GBK与UTF-8编码问题(1)
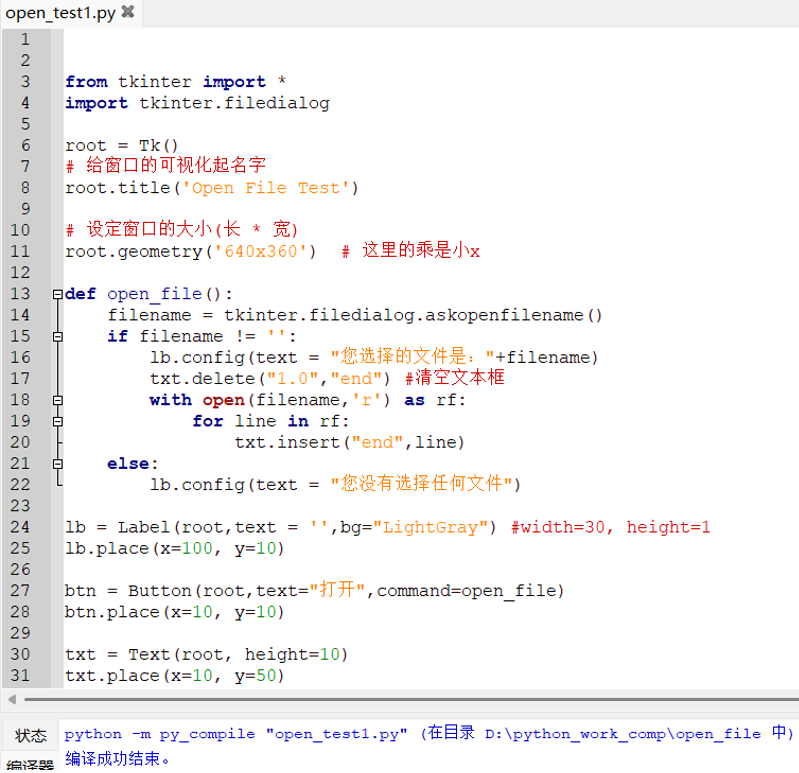
1. 问题现象
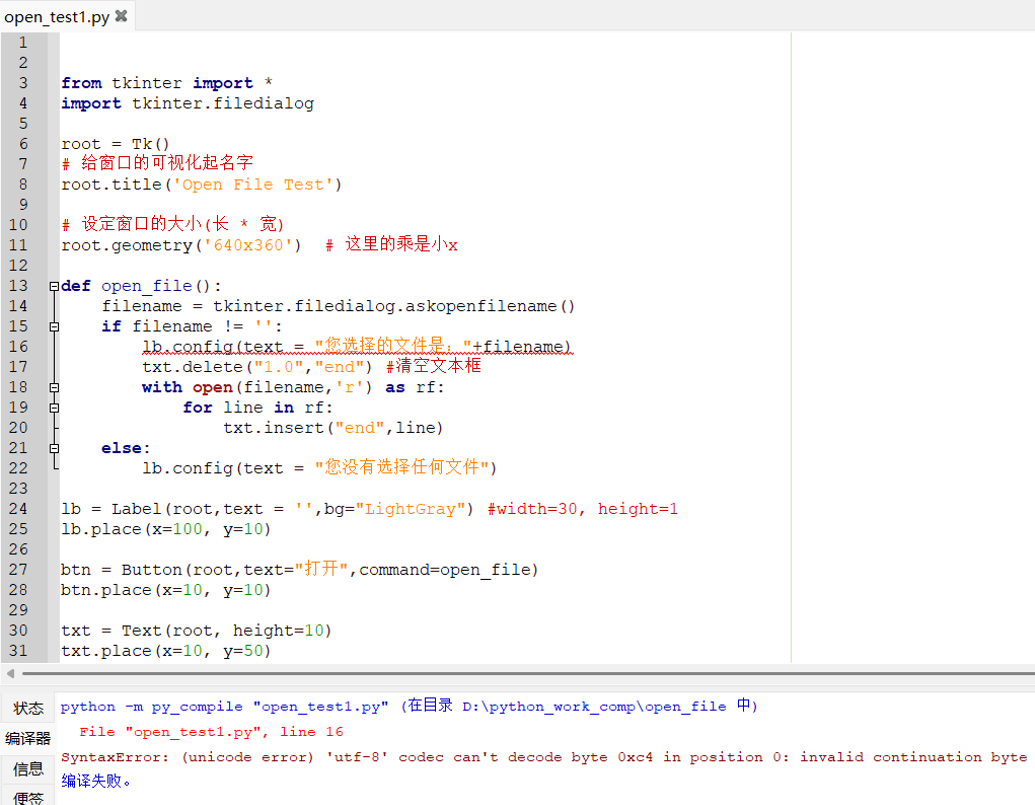
我们在编译.py的python代码时,有时会遇到如下图这种问题。提示说“SyntaxError: (unicode error) ‘utf-8’ codec can’t decode byte 0xc4 in position 0: invalid continuation byte”,代码中有中文字符,这似乎和文件的编码方式有关。
2. 原因分析
我们查了一下关于utf-8的编码解释。
• ASCII:仅支持英文字母、数字和基本符号(共 128 个字符),无法表示非英语字符。
• UTF-8:支持全球所有 Unicode 字符(超过 140,000 个字符),是一种针对 Unicode 的可变长度字符编码,包括中文、日文、阿拉伯文等。
• GBK/GB2312:中国国家标准,仅支持中文及少数其他字符,不兼容其他语言。
示例:
• 字符 A 的编码:
o ASCII/UTF-8:0x41(1 字节)
• 中文字符 “你” 的编码:
o UTF-8:0xE4 BD A0(3 字节)
o GBK:0xC4 E3(2 字节)
