语音合成之十二 TTS声学编解码器的演进
TTS声学编解码器的演进
- 1 引言:声码器/声学编解码器在现代TTS中的关键作用
- 2 奠定基石:从早期声码器到神经合成的曙光
- 3. HiFi-GAN: 革新高效高保真波形生成
- 4. 新的疆域:面向富语义TTS的先进声学编解码器
- 5. XCodec2.0: 统一声学与语义信息
- 6.BiCodec: 为Spark-TTS打造可控的解耦令牌
- 7.总结
1 引言:声码器/声学编解码器在现代TTS中的关键作用
语音合成(Text-to-Speech, TTS)技术的核心目标之一是生成高度自然、富有表现力且与真人无异的语音。在这一追求中,声码器(Vocoder),或更广义地说,声学编解码器(Acoustic Codec)/语音令牌化器(Speech Tokenizer),扮演着至关重要的角色。它的性能直接决定了合成语音的最终质量、自然度乃至可控性 。
回顾历史,声码器的概念最早可追溯至贝尔实验室的Homer Dudley,其初衷在于分析和合成人类语音,并用于节省电信带宽 。早期的声码器,如通道声码器和后来的线性预测编码(LPC) ,奠定了参数化语音合成的基础。然而,这些传统方法合成的语音往往带有明显的“机器味”,难以满足日益增长的对自然度的高要求。
随着深度学习的浪潮,神经声码器应运而生,彻底改变了TTS的面貌。它们不再局限于简单的参数到波形的转换,而是能够从声学特征(如梅尔频谱)生成高质量的原始波形。近年来,随着大型语言模型(LLM)在TTS领域的广泛应用,声学编解码器的角色进一步扩展。它们不仅负责最终的波形生成,更重要的是,它们需要将连续的语音信号分析、压缩并表示为离散的声学令牌(acoustic tokens),这些令牌需要足够丰富以捕捉声音细节、说话人特征乃至语义信息,从而作为LLM的输入或输出 。
这种演变体现了“声码器”概念的扩展。传统意义上的声码器,如在统计参数语音合成(SPSS) 或早期神经声码器中,主要承担从相对固定的声学特征(例如梅尔频谱)到波形的转换任务。HiFi-GAN便是一个典型的例子,它高效地将梅尔频谱图转换为高质量波形 。
然而,XCodec2和BiCodec等新一代模型则更像是完整的“声学编解码器”或“语音令牌化器”。它们不仅包含将令牌解码回波形的“合成”部分,更强调将原始音频“分析”和“表示”为适合LLM处理的离散令牌序列,这些令牌往往承载了远超基本声学特征的韵律、情感、语义及说话人身份等信息 。这意味着声学编解码器不再仅仅是TTS流程末端的渲染模块,而是深度融入LLM驱动的语音生成核心,负责构建一个更全面、更易于控制的语音表示。
2 奠定基石:从早期声码器到神经合成的曙光
在深入探讨现代神经声码器之前,有必要回顾一下那些为语音合成技术奠定基础的早期概念和系统。
-
历史的足迹:基础概念
- Homer Dudley的声码器 (1938年): 这项发明标志着声码器历史的开端。Dudley在贝尔实验室的工作旨在分析和合成人类语音,其原理是通过一组带通滤波器(滤波器组)分析语音信号的频谱包络,并提取激励信号(基频和噪声),然后在合成端利用这些参数重建语音 。这一发明不仅为语音合成提供了新思路,也为语音压缩和加密通信(如二战期间的SIGSALY系统)铺平了道路 。
- Voder (1939年): 作为声码器解码器部分的演示装置,Voder在1939年的纽约世博会上向公众展示了机器合成语音的能力。操作员通过键盘和踏板控制声源和滤波器,模拟产生元音和辅音 。
- 线性预测编码 (LPC): 20世纪60、70年代发展起来的LPC技术是语音编码和合成领域的重大突破。LPC通过一个全极点滤波器来模拟声道特性,用一组预测系数来描述频谱包络 。它比早期的通道声码器更为高效,并成为许多早期语音合成芯片(如著名的德州仪器Speak & Spell玩具)的核心技术 。
