多线程与并发之进程
进程
**程序:**数据结构+算法
数据结构:用来表示人们思维对象的抽象概念的物理表现叫做:数据。对于数据进行处理操作规则叫 做:指令操作
对某一有限数据集所实施的、目的在与借鉴某一问题的一组有限的指令集合,称为:计算。
计算机就是用指令来处理数据。程序就是数据和指令的集合,一个程序的执行过程就是计算。
代码的执行结构(顺序):顺序结构 选择结构 循环结构
1.程序的执行方式
- 顺序方式
- 一个程序完全执行完毕之后才能执行下一个程序
- 比如:一个程序分为三步骤
- 输入数据—>计算–>打印结果
- 缺陷:
- CPU的利用率非常低
- 并发执行
- 把一个操作指令的执行过程,分为几个不同步骤
- 不同步骤由不同的硬件完成,这样可以多个程序同时执行
- 为了提供CPU的利用率,增加
吞吐量 并发执行,现代操作系统特地引入进程概念
2.进程是个什么东西
进程是具有独立功能的程序,关于某个数据集合上的依次运行活动。
进程就是运行的实例
int main(){int a = 11,b = 10;int sum = a + b;std::cout << "sum = " << sum << std::endl;return 0;}// ./a.out 开始执行程序,那么就开启了一个进程在进行工作2.1 进程和程序区别
- 程序是静态的概念(是指令的有序集合 ,“程序文件”),进程是一个动态概念(动态产生,动态消亡)
- 进程是一个程序的一次执行活动**,一个程序可以对应多个进程**。
- 进程是一个独立的活动单位,进程是竞争系统资源的基本单位
2.2进程和程序占用空间的区别
-
程序
- 定义:程序是存储在磁盘上的可执行文件和相关资源的集合。
- 占用磁盘空间:程序包含代码、数据和资源(如图片、配置文件等),这些都存储在磁盘上,占用磁盘空间。
- 定义:程序是存储在磁盘上的可执行文件和相关资源的集合。
-
进程
-
定义:进程是程序的一次动态执行过程,是程序在系统中运行时的实例。
-
占用系统资源:
- 内存:进程运行时会在内存中分配空间,包括:
- 栈区(Stack):用于存储函数调用的返回地址、局部变量等,由系统自动管理。
- 堆区(Heap):用于存储动态分配的内存,由程序员手动管理(如使用
malloc和free)。 - 数据区(Data Segment):用于存储全局变量和静态变量。
- 代码区(Text Segment):用于存储程序的代码。
- CPU:进程需要CPU时间片来执行代码。
- IO资源:进程可能需要访问磁盘、网络等IO资源。
- 内存:进程运行时会在内存中分配空间,包括:
-
进程的存在离不开系统资源的支持,磁盘空间用于存储程序文件,而进程运行时则需要内存、CPU等系统资源。
3.OS为什么要引入进程
就是为了能够让程序并发执行(同一时间段有多个进程在运行),并发是如何做到让多个进程并发执行 呢?
程序的并发,实际就是进程的并发。进程如何同时运行,如何并发?
3.1 进程状态
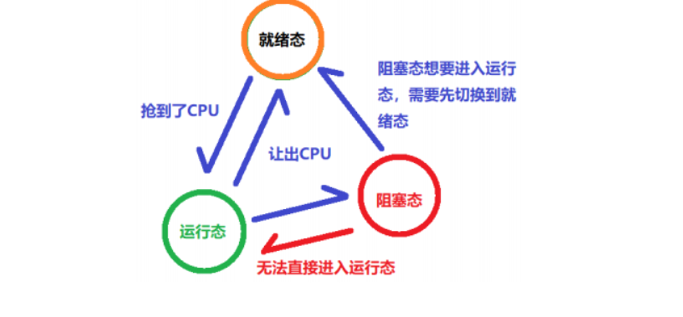
OS把一个进程的执行过程,分为了几个不同的阶段(状态)
-
创建态:在进程创建的时候,系统会生成一个空白的PCB(
process control bloc)进程控制块 -
就绪态 (Ready):准备工作已经做好了,只要有CPU就可以了。就可以执行了。
-
运行态 (Running):CPU正在执行这个进程的指令的。
-
阻塞态 (Blocking,等待waiting):进程正在等待其他的外部事件。
-
消亡态:会释放,PCB(
process control block)进程控制块PCB(process control block)进程控制块
struct task_struct {进程状态进程id进程空间地址文件表项...};
- “ 就绪队列 ”:Ready Queue
- 所处 “ Ready ” 状态的进程,都在一个 “ 后备队列 ”,“ 调度程序 ” 负责确定下一个进入 “ Running ” 状态的进程。
- “ 调度策略 ”:调度算法
- 分时系统:调度策略以 “ 时间片轮转 ” 为主要策略的系统。
- “ 时间片轮转 ” :分时,每一个进程执行一段时间(“ 时间片 ”)
- 如:大部分的桌面系统都是分时系统:
linux,android,windows,macos,unix ...
