从结构化到多模态:RAG文档解析工具选型全指南
在RAG系统建设中,文档解析质量直接决定最终效果上限,选择合适的解析工具已成为避免"垃圾进,垃圾出"(GIGO)困境的关键决策。
一、文档解析:RAG系统的基石与瓶颈
当前企业知识库中超过80%的信息存储于PDF、Word和HTML等格式的文档中。这些文档往往包含复杂布局、多模态内容(文本、表格、图像、公式)和专业结构,传统解析方法难以准确提取其丰富语义信息。研究表明,RAG系统效果不佳的原因中约70%可追溯至文档解析环节的质量问题。
1.1 解析质量对RAG效果的影响机制
文档解析质量直接影响RAG系统效果的多个层面:
- 检索准确性:不完整的文本提取会导致关键信息缺失,影响向量检索效果
- 上下文相关性:失去文档结构会使生成阶段缺乏必要的上下文信息
- 多模态理解:忽略图像、表格等内容会大幅降低回答的准确性和丰富性
1.2 主流文档格式的解析挑战
| 文档类型 | 核心挑战 | 对RAG的影响 | 典型场景 |
|---|---|---|---|
| 布局复杂、文本提取不完整、跨页元素 | 信息丢失导致检索不准确 | 合同、研究报告、学术论文 | |
| Word | 样式信息干扰、版本兼容性问题 | 噪声过多降低相关性 | 产品手册、内部文档 |
| HTML | 标签噪声、动态内容、广告干扰 | 正文提取不纯影响质量 | 网页抓取、在线帮助系统 |
| 扫描文档 | 依赖OCR精度、版面分析难度 | 错误识别导致幻觉风险 | 历史档案、纸质文档数字化 |
二、文档解析技术演进:从规则到多模态
文档解析技术经历了从简单规则方法到现代多模态理解的演进过程:
2.1 技术演进历程
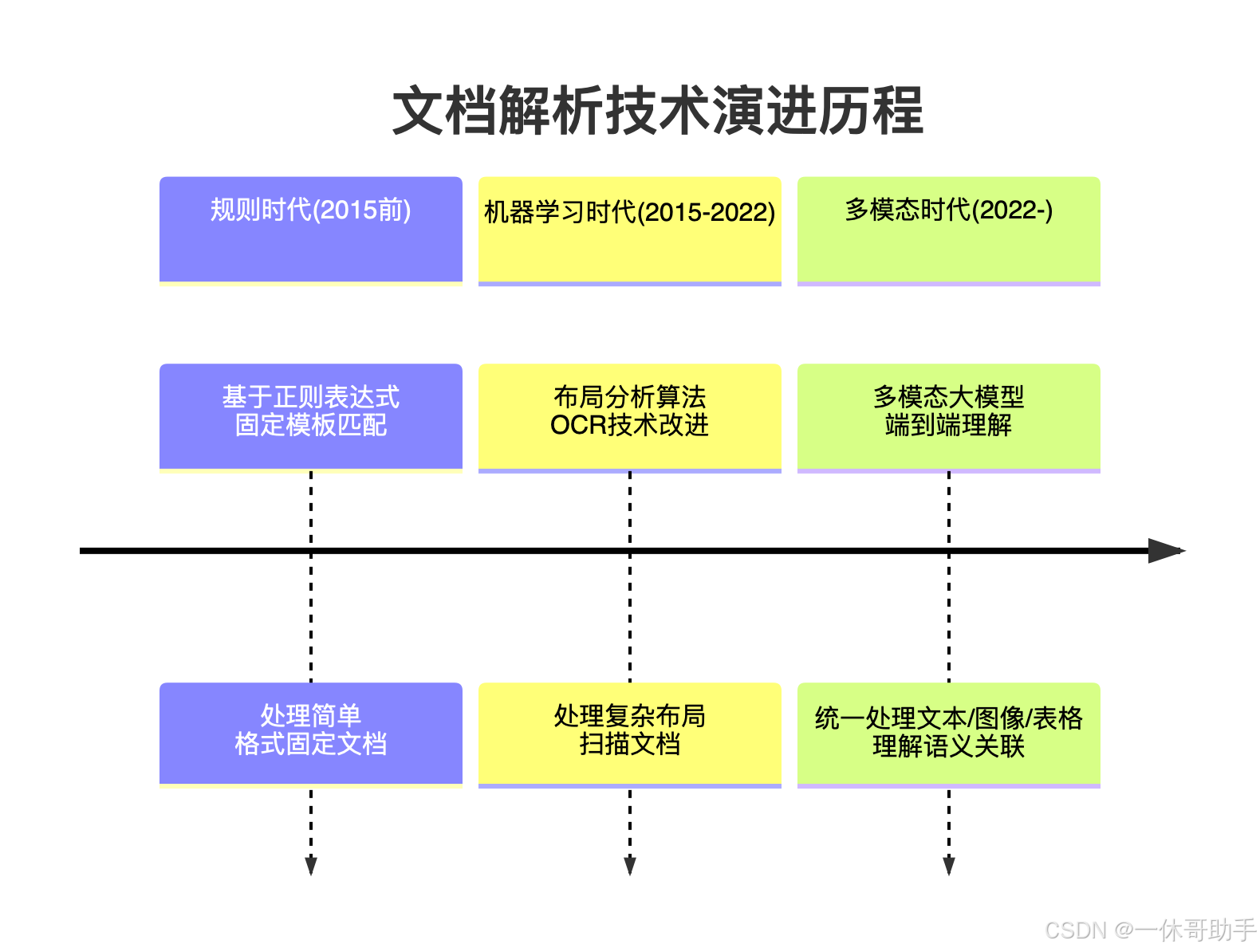
2.2 三大技术路线对比
当前主流的文档解析技术可分为三条技术路线:
-
OCR-PIPELINE方案(模块化流水线)
- 优点:能够获取 bounding box 信息、版式标签信息等;模块灵活可单独优化;支持CPU离线部署;支持扫描版文档
- 缺点:OCR链路依赖于场景数据,泛化性较差;精度不高;CPU环境下速度较慢
-
OCR-FREE方案(端到端多模态大模型)
- 优点:端到端解析简化流程;减少误差累积
- 缺点:不支持区域分块;部署成本高;存在幻觉问题;复杂文档处理能力有限
-
PDF-PARSE方案(规则驱动解析)
- 优点:速度快、效果好;可编辑场景下文字识别准确
- 缺点:不支持扫描版本文档;对图片和表格处理效果欠佳
三、主流文档解析工具全景图
3.1 文本解析工具对比
| 工具名称 | 核心特点 | 适用场景 | 局限性 | 开源/商业 |
|---|---|---|---|---|
| PyPDF2 | 轻量级、基础文本提取 | 简单PDF文本提取 | 复杂布局支持差 | 开源 |
| pdfplumber | 保持文本布局 | 需要保持布局的解析 | 表格处理有限 | 开源 |
| pdfminer.six | 支持高级解析功能 | 复杂PDF文档处理 | 配置复杂 | 开源 |
| python-docx | 标准Word文档处理 | .docx格式解析 | 不支持.doc格式 | 开源 |
| BeautifulSoup | HTML解析灵活强大 | 网页内容提取 | 动态内容需配合其他工具 | 开源 |
3.2 多模态解析工具评估
2025年最具代表性的多模态文档解析工具包括:
3.2.1 Marker(VikParuchuri)
