window 显示驱动开发-将虚拟地址映射到内存段(二)
在将虚拟地址映射到段的一部分之前,视频内存管理器调用显示微型端口驱动程序的 DxgkDdiAcquireSwizzlingRange 函数,以便驱动程序可以设置用于访问可能重排的分配位的光圈。 驱动程序既不能将偏移量更改为访问分配的 PCI 光圈,也不能更改分配在光圈中占用的空间量。 例如,如果驱动程序无法在给定这些约束 (的情况下使分配 CPU 可访问,则硬件可能耗尽) 不显眼的光圈,则视频内存管理器会将分配逐出到系统内存,并允许应用程序访问其中的位。
如果在用户模式显示驱动程序调用 pfnLockCb 函数以请求直接访问内存时,以前创建的分配的内容位于系统内存中,则视频内存管理器会将系统内存缓冲区返回到用户模式显示驱动程序,并且显示微型端口驱动程序不涉及访问分配。 因此,显示微型端口驱动程序不会修改分配的内容,并且保持为未重排格式。 这意味着,当从视频内存中逐出 CPU 可访问的分配时,显示微型端口驱动程序必须取消重排分配,以便应用程序可以直接访问生成的系统内存位。
如果逐出与当前映射用于直接应用程序访问的分配关联的 GPU 资源,则分配的内容将传输到系统内存,以便应用程序可以继续访问同一虚拟地址但不同的物理介质上的内容。 为了设置传输,视频内存管理器调用显示微型端口驱动程序的 DxgkDdiBuildPagingBuffer 函数来创建分页缓冲区,GPU 计划程序调用驱动程序的 DxgkDdiSubmitCommand 函数将分页缓冲区排队到 GPU 执行单元。 特定于硬件的传输命令位于分页缓冲区中。 有关详细信息,请参阅 提交命令缓冲区。 视频内存管理器可确保视频到系统内存的转换对应用程序不可见。 但是,驱动程序必须确保通过 PCI 光圈对分配的字节排序与逐出分配时分配的字节顺序完全匹配。
对于光圈空间段,分配的基础位已位于系统内存中,因此无需传输 (逐出过程中取消重排) 数据。 因此,如果应用程序直接访问位于光圈空间段中的 CPU 可访问分配,则无法重排该分配。
如果某个表面可由应用程序直接通过 CPU 访问,但将在光圈空间段中重排,则显示驱动程序应将图面实现为两个不同的分配。 当用户模式显示驱动程序创建此类图面时,它可以调用 pfnAllocateCb 函数,并将 D3DDDICB_ALLOCATE 结构的 NumAllocations 成员设置为 2,并将 D3DDDICB_ALLOCATE 的pAllocationInfo 数组中D3DDDI_ALLOCATIONINFO结构的 pPrivateDriverData 成员设置为指向有关分配 (的私有数据,例如其重排格式和未重排格式) 。 GPU 将使用的分配包含重排格式的位,应用程序将访问的分配包含未重排格式的位。 视频内存管理器调用显示微型端口驱动程序的 DxgkDdiCreateAllocation 函数来创建分配。 对于从用户模式显示驱动程序传递的每个分配) ,显示微型端口驱动程序解释DXGK_ALLOCATIONINFO结构的 pPrivateDriverData 成员中的专用数据 (。 视频内存管理器不知道分配的格式;它只是为分配分配分配特定大小和对齐方式的内存块。 调用用户模式显示驱动程序的 Lock 函数以锁定图面进行处理会导致以下操作:
- 用户模式显示驱动程序调用 pfnRenderCb 函数,将命令缓冲区中的取消重排操作提交到 Direct3D 运行时和显示微型端口驱动程序。
- 用户模式显示驱动程序调用 pfnLockCb 函数来锁定未重排的分配。 请注意,用户模式显示驱动程序不得在 D3DDDICB_LOCK 结构的 Flags 成员中设置D3DDDILOCKCB_DONOTWAIT标志。
