【JS逆向基础】爬虫核心模块:request模块与包的概念
前言:这篇文章主要介绍JS逆向爬虫中最常用的request模块,然后引出一系列的模块的概念,当然Python中其他比较常用的还有很多模块,正是这些模块也可以称之为库的东西构成了Python强大的生态,使其几乎可以实现任何功能。下面就详细介绍一下这些内容。
1,requests模块
requests 作为一个专门为「人类」编写的 HTTP 请求库,其易用性很强,因此在推出之后就迅速成为 Python 中首选的 HTTP 请求库。requests 库的最大特点是提供了简单易用的 AP!,让编程人员可以轻松地提高效率。由于 requests 不是 Python 的标准
库,因此在使用之前需要进行安装:
pip install requests
python诵过 reauests 可以完成各种类型的 HTTP 请求,包括 HTTP、HTTPS、HTTP1.0、HTTP1.1 及各种请求方法
-
requests支持的方法
requests模块支持的请求:
import requests
requests.get("http://httpbin.org/get")
requests.post("http://httpbin.org/post")
requests.put("http://httpbin.org/put")requests.delete("http://httpbin.org/delete")requests.head("http://httpbin.org/get")
requests.options("http://httpbin.org/get")
- "get--发送一个 GET 请求,用于请求页面信息。
- "options--发送一个 OPTIONS 请求,用于检查服务器端相关信息,
- head-一发送一个 HEAD 请求,类似于 GET 请求,但只请求页面的响应头信息。
- post--发送一个 POST 请求,通过 body 向指定资源提交用户数据。
- "put--发送一个 PUT 请求,向指定资源上传最新内容。
- "patch-一发送一个 PATCH 请求,同 PUT 类似,可以用于部分内容更新。
import requests
res = requests.get("https://ww3.sinaimg.cn/mw690/7772612dgy1hsmrek7r0gj21z41z4k2h.jpg")
with open("风景.jpg","wb")as f:f.write(res.content) #直接对内容进行爬取res1 = requests.get("https://video.pearvideo.com/mp4/short/20240917/cont-1796387-16037163-hd.mp4")
with open("视屏.mp4","wb")as f:f.write(res1.content) #直接对内容进行爬取-
requests的响应信息
print(respone.statuscodeprint(respone.headers)
print(respone.text)
print(response.json)2.编码
print(respone.content)
print(response.encoding)-
UA反爬
请求头需要加上下面的标识
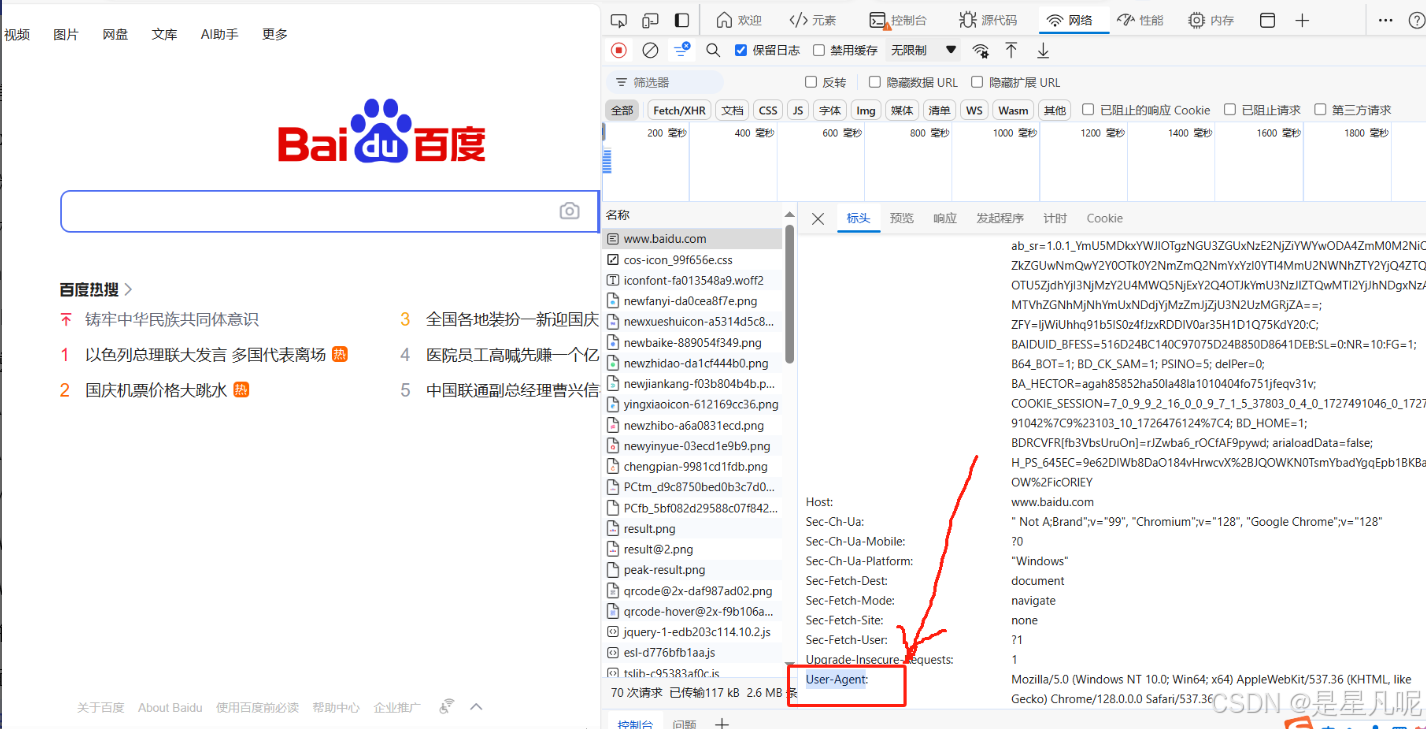
import requestsres1 = requests.get("https://www.baidu.com",headers={"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36"
})with open("baidu.html","w",encoding='utf-8')as f:f.write(res1.text)-
refererf反爬与requests请求参数
import requestsres1 = requests.get("https://m.douban.com/rexxar/api/v2/movie/recommend?",headers={"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36","Referer":"https://movie.douban.com/explore"
},params={"tags": "喜剧",
})# print(res1.text)
print(res1.json())
# print(type(res1.json()))items =res1.json()["recommend_categories"]
for i in items:print(i.get("data"))for j in i.get("data"):print(j.get("text"))-
请求体的数据
模拟有道翻译的小程序
import requestsindata = input("请输入:")
res1 = requests.post("https://aidemo.youdao.com/trans",headers={"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36","Referer":"https://ai.youdao.com/"
