2024年北理工Python123第六章编程题整理
这章的编程题都好少,难度也不高
开始进入文件的输入输出
一、字典翻转输出
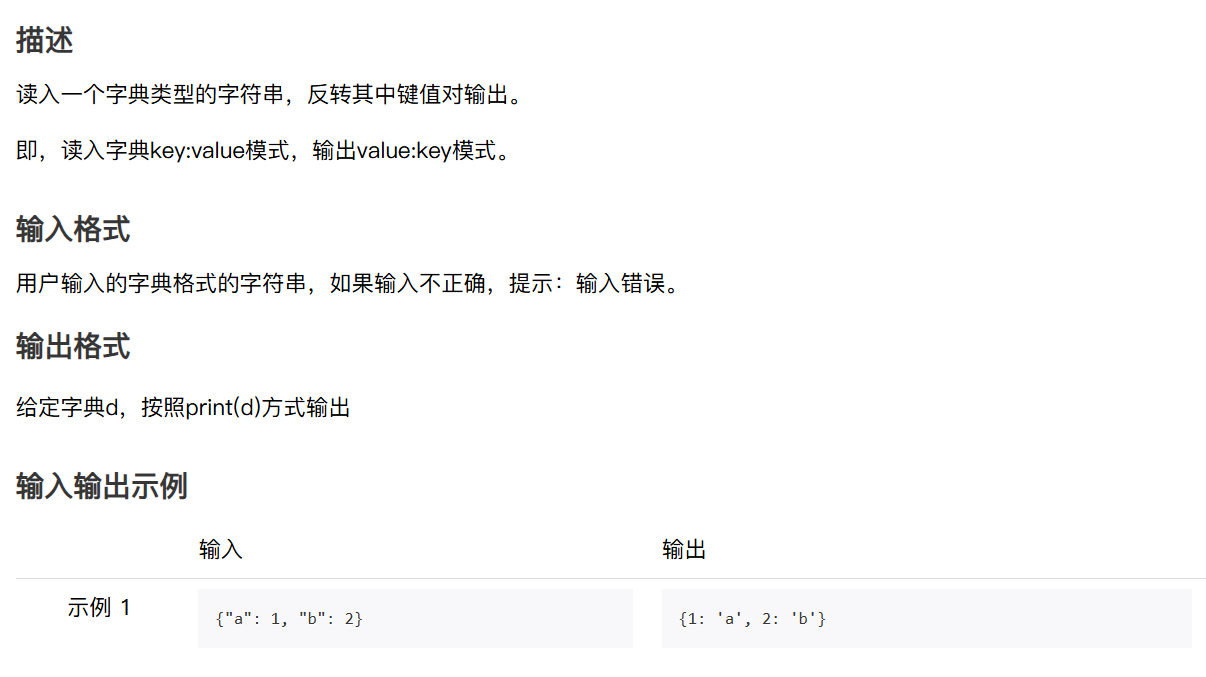
我的代码:
ori_dic = eval(input())
dic={}
if(not isinstance(ori_dic,dict)):#验证输入格式print('输入错误')
else:for item in ori_dic.keys():dic[ori_dic.get(item)]=itemprint(dic)
参考代码
s = input()
try:d = eval(s)e = {}for k in d:e[d[k]] = kprint(e)
except:print("输入错误")
二、《沉默的羔羊》之最多单词
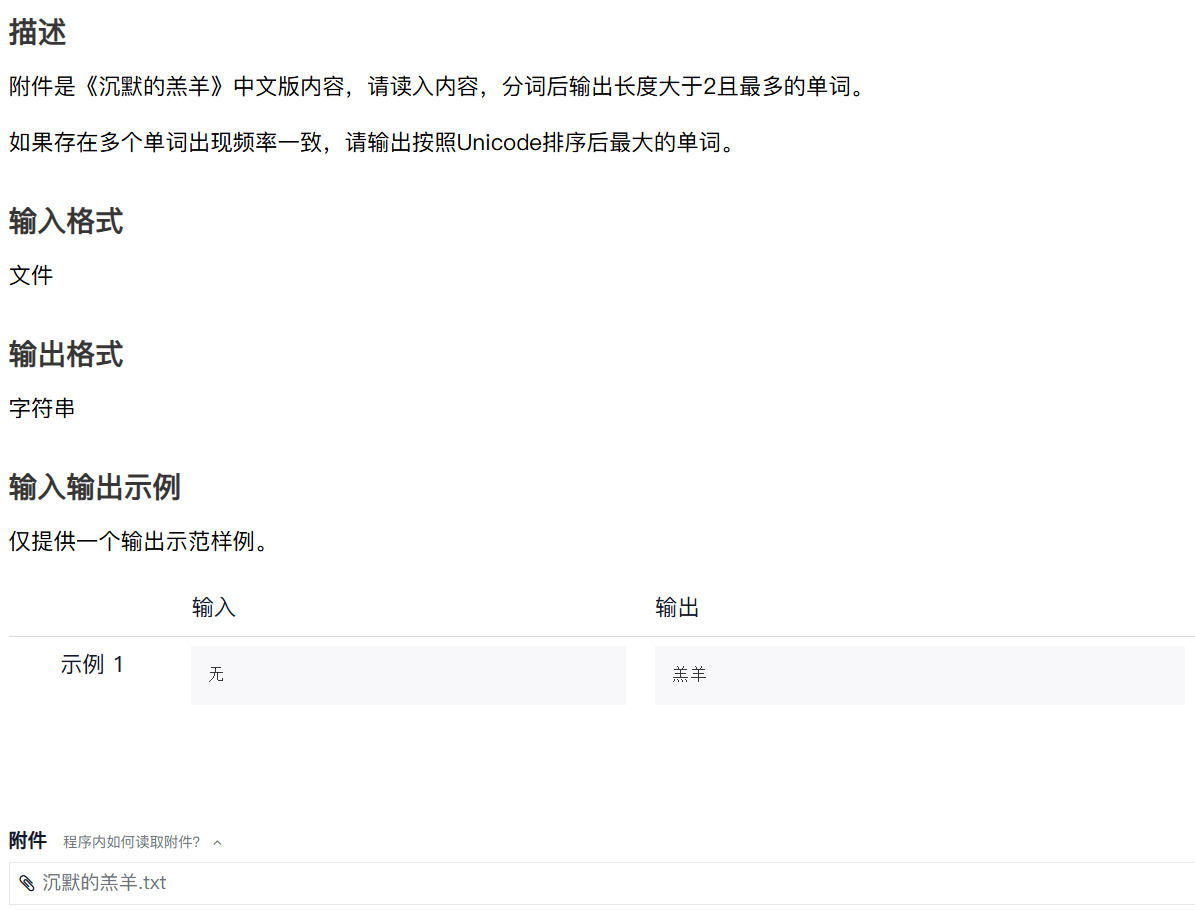
我的代码:
import jieba
from collections import Counter
with open('沉默的羔羊.txt', 'r', encoding='utf-8') as file:text = file.read()
words = jieba.cut(text)
word_counts = Counter(words)
filtered_words = [word for word in word_counts.keys() if len(word) > 2]
max_count = max(word_counts[word] for word in filtered_words)
most_frequent_words = [word for word in filtered_words if word_counts[word] == max_count]
