《Python星球日记》 第52天:反向传播与优化器
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
目录
- 一、引言
- 二、反向传播算法原理简述
- 1. 什么是反向传播?
- 2. 从数学角度理解反向传播
- 3. 反向传播的计算效率
- 三、梯度下降法回顾与改进
- 1. 标准梯度下降法(BGD)
- 2. 随机梯度下降(SGD)
- 3. 小批量梯度下降(Mini-batch SGD)
- 4. 优化算法的进阶版本
- (1) 动量法 (Momentum)
- (2) RMSProp
- (3) Adam优化器
- 四、损失函数详解
- 1. 损失函数的作用
- 2. 均方误差损失(MSE)
- 3. 交叉熵损失(Cross Entropy)
- 4. 损失函数选择指南
- 五、权重初始化与正则化
- 1. 权重初始化的重要性
- 2. 常见的初始化方法
- (1) 零初始化
- (2) 随机初始化
- (3) Xavier/Glorot初始化
- (4) He初始化
- 3. 正则化技术
- (1) L1正则化(Lasso)
- (2) L2正则化(Ridge)
- 六、代码练习:手动实现前向传播与梯度下降过程
- 1. 简单神经网络结构定义
- 2. 前向传播实现
- 3. 计算损失函数
- 4. 反向传播实现
- 5. 使用梯度下降更新参数
- 6. 训练神经网络
- 7. 完整示例:训练XOR问题
- 8. 改进版本:加入动量优化器
- 9. 分析反向传播过程的关键点
- 七、总结与进阶方向
- 1. 今日要点回顾
- 2. 进阶学习方向
- 3. 实践建议
👋 专栏介绍: Python星球日记专栏介绍(持续更新ing)
✅ 上一篇: 《Python星球日记》 第51天:神经网络基础