- 统计参数语音合成 (SPSS): 在深度学习兴起之前,SPSS是主流的语音合成范式。它通常包括文本分析、声学参数预测(如基频F0、频谱参数如梅尔倒谱系数MGC、带非周期性参数BAP)和波形合成三个阶段。其中,波形合成阶段依赖于参数声码器,如STRAIGHT和WORLD,它们根据预测出的声学参数重建语音波形 。尽管SPSS在可懂度和可控性上有所进步,但合成语音往往带有明显的“蜂鸣声”或“机器味”,自然度欠佳。
-
神经革命的号角:
- WaveNet (DeepMind, 2016年): WaveNet的出现标志着语音合成领域的一次范式革命。它是一个自回归的深度生成模型,使用带孔洞的因果卷积直接在原始音频波形上逐样本点进行预测 。
- 重大意义: WaveNet生成的语音在自然度和音质上达到了前所未有的水平,显著超越了传统的SPSS声码器。
- 严峻挑战: 由于其逐样本点的自回归特性,WaveNet的合成速度非常缓慢,难以满足实时应用的需求。
- WaveRNN (2018年) 及类似的基于RNN的方法: 为了解决WaveNet的效率问题,研究者们提出了WaveRNN等模型。它们通常采用更紧凑的循环神经网络(RNN)结构,在保持较高音质的同时,试图提升合成效率 。
- 向非自回归模型的迈进: 自回归模型的计算瓶颈催生了对并行波形生成方法的研究。这直接导致了基于生成对抗网络(GAN)、流模型(Flow-based)以及后来的扩散模型(Diffusion-based)的非自回归声码器的兴起 。
- WaveNet (DeepMind, 2016年): WaveNet的出现标志着语音合成领域的一次范式革命。它是一个自回归的深度生成模型,使用带孔洞的因果卷积直接在原始音频波形上逐样本点进行预测 。
在声码器的发展历程中,对更高感知质量和更快合成速度的追求始终是一对核心矛盾和主要驱动力。SPSS声码器虽然相对较快,但音质不尽如人意 。WaveNet通过逐样本点的自回归生成方式,实现了极高的音质,但牺牲了合成速度 。随后,WaveRNN等工作试图在自回归框架内优化速度 。真正的速度飞跃来自于非自回归模型,它们旨在达到与WaveNet相媲美的音质,同时实现并行生成,HiFi-GAN便是成功平衡这一矛盾的典范 。即便是HiFi-GAN本身,其不同版本也在模型大小、速度和质量之间提供了不同的权衡方案 。这种持续的平衡探索,极大地推动了模型架构、训练技术和损失函数设计的创新,不断拓展着实时高保真语音合成的可能性边界。
3. HiFi-GAN: 革新高效高保真波形生成
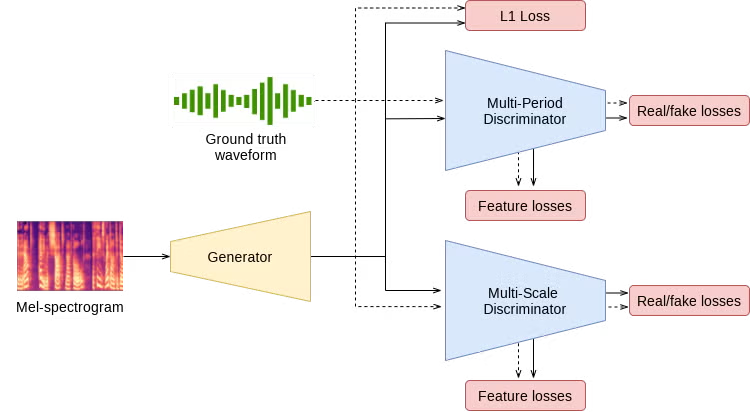
HiFi-GAN (High-Fidelity Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis) 的提出,旨在解决先前GAN声码器在音质上难以匹敌自回归模型,同时保持高效性的难题 。其核心理念在于,对语音信号中存在的周期性模式进行建模,对于提升合成样本的质量至关重要 。
-
架构深度解析:
- 生成器 (Generator, G):
- 采用全卷积神经网络结构,输入为梅尔频谱图。
- 通过一系列转置卷积(transposed convolutions)进行上采样,以匹配原始波形的时间分辨率。
- 多感受野融合模块 (Multi-Receptive Field Fusion, MRF): 这是HiFi-GAN的一项核心创新。MRF模块将多个残差块(residual blocks)的输出相加,每个残差块具有不同的卷积核尺寸和空洞率(dilation rates)。这种设计使得生成器能够并行地观察不同长度的模式,从而增强其对复杂音频结构的建模能力 。
- 判别器 (Discriminators, D): HiFi-GAN巧妙地设计了两种判别器,从不同角度评估生成的音频。
- 多周期判别器 (Multi-Period Discriminator, MPD):
