TCPIP详解 卷1协议 十 用户数据报协议和IP分片
10.1——用户数据报协议和 IP 分片
UDP是一种保留消息边界的简单的面向数据报的传输层协议。它不提供差错纠正、队列管理、重复消除、流量控制和拥塞控制。它提供差错检测,包含我们在传输层中碰到的第一个真实的端到端(end-to-end)校验和。这种协议自身提供最小功能,因此使用它的应用程序要做许多关于数据包如何发送和处理的控制工作。想要保证数据被可靠投递或正确排序,应用程序必须自己实现这些保护功能。一般来说,每个被应用程序请求的 UDP输出操作只产生一个 UDP 数据报,从而发送一个IP数据报。这不同于面向数据流的协议,例如TCP,应用程序写入的全部数据与真正在单个 IP 数据报里传送的或接收方接收的内容可能没有联系。
[RFC0768]是 UDP 的正式规范,它至今仍然是一个标准,30 多年来没有做过重大的修改。如前所述,UDP 不提供差错纠正:它把应用程序传给 IP 层的数据发送出去,但是并不保证它们能够到达目的地。另外,没有协议机制防止高速UDP流量对其他网络用户的消极影响。考虑到这种可靠性和保护性的缺失,我们可能会认为使用UDP一点好处也没有。但是,这是不对的。因为它的无连接特征,它要比其他的传输协议使用更少的开销。另外,广播和组播操作更多直接使用像 UDP 这样的无连接传输。最后,应用程序可选择自己的重传单元的能力是一项重要的考虑。
下图显示了一个UDP数据报作为单个IPv4数据报的封装。IPv6 的封装是类似的,但是一些细节有少许不同。IPv4 协议字段用值 17 来标识UDP。IPv6则在下一个头部字段使用相同的值。

10.2——UDP 头部
下图显示了一个包含负载和 UDP 头部(通常是 8 字节)的 UDP 数据报。
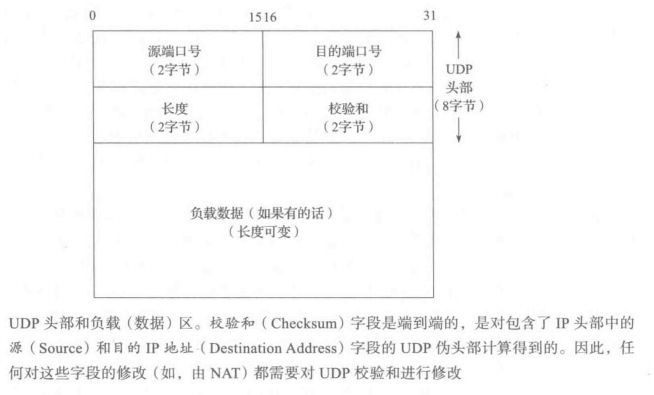
端口号相当于邮箱,帮助协议辨认发送和接收进程。在UDP中,端口号是正的16比特的数字,源端口号是可选的;如果数据报的发送者不要求对方回复的话,它可被置成0。传输协议,如TCP、UDP和SCTP[RFC4960],使用目的端口来帮助分离从IP层进入的数据。因为IP层根据IPv4头部中的协议字段或IPv6头部中的下一个头部字段的值将进入的IP数据报分离到特定的传输协议,这意味着端口号在不同的传输协议之间是独立的。也就是说,TCP 端口号只能被 TCP使用,UDP 端口号只能被 UDP 使用,如此类推。这样的分离导致的一个直接结果是两个完全不同的服务器可以使用相同的端口号和IP地址,只要它们使用不同的传输协议。
UDP长度字段是UDP头部和UDP数据的总长度,以字节为单位。这个字段的最小值是8,除非使用了带有IPv6超长数据报的UDP。发送一个带 0 字节数据的 UDP数据报是允许的,尽管这很少见。值得注意的是UDP 长度字段是冗余的;IPv4 头部包含了数据报的总长度,同时 IPv6 头部包含了负载长度。因此,一个 UDP/IPv4数据报的长度等于IPv4数据报的总长度减去IPv4头部的长度。一个UDP/IPv6数据报的长度等于包含在IPv6头部中的负载长度字段的值减去所有扩展头部(除非使用了超长数据报)的长度。在这两种情况下,UDP长度字段的值应该与从 IP 层提供的信息计算得到的长度是一致的。
10.3——UDP 校验和
UDP 校验和是我们遇到的第一个端到端的传输层校验和(ICMP 有一个端到端的校验和,但它不是一个真正的传输协议)。它覆盖了 UDP 头部、UDP 数据和一个伪头部。它由初始的发送方计算得到,由最终的目的方校验。它在传送中不会被修改(除非它通过一个 NAT)。回想一下 IPv4 头部中的校验和只覆盖整个头部(即它并不覆盖 IP 分组中的任何数据),它在每个 IP 跳都要被重新计算(因为IPv4 TTL 字段的值在数据报转发时会被路由器减少)。传输协议(如 TCP、UDP)使用校验和来覆盖它们的头部和数据。对于UDP来说,校验和是可选的(推荐使用),而其他的则是强制的。当 UDP在 IPv6 中使用时,校验和的计算与使用是强制的,因为在IP 层没有头部校验和。为了给应用程序提供无差错数据,像 UDP 这样的传输层协议,在投递数据到接收方应用程序之前,必须计算校验和或者使用其他差错检测机制。
虽然计算UDP校验和的基本方法与普通互联网校验和(16位字的反码和的反码)类似,但是要注意两个小的细节。首先,UDP数据报长度可以是奇数个字节,而校验和算法只相加16位字(总是偶数个字节)。UDP的处理过程是在奇数长度的数据报尾部追加一个值为 0 的填充(虚)字节,这仅仅是为了校验和的计算与验证。这个填充字节实际上是不会被传送出去的,因此在这里称之为“虚”的。
第二个细节是 UDP(也包括 TCP)计算它的校验和时包含了衍生自 IPv4 头部的字段的一个12字节的伪头部或衍生自IPv6头部的字段的一个40字节的伪头部。这个伪头部也是虚的,它的目的只是用于校验和的计算(在发送方和接收方)。实际上,它从来不会被传送出去。这个伪头部包含了来自 IP 头部的源和目的地址以及协议或下一个头部字段(它的值应该是17)。它的目的是让UDP层验证数据是否已经到达正确的目的地。下图显示了计算UDP校验和时覆盖的字段,包含了伪头部以及UDP头部和负载。
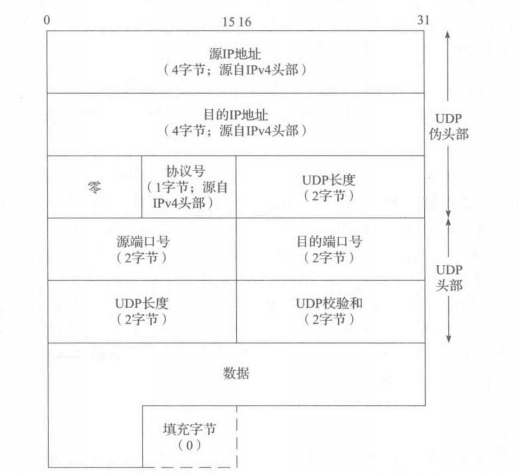