欢迎来到Python星球的第52天!🪐
一、引言
在昨天的学习中,我们了解了神经网络的基础知识。今天,我们将深入探索神经网络的学习机制——反向传播算法,以及多种优化方法,这些都是深度学习的核心概念。无论是调整网络参数还是提升模型性能,这些知识都至关重要。
二、反向传播算法原理简述
1. 什么是反向传播?
反向传播(Backpropagation)是神经网络学习的核心算法。简单来说,它是一种有效计算损失函数对网络参数梯度的方法,让网络能够通过不断调整参数来"学习"。
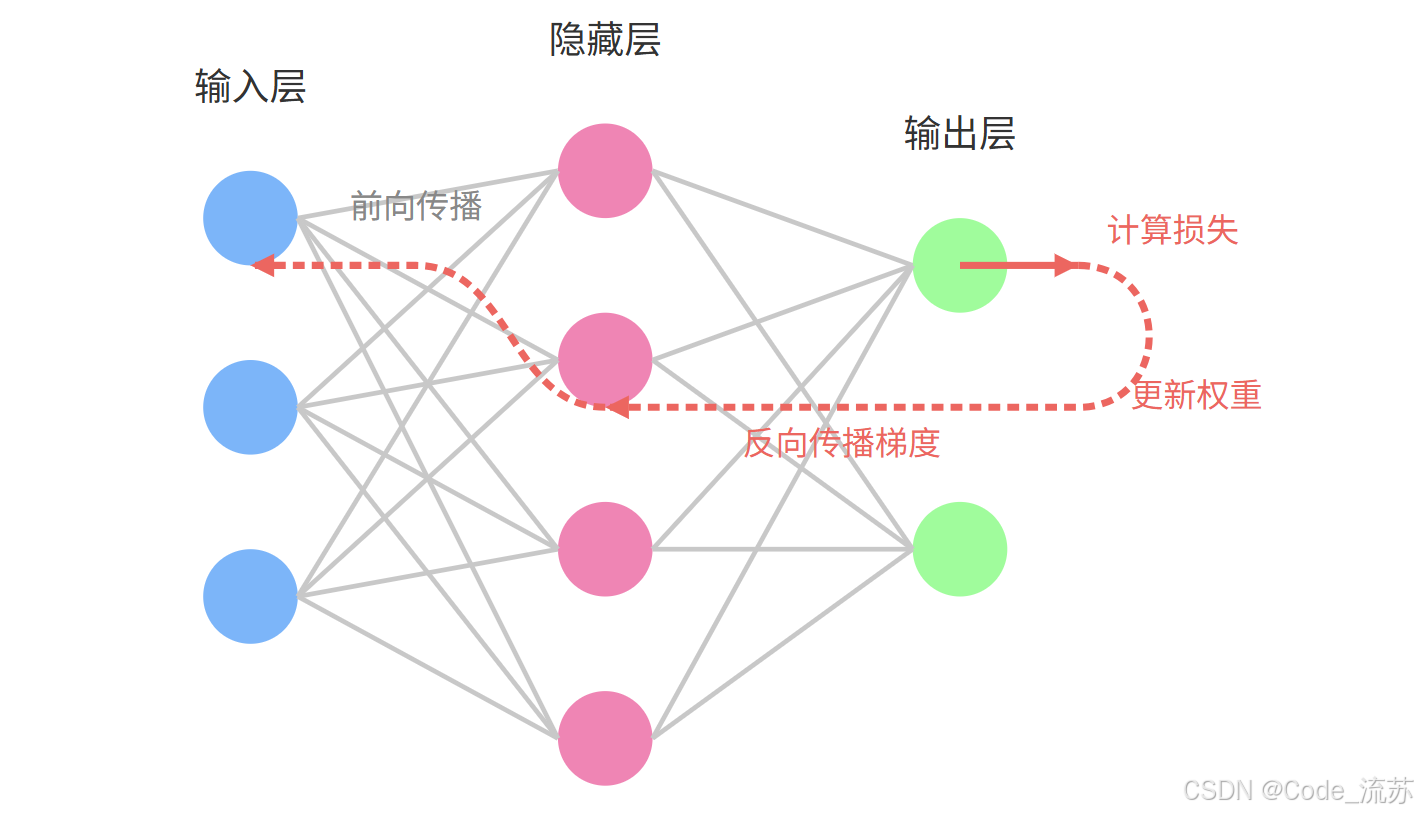
反向传播的基本思想是:
- 首先进行前向传播计算预测值
- 计算预测值与真实值的误差
- 将误差从输出层反向传递回前面的层
- 利用链式法则计算每个参数的梯度
- 根据梯度更新参数
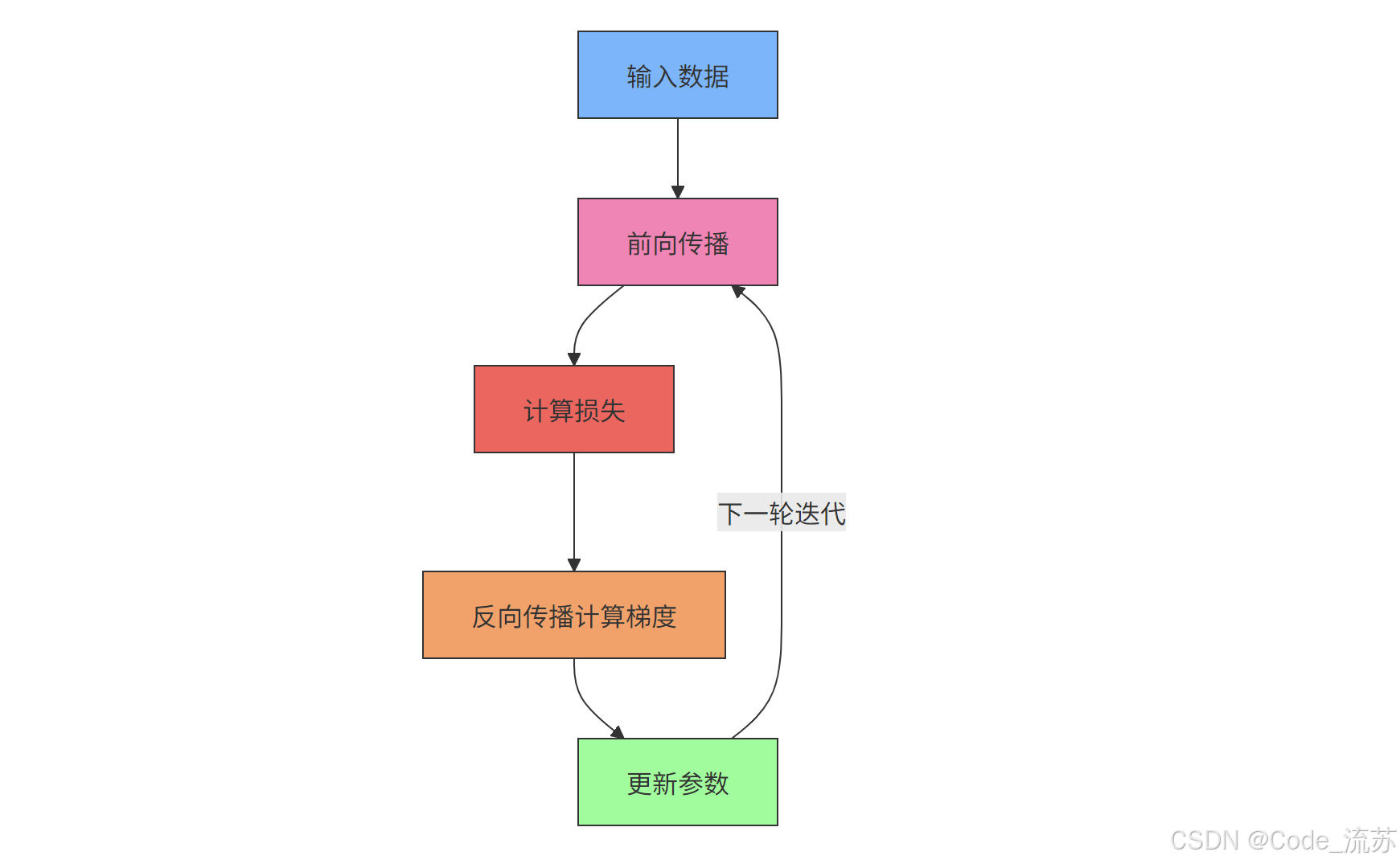
2. 从数学角度理解反向传播
反向传播算法使用链式法则(Chain Rule)来计算梯度。假设我们有一个有两层的神经网络:
- 输入
x - 隐藏层的激活值
h = f(Wx + b) - 输出
y = g(Vh + c) - 损失函数
L
计算参数 W 的梯度时,需要使用链式法则:
∂L/∂W = ∂L/∂y * ∂y/∂h * ∂h/∂W
这就是梯度如何"反向流动"的数学表达。我们从损失函数开始,逐步计算到每个参数。
3. 反向传播的计算效率
反向传播的巧妙之处在于它使用了动态规划的思想,避免了重复计算。在计算前层参数的梯度时,可以重用后层已经计算好的梯度值,大大提高了计算效率。
三、梯度下降法回顾与改进
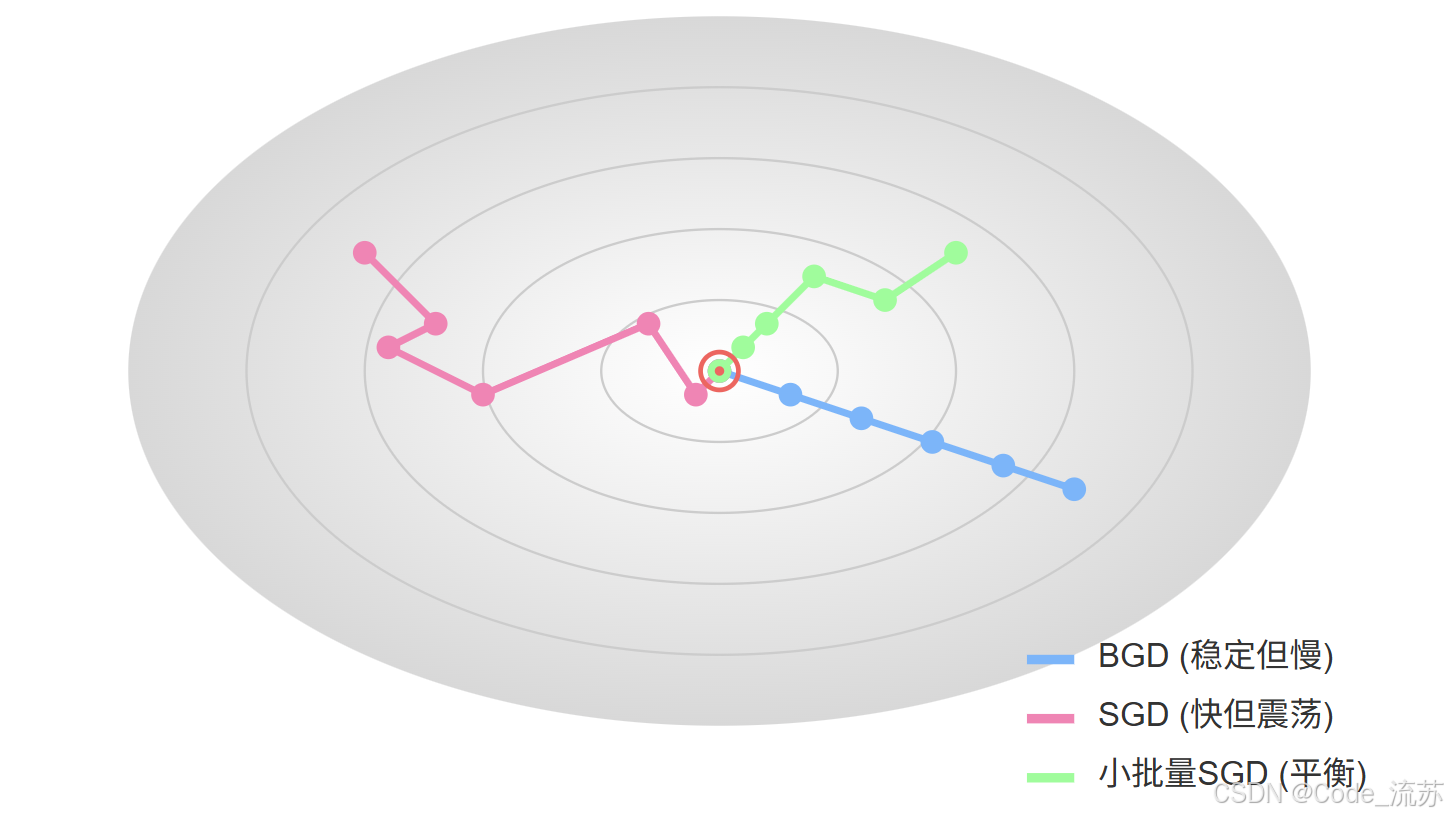
1. 标准梯度下降法(BGD)