- 实时系统:调度策略以“ 实时策略 ” 为主要策略的系统 “
- 实时策略 ”:每次调度都取优先级最高的那个进程执行,直到这个进程执行完毕或者它主动 放弃CPU再或者其他更高的优先级的进程进行抢占。
- 如:
ucos,freeRTOS... - 抢占:插队,“ 强盗逻辑
- 分时系统:调度策略以 “ 时间片轮转 ” 为主要策略的系统。
4.程序执行过程
程序的执行过程:进程的动态生成
**执行过程:**分配资源----->产生进程---->执行指令…
进程要做的第一件事:就是申请一块内存区域来存储程序的数据,不同的数据属性是不一样,分区域来
存储程序数据的
4.1 Linux的进程地址空间的分布
“ 分段 ”:分不同的逻辑区域
Linux对与进程的数据进行分段管理,不同的属性的数据,存储在不同的“ 内存段 ”中,不同的内存段
(内存区域)的属性和管理方法都是不一样。
-
.txt:文本区-
主要存放代码
-
只读并且共享的,这段内存在程序运行期间(进程存活期间),不会被释放。
-
“代码段”随程序的持续性(随进程的持续性)
-
-
.data:数据段- 主要存放程序的已经初始化的全局变量和已经初始化的
static(静态)变量。 - 可读可写,这段内存在进程运行期间,会一直存在,随进程持续性
- 主要存放程序的已经初始化的全局变量和已经初始化的
-
可读可写,这段内存在进程运行期间,会一直存在,随进程持续性。
-
.bss:数据段-
主要存放程序中没有初始化的全局变量和没有初始化的static变量。
-
可读可写,这段内存在进程运行期间,会一直存在,随进程持续性。
-
``.bss `段,在进程初始化的时候,(**可能)**会全部初始化为0.
-
-
.rodata :``read only data只读数据段- 主要存放程序中的只读数据(如:字符串常量,整型常量…)。
- 只读,这段内存在进程运行期间,会一直存在,随进程持续性。
-
stack:栈空间(栈区)-
主要存放局部变量(非static变量)
-
可读可写,这段空间,会自动释放(代码块执行完毕,代码块中的局部变量的空间就释放了)随代码块持续性。
-
返回一个局部变量的地址,是有问题的原因就是在于这里。
-
-
heap :堆空间(堆区)动态内存区域
- 主要是
malloc/realloc/calloc等动态分配的空间。 - 可读可写的,这段内存在进程运行期间,一旦分配,就会一直存在,直到手动释放,或者进程 消亡,
- 防止 “内存泄漏” / “ 垃圾内存 ” 一定要主要一旦开辟空间,就要收到释放。
- 主要是
-
使用的内存地址:并不是物理地址,而是虚拟地址(虚拟内存)。
-
用户内存 (用户态)
-
内核内存 (内核态)
- 如:是4G内存,其中有一个1G是内核内存。
-
-
详细的说再解释一下虚拟地址和物理地址
-
虚拟地址:是程序员视角下的内存地址,每个进程都有独立的虚拟地址空间。在你的程序中,父进程和子进程打印出的变量
p的地址相同,这是因为它们的虚拟地址相同。 -
物理地址:是实际的内存地址,由操作系统通过页表将虚拟地址映射到物理地址。虽然虚拟地址相同,但父进程和子进程的页表不同,导致它们映射到不同的物理地址
-
5.Linux下的进程相关的API函数
5.1 创建一个新的进程:fork函数
-
描述
-
用来创建一个当前进程的子进程的
-
fork创建一个新的进程,得要知道一个进程包含一些什么东西(系统数据 用户数据指令)。 -
fork一 个新进程的时候,这个新进程的 数据 和 指令,来源于它father(它爹)(父进
程,调用fork函数的那个进程 -
fork这个函数在创建子进程的时候:
-
copy父进程的数据和指令!!!!!!
-
父进程的变量,数据对象
-
标准IO的缓冲区
-
文件描述符
-
…
当拷贝完之后,父子进程就独立了。
-
-
-
函数原型
#include <sys/types.h>#include <unistd.h>pid_t fork(void);
- 返回值
fork成功时候,就会有两个进程在执行当前的代码了!!!