上图显示了一个数据是奇数长度的数据报需要一个填充字节来完成校验和的计算。注意到UDP数据报的长度在校验和的计算中出现了两次。如果计算出来的校验和的值正好是 0x0000,它在头部中会被保存成全 1(0xFFFF),等于算术反码。一旦被接收,校验和字段值为0x0000表示发送方没有计算校验和。如果发送方的确计算了校验和,而接收方也检测到一个校验差错,UDP 数据报就会被毫无声息地放弃。尽管会有一些统计计数被更新,但却没有差错消息产生。
尽管 UDP 数据报校验和在原始 UDP 规范中是可选的,目前它们还是被要求在主机中默认使用。在20世纪80年代,一些计算机供应商默认关闭了UDP校验和功能以加速其Sun网络文件系统(NFS)的实现,该网络文件系统使用了UDP。因为有第2层的CRC保护,在许多情况下这可能不会产生问题,然而默认关闭校验和功能被认为是一种不好的方法(也是违反RFC规范的)。早期的互联网经验表明,当数据报通过路由器时,关于它们的正确性的所有赌注都会失败。信不信由你,总会存在有软件和硬件漏洞的路由器在转发数据报时会修改其中的比特。如果端到端的UDP校验和被关闭的话,这些UDP数据报中的错误就无法检测到。同时注意到一些更老的数据链路协议(比如,串行线 IP 或 SLIP)没有任何形式的数据链路校验和,因此存在 IP 分组被修改而检测不到的可能性,除非引入另一种校验和。
考虑到伪头部这样的结构,可以很清楚地看到,当一个UDP/IPv4 数据报穿过一个NAT时,不仅IP层头部的校验和要被修改,而且 UDP伪头部的校验和也必须被正确地修改,因为IP层的地址和/或UDP层的端口号可能会改变。因此NAT通常因同时修改分组中协议的多层而违反分层规则。当然,考虑到伪头部本身就是违反分层规则的,NAT没有选择。UDP流量被NAT处理时的一些特定规则由[RFC4784]给出。
10.5——UDP 和IPv6
考虑到简单性,在对IPv6而非IPv4进行操作时,UDP只需做很小的改动。最明显的不同就是IPv6使用 128 位的地址和由此产生的对伪头部的结构带来的影响。一个相关却更细致的不同在于,在 IPv6 里不存在IP 层头部校验和。因此,如果UDP不使用校验和去运行,就没有端到端检测任何IP 层地址信息的正确性。鉴于此,当UDP用于IPv6时,无论是UDP还是TCP,伪头部校验和都是必需的。伪头部的结构由下图给出。注意到长度字段已经从它的IPv4 相应字段扩展到32 位。回想之前所述,这个字段对 UDP来说是冗余的,对TCP(无论是 TCP/IPv4 还是 TCP/IPv6)来说它不是冗余的,因此在 UDP/IPv6 和 TCP/IPv6中都保留了该字段。

扩展讨论一下 IPv6 分组长度,IPv6 分组大小的两个方面会影响 UDP。第一,在 IPv6里,最小MTU大小是1280字节(与IPv4要求的需要所有主机支持的最小大小576字节不同)。第二,IPv6 支持超长数据报(大于 65 535 字节的分组)。如果我们仔细查看 IPv6 头部和选项集,可以观察到使用超长数据报,32位是能够表示负载长度的。这意味着单个UDP/IPv6数据报确实可以非常大。如[RFC2675]所述,对于UDP头部中的只有16据位长的UDP长度字段会产生一个问题。这样的话,超过65 535字节的UDP/IPv6数据报被封装在IPv6时,它的UDP长度字段值会被置成0。注意到伪头部里的长度字段的大小仍然足够大(32位),对IPv6超长数据报计算这个字段的值,涉及取UDP头部加上数据的总长度。当收到一个分组检查这个字段时,涉及计算UDP数据报(头部加数据)的大小,通过在Jumbo Payload选项中找到的值减去所有IPv6扩展头部的大小来得到,这也是IPv6负载的长度(即数据报总长减40字节的IPv6头部)。在 UDP头部中的长度字段是0且没有Jumbo Payload选项存在的“意外的”情况下,UDP长度可以从不等于零的IPv6负载长度字段中推断得到。
10.5.1 Teredo:通过 IPv4网络隧道传输 IPv6
Teredo(也叫Teredo隧道)为没有其他IPv6连接选项的系统传送IPv6数据报,方法是把IPv6 数据报置于 UDP/IPv4 数据报的负载区里。下图中给出了一个例子场景。
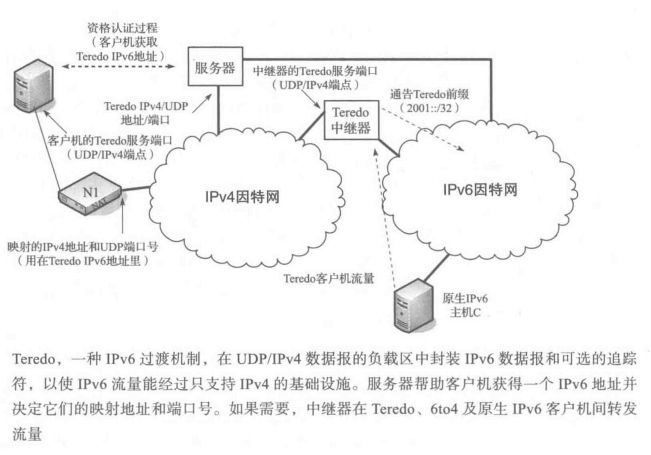
Teredo 客户机是实现了 Teredo 隧道接口的 IPv4/IPv6 主机。在成功通过一个“资格认证”过程之后,接口会被分配一个特定的以 2001::/32 为 IPv6 前缀的Teredo 地址。与 STUN 服务器的作用类似,Teredo服务器用于帮助Teredo封装的IPv6分组建立直接通道以穿越 NAT。Teredo 中继器(relay)与 TURN 服务器的作用类似,如果有大量客户在使用的话,会消耗相当可观的处理资源。值得注意的是,服务器必须包括中继器的所有功能,反之则不然。对IPv6连接来说,使用Teredo中继器是“最后手段”。如果发现其他任何可选的IPv6连接(比如,直接连接或使用6to4),节点就会放弃使用Teredo隧道技术。
参照上图,Teredo 客户机使用主机名或 IPv4 地址和某个Teredo 服务器的 UDP 端口号(通常是 3544)进行初始化配置。Teredo一开始是由微软开发的,并且有一个名为 teredo.ipv6.microsoft.com的Teredo服务器是可用的。当客户机准备获取一个地址时,它就开始资格认证过程。客户机首先从使用它的Teredo服务端口的一个本地链路IPv6 地址发送一个ICMPv6 RS 分组,代理则负责从UDP/IPv4 封装和解封IPv6。封装格式是原始指示符格式,它是两种封装格式中的一种,如下图所示。