most_frequent_words.sort()
print(most_frequent_words[-1])
参考代码:
import jieba
f = open("沉默的羔羊.txt")
ls = jieba.lcut(f.read())
#ls = f.read().split()
d = {}
for w in ls:d[w] = d.get(w, 0) + 1
maxc = 0
maxw = ""
for k in d:if d[k] > maxc and len(k) > 2:maxc = d[k]maxw = kif d[k] == maxc and len(k) > 2 and k > maxw:maxw = k
print(maxw)
f.close()
三、实例9:基本统计值计算
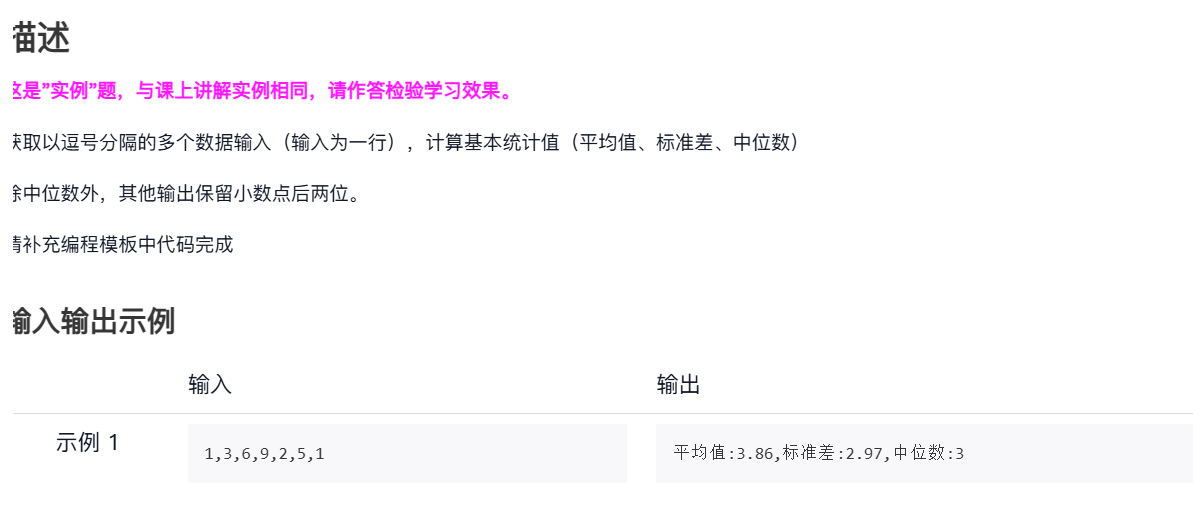
上课的题目
参考代码:
#CalStatisticsV1.py
def getNum(): #获取用户不定长度的输入s = input()ls = list(eval(s))return lsdef mean(numbers): #计算平均值s = 0.0for num in numbers:s = s + numreturn s / len(numbers)def dev(numbers, mean): #计算标准差sdev = 0.0for num in numbers:sdev = sdev + (num - mean)**2return pow(sdev / (len(numbers)-1), 0.5)def median(numbers): #计算中位数numbers.sort()size = len(numbers)if size % 2 == 0:med = (numbers[size//2-1] + numbers[size//2])/2else:med = numbers[size//2]return medn = getNum() #主体函数