所以为了区分父进程和子进程,fork调用一次会有两次返回。
一个是父进程的返回
一个是子进程的返回
所以可以通过返回值来判断当前进程是子进程还是父进程。
-
成功返回:
-
父进程返回 子进程的id号(>0)
-
子进程返回 0
-
-
失败返回:
- -1,同时
errno被设置
- -1,同时
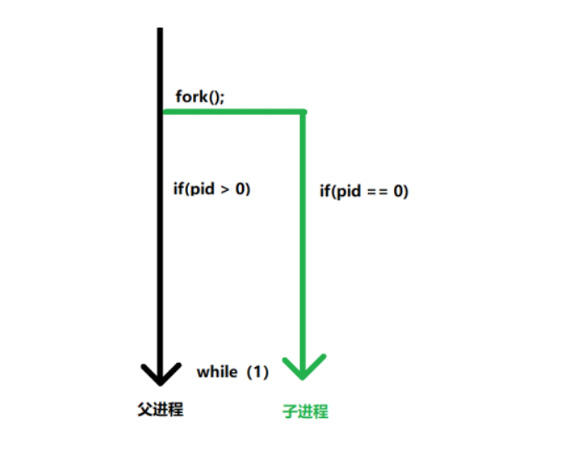
注意:成功创建一个进程之后,会从 fork 返回的位置开始执行。
示例
#include <iostream>
using namespace std;
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
void process1(int num )
{for(int i = 0; i < num ; i++){cout <<" 我是父进程" << endl; cout << "process1:" << i << endl;sleep(1);} } void process2(int num)
{ for(int i = num ; i >= 0 ; i--){cout <<" 我是子进程" << endl;cout << "process2:" << i << endl;sleep(1);} }
int main()
{cout << "第一次打印有父进程打印:" << endl;pid_t pid = fork();if(pid == 0){process1(10);}else{process2(10);}return 0;}5.2 获取进程id号
5.2.1 获取当前进程id号
- 函数原型
#include <sys/types.h>#include <unistd.h>pid_t getpid(void);
-
描述:
- 获取当前进程的id号:
get proccess id
- 获取当前进程的id号:
-
返回值
- @return: 返回当前进程的id号
5.2.2 获取父进程id号
- 函数原型
#include <sys/types.h>#include <unistd.h>pid_t getppid(void);
- 描述:
- 获取父进程的id号:
get parent proccess id
- 获取父进程的id号:
- 返回值 @return:
- 返回父进程的id号
示例
#include <iostream>
using namespace std;
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
void process1(int num )
{for(int i = 0; i < num ; i++){// cout <<" 我是父进程" << endl; cout << getpid() << ":" << i << endl;sleep(1);} } void process2(int num)
{ for(int i = num ; i >= 0 ; i--){// cout <<" 我是子进程" << endl;cout << getpid() << ":" << i << endl;sleep(1);} }
int main()
{cout << "第一次打印有父进程打印" << endl;pid_t pid = fork();if(pid == 0){cout << "当前子进程的id号:"<< getpid() << "当前子进程的父进程号:"<< getppid() << endl;process1(10);}else{cout << "当前父进程的id号:"<< getpid() << "当前父进程的父进程号:"<< getppid() << endl;process2(10);}return 0;}5.3 进程的退出
存在两种情况:
-
自杀(自己退出)
- main函数的返回,进程就会退出
- 调用进程退出函数
-
exit函数原型
#include <stdlib.h>void exit(int status); -
描述:
- 正常退出一个进程
-
参数
-
status:表示:进程的退出码
-
类似于return后面的值
-
exit会做清理工作,比如把缓冲区的内容同步文件.
-
-
_exit函数原型
#include <unistd.h>
void _exit(int status);
- 描述:
- 结束当前进程
- 参数
- @status: 表示退出码,进程的退出码
- 退出码的具体的含义,由程序员解释
_exit 赶时间,坐火箭走的,直接中止进程,来不及做清理工作。(强制退出不会同步缓冲区的内容,不建议用)
- 他杀(被操作系统干掉/其他进程干掉)比如ctrl + c
5.4 等待子进程的结束
- wait函数的原型
#include <sys/types.h>#include <sys/wait.h>
pid_t wait(int *wstatus);
-
函数描述:
- 等待子进程结束
-
参数:
wstatus: 指针,指向的空间,用来保存子进程的退出信息(怎么死的,退出码等)。
-
返回值 @return
- 成功返回退出的那个子进程的进程id号
- 失败返回-1,同时errno被设置。
-
waitpid函数的原型
#include <sys/types.h>#include <sys/wait.h>
pid_t waitpid(pid_t pid, int *wstatus, int options);
-
函数描述:
- 等待指定的子进程退出