- 技术架构:基于PyMuPDF和Tesseract OCR,支持GPU加速(Surya OCR引擎)
- 功能特性:专注PDF转Markdown,支持公式转LaTeX、图片内嵌保存,OCR识别扫描版PDF
- 适用场景:科研文献、书籍等基础PDF转换需求
- 优势:开源免费、处理速度快(比同类快4倍)
- 局限:缺乏复杂布局解析能力,依赖本地GPU资源
3.2.2 MinerU(OpenDataLab)
- 技术架构:集成LayoutLMv3、YOLOv8等模型,支持多模态解析(表格/公式/图像)
- 功能特性:精准提取PDF正文(自动过滤页眉/页脚),支持EPUB/MOBI/DOCX转Markdown或JSON
- 适用场景:学术文献管理、财务报表解析等需高精度结构化的场景
- 优势:企业级安全合规,支持API和图形界面
- 局限:依赖GPU,表格处理速度较慢,配置复杂
3.2.3 Docling
- 技术架构:模块化设计,集成Unstructured、LayoutParser等库
- 功能特性:解析PDF/DOCX/PPTX等格式,保留阅读顺序和表格结构
- 适用场景:企业合同解析、报告自动化,需结合AI框架的复杂应用
- 优势:与IBM生态兼容,支持多格式混合处理
- 局限:需CUDA环境,部分功能依赖商业模型
3.2.4 EasyDoc(商业API)
- 技术架构:AI驱动的多模态解析技术,云端API服务
- 功能特性:三种解析模式(Lite/Pro/Premium),支持跨页表格合并、图表解析
- 适用场景:企业级应用,需要高精度解析且无本地部署需求的场景
- 优势:解析精度高,支持复杂元素处理,无需配置环境
- 局限:商业API需要付费,数据隐私考虑
3.3 企业级解决方案
对于大型企业需求,以下解决方案值得考虑:
3.3.1 阿里云文档智能(Document Mind)
- 特点:提供含层级的段落信息、表格及表格单元信息、图片信息,并包含丰富的标题、段落、页码、注解等版面类型信息
- 优势:多格式支持,提取文档层级树,分析文档版面信息
- 部署:支持公共云API/SDK接入方式
3.3.2 RAG-Anything(香港大学)
- 特点:一站式多模态处理流程,支持10多种主流文档格式,具备全方位内容理解能力
- 优势:整合视觉分析、语言理解和结构化数据处理技术,能够深度理解各类内容
- 开源地址:https://github.com/HKUDS/RAG-Anything
3.3.3 ViDoRAG(阿里巴巴)
- 特点:基于多智能体协作和动态迭代推理的视觉文档检索增强生成框架
- 优势:采用高斯混合模型(GMM)的多模态混合检索策略,动态调整检索结果数量
- 适用场景:教育、金融、医疗等领域的复杂视觉文档分析
四、工具选型指南:五维评估模型
为企业选择文档解析工具时,建议从以下五个维度进行全面评估:
4.1 精度维度
- 文本提取准确率:尤其是特殊字符、数字和专业术语的准确性
- 结构保持能力:标题层级、段落关系、列表结构的保持程度
- 多模态元素处理:表格、图像、公式的识别和转换精度
- 跨页内容处理:跨页表格、分段内容的完整性保持
4.2 性能维度
- 处理速度:单文档平均处理时间,批量处理能力
- 资源消耗:CPU/GPU占用,内存需求,存储需求
- 并发能力:同时处理多个文档的能力和稳定性
- 扩展性:水平扩展和垂直扩展的能力
4.3 功能维度
- 格式支持:支持的文档格式种类和版本
- 输出选项:支持的输出格式(JSON、Markdown、HTML等)
- API质量:API接口的完整性和易用性