批量梯度下降(Batch Gradient Descent)使用整个训练集来计算损失函数的梯度:
# 标准梯度下降
weights = weights - learning_rate * gradient
特点:
- 训练稳定性好
- 每次迭代需要计算整个数据集,计算量大
- 容易陷入局部最小值
- 内存消耗大
2. 随机梯度下降(SGD)
随机梯度下降(Stochastic Gradient Descent)每次只使用一个样本来更新参数:
# 随机梯度下降
for i in range(num_samples):weights = weights - learning_rate * gradient(single_sample[i])
特点:
- 计算速度快
- 能够跳出局部最优解
- 收敛路径震荡,不稳定
- 可能永远不会收敛到最优解
3. 小批量梯度下降(Mini-batch SGD)
小批量梯度下降结合了BGD和SGD的优点,每次使用一小批样本来更新参数:
# 小批量梯度下降
for i in range(0, num_samples, batch_size):batch = data[i:i+batch_size]weights = weights - learning_rate * gradient(batch)
特点:
- 在速度和稳定性之间取得平衡
- 是深度学习中最常用的梯度下降方法
- 可以利用矩阵运算加速
4. 优化算法的进阶版本
随着深度学习的发展,研究人员提出了多种改进版本的梯度下降算法,解决了学习率选择、方向震荡等问题。
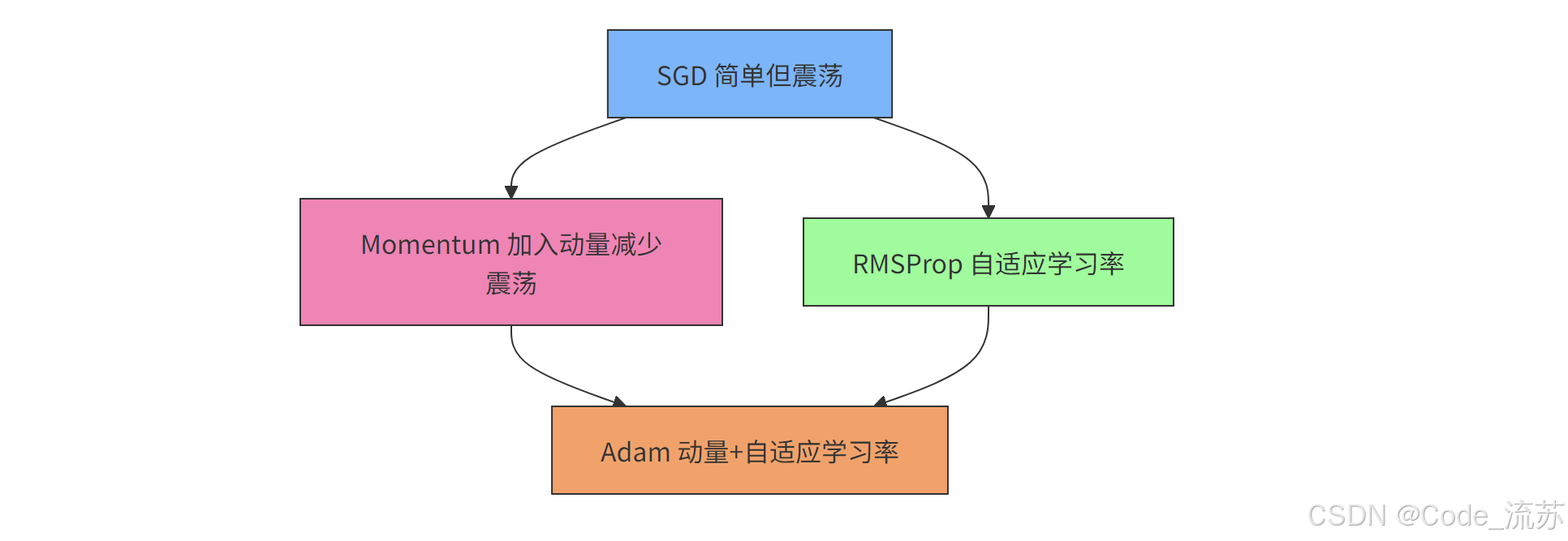
(1) 动量法 (Momentum)
动量法通过累积过去的梯度来加速训练,同时减少震荡:
# 动量法
velocity = momentum * velocity - learning_rate * gradient
weights = weights + velocity
动量法就像一个小球在山谷中滚动,可以加速通过平坦区域,减缓通过陡峭区域的速度。惯性帮助我们避免陷入局部最小值。
(2) RMSProp
RMSProp通过归一化梯度,解决了学习率过大或过小的问题:
# RMSProp
cache = decay_rate * cache + (1 - decay_rate) * gradient**2
weights = weights - learning_rate * gradient / (np.sqrt(cache) + epsilon)
RMSProp自适应地调整每个参数的学习率,对于频繁更新的参数使用较小的学习率,对于不常更新的参数使用较大的学习率。
(3) Adam优化器
Adam结合了动量法和RMSProp的优点,是目前最流行的优化算法之一:
# Adam
m = beta1 * m + (1 - beta1) * gradient # 一阶矩估计
v = beta2 * v + (1 - beta2) * gradient**2 # 二阶矩估计
m_corrected = m / (1 - beta1**t) # 偏差校正
v_corrected = v / (1 - beta2**t) # 偏差校正
weights = weights - learning_rate * m_corrected / (np.sqrt(v_corrected) + epsilon)
Adam的优点:
- 结合了动量和自适应学习率的优点
- 对超参数不敏感,通常使用默认值即可
- 适用于大多数问题和网络架构
- 在实践中表现最稳定
四、损失函数详解
1. 损失函数的作用