- 由多个子判别器组成,每个子判别器负责处理音频信号在不同周期性间隔上的特征(例如,通过观察每隔p个样本点的数据) 。
- 这一设计对于捕捉语音信号中固有的、多样的周期性模式至关重要,而这些模式往往被以往的模型所忽略,从而显著提升了合成语音的真实感 。
- 输入音频被重塑为二维数据,以便应用二维卷积,确保梯度能够有效地传播。
- 多尺度判别器 (Multi-Scale Discriminator, MSD):
- 借鉴自MelGAN,MSD在不同尺度(原始音频、下采样后的音频)上评估音频样本 。
- 这有助于捕捉音频的短期和长期依赖关系,以及整体波形结构。
- MSD采用带步长的分组卷积。为保证训练稳定性,除处理原始音频的子判别器外,其他子判别器采用权重归一化,而前者采用谱归一化。
- 多周期判别器 (Multi-Period Discriminator, MPD):
- 判别器的替代设计: 曾有研究提出使用Wave-U-Net判别器作为MPD/MSD集成判别器的替代方案。这种单一但表达能力强的判别器采用Wave-U-Net架构,能够以与输入信号相同的分辨率逐样本点评估波形,并通过带有跳跃连接的编码器和解码器提取多层次特征。实验表明,这种设计可以在判别器更轻量、更快的情况下达到相当的语音质量 。
- 生成器 (Generator, G):
-
训练范式:
- 对抗损失 (Adversarial Loss): 采用LSGAN (Least Squares GAN) 的损失函数,以实现更稳定的训练。MPD和MSD的输出共同构成了对抗损失。
- 特征匹配损失 (Feature Matching Loss, LFM): 计算真实样本和生成样本在判别器中间层特征之间的L1距离。这有助于引导生成器产生与真实音频特征相似的输出,从而稳定训练过程并提升音质。
- 梅尔频谱损失 (Mel-Spectrogram Loss, LMel): 计算生成波形的梅尔频谱与真实梅尔频谱之间的L1距离。这是一个辅助损失,尤其在训练初期,能够有效地指导生成器的学习方向。
-
性能与深远影响:
- 高保真度: 在MOS(平均意见分)评估中,HiFi-GAN的得分不仅显著优于先前的GAN声码器,甚至超越了如WaveGlow等一些自回归模型,达到了接近真人的音质水平 。
- 高效率: HiFi-GAN在GPU上实现了远超实时的合成速度,其轻量级版本甚至能在CPU上达到实时合成 。
- 泛化能力: HiFi-GAN在未见过说话人的梅尔频谱转换以及端到端TTS任务中均表现出良好的性能 。
- 广泛应用: 由于其在音质和速度上的出色平衡,HiFi-GAN迅速成为后续众多TTS系统和研究中广泛采用的基础声码器 ,例如在先进的CosyVoice2.0系统中也得到了应用 。
表1: HiFi-GAN 性能总结 (基于LJSpeech数据集的原始论文结果)
| 模型 | MOS (±置信区间) | GPU合成速度 (kHz / 倍于实时) | CPU合成速度 (kHz / 倍于实时) | 参数量 (百万) |
|---|---|---|---|---|
| Ground Truth | 4.45 (±0.06) | - | - | - |
| WaveNet (MoL) | 4.02 (±0.08) | 0.07 / ×0.003 | - | 24.73 |
| WaveGlow | 3.81 (±0.08) | 501 / ×22.75 | 4.72 / ×0.21 | 87.73 |
| MelGAN | 3.79 (±0.09) | 14,238 / ×645.73 | 145.52 / ×6.59 | 4.26 |
| HiFi-GAN V1 | 4.36 (±0.07) | 3,701 / ×167.86 | 31.74 / ×1.43 | 13.92 |
| HiFi-GAN V2 | 4.23 (±0.07) | 16,863 / ×764.80 | 214.97 / ×9.74 | 0.92 |
