【大数据】MapReduce 编程--WordCount
API 是“Application Programming Interface”的缩写,即“应用程序编程接口”
Hadoop 提供了一套 基于 Java 的 API,用于开发 MapReduce 程序、访问 HDFS、控制作业等
MapReduce 是一种 分布式并行计算模型,主要用于处理 大规模数据集。它将计算任务分为两个阶段:
阶段 功能 程序类名(通常) Map 阶段 对输入数据进行处理和拆分,生成键值对(key-value) Mapper 类 Reduce 阶段 汇总 Map 输出的 key-value 数据,对相同 key 的数据进行合并处理 Reducer 类
MapReduce应用程序至少包含 3 个部分:一个 Map 函数、一个 Reduce 函数和一个 main 函数。在运行一个mapreduce计算任务时候,任务过程被分为两个阶段:map阶段和reduce阶段,每个阶段都是用键值对(key/value)作为输入(input)和输出(output)
Mapper实现
public class WcMap extends Mapper<LongWritable, Text, Text, LongWritable>{//重写map这个方法//mapreduce框架每读一行数据就调用一次该方法protected void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {//具体业务逻辑就写在这个方法体中,而且我们业务要处理的数据已经被框架传递进来,在方法的参数中key-value//key是这一行数据的起始偏移量,value是这一行的文本内容}
}WcMap 类继承了 Hadoop 提供的 Mapper 类,并且指定了四个泛型参数
Mapper 的泛型Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
-
KEYIN: 输入键的类型(Map函数输入)-- -
VALUEIN: 输入值的类型 -
KEYOUT: 输出键的类型(Map函数输出) -
VALUEOUT: 输出值的类型
| 参数 | 类型 | 含义 |
|---|---|---|
LongWritable | 输入键 | 一行文本的起始偏移量(比如第几字节开始) |
Text | 输入值 | 一整行文本内容 |
Text | 输出键 | 单词(比如:"Hello") |
LongWritable | 输出值 | 单词的计数(一般为 1) |
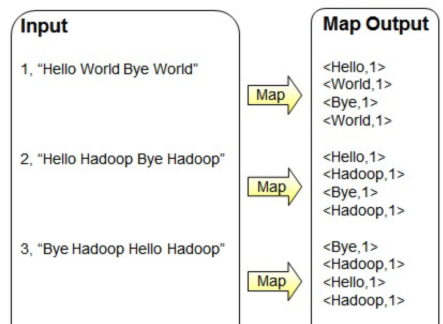
Map过程:并行读取文本,对读取的单词进行map操作,每个词都以
<key,value>形式生成。一个有三行文本的文件进行MapReduce操作。
读取第一行
Hello World Bye World,分割单词形成Map。
<Hello,1> <World,1> <Bye,1> <World,1>读取第二行
Hello Hadoop Bye Hadoop,分割单词形成Map。
<Hello,1> <Hadoop,1> <Bye,1> <Hadoop,1>读取第三行
Bye Hadoop Hello Hadoop,分割单词形成Map。
<Bye,1> <Hadoop,1> <Hello,1> <Hadoop,1>
MapReduce 中的 Mapper 实现,用于实现“词频统计”(WordCount)功能
按行读取文本,把每个单词都变成 <word, 1> 输出,为后续的词频统计做准备
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**** * @author Administrator* 1:4个泛型中,前两个是指定mapper输入数据的类型,KEYIN是输入的key的类型,VALUEIN是输入的value的值* KEYOUT是输入的key的类型,VALUEOUT是输入的value的值 * 2:map和reduce的数据输入和输出都是以key-value的形式封装的。* 3:默认情况下,框架传递给我们的mapper的输入数据中,key是要处理的文本中一行的起始偏移量,这一行的内容作为value* 4:key-value数据是在网络中进行传递,节点和节点之间互相传递,在网络之间传输就需要序列化,但是jdk自己的序列化很冗余* 所以使用hadoop自己封装的数据类型,而不要使用jdk自己封装的数据类型;* Long--->LongWritable* String--->Text */
public class WcMap extends Mapper<LongWritable, Text, Text, LongWritable>{//重写map这个方法//mapreduce框架每读一行数据就调用一次该方法@Overrideprotected void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {//具体业务逻辑就写在这个方法体中,而且我们业务要处理的数据已经被框架传递进来,在方法的参数中key-value//key是这一行数据的起始偏移量,value是这一行的文本内容//1:String str = value.toString();//2:切分单词,空格隔开,返回切分开的单词String[] words = StringUtils.split(str," ");//3:遍历这个单词数组,输出为key-value的格式,将单词发送给reducefor(String word : words){//输出的key是Text类型的,value是LongWritable类型的context.write(new Text(word), new LongWritable(1));}}
}
继承 Hadoop Mapper 的类---------------- public class WcMap extends Mapper<LongWritable, Text, Text, LongWritable>
重写的 map 方法---MapReduce 框架自动调用,对文件的每一行都会调用一次
@Override
protected void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {
| 参数 | 作用 |
|---|---|
key | 当前行在文件中的偏移量(不重要) |
value | 当前这一行的文本内容(例如:"Hello Hadoop Bye") |
context | Hadoop 框架提供的对象,用于输出结果 |
