oracle 优化器
优化器是Oracle中的一个核心模块,它的作用是为用户输入的SQL语句选择一个计算出来的最高效的执行计划。
查询优化器对于SQL语句的性能非常重要。优化器是 SQL 分析和执行的优化工具,负责制定 SQL 的执行计划。 比如什么时候是全表扫描,什么时候是索引范围搜索,或者是全索引扫描。如果是表与表之间连接的时候,它会负责去定表之间以一种什么样子的形式来关联,比如哈希连接还是嵌套循环或者是合并连接。这些因素直接决定了 SQL 的执行效率,所以优化器是 SQL 执行的核心。如果查询优化器生成的执行计划低效,那么就会导致低劣的性能。有一些参数的配置能够影响到查询优化器生成高效的执行计划。
SQL语句在Oracle中的执行过程如下图14-1所示。
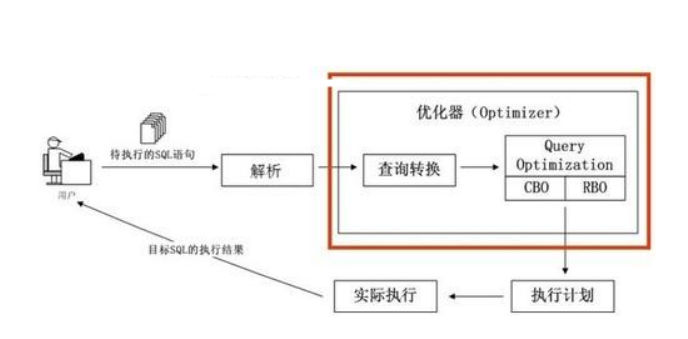
图14-1 SQL语句执行过程
优化器的类型:
基于规则的优化器(RBO,Rule-Based Optimizer)
基于成本的优化器(CBO,Cost-Based Optimizer)
14.3.1基于规则优化器RBO
基于规则的优化器现在基本上已经不怎么用了,这里只做简单介绍。基于规则的优化器诞生于早期关系型数据库,它的原理是基于一系列规则的优先顺序来分析出执行计划,以判断最优查询路径。
其中排名越靠前,Oracle认为效率越高。例如:按索引访问的效率肯定高于全表扫描,多字段复合索引的效率高于单字段索引,等。RBO不关心被访问对象的实际数据分布情况、索引效率等,仅凭想象去决定应该如何去访问数据库。RBO是一种非常粗放型的优化器。
基于规则的优化器是将一系列规则固定在系统中,给 每个执行路径定一个等级。最低是1最高是15。如:等级1对应的是:single row by rowid (通过rowid访问数据),等级15则对应的是:full table scan (全表扫描) 。当SQL执行的时候,有不同的执行路径可以选择,那么就从该SQL的执行计划中选择一条等级值最低的路径作为其执行计划。
RBO由于选择执行计划的方式比较死板,所以会有很多缺陷(相对于CBO):
(1)在使用RBO的时候,一旦执行计划出了问题,很难对其做调整。
(2)使用RBO时,SQL的写法,甚至是SQL中涉及对象在SQL文本出现的先后次序都可能会影响RBO对执行计划的选择。
(3)Oracle 数据库很多好的特性、功能RBO都无法兼容。例如目标SQL中涉及的对象有ITO;使用了哈希链接、星型链接、函数索引等。
(4)Oracle 数据库很多好的特性、功能RBO都无法兼容。例如如目标SQL中涉及的对象有ITO;使用了哈希链接、星型链接、函数索引等。
由于诸多原因,RBO选择出来的执行计划不一定是最优的执行计划(例如:建立索引的字段都是同样的值,那么使用索引效率不如全表扫描效率高。但是依然会通过索引去取值)。所以,Oracle 10g 开始,就改为使用CBO了。Oracle 10g 以后的版本,如果想要使用RBO。需要通过修改优化器模式,或使用RULE Hint来继续使用RBO。
在当前会话中使用RBO,代码如下:
ALTER SESSION SET OPTIMIZER_MODE=‘RULE’
14.3.2基于成本的优化器CBO
为了解决RBO由于硬编码导致执行计划不准确的问题,从Oracle7开始,Oracle就引入了CBO。CBO在选择执行计划的时候,所用的判断原则为成本,CBO会从诸多的执行计划中选择一条成本最小的执行路径作为其执行计划。各条执行路径成本是根据目标的SQL语句所涉及的表、索引、列等相关对象的统计信息计算得出的。这些统计信息存储在Oracle的数据字典里,并且从多个角度描述了Oracle数据库中相关对象的数据量、数据分布情况等信息。
Oracle在选择执行计划的时候,会根据这些统计信息算出相关执行步骤对应的IO、CPU和网络资源消耗的值,然后根据这些消耗的成本选择一条执行路径。
Cardinality 是CBO特有概念,指的是指定结果集的行数。与SQL执行计划的某个执行步骤相对应。用于对目标SQL的某个执行步骤的执行结果包含的记录数进行估算。对于整个SQL,是最终执行结果包含的记录数。这个值越大,标识着结果集所消耗的IO越多。对应的成本一般也会越大。这个执行路径的总的成本也会越大。
可选择率,是CBO特有的概念。指的是加上WHERE条件后返回的结果集的数量与不加条件返回的原始结果集的记录数比值。这个值的取值范围是0~1 计算公式如下:
施加谓语条件得到的记录数
可选择率 = --------------------------------------------------
未施加谓语条件返回的原始记录数