| HiFi-GAN V3 | 4.05 (±0.08) | 26,169 / ×1,186.80 | 296.38 / ×13.44 | 1.46 |
HiFi-GAN的成功,特别是其相较于先前GAN声码器在音质上的显著提升,很大程度上归功于其判别器的创新设计。GAN的训练依赖于生成器和判别器之间的博弈,判别器向生成器提供有意义的梯度至关重要。早期的GAN声码器(如MelGAN)虽然也使用了多尺度判别器(MSD),但在捕捉所有语音真实感方面仍有不足 。HiFi-GAN的论文明确指出,对周期性模式的建模是提升音质的关键 。为此,多周期判别器(MPD)被专门设计出来,通过多个子判别器分别关注音频的不同周期成分 。HiFi-GAN论文中的消融实验以及后续一些关于判别器设计的研究(如 中提出的单一判别器替代方案)都强调了判别器架构的重要性;移除MPD会显著降低合成语音的质量 。这突出表明,对于基于GAN的语音合成而言,仅仅拥有一个强大的生成器是不够的。判别器能否有效感知并惩罚各种细微的声学瑕疵(如周期性、不同尺度下的时间结构等),对于最终实现高保真度至关重要。
4. 新的疆域:面向富语义TTS的先进声学编解码器
尽管HiFi-GAN在梅尔频谱到波形的转换任务上表现卓越,但随着大型语言模型(LLM)在TTS领域的崛起,对声学表示(即声学令牌)提出了新的、更高的要求:
- 离散化与高压缩: LLM通常处理离散的令牌序列,因此声学表示需要被有效地离散化,并且为了处理效率和存储,需要达到一定的压缩率。
- 语义感知: 新一代的声学令牌不仅要捕捉声音细节,还应包含语言内容信息,使得LLM能够更好地理解和生成语音的语义层面 。
- 可控性: 为了生成更具表现力的语音,声学表示应支持对说话人身份、风格、情感等属性的精细控制 。
- 高效率: 低比特率的声学令牌有助于加快LLM的处理速度并减少数据传输和存储的开销。
现有的纯声学编解码器(如Encodec,仅关注重建质量,难以让LLM预测音频的“低层波动”)和纯语义编解码器(如Hubert,忽略声学细节,常导致两阶段建模)都难以完全满足这些新需求 。因此,研究重点开始从单纯的“声码器”(mel-to-wave)转向功能更全面的“声学编解码器/令牌化器”(audio-to-tokens-to-audio)。这些新模型不仅负责最终的波形合成,更承担了将语音分析、编码为富含多维度信息的离散令牌序列的关键任务。
5. XCodec2.0: 统一声学与语义信息
XCodec系列代表了在LLM时代下,为满足富语义TTS需求而设计的新一代声学编解码器。
-
XCodec的演进:
- 初代XCodec: 其目标是在码本的各个层级(最初基于RVQ)融合声学和语义信息,以支持单阶段流式生成,并简化LLM的建模复杂度 。
- XCodec2.0的改进: XCodec2.0在前代基础上进行了显著优化,包括:
- 降低TPS (Tokens Per Second): 意味着更高的压缩率或处理效率。
- 支持单码本: 简化了令牌结构。
- 提升重建质量。
- 增加多语言语音语义支持 。 其最终目标是使该令牌化器更加实用,成为音频LLM的标准构建模块 。
-
XCodec2.0架构剖析:
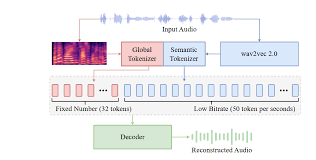
- 单层设计: 从多层残差矢量量化(RVQ)转向单层矢量量化(VQ)或有限标量量化(Finite Scalar Quantization, FSQ) 。一篇讨论指出其从RVQ演进为单个VQ 。
- 语义特征融入: 在量化阶段之前,XCodec2.0会整合来自预训练语义编码器(例如,从Wav2Vec 2.0或Hubert等语音表示模型中提取)的语义特征 。
- 语义重建损失: 在RVQ(或单VQ)之后应用一项语义重建损失,以确保量化后的表示仍能保持语义的完整性 。