m = mean(n)
print("平均值:{:.2f},标准差:{:.2f},中位数:{}".format(m, dev(n,m),median(n)))
四、实例10:文本词频统计 – Hamlet
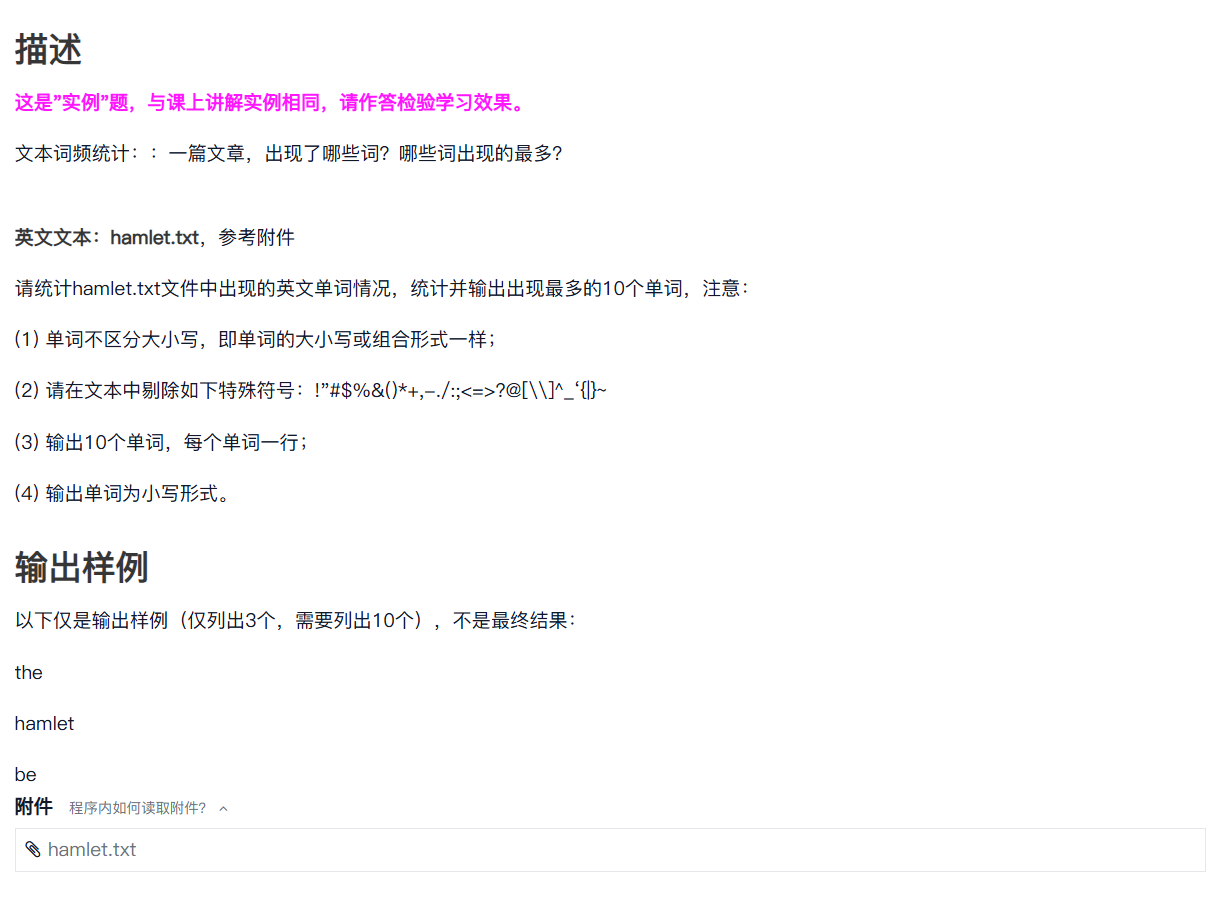
参考代码:
def getText():txt = open("hamlet.txt", "r").read()...def getText():txt = open("hamlet.txt", "r").read()txt = txt.lower()for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_‘{|}~':txt = txt.replace(ch, " ") return txthamletTxt = getText()
words = hamletTxt.split()
counts = {}
for word in words: counts[word] = counts.get(word,0) + 1
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)
for i in range(10):word, count = items[i]print (word)
五、人名最多数统计
s = '''双儿 洪七公 赵敏 赵敏 逍遥子 鳌拜 殷天正 金轮法王 乔峰 杨过 洪七公 郭靖 杨逍 鳌拜 殷天正 段誉 杨逍 慕容复 阿紫 慕容复 郭芙 乔峰 令狐冲 郭芙 金轮法王 小龙女 杨过 慕容复 梅超风 李莫愁 洪七公 张无忌 梅超风 杨逍 