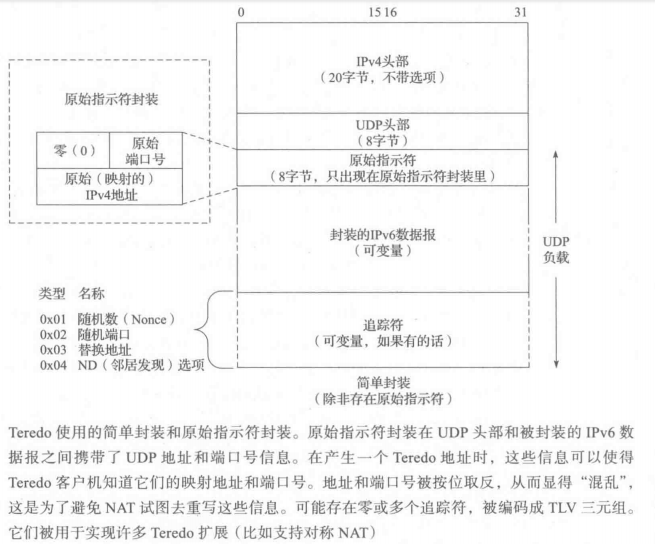
成功回应是一种 ICMPv6 RA 消息,使用上图所示的原始指示符封装格式。RA 包含一个前缀信息选项,该选项是一个有效的 Teredo前缀。原始指示符为客户机提供自身的映射地址和端口信息。RA的源地址是服务器的一个有效的本地链路IPv6地址。RA 的目的地址是客户机用作 RS 消息源地址的本地链路IPv6 地址。假设一切正常的话,客户机现在是“有资格的”,并且可以根据服务器提供的前缀和原始信息来产生它的Teredo IPv6 地址。Teredo 地址是一个 IPv6 地址,使用下图所示的格式,由多个参数构成。
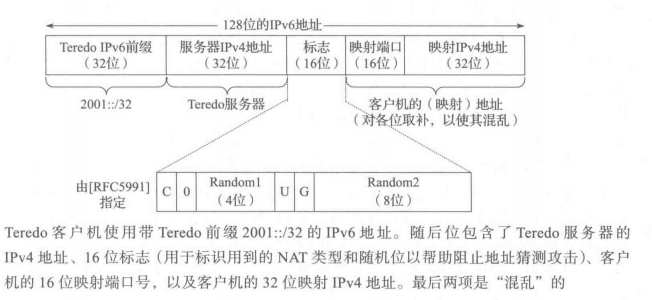
一个 Teredo 地址(见上图)包含 Teredo 前缀(2001::/32)、Teredo 服务器的 IPv4 地址、一个16位的标志(Flags)字段,然后是映射的端口号和映射的IPv4地址。最后两项是从 Teredo 服务器看到的客户机的地址信息,经常由客户机的最外层NAT决定。真实的地址和端口号信息是按位取反的,以使鲁莽的NAT不去重写它们。
16 位的标志字段用于标识在资格认证过程期间发现的 NAT 类型。一些 NAT只有在扩展得到支持时才能使用Teredo,但是大多数普通类型的家庭网络不需要扩展的支持就可以工作。
- C(cone NAT):用于标识是否碰到一个锥形NAT并给予合适的支持,但现在这种用法被弃用,这个字段应该置成0(客户机忽略这个字段,服务器检查它以寻找过时的客户机)。
- 下一个位字段置成0。
- U(Universal):留给未来使用,但现在被置成0
- G(Group):留给未来使用,但现在被置成0
- Random1和Random2:根据[RFC5991]选择Random1和Random2字段的随机值,从而使得Teredo地址很难被猜到(一种安全的措施就是尽量减少潜在攻击者的随机试探)。
一旦一个已取得资格的客户机建立了自己的 Teredo 地址,它就可以发送IPv6 流量了。一般来说,一台Teredo客户机可能想要与另一台在同一链路中的客户机、另一台在IPv4互联网中的客户机或在IPv6互联网中的一台主机进行通信。在每种情况下,Teredo会提供一些基于UDP/IPv4的邻居发现来取代IPv6。对于在同一链路中的客户机,Teredo使用一种组播地址为224.0.0.253的IPv4组播发现协议。特殊的Teredo“气泡”分组(那些不带数据负载的分组)用于判断目的地址是否在同一链路中。这些气泡以最小大小的Teredo分组出现,使用下图中的简单封装格式。
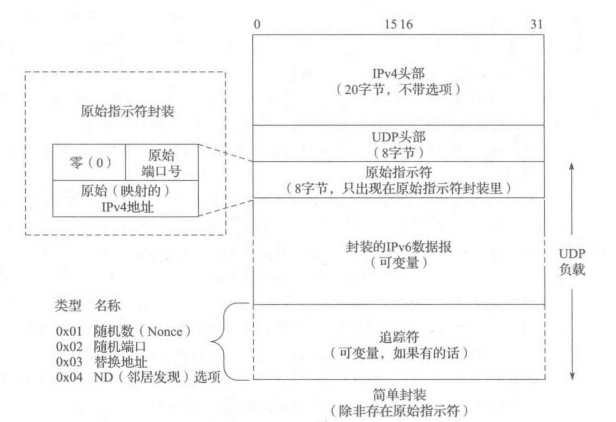
它们包含一个IPv6头部,其中目的IP 地址字段被设为这次通信的目的地。这个IPv6 分组包含一个没有负载和附加扩展(下一个头部字段被置为 0x3b,表示为空)的IPv6头部。对于在IPv4互联网中的客户机,回想一下Teredo IPv6地址包含了IPv4映射地址和端口号,因此,客户机可直接发送Teredo封装的分组到其他客户机的NAT。对于受限的 NAT,Teredo使用气泡来打孔和建立 UDP NAT 映射。
当一个已取得资格认证的客户机有一个分组要发送到一台IPv6主机(即一台没使用Teredo地址的主机)时,它首先判断是否已经知道一个负责该分组的目的地的Teredo中继器。如果知道,使用简单封装把分组发送出去。如果不知道,客户机格式化一个包含大随机数(如64比特)的ICMPv6回显报文,并经由Teredo服务器把它发送到其IPv6目的地。接收主机看到一个进入的IPv6数据报,其源地址等于客户机的Teredo地址。它产生一个回显应答,路由到最近的Teredo中继器。然后这个中继器转发回应给客户机。接收客户机再观察这个中继器的IPv4 地址,并更新缓存以指明后续的目的地为该IPv6 主机的分组应该使用这个刚确定下来的中继器。
在[RFC6081]中,Teredo 可以支持许多扩展选项,它们中的一些有助于支持 Teredo 对对称 NAT 的操作。这些扩展对协议特性进行了改动,包括以下方面:对称 NAT 支持(SNS),带 UPnP 的对称 NAT(UP),端口保留对称 NAT(PP),顺序端口对称 NAT(SP),发夹(HP),以及服务器负载减免(SLR)。除了UP和 PP两个扩展都依赖于SNS扩展以外,其他扩展都可以独立使用。通过对这些扩展进行各种组合,多种NAT类型都可得到支持,
为了实现这些扩展,一个或多个追踪符可能会出现在 Teredo 消息中。使用与ICMPv6 ND 选项一样的基本格式,追踪符被编码成一个有序的TLV 组合列表,这种格式包含一个 8 位的类型字段和一个8位的长度字段。类型字段的最高序的两个位编码指明主机不能识别追踪符类型时应怎样处理。位模式01表示主机应丢弃该分组;所有其他的都表示未知的追踪符应被忽略,而其他的则应按顺序处理。追踪符类型的值的官方列表由IANA[TTYPES]维护。当前被定义的追踪符如下表所示。
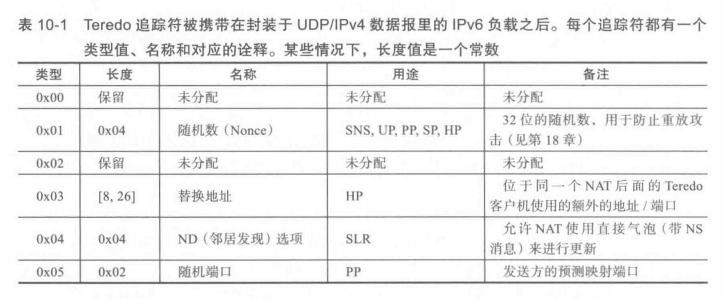
随机数追踪符包含一个32位的随机值,该值对每个消息都是唯一的。它是一共安全措施,防止重放攻击,且与HP或SNS的(IPv4端口,地址)对一起使用。每个对是6字节长,随机数追踪符可以拥有1~4个这样的对。这些对确定了一些UDP/IPv4端点——在一个NAT的同一边的其他Teredo客户机可以通过这些端点来联系发送方,同时它们可与HP扩展一起使用。