- 集成能力:与现有RAG框架、向量数据库的集成难度
4.4 成本维度
- 许可费用:开源许可限制或商业许可费用
- 部署成本:硬件需求、云服务成本
- 维护成本:更新频率、技术支持可用性
- 人力成本:学习曲线、开发集成工作量
4.5 合规与安全
- 数据隐私:数据处理位置,隐私保护措施
- 合规认证:行业特定合规认证(HIPAA、GDPR等)
- 审计能力:操作日志、解析历史追溯能力
- 可靠性:服务可用性,故障恢复能力
五、实践建议:按场景选型策略
5.1 学术研究场景
特点:大量PDF论文、技术报告,包含复杂公式、图表和参考文献
推荐工具:MinerU + 专用公式识别工具(如Mathpix)
配置建议:
- 启用高精度模式处理公式和图表
- 配置学术术语词典提高识别准确率
- 设置参考文献解析规则保留引文信息
5.2 企业知识库场景
特点:多格式文档(Word、PDF、PPT),需要内容标准化和结构化管理
推荐工具:EasyDoc API或阿里云文档智能
配置建议:
- 定义企业特定的文档结构和元数据规范
- 设置自动化管道处理新文档入库
- 建立质量检查机制确保解析质量
5.3 法律合规场景
特点:合同、法规文档,要求极高准确性和完整性,敏感内容处理
推荐工具:本地部署的MinerU或Docling
配置建议:
- 实现完全离线处理保障数据安全
- 配置法律术语词典和模板库
- 建立版本控制和变更追踪机制
5.4 互联网内容处理
特点:大量HTML页面,动态内容,广告和导航噪声
推荐工具:MarkitDown(微软) + BeautifulSoup
配置建议:
- 配置内容提取规则针对不同网站模板
- 设置广告和噪声内容过滤规则
- 使用动态渲染工具(Selenium/Playwright)处理JavaScript内容
六、架构设计最佳实践
6.1 模块化解析管道设计
实现可扩展、易维护的文档解析系统需要采用模块化设计:
class DocumentProcessingPipeline:def __init__(self):self.preprocessors = [] # 预处理模块self.parsers = {} # 解析器按类型组织self.postprocessors = [] # 后处理模块def process_document(self, file_path: str, strategy: str = 'modular'):# 文档类型检测file_type = self.detect_file_type(file_path)# 选择处理策略if strategy == 'deepdoc':return self.call_deepdoc_api(file_path) # 一体化方案# 模块化处理流程preprocessed = self.apply_preprocessors(file_path, file_type)parsed_content = self.apply_parser(preprocessed, file_type)result = self.apply_postprocessors(parsed_content)return resultdef apply_parser(self, file_info, file_type):"""根据文件类型选择最优解析器"""if file_type == '.docx':return self.process_with_markitdown(file_info)elif file_type == '.pdf':if self.is_complex_pdf(file_info): # 复杂度检测return marker.parse(file_info)return pymupdf.parse(file_info)else:return unstructured.parse(file_info)
