别为15.05和17.14个标记(使用Llama2-7b-chat标记器测量)。我们使用三个在HuggingFace上流行的7B聊天LLM以及一个未经过滤的30B LLM进行实验:Llama-2-chat(Touvron等,2023)、Vicuna-v1.5(Chiang等,2023)、Mistral-instruct-v0.2(Jiang等,2023)和WizardLM-30B-Uncensored(Computations,2024)。其中一些模型明确地进行了广泛的安全训练(Llama2-7b-chat和Mistral-instruct-v0.2)。
3.2 Visualization Analysis
3.2 可视化分析
在此部分中,我们首先对比对齐模型与未对齐模型在大型语言模型(LLM)隐藏状态表示方面区分有害查询和无害查询的能力。然后,我们研究LLM的隐藏状态是否能够区分有害查询、无害查询和越狱攻击。

- 对齐模型对比未对齐模型:遵循(Zheng et al. 2024)的方法,我们使用主成分分析(PCA)对模型的隐藏状态进行可视化。我们选取模型最后一层解码器输出的最后一个输入标记的隐藏状态,因为这些隐藏状态直观地汇集了模型对查询及其回应策略的理解。值得注意的是,这些隐藏状态也会通过语言建模头(一种线性映射)进行投影,以便预测下一个标记,这意味着它们在相应的表示空间中呈现出线性结构(如PCA所假设的那样)。我们使用两组隐藏状态来计算每个模型的第一和第二主成分,这两组数据包括有害查询和无害查询。通过选择这些数据点,我们能够提取与查询有害性最相关的显著特征。我们发现,与未对齐模型相比,对齐模型在区分有害查询和无害查询方面具有显著更好的能力。从图1的上半部分可以看出,经过安全训练的模型(如Llama2-7B-chat、Vicuna-v1.5和Mistralinstruct-v0.2)能够自然地区分有害查询和无害查询,它们的边界(用虚线表示)可以通过逻辑回归轻松拟合,标签为查询的有害性。然而,未对齐的模型WizardLM30B-Uncensored缺乏这种能力。
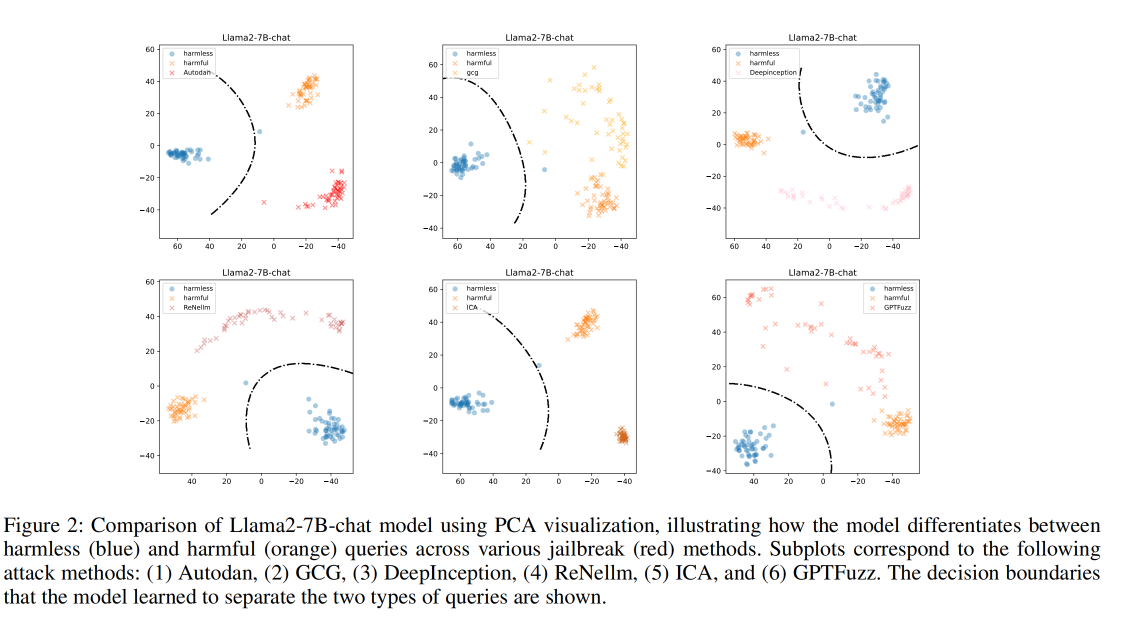
- 对越狱攻击的区分能力:受此发现的启发,我们基于easyjailbreak数据集和上述合成数据集中的50个有害查询构建了六种不同的越狱攻击。这些攻击方法包括AutoDAN(Liu et al. 2024)、DeepInception(Li et al. 2023)、GPTFuzz(Yu, Lin, and Xing 2023)、ICA(Wei, Wang, and Wang 2023)、ReNellm(Ding et al. 2024)和gcg(Zou et al. 2023),每种方法都旨在通过不同的方式绕过模型的安全机制。