ND选项追踪符包含一个字节,用来标识TeredoDiscoverySolicitation(0x00)或TeredoDiscoveryAdvertisement(0x01)。在第一种情况下,要求接收方用一个包含第二种消息形式的直接气泡(比如,在Teredo客户机直接直接发送)来进行应答。TeredoDiscoveryAdvertisement类型就是应答。这个追踪符用于支持SLR扩展,它有效地允许NS/NA消息携带在直接气泡里,而不是需要服务器参与的间接气泡里,以更新NAT状态。最后,随机端口追踪符包含一个16位的UDP端口号,这个端口号是发送方对它被映射的端口号的最好猜测。这被PP扩展使用。
10.6——UDP-Lite
有些应用程序可以容忍在发送和接收的数据里引入的比特差错。通常,为了避免建立连接的开销或者为了使用广播或组播地址,这类应用程序会选择使用 UDP,但是 UDP 使用的校验和要么覆盖整个负载,要么就一点也没有(比如,发送方不计算校验和)。一个称为UDP-Lite或UDPLite[RFC3828]的协议通过修改传统的UDP协议,提供了部分校验和来解决这个问题。这些校验和只覆盖每个 UDP 数据报里的一部分负载。UDP-Lite有它自己的IPv4 协议和 IPv6下一个头部字段值(136),因此它实际上算是一种独立的传输协议。UDP-Lite用一个校验和覆盖范围字段取代了(冗余的)长度字段来修改UDP 头部(见下图)。

上图中的校验和覆盖范围字段是被校验和覆盖的字节数(从 UDP-Lite 头部的第 1 个字节开始)。除了特殊的值 0 以外,最小值是 8,因为 UDP-Lite 头部自身总是要求被校验和覆盖的。值 0 表示整个负载都被校验和覆盖,这就和传统 UDP 一样了。这里存在一个关于IPv6 超长数据报的问题,因为用于存放校验和覆盖范围字段的空间有限。对于这类数据报,被覆盖数最多可以是64KB或整个数据报(即校验和覆盖范围字段的值为0)。使用一些特殊的套接字API选项为应用程序指明使用UDP-Lite(IPPROTO_UDPLITE)和要求的校验和覆盖范围的数量(使用setsockopt的SOL_UDPLITE、UDPLITE_SEND_CSCOV和UDPLITE RECV_CSCOV 选项)。
10.7——IP分片
当IP 层接收到一个要发送的IP数据报时,它会判断该数据报应该从哪个本地接口发送(通过查找一个转发表)以及要求的 MTU 是多少。IP 比较外出接口的 MTU 和数据的大小,如果数据报太大则进行分片。IPv4中的分片可以在原始发送方主机和端到端路径上的任何中间路由器上进行。数据报分片自身也可被分片。IPv6中的分片只允许源主机进行分片。
当一个IP数据报被分片了,直到它到达最终目的地才会被重组。对此有两个原因,第二个要比第一个重要。第一个原因,在网络中不进行重组要比重组更能减轻路由器转发软件(或硬件)的负担。第二个原因,同一数据报的不同分片可能经由不同的路径到达相同的目的地。如果发生这种情况,路径上的路由器通常没有能力来重组原始的数据报,因为它们都只能看到所有分片的一个子集。考虑到路由器当前的性能级别,表面上,第一个原因并不是很令人信服,但是当想到大多数路由器最终无论怎样都会具备终端主机一样的功能时(如,当它们被管理或配置时),这就更不能令人信服了。所以第二个原因仍然是主要的。
10.7.1 例子:UDP/IPv4分片
下图描述了一个 3020 字节的 UDP/IPv4 数据报被分割成多个IPv4 分组的情况。
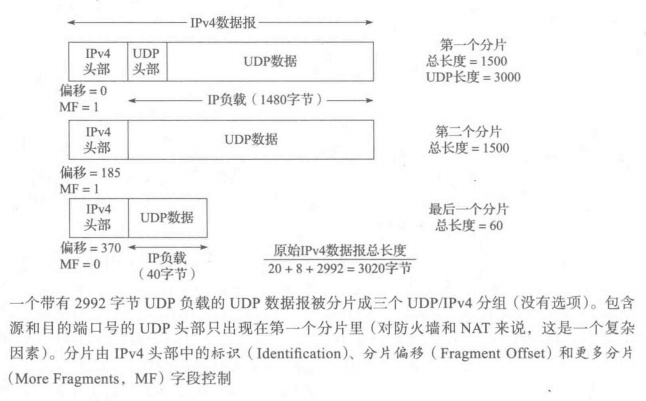
在上图中,我们看到原始UDP 数据报包含了2992字节的应用程序数据(UDP负载)和8 字节的UDP头部,结果产生一个总长度字段值为3020字节的IPv4数据报(包含了一个20 字节的IPv4头部)。当这个数据报被分片成三个分组时,产生40个额外字节(每个新生成的IPv4分片头部20字节)。因此,总发送的字节数是3060,增加的IPv4开销大概是1.3%。标识字段的值(由原始发送方设置)被复制到每个分片,同时当分片到达目的地时利用它来分成组。分片偏移字段给出该分片负载字节中的第一个字节在原始 IPv4 数据中的偏移量(以 8 字节为单位)。很明显,第一个分片的偏移总是 0。这里,我们看到第二个分片的偏移是185(185*8 = 1480)。1480 是第一个分片的大小减去 IPv4 头部的大小。类似的分析可应用在第三个分片上。最后,MF位字段指明该数据报后面是否还有更多的分组,只有最后一个分片才应置成0。当MF = 0的分片被接收到时,重组程序才能确定原始数据报的长度,它等于分片偏移字段的值(乘以8)加上IPv4总长度字段的值(减去 IPv4 头部长度)。因为每个偏移字段都是相对原始数据报的,重组进程可以处理非顺序到达的分片。当一个数据报被分片后,每个IPv4头部中的总长度字段要被修改成该分片的总长度。
10.7.2 重组超时
一个数据报的任何一个分片首先到达时,IP 层就得启动一个计时器。如果不这样做的话,不能到达的分片可能会最终导致接收方用尽缓存,留下一种攻击机会。一般的超时时间是30s或60s。收到任何一个分片时计时器就开始计时,且收到新的分片也不会被重置。因此,计时器给出了同一数据报分片之间可被分隔的最大间隔时间的限度。
10.8——采用UDP的路径MTU发现