- pfnLockCb 函数将等待传输 (在分配之间展开) 。
- pfnLockCb 函数请求显示微型端口驱动程序获取未重排分配的虚拟地址,并将虚拟地址返回到 D3DDDICB_LOCKpData 成员中的用户模式显示驱动程序。
- 用户模式显示驱动程序将未重排分配的虚拟地址返回到 D3DDDIARG_LOCK 的 pSurfData 成员中的应用程序。
下图演示了如何将虚拟地址映射到线性光圈空间段的基础页面。
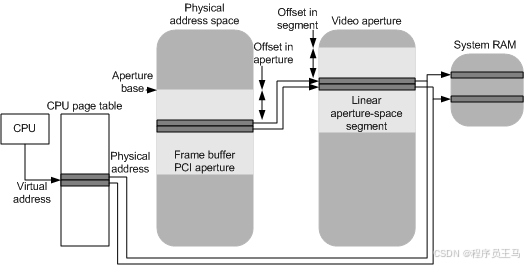
1. 重排分配与 CPU 访问的冲突
问题背景:
某些图形分配(如纹理)可能被硬件“重排”(swizzled)以优化 GPU 访问性能,但这种格式对 CPU 不友好。如果应用程序需要直接通过 CPU 访问这些分配(如 Lock 操作),则需要取消重排(unswizzle)。
约束条件:
- 显示微型端口驱动程序(Display Miniport Driver)在 DxgkDdiAcquireSwizzlingRange 中不能修改 PCI 光圈的偏移或大小。
- 若硬件无法满足 CPU 访问的约束(如光圈空间不足),视频内存管理器(VidMM)会将分配逐出(evict)到系统内存,并取消重排。
2. 系统内存中的分配访问
直接访问系统内存:如果分配已被逐出到系统内存,用户模式显示驱动(UMD)通过 pfnLockCb 直接获取系统内存指针,微型端口驱动不参与,内容保持未重排格式。
关键要求:在逐出时,驱动程序必须确保取消重排,使系统内存中的数据是 CPU 可读的线性格式。
3. GPU 资源逐出与分页机制
动态逐出处理:
若 GPU 正在使用的分配被逐出(如因内存压力),VidMM 会通过以下步骤透明迁移数据:
- 调用 DxgkDdiBuildPagingBuffer 创建分页缓冲区(包含硬件特定的传输命令)。
- 通过 DxgkDdiSubmitCommand 提交到 GPU 执行。
- 确保迁移对应用程序透明(虚拟地址不变,物理介质变化)。
数据一致性:驱动程序必须保证 PCI 光圈中的字节顺序与逐出时的系统内存完全一致。
4. 光圈空间段的特殊处理
无重排需求:光圈空间段(Aperture Segment)的分配本身位于系统内存,无需重排。若应用程序直接访问此类分配,驱动程序必须禁止重排。
5. 双分配策略(重排与非重排共存)
适用场景:
若一个表面需要同时满足:
- GPU 访问(重排格式优化性能)。
- CPU 访问(未重排格式保证兼容性)。
实现方式:
- UMD 调用 pfnAllocateCb 创建 两个分配(NumAllocations=2),分别存储重排和未重排数据。
- 通过 pPrivateDriverData 传递格式信息(如重排参数)。
- 微型端口驱动在 DxgkDdiCreateAllocation 中解析私有数据,管理两种格式。
Lock 操作流程:
- UMD 提交命令缓冲区(pfnRenderCb)取消重排(GPU 执行格式转换)。
- 调用 pfnLockCb 锁定未重排的分配(等待转换完成)。
- 返回未重排分配的虚拟地址给应用程序。
六、关键驱动责任
- 格式转换:在逐出或 Lock 时,确保重排数据转换为线性格式。
- 双分配管理:维护重排/未重排副本的一致性(如通过 GPU 命令同步)。
- 透明性:确保应用程序无感知(虚拟地址不变,物理介质可能变化)。
总结
这段描述揭示了 WDDM 如何平衡 GPU 性能(重排)与 CPU 可访问性,通过动态逐出、分页缓冲区、双分配等机制实现高效内存管理。驱动程序需正确处理重排/取消重排、分页操作及多副本同步,以满足图形和计算应用的多样化需求。