鳌拜 岳不群 黄药师 黄蓉 段誉 金轮法王 忽必烈 忽必烈 张三丰 乔峰 乔峰 阿紫 乔峰 金轮法王 袁冠南 张无忌 郭襄 黄蓉 李莫愁 赵敏 赵敏 郭芙 张三丰 乔峰 赵敏 梅超风 双儿 鳌拜 陈家洛 袁冠南 郭芙 郭芙 杨逍 赵敏 金轮法王 忽必烈 慕容复 张三丰 赵敏 杨逍 令狐冲 黄药师 袁冠南 杨逍 完颜洪烈 殷天正 李莫愁 阿紫 逍遥子 乔峰 逍遥子 完颜洪烈 郭芙 杨逍 张无忌 杨过 慕容复 逍遥子 虚竹 双儿 乔峰 郭芙 黄蓉 李莫愁 陈家洛 杨过 忽必烈 鳌拜 王语嫣 洪七公 韦小宝 阿朱 梅超风 段誉 岳灵珊 完颜洪烈 乔峰 段誉 杨过 杨过 慕容复 黄蓉 杨过 阿紫 杨逍 张三丰 张三丰 赵敏 张三丰 杨逍 黄蓉 金轮法王 郭襄 张三丰 令狐冲 赵敏 郭芙 韦小宝 黄药师 阿紫 韦小宝 金轮法王 杨逍 令狐冲 阿紫 洪七公 袁冠南 双儿 郭靖 鳌拜 谢逊 阿紫 郭襄 梅超风 张无忌 段誉 忽必烈 完颜洪烈 双儿 逍遥子 谢逊 完颜洪烈 殷天正 金轮法王 张三丰 双儿 郭襄 阿朱 郭襄 双儿 李莫愁 郭襄 忽必烈 金轮法王 张无忌 鳌拜 忽必烈 郭襄 令狐冲 谢逊 梅超风 殷天正 段誉 袁冠南 张三丰 王语嫣 阿紫 谢逊 杨过 郭靖 黄蓉 双儿 灭绝师太 段誉 张无忌 陈家洛 黄蓉 鳌拜 黄药师 逍遥子 忽必烈 赵敏 逍遥子 完颜洪烈 金轮法王 双儿 鳌拜 洪七公 郭芙 郭襄 赵敏'''
ls = s.split()
d = {}
for i in ls:d[i] = d.get(i, 0) + 1
max_name, max_cnt = "", 0
for k in d:if d[k] > max_cnt:max_name, max_cnt = k, d[k]
print(max_name)
这是传统解法,先使用字典建立"姓名与出现次数"的关系,然后找出现次数最多数对应的姓名。