UDP 的应用程序与路径 MTU 发现机制(PMTUD)之间的交互过程[RFC1191]。对一个像UDP这样的协议来说,调用这样协议的应用程序一般只控制输出数据报的大小,如果有方法能确定一个可以避免分片的合适的数据报大小,那么这会是很有用的。传统的 PMTUD 使用ICMP PTB 消息来获得一个最大分组大小,其沿着一条路由路径传输不会引入分片。典型地,这些消息在 UDP 层之下被处理,对应用程序不可见,因此,它们要么是一个API调用,被应用程序用于获取对路径(与每个路径的目的地都已通信过)的MTU大小的当前最好的估计,要么是不被应用程序所知的、能独立地进行PMTUD 的 IP 层。IP 层经常基于每个目的地址缓存一个 PMTUD 信息,并且当没有更新时就让它超时。
10.9——IP分片和ARP/ND之间的交互
使用 UDP,我们可以看到诱导的 IP 分片和典型的 ARP 实现之间的关系。回想一下,ARP 是用于将 IP 层地址映射到同一个 IPv4 子网里的相应的 MAC 层地址。我们关心的问题包括,什么时候发送多个分片?应该产生多少条ARP消息?以及搁置中的ARP请求/应答在完成之前会有多少个分片要处理?(IPv6 ND也有类似的问题。)我们用以下两条命令来查看答案,使用 1500 字节 MTU 返回到我们的主机和 LAN:
Linux% sock -u -i -n1 -w8192 10.0.0.20 echo
Linux% sock -u -i -n1 -w8192 10.0.0.3 echo
这些参数使得我们的 sock 程序产生了一个带有 8192 字节用户数据的 UDP 数据报。在一个使用 1500 字节 MTU 大小的以太网中,我们料想到这将会产生6个分片。我们还确保了在运行这个程序之前 ARP 缓存是空的,所以在任何分片被发送之前,肯定会互相发送一个ARP 请求和应答(见下图。为了简洁,某些行已被整理)。
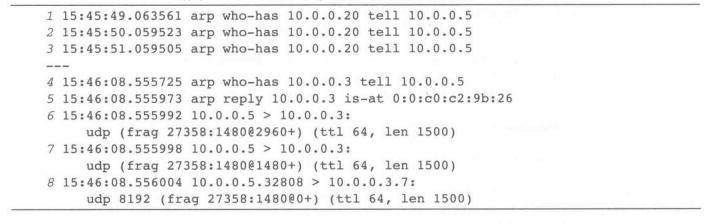
在这个实验里,我们正好知道地址10.0.0.20没有分配给一台运行中的主机,因此我们应该收不到应答。在上图的第一部分(分组 1 ~ 3),我们观察到三个ARP 请求被将近1s 的时间分开。三个请求被发送后,没有主机应答,因此 ARP 请求者放弃了。下一种情况,大概 250μs后有一个 ARP 应答被接收到,同时大约 20μs 后一个分片被发送。在这之后,剩下的分片紧挨着一起被发送出去,每个之间大约有6μs的间隔。回想一下,在这个系统里
(Linux),最后一个分片首先被发送。
注意 历史上,分片和 ARP之间的交互一直都是有问题的。例如,在某些情况下每一个分片都得发送一个ARP请求,而在某些情况下只有分片中的一个要排队等候ARP应答(从而使数据报丢失了,因为除了一个分片外的所有分片都被丢弃了)。第一个问题在[RFC1122]里被解决了,那需要一种实现来阻止这种ARP洪泛。建议的最大速率是每秒一个。第二个问题也在[RFC1122]里被讨论,但它只指出,对每一个分组集,其中的分组的目的地是相同的未解析的IP 地址,链路层“应该保存(而不是丢弃)其中的至少一个(最新的)分组”。这种方法会引起不必要的分组丢失,不过已经在具体实现里解决了,方法是给那些ARP请求还在挂起的分组提供一个更大的队列。
10.10——最大 UDP 数据报长度
理论上,一个 IPv4 数据报的最大长度是 65 535 字节,这由 IPv4 头部的 16 位总长度字段决定。除去20字节不带选项的IPv4头部和一个8字节的UDP头部,就剩下最大 65 507 字节留给一个 UDP 数据报的用户数据。对于 IPv6,假设没使用超长数据报,16位负载长度字段可允许655 527 字节的有效UDP负载(65 535字节的IPv6 负载中的8 字节被用于UDP头部)。然而,有两个原因使得这些大小的满额数据报不能被端到端投递。第一,系统的本地协议实现可能有一些限制。第二,接收应用程序可能没准备好去处理这么大的数据报。
10.10.1 实现限制
协议实现给应用程序提供一个API以让它选择一些默认缓存大小来进行发送和接收。某些实现提供的默认值小于最大IP数据报大小,实际上有些还不支持发送大于几十KB的数据报(尽管这个问题不多见)。
API套接字[UNP3]提供一组函数让应用程序能够调用以设置或查询接收和发送缓存的大小。对于一个UDP套接字,这个大小与应用程序可读或可写的最大UDP数据报大小直接关联。典型的默认值是 8192 字节或 65 535 字节,但一般可以调用 setsocketopt()API 来设置更大的值。
我们提到过一台主机重组分片时要提供足够的缓存来接收至少一个576 字节的IPv4数据报。许多UDP应用程序被设计成限制数据报的大小在512字节或更小以下(这使得IPv4数据报小于576字节)。对UDP数据报的大小使用了这些限制的例子包括DNS和 DHCP。
10.10.2 数据报截断
UDP/IP能发送和接收一个给定大小的(大)数据报并不意味着接收应用程序就能够读取这种大小的数据报。UDP 编程接口允许应用程序指定每次一个网络的读操作完成时返回的最大字节数。如果接收的数据报超过这个指定大小会发生什么?
大多数情况下,这个问题的答案是 API 截断数据报,丢弃这个数据报里超过接收应用程序指定字节数的任何超额数据。然而,每种实现的具体操作是不同的。一些系统把这些数据报的超额数据放到后续的读操作中,另一些则通知调用者有多少数据被截断了(或有些情况是通知有一些数据被截断但不知具体是多少)。