- 帧率: 以50Hz的帧率运行,即每秒产生50个声学令牌 。
- 输出: 生成单流的离散声学令牌。
-
设计理念:
- 为基于LLM的音频生成而优化: 通过提供包含丰富语义信息的单流声学令牌,XCodec2.0简化了LLM的预测任务,相比于传统RVQ产生的多码本或解耦表示更为直接 。
- 提升语义完整性: 通过显式地用语义信息指导编解码过程,旨在减少合成语音中的内容错误(例如,降低词错误率WER) 。
- 兼顾压缩与质量: 在保证较高重建质量的同时,力求达到实用的压缩水平(如较低的TPS) 。
-
应用与性能:
- 可与codec-bpe等工具集成,用于音频语言建模 。
- 实验表明,在TTS任务中,与基线声学编解码器相比,XCodec2.0能够改善WER,这支持了“整合语义信息有助于LLM更好地理解内容”的假设 。
- 相较于SpeechTokenizer,XCodec在WER以及说话人相似度(Sim-O, UTMOS)方面表现更优,表明其能更有效地整合语义和声学信息 。
在先进声学编解码器的设计中,一个关键的考量点在于如何将语义信息与声学信号处理路径相融合,这可以称之为“语义接合点”(Semantic Seam)。XCodec2.0的策略是在量化之前显式地注入语义特征,并在量化之后使用特定的损失函数来强化语义信息的保留。传统的纯声学编解码器可能在压缩过程中丢失语义的细微差别,而纯语义编解码器则牺牲了声学细节 。像SpeechTokenizer这样的早期尝试采用了两阶段方法,试图在不同层级分别处理语义和声学信息 。
XCodec2.0则采取了“早期融合”的思路,从预训练的语义编码器获取特征 ,并将其置于VQ瓶颈层之前。这样做使得VQ学习过程能够兼顾并保留这种融合后的信息。同时,在VQ之后施加语义重建损失,进一步确保最终选择的离散码字在语义上是准确且有意义的 。这种策略旨在创建一个更整体化的离散表示。其成功(例如,在WER上的改进 )表明,用语义信息来影响量化过程,可能比后续再尝试添加语义或将两者完全分离(如果目标是为LLM生成单一、统一的令牌流)更为有效。这与BiCodec所采用的显式解耦策略形成了对比。
6.BiCodec: 为Spark-TTS打造可控的解耦令牌
BiCodec是专为Spark-TTS系统设计的一款声学编解码器,其核心在于通过解耦的声学令牌实现富有表现力且可精细控制的语音合成。
-
设计原则 (针对Spark-TTS):
- 单流解耦令牌: BiCodec将语音分解为两种互补的令牌类型,并整合在单一的令牌流中:
- 低比特率语义令牌 (Low-bitrate Semantic Tokens): 负责捕捉语言学内容,即“说什么”。
- 定长全局令牌 (Fixed-length Global Tokens): 用于表示说话人属性以及其他副语言学特征(如音色、风格、情感),即“怎么说”。
- 核心目标: 实现对语音属性(如性别、音高、语速、情感)的细粒度控制,达成高质量的零样本(zero-shot)声音克隆,同时为基于LLM的TTS保持高效率。
- 单流解耦令牌: BiCodec将语音分解为两种互补的令牌类型,并整合在单一的令牌流中:
-
BiCodec模型内部机制:
- 编码器 (Encoder): 处理输入音频以提取初始特征。
- 语义令牌量化: 可能采用标准的VQ方法对时变的语义内容进行量化。
- 全局嵌入量化创新:
- 采用有限标量量化 (FSQ)。
- 利用可学习查询 (learnable queries) 和 交叉注意力机制 (cross-attention mechanism) 来推导全局嵌入。与简单的平均池化或其他全局属性提取方法相比,这是一种新颖的途径,能够为全局特征(如说话人音色)生成更具表现力和灵活性的表示 (虽然在对比TiCodec时提及此方法,但暗示了BiCodec采用了类似或更优的机制)。
- 解码器 (Decoder): 从语义令牌和全局令牌的组合流中重建语音波形。