损失函数(Loss Function)是神经网络学习的指南针,它告诉我们模型当前预测值与真实值有多大差距。损失函数有两个关键作用:
- 量化模型预测的准确程度
- 提供梯度信息,指导模型参数更新
不同的问题需要不同的损失函数,选择合适的损失函数对模型表现至关重要。
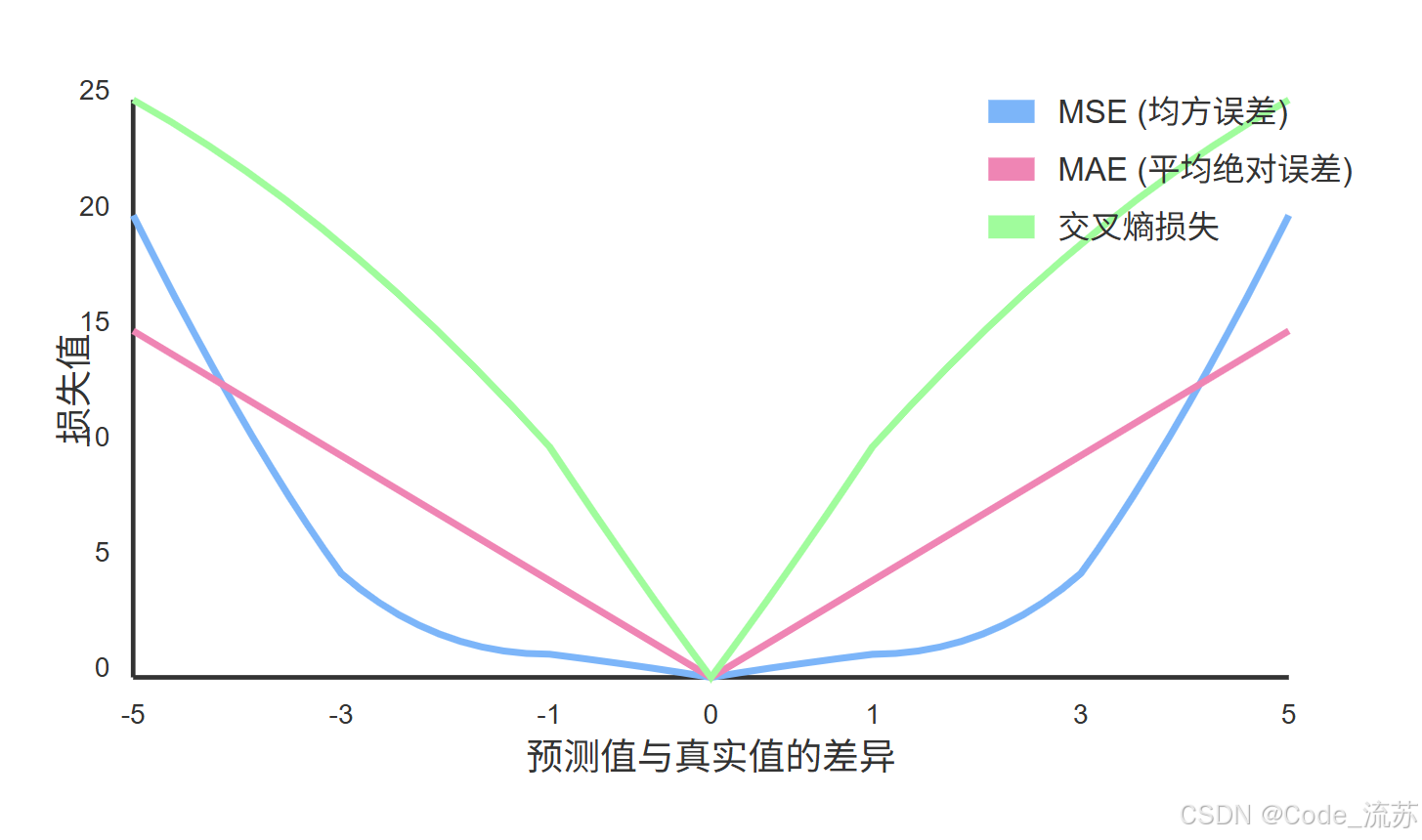
2. 均方误差损失(MSE)
均方误差(Mean Squared Error)是回归问题中最常用的损失函数,它计算预测值与真实值之差的平方和的平均值:
def mse_loss(y_true, y_pred):return np.mean((y_true - y_pred)**2)
均方误差的特点:
- 对较大误差惩罚更重(因为是平方关系)
- 处处可导,便于优化
- 当误差服从正态分布时,等价于最大似然估计
- 单位与原始数据的平方相同,不直观
3. 交叉熵损失(Cross Entropy)
交叉熵损失主要用于分类问题,尤其是在输出层使用softmax激活函数的网络中:
def binary_cross_entropy(y_true, y_pred):return -np.mean(y_true * np.log(y_pred) + (1 - y_true) * np.log(1 - y_pred))def categorical_cross_entropy(y_true, y_pred):return -np.sum(y_true * np.log(y_pred)) / len(y_true)
交叉熵损失的特点:
- 非常适合概率输出的模型
- 产生比MSE更大的梯度,加速学习
- 避免学习过程中的梯度消失问题
- 对错误分类的样本有更严厉的惩罚
4. 损失函数选择指南
如何为您的问题选择合适的损失函数?