},params={},data={"q":indata,"from":"Auto","to":"Auto"
})
print(res1.text)
print(res1.json().get("translation"))-
cookie反爬
cookie在用户登陆的时候生成一个,当用户再次用浏览器请求相同的信息数据的时候就会自带一个cookie值,cookie比对成功之后服务端会进行免登录,而爬虫程序就会需要带cookie才可以爬取数据成功
#(1)模拟登录,获取动态cookie
res1=requests.post("http://127.0.0.1:5000/auth", data={"yuan"user","pwd":"123"
}
#(2)响应cookie
print(dict(res1.cookies))#(3)再次登录发送cookie
res1 = requests.get("http://127.0.0.1:5000/auth",headers={"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36"},cookie=dict(res1.cookies))
print(res1.text)-
session对象
#举例本地端口,此程序无法实际运行
import requests
session =requests.session()
session.post("http://127.0.0.1:5000/auth",data={"user": "yuan","pwd": "123",}
)
#(2)携带cookie爬取数据
res2 = session.get("http://127.0.0.1:5000/books")-
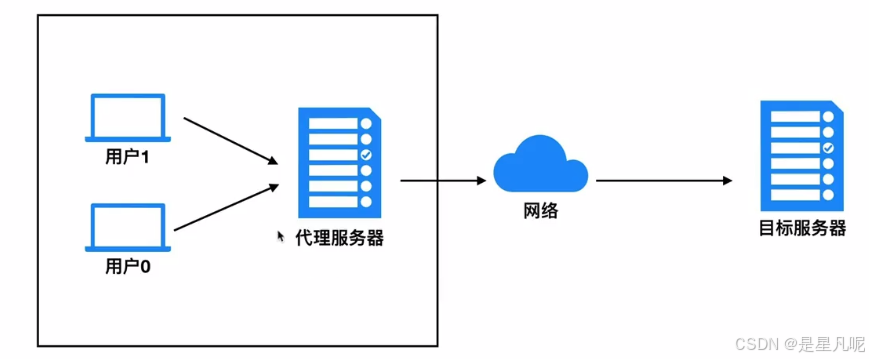
代理IP
代理IP:反反爬使用代理ip是非常必要的一种反反爬的方式,但是即使使用了代理ip,对方服务器任然会有很多的方式来检测我们是否是一个爬虫,比如:一段时间内,检测IP访问的频率,访问太多频繁会屏蔽;检查Cookie,User-Agent,Referer等header参数,若没有则屏蔽;服务方购买所有代理提供商,加入到反爬虫数据库里,若检测是代理则屏蔽等。所以更好的方式在使用代理ip的时候使用随机的方式进行选择使用,不要每次都用一个代理ip
2,模块与包
-
模块初识
def add(x,y):return x + ydef subtract(x,y):return x - ydef multiply(x,y):return x * ydef divide(x,y):return x / y#==================================
#调用其他文件中的接口的方式1
import cal
import mul
x = 1
y = 120
z = cal.subtract(x,y)
q = mul.multiply(x,y)
print(z)# 方式2
from cal import subtract
from mul import multiply,divide
from mul import * #mul文件内的接口都可以用
x = 1
y = 120
z = subtract(x,y)
print(z)-
模块与包的导入本质
本质上面在一个启动文件中导入一个python程序包,需要在启动文件(一般名字是main)同级目录及其以下的文件夹目录下面的导入的包
如下程序所示:
from cal.cal import subtract
from cal.mul import multiply,divide
from cal.mul import * #mul文件内的接口都可以用
x = 1
y = 120
z = subtract(x,y)
print(z)-
第三方包的导入与引用
1,注意之际命名的python文件包的名字不可以与已有标准库或者下载的第三方的包一样
2,通过from在启动文件中导入第三方包的时候,程序就已经将第三方文件中的程序加载执行了一遍了
import sys
# py程序文件导入报的路径都是通过下面加载的文件路径导入的
print("sys.path:::", sys.path)-
自定义的包文件的导入
import os
import sys
print("sys.path:::",sys.path)
path01 = os.path.dirname(__file__)
path02 = os.path.dirname(path01)
sys.path.insert(0,path02)-
常见OS模块的接口
import os
# 创建文件夹
# (1)
# os.mkdir("我的模块")
# 路径拼接
path = os.path.join("我的模块","my.txt")
print(path)
with open(path, "w", encoding="utf-8") as f:data = f.write("icwdgcbiwdbci")#(4)是否存在某文件或目录
print(os.path.exists("我的模块2"))#(5) 检查某一文件中的文件名与其路径名
path1 = ("/Users/yuan/PycharmProjects/my.txt")
print(os.path.basename(path1))
print(os.path.dirname(path1))
print(os.path.split(path1))