把 Text 类型转换成普通字符串:String str = value.toString();
按空格切分字符串,获取单词数组:String[] words = StringUtils.split(str," ");例如:"Hello Hadoop Bye" => ["Hello", "Hadoop", "Bye"]-----Apache Commons 的 StringUtils.split 方法
遍历所有单词
for(String word : words){context.write(new Text(word), new LongWritable(1));
}
每拿到一个单词,就创建一对键值对 <单词, 1> 输出出去。这些结果会传给 Reduce 处理
Hadoop 的 MapReduce 任务运行在集群中,key-value 是在网络上传输的, 不能使用 Java 原生类型(如 String、long),必须使用 Hadoop 提供的可序列化数据类型
Java类型 Hadoop类型 String Textlong LongWritableint IntWritablefloat FloatWritable
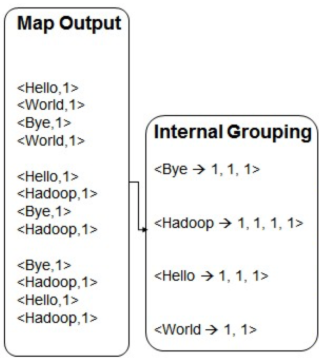
<Bye,1,1,1> <Hadoop,1,1,1,1> <Hello,1,1,1> <World,1,1>不是我们写的代码做的,而是 MapReduce 框架自动完成的工作,叫做 Shuffle + 分组过程(有时也叫分区、排序、合并)
MapReduce 的完整流程
Mapper 阶段
输入的 3 行:
Hello World Bye World
Hello Hadoop Bye Hadoop
Bye Hadoop Hello Hadoop
Mapper 输出
<Hello,1> <World,1> <Bye,1> <World,1>
<Hello,1> <Hadoop,1> <Bye,1> <Hadoop,1>
<Bye,1> <Hadoop,1> <Hello,1> <Hadoop,1>
Combiner 阶段(局部归约)
如果配置了 Combiner(它的逻辑通常和 Reducer 是一样的),那在每台 Map 机器本地就会先对相同的 key 做一次合并
<Hello,1> <Hello,1> <Hello,1>合成:<Hello,3>
Combiner 是可选的优化步骤,有助于减少网络传输数据量--:Combiner 需要配置,它不是自动就起作用的
Shuffle + Sort + Grouping(框架自动做)
这一步发生在 Mapper 和 Reducer 之间,称为 洗牌过程(Shuffle),是 MapReduce 的精髓。
| 步骤 | 解释 |
|---|---|
| Shuffle | 把相同 key 的数据发送给同一个 Reducer(网络传输) |
| Sort | 对 key 进行排序(Hadoop 默认会对 key 排序) |
| Group | 把相同 key 的多个 value 放在一个集合中 |
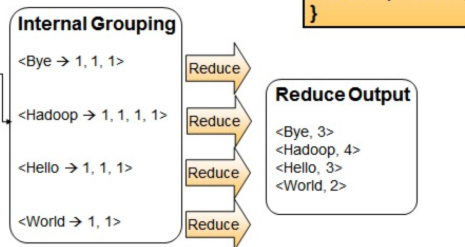
最终 Reducer 接收到的数据
<Hello, [1,1,1]>
<World, [1,1]>
<Bye, [1,1,1]>
<Hadoop, [1,1,1,1]>
假设你原始文本是:Hello World Hello
Map 阶段输出:<Hello,1> <World,1> <Hello,1>
Reduce 阶段输入(自动分组):key = Hello, values = [1, 1] key = World, values = [1]
Reduce 输出:<Hello,2> <World,1>
Reducer 实现
WcReduce 是 MapReduce 中的 Reducer 实现类
public class WcReduce extends Reducer<Text, LongWritable, Text, LongWritable>{//继承Reducer之后重写reduce方法//第一个参数是key,第二个参数是集合。//框架在map处理完成之后,将所有key-value对缓存起来,进行分组,然后传递一个组<key,valus{}>,调用一次reduce方法protected void reduce(Text key, Iterable<LongWritable> values,Context context) throws IOException, InterruptedException {}
}继承了 Hadoop 提供的 Reducer 类
| 泛型参数 | 类型 | 含义 |
|---|---|---|
KEYIN | Text | 单词 |
VALUEIN | LongWritable | 数字 |
KEYOUT | Text | Reduce 的输出 key(还是单词) |
VALUEOUT | LongWritable | Reduce 的输出 value(统计的总次数) |
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context)
throws IOException, InterruptedException {
reduce 方法就处理每一组(key 相同)Map 输出的结果
-
key: 单词,例如"Hello"、"Hadoop"。 -
values: 一个可遍历的对象,包含所有这个单词对应的值,例如<"Hello", [1, 1, 1]>。 -
context: 用来把结果写出去
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**** * @author Administrator* 1:reduce的四个参数,第一个key-value是map的输出作为reduce的输入,第二个key-value是输出单词和次数,所以* 是Text,LongWritable的格式;*/
public class WcReduce extends Reducer<Text, LongWritable, Text, LongWritable>{//继承Reducer之后重写reduce方法//第一个参数是key,第二个参数是集合。//框架在map处理完成之后,将所有key-value对缓存起来,进行分组,然后传递一个组<key,valus{}>,调用一次reduce方法//<hello,{1,1,1,1,1,1.....}>@Overrideprotected void reduce(Text key, Iterable<LongWritable> values,Context context) throws IOException, InterruptedException {//将values进行累加操作,进行计数long count = 0;//遍历value的list,进行累加求和for(LongWritable value : values){count += value.get();}//输出这一个单词的统计结果//输出放到hdfs的某一个目录上面,输入也是在hdfs的某一个目录context.write(key, new LongWritable(count));}