在我们讨论 TCP 时会发现,它给应用程序提供连续的字节流,没有任何消息边界。因此,应用程序可得到它请求的任意大小的数据量,可供给充足的数据(如果不行,通常可以等待)。
10.11——UDP 服务器的设计
在典型的客户机/服务端场景中,一个客户机启动,立即与一台服务器通信,然后就完成了。而另一方面,服务器启动然后进入睡眠,等待一个客户机请求的到达。它们在客户机数据报到达时被唤醒,这经常需要服务器来评估这个请求以及可能要进行更进一步的处理。这里我们关注的不是客户机和服务器的程序编写方面([UNP3]覆盖了所有这些细节),而是对使用UDP的服务器的设计和实现有影响的UDP协议特性。虽然我们描述的特性有点依赖被使用的 UDP实现,但是这些特性对大多数实现来说是共同的。
10.11.1 IP地址和 UDP 端口号
到达 UDP 服务器的是来自客户机的 UDP 数据报。IP 头部包含了源和目的 IP 地址,UDP头部包含源和目的UDP端口号。当一个应用程序接收到一个UDP消息时,它的IP和UDP头部已经被剥掉;如果想要给予回复,应用程序必须由操作系统以其他方式告知是谁(源IP地址和端口号)发送的消息。这个特点允许UDP 服务器去处理多个客户机。
有些服务器需要知道数据报是发送给谁的,即目的IP 地址。这看起来似乎很明显,服务器不用查看接收到的数据报即可马上知道这些信息,然而通常情况并非如此。比如,因为多址、IP 地址别名,以及 IPv6 多范围使用,一台主机可能有多个IP 地址,单个服务器可使用它们中的任何一个来接收进入的数据报(实际情况通常是这样的)。任何想要根据客户机选择的目的IP 地址来有分别地执行任务的服务器都需要得到目的IP 地址信息。另外,如果目的地址是广播或组播的(如,主机需求(Host Requirements)RFC[RFC1122]指出 TFTP服务器应忽略接收到的发送给一个广播地址的数据报),那么有些服务则可能会有不同的回应。
注意 DNS服务器是对目的IP地址敏感的一种服务器类型。它会使用这个信息来对它返回的地址映射表排列特定的次序。
这里得到的教训是,即使一个 API 可以得到传输层数据报里的所有数据,但是额外的来自各层的信息(一般是地址信息)也可能是使服务器更有效地进行操作所需要的。当然,这个问题并非 UDP 独有
设计同时使用IPv4 和 IPv6 的 UDP 服务器必然要考虑到这两种地址类型有明显不同的长度以及需要不同的数据结构。另外,用IPv6地址来给IPv4编码的交互操作机制可能允许使用 IPv6 套接字同时处理 IPv4 和 IPv6 寻址。更多细节见[UNP3]。
10.11.2 限制本地IP地址
大多数UDP服务器在创建 UDP 端点时都使其本地IP 地址具有通配符(wildcard)的特点。也就是说如果进入的UDP数据报的目的地是一个服务器的端口,那么在该服务器上的任何本地接口均可接收到它(任何在本地机器中使用的IP地址,包含本地回路地址)。
大多数 UDP 服务器在创建 UDP 端点时都使其本地 IP 地址具有通配符(wildcard)的特点。也就是说如果进入的 UDP 数据报的目的地是一个服务器的端口,那么在该服务器上的任何本地接口均可接收到它(任何在本地机器中使用的 IP 地址,包含本地回路地址)。例如,我们在端口号 7777 启动一个 IPv4 UDP 服务器:
Linux% sock -u -s 7777
然后我们用netstat命令来查看端点的状态(见下图)

输出中我们删除了几行,只留下我们感兴趣的。-l 选项输出所有监听套接字(服务器)。–udp 选项只输出与 UDP 协议相关的数据。-n 选项指明只打印 IP 地址,而非全扩展主机名。
本地地址被打印成*:7777,这里的星号代表本地IP 地址已被通配符化。当服务器建立它的端点,它可以指定主机的一个本地 IP 地址,包括一个广播地址,作为该端点的本地IP地址。在这些情况里,只有目的 IP 地址与指定的本地地址匹配时,进入的 UDP 数据报才会被转到这个端点。使用我们的 sock 程序,如果我们在端口号前指定一个IP 地址,它就成为了这个端点的本地地址。例如,命令
Linux% sock -u -s 127.0.0.1 7777
限制了服务器只接收到达本地回路接口(127.0.0.1)的数据报,这些数据报只能在同一台主机生成。下图显示了本例的netstat输出。

如果我们尝试在同一以太网的主机上发送一个数据报到这个服务器,一个ICMPv4 端口不可到达消息就会被返回,发送应用程序会接收到一个错误。服务器看不到这个数据报。
10.11.3 使用多地址
在同一个端口号开启几个不同的服务器,每个服务器使用一个不同的本地IP地址,这是可能的。然而,通常应用程序应该告诉系统允许这样重用相同的端口。
注意 使用套接字API时,SO_REUSEADDR套接字选项必须指定。在我们的sock 程序里通过指明-A选项即可。
即使我们只有一个真实的网络接口,我们还是可以建立额外的IP 地址来供使用。这里,我们的主机有一个原生IPv4 地址 10.0.0.30,而我们将赋予它两个额外的地址:
Linux% ip addr add 10.0.2.13 scope host dev eth0
Linux% ip addr add 10.0.2.14 scope host dev eth0
现在我们的主机有 4 个单播 IPv4 地址:它的原生地址,我们刚才加的那两个,以及它的本地回路地址。我们可以使用 sock 程序在同一个 UDP 端口(8888)开启三个不同的 UDP实例:
Linux% sock -u -s -A 10.0.2.13 8888
Linux% sock -u -s -A 10.0.2.14 8888
Linux% sock -u -s -A 8888
服务器必须使用-A 选项来启动,告诉系统允许重用相同的地址信息。下图的netstat 输出显示了服务器正在监听的地址和端口号。

在这个场景里,只有那些目的地是 10.0.0.30、直接广播地址(如,10.255.255.255)、受限广播地址(255.255.255.255)或本地回路地址(127.0.0.1)的IPv4数据报才能到达带通配符本地地址的那个服务器,因为那些受限的服务器覆盖了所有其他的可能情况。
当有带通配符地址的端点存在时,就暗示着一种优先级。带指定IP 地址的端点,会越过通配符,当这个指定的 IP与目的 IP 地址匹配时,它总是被优先选择。而只有当匹配不成功时才会使用带通配符的端点。
10.11.4 限制远端 IP 地址
在前面我们展示的所有 netstat 输出中,远端IP 地址(比如,不是正在运行的服务器本地的地址)和远端端口号被显示为0.0.0.0:*,表示端点将会接收来自任何IPv4地址和任何端口号的进入UDP数据报。然而,可以选择限制远端地址,也就是说端点只接收来自指定IPv4地址和端口号的UDP数据报。注意,一旦服务器收到了某个客户机的流量,这些限制就会被加上,以过滤掉来自其他客户机的额外流量。在我们的sock程序中使用-f选项来指定远端 IPv4 地址和端口号:
Linux% sock -u -s -f 10.0.0.14.4444 5555
这样就设置了远端IPv4地址为10.0.0.14以及远端端口号为4444。服务器端口为5555。如果运行 netstat,我们可以看到本地地址也被设置,尽管我们没有明确指定它(见下图)。

这是指定远端IP 地址和远端端口的一个典型的副作用:如果指定远端地址而没选择本地地址的话,那么本地地址会被自动选择。它的值是由 IP 路由选择的能到达那个指定的远端IP地址的网络接口的地址。确实,在这个例子里,在这个以太网里能连接到那个远端地址的主要IPv4地址就是10.0.0.30。注意这样得到的端点和限制远端地址的一个结果是,现在清单里的状态(State)栏指示连接是已建立的(ESTABLISHED)。
下表总结了UDP服务器可建立的三种地址绑定方式。

在所有情况里,local_port是服务器的端口,local_IP必须是本地分配的IP地址中的一个。表中三行的顺序就是UDP模块在尝试决定哪个本地端点去接收进入数据报时使用的顺序。最具体的绑定方式(第一行)首先被尝试,最不具体的(最后一行,两个IP地址都是通配符)被最后尝试。
10.11.5 每端口多服务器的使用
尽管RFC里没有说明,但默认情况下最常见的是:对一给定的地址族(即IPv4或IPv6),同一时间只允许一个应用程序端点与任何一个(本地 IP 地址,UDP 端口号)对关联。当一个UDP数据报到达其目的IP地址的那台主机的目的活动端口时,它的一个拷贝被传送给这个唯一的端点(如,一个正在监听的应用程序)。如前所示,这个端点的IP地址可以是通配符,但是只能是唯一一个应用程序可以接收这些指定地址的数据报。如果我们试图去启动另一个使用相同地址族、有相同通配符本地地址和相同端口的服务器时,则是行不通的:
Linux% sock -u -s 12.46.129.3 8888 &
Linux% sock -u -s 12.46.129.3 8888
can't bind local address:Address already in use
为了支持组播,可允许多个端点使用相同的(本地IP 址,UDP端口号)对,但是应用程序一般要告诉 API 允许这样做(也就是说,像前面指出的,用-A 选项来指定SO_REUSEADDR 套接字选项)。
注意 4.4BSD 要求应用程序设置不同的套接字选项(SO_REUSEPORT)来允许多端点共享同一端口。此外,每个端点必须设置这个选项,包括第一个使用这个端口的端点。
当一个 UDP数据报到达的目的 IP 地址是一个广播或组播地址,同时这个目的 IP 地址和端口号有多个端点时,那么每个端点都会收到这个数据报的一个拷贝(端点的本地IP地址可以是能匹配任何目的IP地址的通配符)。然而,如果一个UDP数据报到达其目的IP地址是一个单播地址(即一个普通的地址)时,那么只有唯一的端点会收到这个数据报的一个拷贝。至于哪个端点会收到这个单播数据报,这是依赖于具体实现的,但是这种策略有助于允许多线程和多进程服务器避免在同一进入请求上被多次调用。
10.11.6 跨越地址族:IPv4 和IPv6
编写不只跨越协议(例如 TCP 和 UDP)而且跨越地址族的服务器是可能的。即,我们可以编写服务器,既可对 IPv4 也可对 IPv6 的进入请求进行回复。这整个看起来好像是简单明了的(IPv6 地址只是同一主机上的 128 位长的 IP 地址而已),但是关于共享端口空间会有些小问题。对于某些系统,UDP(和 TCP)的 IPv6 和 IPv4之间的端口空间是共享的。这就是说如果一个服务绑定在一个使用IPv4的 UDP端口上,它同时也被分配给在IPv6空间里的同一个端口(反之亦然),使得其他服务不能使用该端口(除非如前所述,SO_REUSEADDR套接字选项被使用)。更进一步,因为 IPv6 地址能以一种互操作的方式来对IPv4 地址进行编码,所以 IPv6 里的通配符绑定方式可能会接收到进入的 IPv4 流量。