- 回归问题:通常使用MSE或MAE(平均绝对误差)
- 二分类问题:使用二元交叉熵损失
- 多分类问题:使用分类交叉熵损失
- 不均衡数据集:考虑使用Focal Loss等特殊损失函数
- 生成模型:可能需要自定义损失函数
五、权重初始化与正则化
1. 权重初始化的重要性
神经网络的权重初始化不是一个小细节,而是影响模型是否能够成功训练的关键因素。不恰当的初始化可能导致:
- 梯度消失:如果权重太小,梯度在反向传播过程中会变得越来越小
- 梯度爆炸:如果权重太大,梯度可能会变得非常大,导致训练不稳定
- 对称性问题:如果所有权重都相同,神经元将学习相同的特征
2. 常见的初始化方法
(1) 零初始化
最简单但效果最差的方法是将所有权重初始化为零:
weights = np.zeros((input_size, output_size))
这种方法的问题是所有神经元会进行完全相同的计算和更新,导致网络无法学习不同的特征。
(2) 随机初始化
一个简单的改进是使用小的随机值:
weights = np.random.randn(input_size, output_size) * 0.01
这种方法可以打破对称性,但仍可能面临梯度消失或爆炸的问题。
(3) Xavier/Glorot初始化
针对使用sigmoid或tanh激活函数的网络设计:
# Xavier初始化
weights = np.random.randn(input_size, output_size) * np.sqrt(2 / (input_size + output_size))
Xavier初始化考虑了输入和输出的大小,保持前向传播和反向传播中方差的稳定。
(4) He初始化
针对ReLU激活函数设计的初始化方法:
# He初始化
weights = np.random.randn(input_size, output_size) * np.sqrt(2 / input_size)
He初始化特别适合使用ReLU激活函数的深层网络,能够有效防止梯度消失问题。
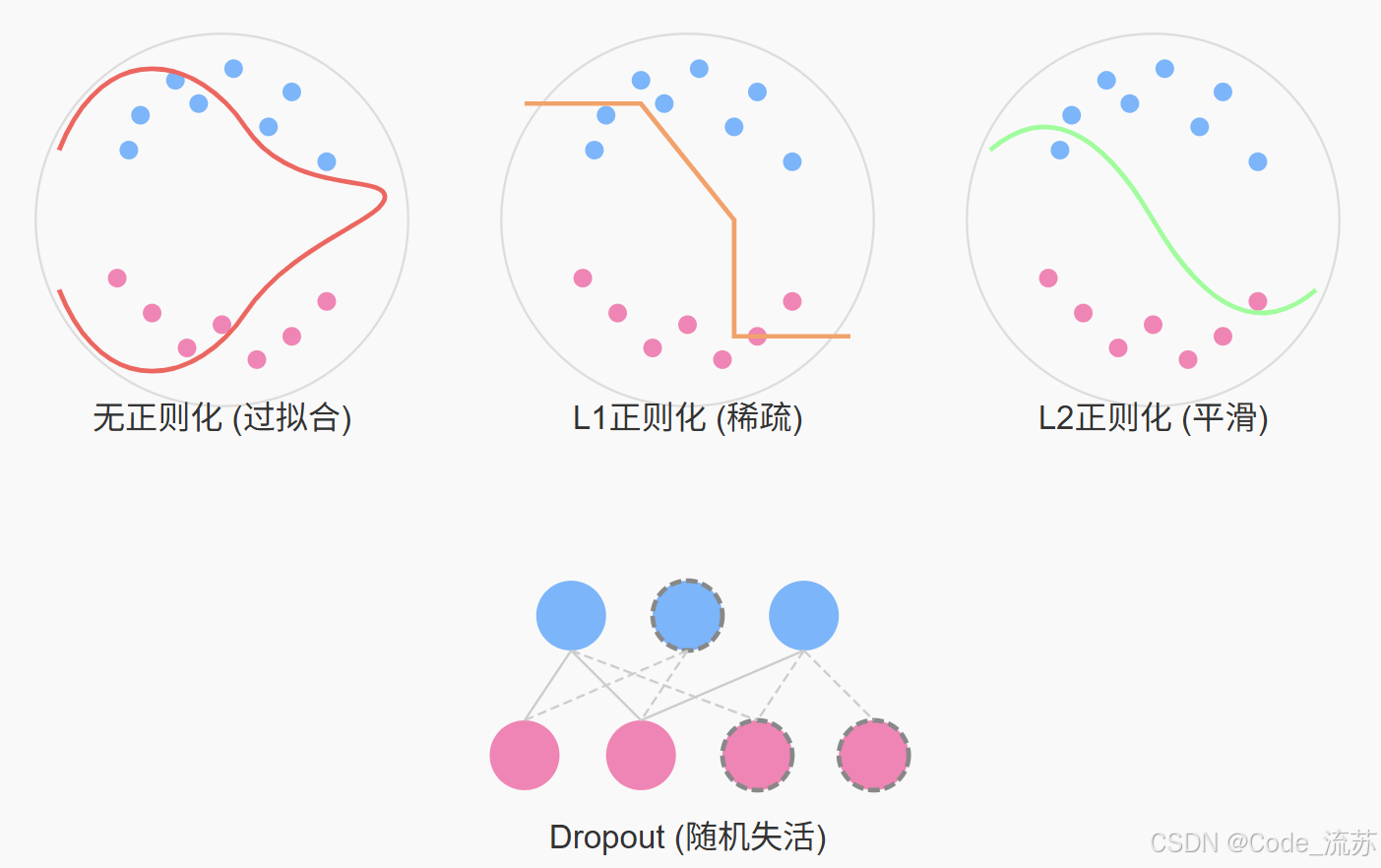
3. 正则化技术
正则化是防止神经网络过拟合的重要技术,通过添加约束使模型更加简单,提高泛化能力。
(1) L1正则化(Lasso)
L1正则化通过在损失函数中添加权重绝对值之和的惩罚项:
L1_loss = original_loss + lambda * sum(abs(weights))
L1正则化的特点:
- 倾向于产生稀疏权重(许多权重为零)
- 可以用于特征选择
- 对异常值不敏感
(2) L2正则化(Ridge)
L2正则化通过在损失函数中添加权重平方和的惩罚项:
L2_loss = original_loss + lambda * sum(weights**2)
L2正则化的特点:
- 所有权重趋向于变小,但通常不会变为零
- 计算梯度简单
- 对大权重惩罚更重
- 在深度学习中最常用
正则化效果示意图:
六、代码练习:手动实现前向传播与梯度下降过程
让我们通过一个实际的代码例子,来手动实现神经网络的前向传播和反向传播过程,这将帮助我们深入理解这些算法的工作原理。
1. 简单神经网络结构定义
我们将构建一个简单的两层神经网络,包含一个隐藏层和一个输出层:
import numpy as np# 网络结构: 2个输入 -> 3个隐藏单元 -> 1个输出
input_size = 2
hidden_size = 3
output_size = 1# 随机初始化权重
np.random.seed(42) # 设置随机种子,确保结果可复现
W1 = np.random.randn(input_size, hidden_size) * 0.1 # 输入层到隐藏层的权重
b1 = np.zeros((1, hidden_size)) # 隐藏层的偏置项
W2 = np.random.randn(hidden_size, output_size) * 0.1 # 隐藏层到输出层的权重
b2 = np.zeros((1, output_size)) # 输出层的偏置项# 激活函数: Sigmoid
def sigmoid(x):return 1 / (1 + np.exp(-x))# Sigmoid的导数