-
训练策略:
- GAN方法论: 采用端到端的对抗训练框架。
- 判别器: 使用多周期判别器 (MPD) 和多频带多尺度短时傅里叶变换 (STFT) 判别器,分别用于波形域和频域的判别 (这与HiFi-GAN及其他现代编解码器的做法类似)。
- 重建损失: 在多尺度梅尔频谱图上计算L1损失。
- L1特征匹配损失: 通过判别器的中间层特征计算。
- VQ码本学习: 包含码本损失(编码器输出与量化结果之间的L1损失,使用停止梯度)和承诺损失 (commitment loss)。使用直通估计器 (Straight-Through Estimator, STE) 进行梯度反向传播。
- Wav2Vec 2.0重建损失: 在量化之后应用,以增强语义相关性 (借鉴了X-Codec的做法) 。
- 全局嵌入训练稳定性: 在训练初期,解码器使用的全局嵌入直接从编码器输出的未量化特征池化得到(教师信号),同时全局令牌的FSQ码本通过L1损失向该教师信号学习。这种教师强制策略在训练稳定后会被移除。
- GAN方法论: 采用端到端的对抗训练框架。
-
解决的问题与影响:
- 解决了现有LLM-based TTS中,因预测多个码本而导致的多阶段处理或复杂架构的局限性 。
- 通过单一的编解码器LLM,提供了一个统一的零样本TTS系统,并具备全面的属性控制能力 。
- 这种解耦表示在保留语义令牌效率的同时,实现了对音色的细粒度控制 。
-
性能表现:
- 据称在零样本声音克隆方面达到SOTA水平,并能生成高度可定制化的声音 。
- BiCodec本身的重建质量是Spark-TTS整体评估的一部分,具体指标可参考其论文中的重建实验结果 [ (Table 2, 3 for reconstruction)]。
表2: BiCodec 架构与训练亮点
| 方面 | 描述 |
|---|---|
| 核心理念 | 解耦的语义令牌与全局令牌,实现单流输出 |
| 语义令牌类型 | 低比特率 |
| 全局令牌类型 | 定长,基于FSQ |
| 全局属性提取 | 可学习查询 (Learnable queries) 与交叉注意力 (Cross-attention) |
| 关键训练目标 | GAN对抗损失, L1梅尔频谱重建损失, L1特征匹配损失, VQ码本损失 (codebook & commitment), Wav2Vec 2.0重建损失 (语义相关性) |
BiCodec将语义内容和说话人属性显式分离为不同类型的令牌,这是一种深思熟虑的设计选择,旨在增强可控性并简化下游LLM(在Spark-TTS中)的任务。对于LLM而言,从一个整体的、纠缠的表示中控制特定的语音属性(如音色、情感、音高)可能相当具有挑战性。以往的系统可能需要复杂的多阶段生成或精巧的提示工程才能实现此类控制 。
BiCodec则提出了一种“因子分解”的语音表示方法:语义令牌承载“说什么”的信息,而全局令牌承载“怎么说”(如说话人身份、整体风格)的信息 。这使得Spark-TTS中的LLM有可能更独立地学习和操纵这些方面。例如,它可以将给定文本的语义令牌与参考说话人的全局令牌相结合,以实现声音克隆。同时,低比特率语义令牌的使用也保证了效率 。这种解耦策略代表了构建更直观、更强大的合成语音控制接口的重要一步。它与LLM的模块化特性非常契合,允许LLM专注于生成或操纵由这些解耦令牌类型所代表的语音信号的特定方面。这与XCodec2.0所追求的统一令牌流形成了不同的设计哲学。
7.总结
从HiFi-GAN在波形合成效率与保真度上取得的突破,到XCodec2.0和BiCodec在语义丰富性与可控性方面的探索,TTS声学编解码技术在过去数年中取得了令人瞩目的进展。
当前声码器的设计趋势:
- GAN的基石地位: 生成对抗网络(GAN)仍然是训练高保真声码器和编解码器的核心技术之一,尽管通常会辅以感知损失和特征匹配损失来进一步提升效果 。