可选择率和成本的估算关系是:可选择率越大,对应的结果集行数也会越大。可选择率越大,执行步骤估算的成本值也就越大,这个执行路径对应的总成本也会越大。
可传递性,依然是CBO特有概念。CBO在拿到SQL语句后的第一件事,就是对SQL进行等价改写。即在SQL上添加根据现有条件推导出来的新的谓语条件,SQL在进行执行路径选择的时候,就会将推导出来的谓词条件对应的执行步骤也进行计算。可能会得到一个成本比原来的谓词条件成本更低的执行路径。从而选择更优的执行计划。关于可传递性,分为三种情况:
简单谓词传递;
连接谓词传递;
外连接谓词传递;
CBO的优点:
(1)即使没有理解优化器的工作原理,大多数情况下也能得到最优化的性能。
(2)通过统计信息控制优化。
CBO解决了RBO的先天缺陷,并且越来越智能,但是仍然有很多可以优化的地方,如:
CBO认为SQL的where条件出现的各个列相互独立,没有关联。CBO对于每个列单独进行成本计算,然后通过执行成本来选择执行计划,但是很多列有时候是相关联的,单独计算可能会导致执行计划出现偏差,选错执行计划。
CBO选择执行计划的时候,只考虑当前SQL。 CBO假设所有SQL都是单独执行,互不干扰的,但很多时候,执行目标SQL需要的数据块、索引叶子块等数据可能已经被缓存到了Buffer Cache中了,单独计算可能也会导致选择不到最优的执行计划。
CBO在直方图统计方面有诸多限制。
CBO在处理多表关联的SQL时,可能会漏选执行计划。在关联的表越多的情况下,执行路径的总数量也会成倍数增长。例如:假如一个表只有1个执行分支可供选择,那么两个表(t1,t2)就是有 t1-t2(先执行t1条件,然后筛选t2条件) 和 t2-t1(先执行t2条件,然后筛选t1条件 两个执行路径。如果是三个表(t1,t2,t3)那么就会有6种组合,如果是四个表那么就有24种组合,其计算方式为:表格数量的阶乘。那么如果有十几个二十个表的时候,则会有百亿级别的执行路径。如果把所有执行路径全部执行一遍,则选择器会耗费相当巨大的时间。所以Oracle在执行CBO的时候,会有最大选择路径的隐含参数。
【例14-2】创建表t1和t2,插入测试记录。两表进行关联,查看执行计划。
创建表代码如下:
–第十四章\yhgl.sql
create table t1(c1 number,c2 varchar2(10));
CREATE table t2(c1 number,c2 VARCHAR2(10));
t2表中创建索引,代码如下:
CREATE index idx_t2 on t2 (c1);
往表中插入一些数据,代码如下:
insert into t1 values (15,‘美妆博主’);
insert into t1 values (10,‘母婴博主’);
insert into t1 values (20,‘家居博主’);
insert into t1 values (10,‘mcn’);
Commit;
查看执行计划,代码如下:
EXPLAIN PLAN FOR
SELECT t1.C1,t2.c2 FROM T1,t2 WHERE t1.C1 = t2.C1 and t1.C1 =10;
SELECT * FROM TABLE(dbms_xplan.display);
执行后如图14-2所示。
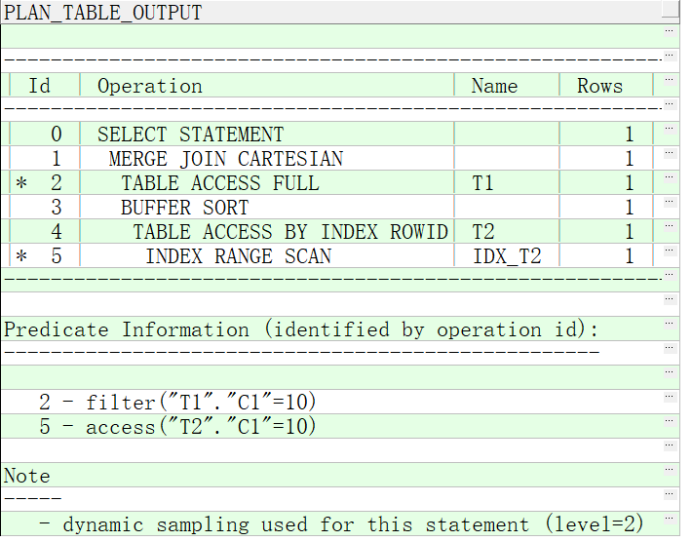
图14-2执行计划
在执行计划id为5的执行计划中可以看到Oracle执行计划通过索引进行了范围扫描。而这个步骤所对应的查询条件是 access(“T2”.“C1”=10)。 这个条件说明执行计划生成的谓词条件中有t2.c1=10 这个谓词条件,但原SQL中并不包含该条件。说明CBO确实对SQL语句进行了改写。而改写后的SQL条件可以使用t2表的索引,这有利于提高SQL语句的执行效率。改写后的SQL,代码如下:
SELECT t1.C1,t2.c2 FROM T1,t2 WHERE t1.C1 = t2.C1 and t1.C1 =10 and t2.c1 = 10;
Oracle 优化器模式可以切换,切换当前session的优化器模式,代码如下:
ALTER SESSION SET OPTIMIZER_MODE=‘RULE’
其中,OPTIMIZER_MODE的各个值如下:
RULE:使用RBO来解析目标SQL。
CHOOSE:9i 的默认值,表示在执行SQL语句时,选择那个RBO还是CBO取决于对象是否具有统计信息。
FIRST_ROWS_n(n= 1,10,100,1000) :使用CBO进行执行,并且在执行时,以最快的响应速度,返回前n条记录。
ALL_ROWS: 10g 及以后的默认值,表示使用CBO来解析目标SQL,且挑选执行计划时,侧重计算执行路径成本值。