def sigmoid_derivative(x):s = sigmoid(x)return s * (1 - s)
2. 前向传播实现
前向传播是神经网络计算预测值的过程,我们将输入数据从输入层传递到输出层:
def forward(X):# 隐藏层z1 = np.dot(X, W1) + b1 # 线性变换a1 = sigmoid(z1) # 激活函数# 输出层z2 = np.dot(a1, W2) + b2 # 线性变换a2 = sigmoid(z2) # 激活函数# 保存中间值,用于反向传播cache = {"z1": z1,"a1": a1,"z2": z2,"a2": a2}return a2, cache # 返回预测值和中间计算结果
3. 计算损失函数
我们使用二元交叉熵损失函数:
def compute_loss(y_pred, y_true):# 二元交叉熵损失m = y_true.shape[0] # 样本数量loss = -np.sum(y_true * np.log(y_pred) + (1 - y_true) * np.log(1 - y_pred)) / mreturn loss
4. 反向传播实现
反向传播是计算损失函数对各个参数的梯度的过程:
def backward(X, y, cache):m = X.shape[0] # 样本数量# 从缓存中获取前向传播的中间结果a1 = cache["a1"]a2 = cache["a2"]# 输出层误差dz2 = a2 - y # 二元交叉熵损失对sigmoid输出的导数简化形式# 计算W2和b2的梯度dW2 = np.dot(a1.T, dz2) / mdb2 = np.sum(dz2, axis=0, keepdims=True) / m# 反向传播到隐藏层dz1 = np.dot(dz2, W2.T) * sigmoid_derivative(cache["z1"])# 计算W1和b1的梯度dW1 = np.dot(X.T, dz1) / mdb1 = np.sum(dz1, axis=0, keepdims=True) / m# 返回所有梯度gradients = {"dW1": dW1,"db1": db1,"dW2": dW2,"db2": db2}return gradients
5. 使用梯度下降更新参数
现在我们实现梯度下降算法来更新网络参数:
def update_parameters(gradients, learning_rate):global W1, b1, W2, b2 # 使用全局变量# 从梯度字典中获取梯度dW1 = gradients["dW1"]db1 = gradients["db1"]dW2 = gradients["dW2"]db2 = gradients["db2"]# 更新参数W1 = W1 - learning_rate * dW1b1 = b1 - learning_rate * db1W2 = W2 - learning_rate * dW2b2 = b2 - learning_rate * db2
6. 训练神经网络
最后,我们将所有步骤组合起来,训练神经网络:
def train(X, y, learning_rate=0.1, iterations=10000):losses = []for i in range(iterations):# 前向传播y_pred, cache = forward(X)# 计算损失loss = compute_loss(y_pred, y)losses.append(loss)# 反向传播gradients = backward(X, y, cache)# 更新参数update_parameters(gradients, learning_rate)# 打印进度if i % 1000 == 0:print(f"迭代 {i}, 损失: {loss:.6f}")return losses
7. 完整示例:训练XOR问题
XOR(异或)问题是一个经典的非线性分类问题,我们用它来测试我们的神经网络:
# 准备XOR数据集
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y = np.array([[0], [1], [1], [0]])# 训练模型