注意 情况要针对具体实现。在Linux 里,所有端口空间都是共享的,所有的通配符 IPv6 绑定意味着对应的IPv4 绑定。在 FreeBSD 里,IPV6_V6ONLY 套接字选项可用于保证只在IPv6空间进行绑定。程序员应该查阅其支持的那个操作环境的IPv6的套接字接口。[RFC3493]描述了C语言绑定。
10.11.7 流量和拥塞控制的缺失
大多数 UDP 服务器是迭代(iterative)服务器。也就是说单个服务器线程(或进程)在单个 UDP 端口(如,服务器的知名端口)处理所有客户请求。通常一个应用程序使用的每个UDP 端口均有一个大小有限的队列与之对应。也就是说来自不同客户机的、几乎同时到达的请求会被 UDP 自动排入队列里。接收到的UDP数据报以它们到达的顺序(也就是说,FCFS——先到先服务)被传送给应用程序(当它请求下一个时)。
然而,这个队列有可能会溢出,使得UDP实现丢弃进入的数据报。因为UDP不提供流量控制(flow control)(也就是说,让服务器告诉客户机减慢速率是不可能的),即使只服务于一个客户,这样的事情也会发生。因为UDP 是一个无连接协议,自身没有可靠机制,应用程序无法得知什么时候 UDP输入队列产生了溢出。超额的数据报仅仅被UDP 丢弃而已。
这样的事实引起了另一个问题,发送方和接收方之间的IP 路由器(在网络中间)里也有队列。当这些队列变满时,流量可能会被丢弃,多多少少与UDP 的输入队列类似。当这种情况出现时,网络被称之为拥塞。拥塞是不希望的,因为它会影响所有流量经过拥塞发生地点的网络用户,这与前面提到的 UDP输入情况不一样,那里只有单个应用程序服务受影响。UDP对拥塞提出了特别的关注,因为当网络正在拥塞时,不能通知它降低发送率。(即使能被告知,也没有机制来降低。)因此,这被称为拥塞控制缺失。拥塞控制是一个复杂的课题,目前仍是一个热门研究领域。
10.12——UDP/IPv4和UDP/IPv6数据报的转换
对于 UDP/IPv4数据报,UDP 头部的校验和字段允许为0(不计算),而UDP/IPv6则不然。后果是,校验和为0的完整数据报到来时,从IPv4转换到IPv6产生的结果是,生成一个带有完整进行了计算的伪头部校验和的UDP/IPv6数据报,或者是丢弃了到来的数据报。转换器应提供一个配置选项来选择取舍哪种情况,因为产生这些校验和的开销可能是不能接受的。如果使用了非校验和中立的地址映射的话,包含非零校验和的分组在任一边被转换时都要求更新校验和。
分片数据报出现另一个挑战。对于无状态的转换器,被分片的带有零校验和的UDP/IPv4数据报不能转换,因为没有合适的 UDP/IPv6可以计算。这些数据报被丢弃。有状态的转换器(即 NAT64)可以重组许多分片和计算要求的校验和。被分片的带有已计算校验和的 UDP/IP数据报在转换的两边都被当作普通分片处理。大UDP/IPv4数据报需要分片以适合转换后的 IPv6 最小 MTU,它们同样被当作普通 IPv4 数据报处理(即它们按需求分片)。
10.13——互联网中的 UDP
如果试图描述互联网上的 UDP 流量的特征,我们会发现,要得到有用、公众可用的数据是有些困难的,同时各个站点因协议引起的流量负载的崩溃也不尽一样。也就是说,像[FKMC03]这样的研究发现,UDP占据了观察到的互联网流量的10%~40%,同时随着点对点应用数量的增加,UDP的使用也正在上升,尽管TCP流量仍在分组和字节量方面占据了统治地位。
在[SMC02]中,发现互联网分片流量大多数都是UDP的(分片流量的68.3%是UDP的),尽管总体流量中只有极少是分片的(大约分组的 0.3%,字节的0.8%)。该作者指出最常见的被分片的流量类型是基于UDP的多媒体流量(55%;微软的媒体播放器占了其中的一半),以及像出现在VPN隧道里的封装/隧道流量(大约22%)。此外,大约10%的这些分片是反序的(reverse-order)(我们在之前的例子里说过最后一个IP分片要优先第一个被发送),最常见的分片大小是1500字节(75%),然后是1484字节(18%)和1492字节(1%)。
分片出现的原因来自两个因素:粗糙封装和路径MTU发现的缺失,以及采用可能使用大消息的应用程序。前者与经过多个协议层时的多层封装有关,这增加了额外的头部,使得原始适合 1500字节 MTU(最常见的大小)的 IP 分组不再装得下(如,要经过 VPN 隧道的应用程序流量)。第二个因素在于使用大分组的应用程序(如视频应用程序)最终要分片。[SMC02]研究里的一个奇怪和不幸的发现是,大量的IPv4 DF位字段是启用的UDP分组
我们在之前的例子里说过最后一个IP分片要优先第一个被发送),最常见的分片大小是1500字节(75%),然后是1484字节(18%)和1492字节(1%)。
分片出现的原因来自两个因素:粗糙封装和路径MTU发现的缺失,以及采用可能使用大消息的应用程序。前者与经过多个协议层时的多层封装有关,这增加了额外的头部,使得原始适合 1500字节 MTU(最常见的大小)的 IP 分组不再装得下(如,要经过 VPN 隧道的应用程序流量)。第二个因素在于使用大分组的应用程序(如视频应用程序)最终要分片。[SMC02]研究里的一个奇怪和不幸的发现是,大量的IPv4 DF位字段是启用的UDP分组
(可能要尝试进行 PMTU 发现)被封装在没启用该位字段的 UDP 分组里(从而破坏了该尝试,却使相应的应用程序对此事实一无所知)。