-
参数
-
pid: 指定要等待的那个进程或者是进程组-
pid > 0表示指定id进程结束 -
pid == -1,表示等待任意子进程退出 -
pid == 0,表示等待与调用进程同组的任意子进程- 进程组:就是一组进程,每个进程必须会属于某一进程组,并且每个进程组都会有一个组长进程,一般来说,创建这个进程组的进程为组长,进程组有一个组id, 这个组id就是组长进程的pid
-
pid < -1,表示等待组id等于pid绝对值的那个组的任意子进程-
如: pid == -2398
等待2398那个组里面的任意子进程结束。
-
-
-
wstatus:- 同上
-
options(等待选项 ):- 0:表示阻塞等待
WNOHANG:非阻塞,假如没有子进程退出,就立即返回。
-
-
返回值 @return
- 成功返回退出的那个子进程的进程id号
- 失败返回-1,同时
errno被设置。
示例
#include <iostream>
using namespace std;
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
void process1(int num )
{for(int i = 0; i < num ; i++){// cout <<" 我是父进程" << endl; cout << getpid() << ":" << i << endl;sleep(1);} } void process2(int num)
{ for(int i = num ; i >= 0 ; i--){// cout <<" 我是子进程" << endl;cout << getpid() << ":" << i << endl;sleep(1);} }
int main()
{cout << "第一次打印有父进程打印" << endl;pid_t pid = fork();if(pid == 0){cout << "当前子进程的id号:"<< getpid() << " 当前子进程的父进程号:"<< getppid() << endl;process1(10);}else{int status = 0;waitpid(pid, &status, 0);cout << "当前父进程的id号:"<< getpid() << " 当前父进程的父进程号:"<< getppid() << endl;cout << "子进程:" << pid << "退出" << status << endl;} return 0;}
6.守护进程、僵尸进程和孤儿进程分别是什么?
守护进程(Daemon)
守护进程是在后台运行且不与任何控制终端关联的进程。通常,守护进程在系统启动时启动,并在系统
关闭时终止。它们用于执行系统级别的任务,如网络服务、数据备份等。
僵尸进程(Zombie Process)
僵尸进程是一个已经结束但仍然在进程表中占有一个位置的进程。它已经完成了执行,但其父进程尚未通过调用 wait() 或waitpid() 来获取其终止状态。僵尸进程不占用任何系统资源(如内存、CPU),但会占用一个进程表项。
孤儿进程(Orphan Process)
孤儿进程是指父进程在子进程之前结束,而子进程仍在运行的进程。孤儿进程的父进程会变成 init 进程(在 Linux 中通常是进程号为 1 的进程),init 进程会自动调用 wait() 来回收孤儿进程结束时的状态,从而防止孤儿进程变成僵尸进程。
僵尸进程和孤儿进程如何避免?
避免僵尸进程:
- 确保父进程在子进程结束后调用
wait()或waitpid()来获取子进程的终止状态。 - 使用信号处理函数,在子进程结束时捕获 S
IGCHLD信号,并在信号处理函数中调用 wait() 。
避免孤儿进程:
孤儿进程通常不是问题,因为它们会被 init 进程自动回收。但如果需要避免创建孤儿进程,可以在子
进程退出前确保父进程不退出
7 死锁
死锁的四个必要条件(缺一不可)
- 互斥条件
- 资源一次只能被一个线程占用(如锁被一个线程持有,其他线程必须等待)。
- 占有并等待
- 线程持有至少一个资源,同时等待获取其他被占用的资源。
- 不可剥夺
- 线程已获得的资源不能被强制抢占,只能主动释放。
- 循环等待
- 存在一个线程的循环等待链(如线程A等线程B,线程B等线程A)
破坏"占有并等待"
- 一次性获取所有资源(要么全部拿到,要么都不拿):
2. 破坏"不可剥夺"
- 使用
pthread_mutex_trylock尝试获取锁,失败时主动释放已持有的锁:
3. 破坏"循环等待"
- 固定加锁顺序(所有线程按相同顺序获取锁):
4. 使用超时机制
- 通过
pthread_mutex_timedlock设置等待超时,避免无限等待:
两个线程像两个固执的人,各自死死抓着对方想要的东西,谁也不肯先松手,结果大家都卡住没法干活。
🌰 举个生活例子:
- 线程A 拿着 钥匙,但需要 手机 才能出门;
- 线程B 拿着 手机,但需要 钥匙 才能离开;
- 结果两人大眼瞪小眼,谁都动不了 —— 这就是死锁!
✅ 描述的关键点:
- 互相占有:线程A占资源1,线程B占资源2。
- 互相需求:线程A等资源2,线程B等资源1。
- 僵持不下:双方都阻塞,程序“冻结”。
💡 如何破解?(对应代码方案)
- 避免嵌套锁:别让线程同时持有多个锁。
- 固定顺序:所有线程按相同顺序抢锁(比如先抢钥匙再抢手机)。
- 设置超时:等太久就放弃重试(
pthread_mutex_trylock)
- 记住:多线程编程中,加锁顺序一致 + 及时释放锁 是避免死锁的黄金法则!