losses = train(X, y, learning_rate=0.5, iterations=10000)# 测试模型
y_pred, _ = forward(X)
print("\n预测结果:")
for i in range(len(X)):print(f"输入: {X[i]}, 预测: {y_pred[i][0]:.4f}, 真实值: {y[i][0]}")

8. 改进版本:加入动量优化器
让我们修改更新参数的函数,加入动量优化器,以加速训练过程:
# 初始化速度参数
v_W1 = np.zeros_like(W1)
v_b1 = np.zeros_like(b1)
v_W2 = np.zeros_like(W2)
v_b2 = np.zeros_like(b2)def update_with_momentum(gradients, learning_rate, momentum=0.9):global W1, b1, W2, b2, v_W1, v_b1, v_W2, v_b2# 从梯度字典中获取梯度dW1 = gradients["dW1"]db1 = gradients["db1"]dW2 = gradients["dW2"]db2 = gradients["db2"]# 使用动量更新v_W1 = momentum * v_W1 - learning_rate * dW1v_b1 = momentum * v_b1 - learning_rate * db1v_W2 = momentum * v_W2 - learning_rate * dW2v_b2 = momentum * v_b2 - learning_rate * db2# 更新参数W1 = W1 + v_W1b1 = b1 + v_b1W2 = W2 + v_W2b2 = b2 + v_b2
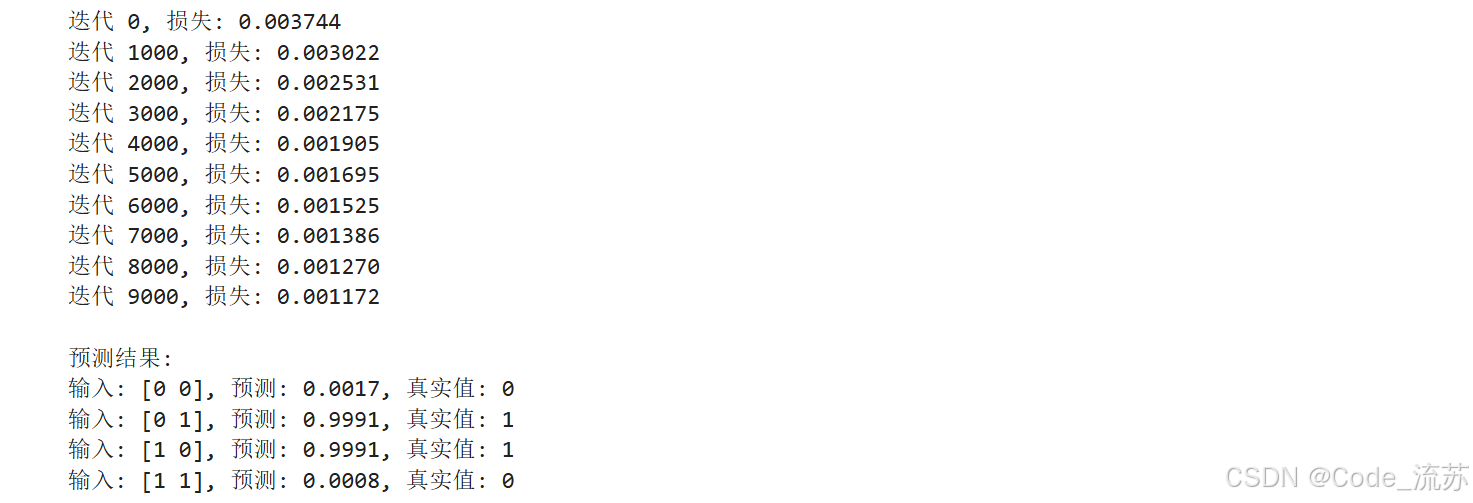
9. 分析反向传播过程的关键点
在上面的代码中,有几个关键点需要理解:
-
链式法则应用:在计算输入层权重梯度时,我们依次传递了输出层的误差,通过
np.dot(dz2, W2.T)将梯度反向传播到隐藏层。 -
梯度计算:对于每一层,我们计算了权重和偏置的梯度,公式为:
- 权重梯度:
dW = 前一层的激活值.T @ 当前层的误差 / 样本数 - 偏置梯度:
db = 当前层误差的总和 / 样本数
- 权重梯度:
-
激活函数导数:使用了sigmoid函数的导数
sigmoid_derivative,用于计算隐藏层误差。 -
批量梯度:我们计算的是所有样本的平均梯度,实现了批量梯度下降。
通过这个简单的例子,我们可以看到神经网络的核心学习机制:前向传播生成预测,计算误差,然后通过反向传播更新参数,不断迭代这个过程,使网络逐渐学会解决问题。
七、总结与进阶方向
1. 今日要点回顾
在今天的学习中,我们深入探讨了神经网络的学习机制:
- 反向传播算法是神经网络学习的核心,通过链式法则计算梯度
- 梯度下降法有多种变体,包括BGD、SGD、Mini-batch SGD
- 优化器如Momentum、RMSProp和Adam可以加速训练过程并提高稳定性
- 损失函数定义了模型预测的好坏,不同问题需要不同的损失函数
- 权重初始化和正则化对模型训练和泛化能力至关重要
2. 进阶学习方向
如果你想进一步探索这个领域,可以考虑以下方向:
- 高级优化算法:学习更多优化算法,如AdaGrad、Nadam等
- 批量归一化:了解如何使用批量归一化加速训练
- 学习率调度:探索学习率衰减策略
- 更复杂的神经网络架构:卷积神经网络、循环神经网络等
- 自动微分框架:了解PyTorch、TensorFlow等框架如何自动计算梯度
3. 实践建议
- 尝试实现不同的优化器,比较它们的性能
- 在实际项目中,从简单的模型开始,逐步增加复杂性
- 多尝试不同的超参数组合,如学习率、批量大小、正则化强度等
- 使用可视化工具监控训练过程,及时发现问题
随着我们对神经网络内部机制的深入理解,我们将能够更有效地设计和调试深度学习模型,为后续的学习打下坚实基础。明天,我们将继续深度学习的旅程,探索卷积神经网络的奥秘。期待你的参与!
祝你学习愉快,Python星球的探索者!👨🚀🌠
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!