- FSQ的兴起: 有限标量量化(FSQ)正逐渐成为新一代编解码器中(XCodec2.0中通过“单一VQ”间接体现,BiCodec,CosyVoice2.0均采用)替代传统RVQ的首选方法,因为它在每帧生成较少令牌序列方面具有简单性和效率优势 。
- 以LLM为中心的设计: 声学编解码器的设计越来越倾向于产生为LLM处理而优化的令牌流,这催生了那些优先考虑语义丰富性、可控性以及适当压缩级别的架构 。
- 语义引导的重要性: 在编解码器中显式地整合语义信息(例如XCodec2.0中输入语义编码器特征,BiCodec中应用wav2vec2.0损失)已成为一种普遍做法,旨在提高内容准确性和自然度 。
表3: 现代声码器/声学编解码器特性对比
| 特性 | HiFi-GAN | XCodec2.0 | BiCodec (in Spark-TTS) | CosyVoice2.0 (声学部分) |
|---|---|---|---|---|
| 主要目标 | 波形保真度与效率 | 统一的语义-声学令牌,简化LLM处理 | 解耦的可控令牌 (语义 vs. 全局属性) | 系统集成,流式,高表现力 |
| 编解码器输入 | 梅尔频谱图 | 原始音频 | 原始音频 | 语义语音令牌 (来自LLM) |
| 编解码器输出 | 波形 | 单流离散声学令牌 | 单流离散令牌 (语义+全局) | 梅尔频谱图 (送入HiFi-GAN声码器) |
| 关键架构元素 | MRF, MPD, MSD | 语义编码器 + 单层VQ/FSQ, 对抗判别器 | 编码器, 解耦量化器 (语义VQ + 全局FSQ含注意力机制), 解码器, 对抗判别器 | FSQ (令牌化), 流匹配模型 (令牌到梅尔), HiFi-GAN (梅尔到波形) |
| 量化策略 | (不适用,为声码器) | 单层VQ/FSQ | 语义VQ + 全局FSQ | FSQ |
| 语义处理 | 间接 (依赖输入梅尔频谱的语义质量) | 量化前融入语义特征,量化后施加语义损失 | 解耦为语义令牌,应用Wav2Vec2.0损失 | LLM负责主要语义处理,输出语义令牌 |
| 主要优势 | 高保真、高效率波形合成 | 统一令牌简化LLM,提升语义完整性 | 细粒度语音属性控制,零样本声音克隆 | 低延迟流式合成,高自然度与表现力,多语言支持 |
在如何将声学信息有效地提供给LLM以用于TTS任务方面,似乎出现了两种主要的设计哲学:一种是如XCodec2.0所倡导的统一令牌流,另一种则是如BiCodec所采用的解耦令牌流。LLM擅长序列建模,关键问题在于哪种类型的序列能够最好地表示语音以用于生成。XCodec2.0主张采用单一的令牌流,其中声学和语义信息被融合在一起 。这或许能简化LLM的输入结构,因为它只需要处理一种类型的令牌。其挑战在于确保LLM能够从这种融合的表示中隐式地学习控制不同的语音属性。相比之下,BiCodec则主张将语义内容和全局说话人属性显式地解耦开来 。这可能使LLM通过操纵这些不同类型的令牌来更容易地施加细粒度的控制。其挑战则在于如何在LLM内部有效地管理这些不同类型的令牌。
这两种方法都旨在改进以往如多流RVQ输出或缺乏明确语义/说话人信息的纯声学令牌序列等旧方法。目前,该领域正在积极探索连接连续语音世界和离散LLM处理的最佳接口。这些不同方法能否成功,将取决于它们在表示能力、可控性以及LLM学习使用这些令牌的难易程度之间所达成的平衡。尚不清楚哪种范式会在所有用例中最终胜出。
- 未来展望:
- 在保持高质量的同时进一步提升压缩率。
- 实现对表现力属性的更细粒度、更直观的控制。
- LLM与声学编解码器的端到端联合训练,以实现更紧密的集成。
- 能够以最少的数据稳健处理多样化声学条件和未见过说话人的编解码器。
- 在编解码器架构本身中探索扩散模型的应用,而不仅仅是作为最终的声码器阶段 (例如SpecDiff-GAN在HiFi-GAN基础上引入扩散过程)。