}累加单词出现次数
long count = 0;
for(LongWritable value : values){count += value.get();
}
LongWritable 是 Hadoop 提供的可序列化的 long 类型(因为 MapReduce 要在网络中传输数据,不能用普通的 Java 类型)
定义一个变量 count,用来统计每个单词出现的总次数
遍历传进来的所有 value 值(也就是 1)
context.write(key, new LongWritable(count));
执行MapReduce任务
在MapReduce中,由Job对象负责管理和运行一个计算任务,并通过Job的一些方法对任务的参数进行相关的设置。
设置了使用TokenizerMapper完成Map过程中的处理和使用IntSumReducer完成Combine和Reduce过程中的处理
设置了Map过程和Reduce过程的输出类型:key的类型为Text,value的类型为IntWritable。
任务的输出和输入路径则由命令行参数指定,并由FileInputFormat和FileOutputFormat分别设定。
完成相应任务的参数设定后,即可调用job.waitForCompletion()方法执行任务。
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.util.Scanner;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import java.net.URI;
/**** 1:用来描述一个特定的作业* 比如,该作业使用哪个类作为逻辑处理中的map,那个作为reduce* 2:还可以指定该作业要处理的数据所在的路径* 还可以指定改作业输出的结果放到哪个路径* @author Administrator**/
public class WcRunner{public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {//创建配置文件Configuration conf = new Configuration();//获取一个作业Job job = Job.getInstance(conf);//设置整个job所用的那些类在哪个jar包job.setJarByClass(WcRunner.class);//本job使用的mapper和reducer的类job.setMapperClass(WcMap.class);job.setReducerClass(WcReduce.class);//指定reduce的输出数据key-value类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(LongWritable.class);//指定mapper的输出数据key-value类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(LongWritable.class);Scanner sc = new Scanner(System.in);System.out.print("inputPath:");String inputPath = sc.next();System.out.print("outputPath:");String outputPath = sc.next();//指定要处理的输入数据存放路径FileInputFormat.setInputPaths(job, new Path("hdfs://master:9000"+inputPath));//指定处理结果的输出数据存放路径FileOutputFormat.setOutputPath(job, new Path("hdfs://master:9000"+outputPath));//将job提交给集群运行 job.waitForCompletion(true);//输出结果try {FileSystem fs = FileSystem.get(new URI("hdfs://master:9000"), new Configuration());Path srcPath = new Path(outputPath+"/part-r-00000");FSDataInputStream is = fs.open(srcPath);System.out.println("Results:");while(true) {String line = is.readLine();if(line == null) {break;}System.out.println(line);}is.close();}catch(Exception e) {e.printStackTrace();}}
}从 HDFS 读取输出文件 part-r-00000,然后打印文件的每一行,直到文件内容读取完为止。其核心操作是通过 FileSystem 获取 HDFS 文件系统,然后使用 FSDataInputStream 读取文件的内容
----------
FileSystem.get() 方法获取 HDFS 文件系统的实例
URI: 这是 HDFS 文件系统的 URI,指定了 HDFS 的访问路径。"hdfs://master:9000" 表示 HDFS 在 master 主机的 9000 端口上运行
Configuration: 这是 Hadoop 的配置对象,包含了关于 Hadoop 系统的各种设置。new Configuration() 会创建一个默认的配置
outputPath 是用户在输入时提供的输出路径,这里使用 outputPath + "/part-r-00000" 来构建文件路径---part-r-00000 是默认的输出文件名
FSDataInputStream 对象是用来读取文件内容的
is.readLine() 方法逐行读取文件的内容。
-
如果
readLine()返回null,表示文件已经读完。 -
每读取一行,就将其打印出来。