对于Llama2-7B-chat,我们使用三组隐藏状态来计算第一和第二主成分,包括无害查询、有害查询和越狱攻击。我们观察到,经过安全协议训练的模型不仅可以区分有害查询和无害查询,还可以区分越狱攻击。这些类别之间的边界(用虚线表示)可以轻松地通过支持向量机(SVM)拟合,查询的有害性仍然作为标签。基于这一观察,我们开发轻量级分类模型的见解包括:(i)采用更稳健的方法来采样分类标准,以及(ii)更准确地拟合模型表示空间中无害查询、有害查询和越狱攻击之间的边界。
4 Hidden State Filter
在本节中,我们将概述 HSF,然后详细描述其设计。
4.1 Overview of Hidden State Filter
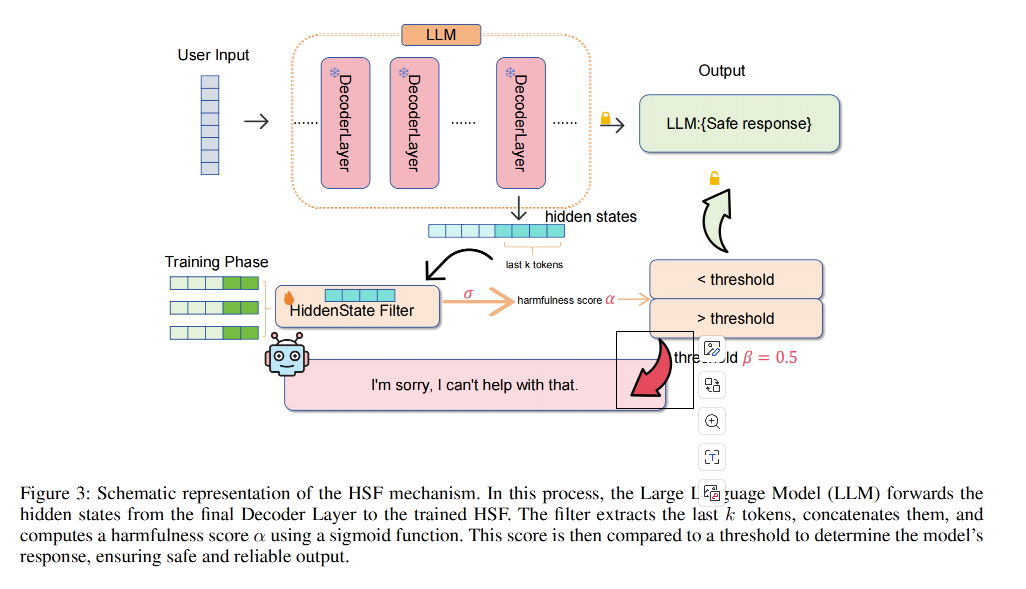
我们的 HSF 包含两个阶段,如图 3 所示。
第一阶段是训练阶段,构建一个弱分类器来对用户查询进行分类。该弱分类器使用在指定 LLM 的前向传播过程中从最后一个解码器层提取的隐藏向量进行训练。
在第二个推理阶段,用户查询经过 LLM 的前向传播,从最后一个解码器层获取隐藏向量。然后,HSF 对这些隐藏向量的最后 k 个标记进行分类,以确定是否阻止当前推理。本节的其余部分将详细介绍每个步骤。需要注意的是,HSF 不能跨不同模型进行泛化;因此,为了清晰起见,我们将使用 Llama2-7B-chat 和 Mistral-instruct-v0.2 作为示例模型来说明该过程。
4.2 Training Phase: A Weak Classifier
为了构建专家模型,我们首先从 UltraSafety(Guo et al. 2024)和 PKUSafeRLHF-prompt(Ji et al. 2024b)数据集中各收集了 3,000 个样本作为有害查询数据集。这些查询预计将被任何与人类价值观一致的 LLM 拒绝。我们还从 databricks-dolly-15k(Conover et al. 2023)数据集中收集了 6,000 个样本作为无害查询数据集。对于对齐效果较差的 Mistral-instruct-v0.2 模型,我们还分别从我们构建的有害和无害数据集中各采样了 750 个查询。这些样本用于通过添加模板补全越狱攻击模板来创建正负数据集以进行训练。
步骤 1:为了构建训练样本,我们将这些查询输入模型并进行前向传播,提取最后一层解码器隐藏状态中对应于最后 k 个标记的向量,记为 t k ∈ R n × k t_k \in \mathbb{R}^{n \times k} tk∈R