Kafka消息不丢失处理
kafka作为消息中间件,吞吐量大(至于为啥吞吐量大,本文不做介绍),所以大家用的多。涉及到异构数据库更换,以及数据预处理后的迁移,基本想到的都是通过kafka。
概览图
我先画个图
 生产者到kafka
生产者到kafka
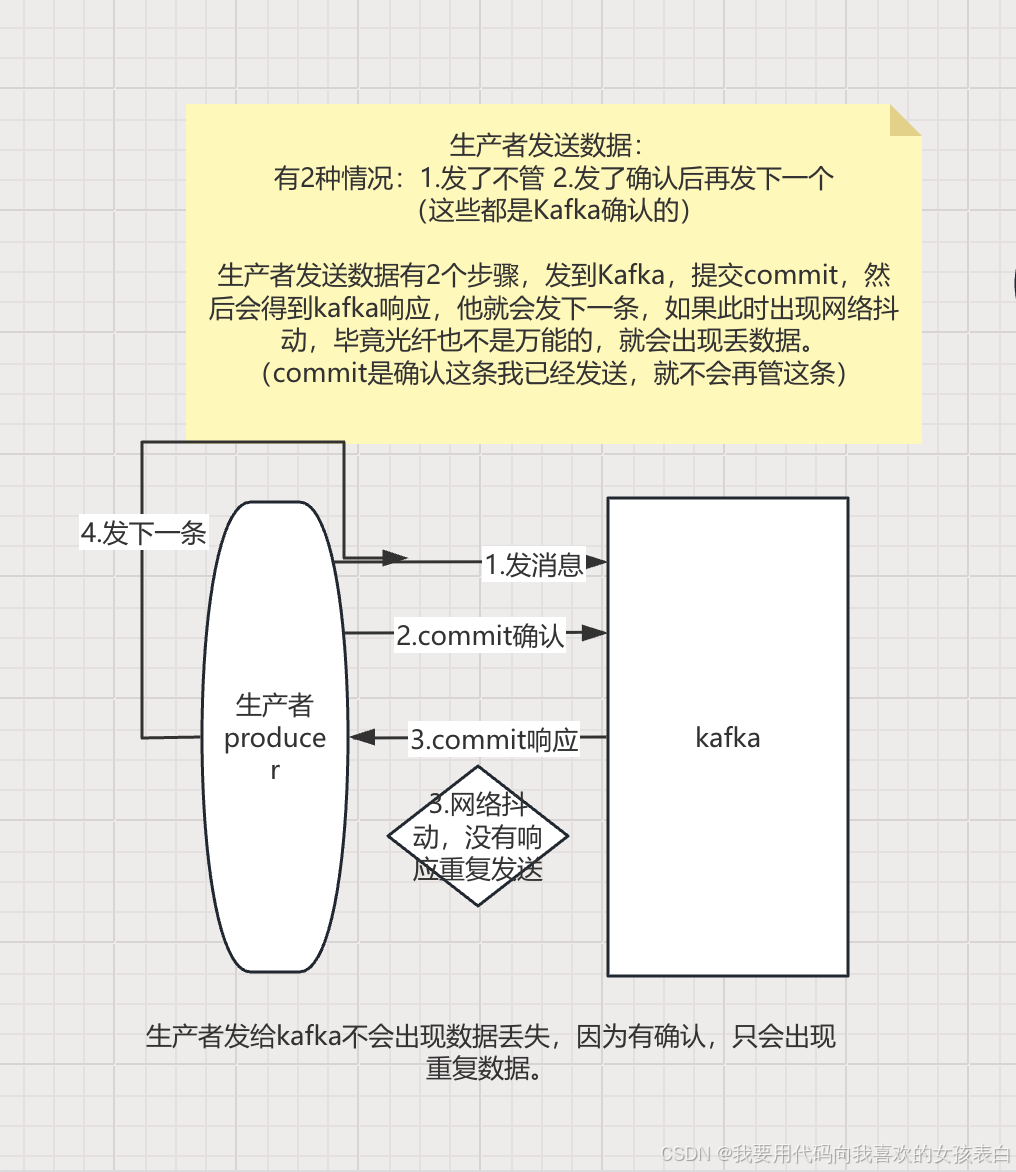
推荐用kafkla0.11后的版本,有幂等性,开启后,即使生产者因为网络抖动重发到Kafka中,kafka也会自动去重,保证消费者不会重复消费。
enable.idempotence = true
我们已经保证了生产者不会丢数据,也不会有重复数据。
kafka到消费者
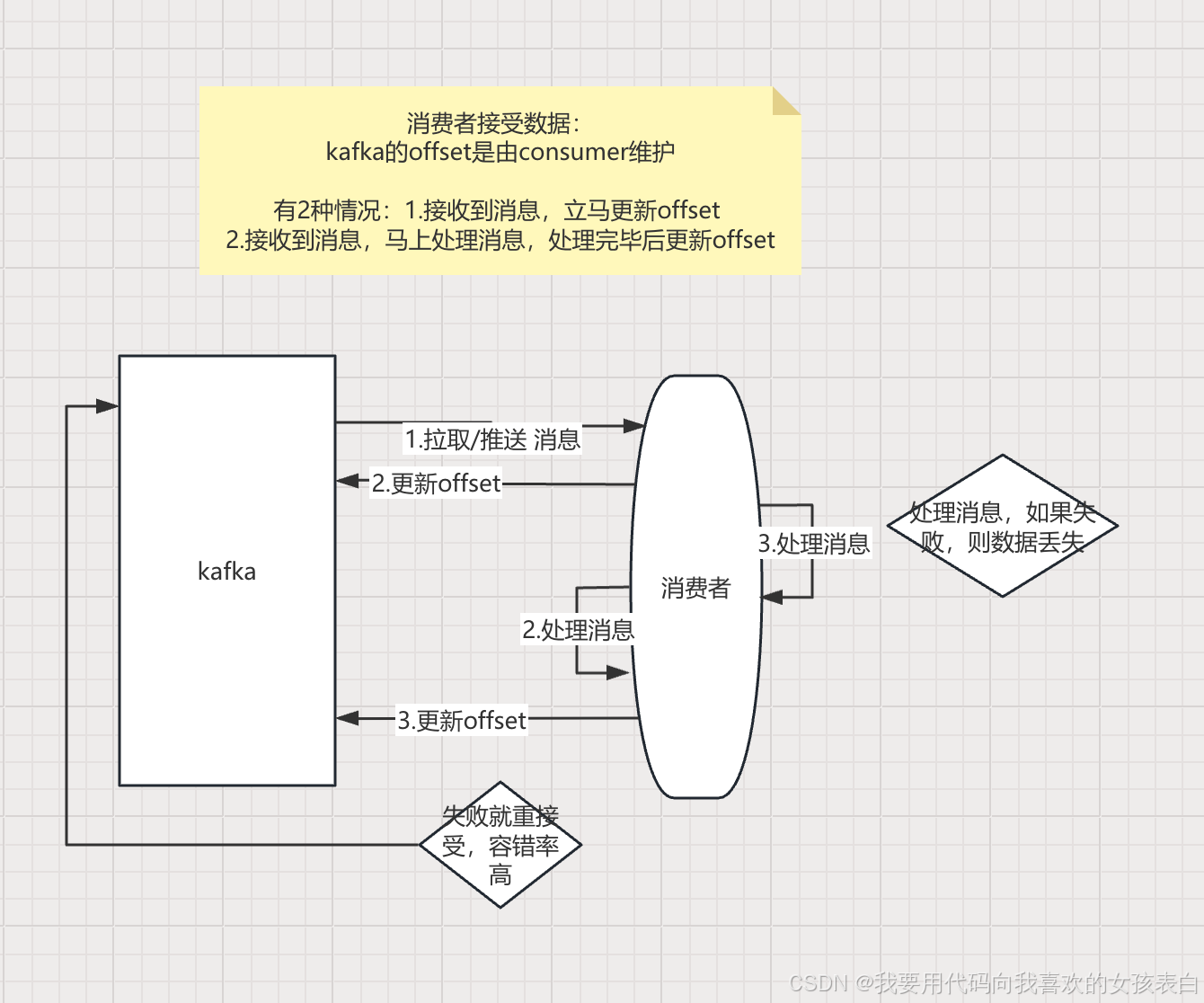
一般我们用第二种,可以保证数据不丢失。
ps:如果消费者挂了(集群的第一个节点挂了),新的节点会重新拉去这个offset,会导致重复消费(重复消费很好解决,比如有多个指令插入数据库,第一个指令成功了,后面的失败了,我们可以加一个事务,保证一致性。这种就解决了数据库的重复,或者我们插入前先根据id查询,保证一致性。存在我就不插入。或者后面去重,在消费者端处理方法很多)
如果kakfa挂了
kafka是集群,如果一个broker挂了,其他的【有备份】,那没事,除非broker都挂了(集群都挂概率很小,尤其是多az--区域数据中心),否则数据不会丢的。只要已经commit(提交到kafka)了。
备份怎么做?这就涉及到ack确认机制了,给他为-1,就会提交到每个broker,只要有一个broker正常,也没事。
参考:
https://zhuanlan.zhihu.com/p/459610418
豆包(帮忙答疑不懂的)