数据来源:基于的架构思路改进
6.2 多模态内容处理策略
对于包含丰富多模态内容的文档,需要采用专门的处理策略:
6.2.1 表格处理双路径
6.2.2 图像混合内容处理
对于包含图像的文档,采用三重索引机制确保检索效果:
{"chunk_id": "doc007_imageblock","searchable_content": "系统架构如图... [图片描述:三层微服务架构...]","metadata": {"original_text": "系统架构如下图所示","image_uri": "https://oss.example/arch.png"}
}
6.3 质量评估与迭代优化
建立持续的解析质量评估机制至关重要:
-
自动化评估指标
- 文本保留率:原始文本内容的保留比例
- 结构准确性:文档结构元素的正确识别率
- 元素完整性:表格、图像等多模态元素的完整提取率
-
人工审核流程
- 定期抽样审核:每周随机抽取已处理文档进行人工检查
- 关键文档复核:对重要文档实施100%人工复核
- 错误反馈循环:建立错误案例库指导系统优化
-
A/B测试框架
- 并行处理比较:使用不同解析器处理同一文档对比结果
- 效果评估:基于下游RAG任务效果评估解析质量
- 自动切换:根据性能指标自动选择最佳解析方案
七、未来发展趋势
文档解析技术正在快速发展,以下几个方向值得关注:
-
多模态大模型统一处理
- 端到端的文档理解模型(如olmOCR、mistral ORC)
- 减少预处理环节,降低误差累积
- 提高泛化能力和准确性
-
领域自适应解析
- 针对特定领域(医疗、法律、金融)优化的解析模型
- 领域术语和结构模式的集成理解
- 少样本学习适应新文档类型
-
实时学习与优化
- 根据用户反馈实时调整解析策略
- 持续学习机制适应新文档格式和布局
- 自动错误检测和纠正机制
-
多模态关联理解
- 深度理解文本、图像、表格之间的语义关联
- 构建文档内知识图谱增强检索效果
- 跨模态注意力机制提升理解能力
结论
文档解析作为RAG系统的基石,其质量直接决定整个系统的效果上限。随着多模态文档成为主流信息载体,传统的纯文本解析方法已无法满足现代RAG系统的需求。选择合适的文档解析工具需要综合考虑精度、性能、功能、成本和安全等多个维度,并结合具体的应用场景做出决策。
未来,随着多模态大模型技术的发展,文档解析将变得更加智能和精准,能够更好地理解和提取复杂文档中的丰富信息。建议企业在构建RAG系统时,将文档解析作为独立子系统进行持续迭代和优化,其质量提升将为下游任务带来10倍级的效果放大。
最佳实践总结:
- 从简单开始:首先评估现有开源工具(如pdfplumber、BeautifulSoup)是否能满足需求
- 逐步复杂化:随着需求增长引入多模态解析工具(如Marker、MinerU)
- 考虑商业方案:对于企业级应用,评估商业API(如EasyDoc、阿里云文档智能)的成本效益
- 建立质量监控:实施持续的解析质量评估和优化机制
- 保持灵活性:采用模块化设计,便于未来替换和升级解析组件
通过科学合理的工具选型和架构设计,企业可以构建高效、准确的文档解析管道,为RAG系统提供高质量的知识输入,最终实现更智能、可靠的问答和应用体验。