因此出现上述编译问题,就是因为.py文件的编码方式与Python 解释器的编码解析方式不同导致。
3. 解决方法
解决此问题有两种简单方法:
(1)在 Python 代码第1行,加入 # --coding:GBK -- ,一种指定源文件编码格式的特殊注释,也称为编码声明(coding declaration)。它的作用是告诉 Python 解释器当前文件使用GBK 编码保存,这样解释器才能正确解析文件中的非 ASCII 字符(如中文)。如下图,这时编译就不会报错了。
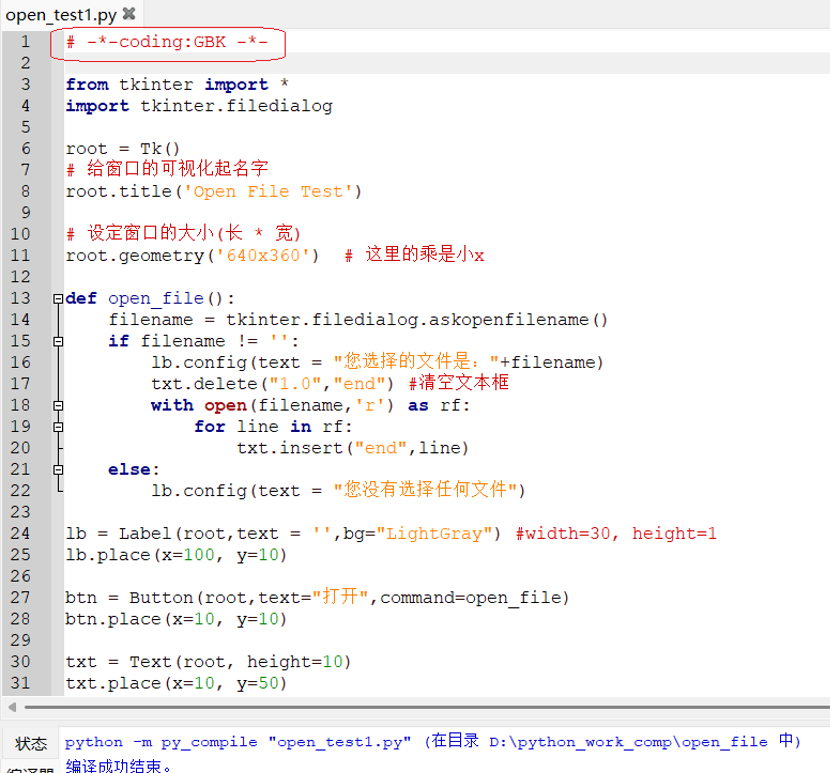
编码声明必须放在 Python 文件的首行或第二行,有以下几种等效写法:
# -*- coding: GBK -*- # Emacs风格
# coding: GBK # 简洁风格
# encoding: GBK # 同上
不过如果.py文件不是GBK 编码保存的,那也有可能还会编译出错,这时我们可以尝试第2种方法。
(2)因为Python 3.x 默认使用 UTF-8 编码解析源代码,因此我们只要将.py文件转换成UTF-8 编码,那么也能保证正常编译。可以利用Notepad++软件打开.py文件,点击菜单栏编码,再点击转为UTF-8编码,然后保存即可。
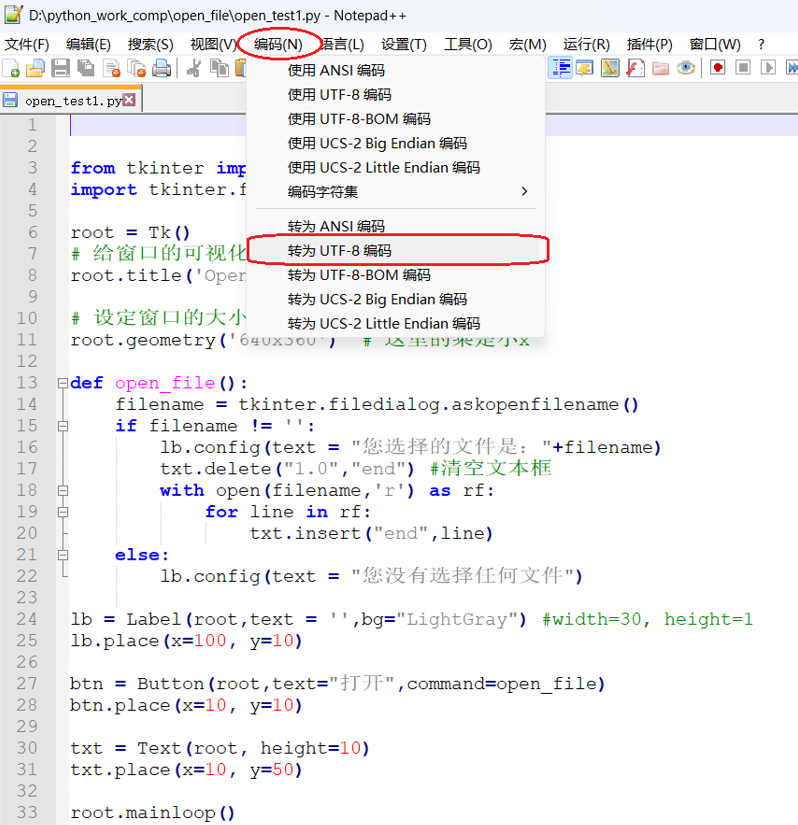
这时再编译,也不会报错了。