从0开始学习大模型--Day07--大模型的核心知识点
AI常见名词
知识库
分为传统知识库与AI知识库,前者是单纯的存储各个领域的知识,后者则是与LLM结合,使AI系统能够更好地利用本地知识来响应查询和执行任务。比如,假如公司新来了个维修人员,他可以直接调用AI知识库去学习维修手册,痛点,需要注意的点以及不懂得地方都可以直接问AI知识库,在一定程度上起到了老师傅的作用。
向量化(Embeding)
向量化表示:Embeding是将文本数据(如单词、短语或整个文档)转换为数值向量的过程。这些数值向量捕捉到了文本项的语义和语法特征,使得计算机能够处理文本数据。
维度降低:通过Embedding,可以将每个文本项表示为一个较低维度的稠密向量,这些向量在较小的维度空间内保持了原始数据的重要特征。
语义关系:embedding向量能够编码语义信息,使得语义上相似的词汇在向量空间中彼此接近。这一特性使得embedding在信息检索、文本分类情感分析等任务中非常有效。
提示词工程(prompt engineer)
定义:指的是在与人工智能系统交互,如何精心设计和优化输入语句(prompts)的过程。这个过程关注于如何构造问题或命令,以从 AI 系统获取最有效和相关的回应。
目的:通过改进交互方式,提高与 AI 系统沟通的质量和效率。
关键性质:Prompt Engineering 重视语言的选择、上下文的应用,以及用户意图的明确表达。通过细致调整输入语句,可以优化 AI的理解和响应,从而提升整体的交互体验。
RAG(检索增强生成)
结合检索与生成:RAG 融合了信息检索和文本生成两种技术,先从大数据中检索信息,再基于这些信息生成文本。
增强生成质量:通过使用检索到的相关信息,RAG 旨在提高文本生成的相关性、准确性和深度。
应用于复杂查询:RAG 特别适用于需要广泛知识和深度理解的复杂查询,能够提供更丰富、更精确的回答。
接下来,我们用一张流程图来看大模型处理语句的过程:
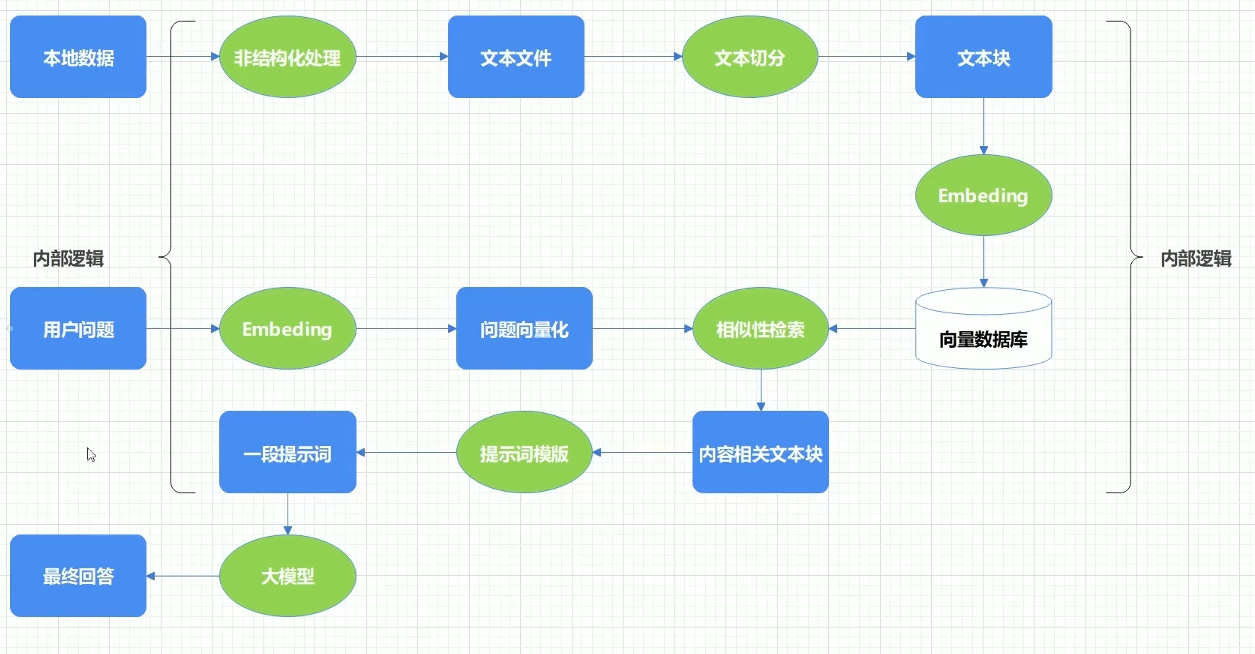
大模型处理用户问题的过程
首先,我们要先构建大数据本身数据库,将本地数据通过非结构化处理变成文本文件(大模型一般都是处理文本,即使是图片也是存储成文本的形式),并将其切分成一个个文本块(大模型接受数据的量是有限的,一般不会读取一整个文档或一大段文字,而是切分成文本块一个个分析),再通过向量化存储在数据库中;当用户开始输入问题提问时,大模型会先将其向量化,与数据库中的向量作比对,将相似的向量提取出来,转成文本块,并与提示词模版相结合,从而变成一段更合理,更有逻辑性,能让大模型看懂的提示词输入给大模型,从而输出回答,在上述处理文本的过程,就是RAG。
微调(Finetuning)
模型优化:微调是对预训练的人工智能模型进行进一步训练,以便它更好地适应特定的任务或数据集。
数据适应性:通过使用特定领域或任务的数据,微调调整模型的参数使其更适合于该特定环境。
性能提升:微调的目的是提高模型在特定任务上的表现,比如提升精度、减少错误率或提高处理速度。
总结就是用另外的数据集重新训练一次模型,让其能够适应不同领域的数据。
AI agent(AI 代理人)
信息检索与决策:AIAgents 是设计用来感知环境、做出决策并自主行动以实现特定目标的软件程序或系统。它们通过内部模型来考虑除当前输入之外的一些上下文,从而做出更为明智的决策;
目标导向:这些智能体可以像规划者一样,设定持定的目标或目的,并在当前状态、所需达到的目标以及达到这些目标的系列行动之间进行选择;
适应与学习:AlAgents 也包括学习型智能体,它们能够根据接收到的数据和反馈适应和改进其决策制定。
学习来源于B站教程:【进阶篇】01.AI以及大模型的进阶核心知识点(重要,请反复观看!)_哔哩哔哩_bilibili