Chain-of-Draft (CoD) 是提示工程的新王者

图像由 DALL·E 3 生成
推理型大模型,是当前 AI 研究的热门话题。
我们从最早的 GPT-1 一路走到现在像 Grok-3 这样的高级推理模型。
这段旅程可以说非常精彩,过程中也发现了很多重要的推理方法。
其中之一就是 Chain-of-Thought(CoT)提示法(包括 few-shot 和 zero-shot),它引领了如今大模型推理的革命。
令人兴奋的是,现在又有了一个更强的新技术,由 Zoom Communications 的研究人员提出。
这个方法叫做 Chain-of-Draft(CoD)提示法,在回答问题时,仅用到 7.6% 的推理 token 就能在准确率上超过 CoT。
📌 本文是一线工程实践中挖掘出的前沿提示技术思路。
🔧 技术实战派|AI软硬件一体解决者
🧠 从芯片设计、电路开发、GPU部署 → Linux系统、推理引擎 → AI模型训练与应用
🚀 10年工程经验 + 商业认知,带你看懂真正落地的 AI 技术
📩 学AI?做AI项目?买AI训练推理设备?欢迎关注私信。
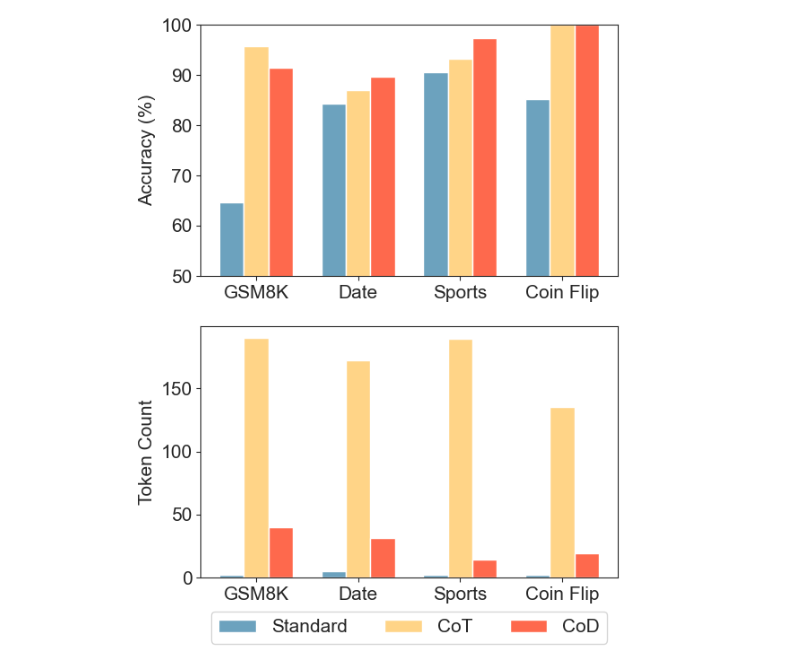
Claude 3.5 Sonnet 在不同推理任务中,使用标准提示(直接回答)、CoT 和 CoD 的准确率与 token 使用量对比
对于目前非常冗长、计算时间多、延迟高的大模型推理来说,这个方法可以说是一个巨大胜利。现实中很多对时间要求高的任务,都会受限于这些瓶颈。
我们下面就来讲个故事,深入看看 Chain-of-Draft(CoD)提示法到底是怎么运作的,以及你要怎么用它让你的 LLM 更加准确、更加省 token,前所未有。
但先说一下提示工程这回事
研究人员一直在不断探索 LLM 中的新行为。
从 Transformer 演变到生成式预训练模型 GPT,我们很快就发现,把模型扩展到 GPT-2(15 亿参数)后,它就能表现出无监督多任务学习能力(无需监督学习/任务专属数据集的微调,也能执行多种任务)。
当进一步扩展到 GPT-3(1750 亿参数)后,人们发现只要在输入中给出几个例子,它就能很快适应并很好地完成新任务(Few-shot 提示法)。
后来又有人发现,如果把问题拆解成中间推理步骤,并让大模型去生成这些步骤,就能在算术、常识、符号推理任务中达到 SOTA(state-of-the-art)性能。
这个方法就是 Chain-of-Thought(CoT)提示法。
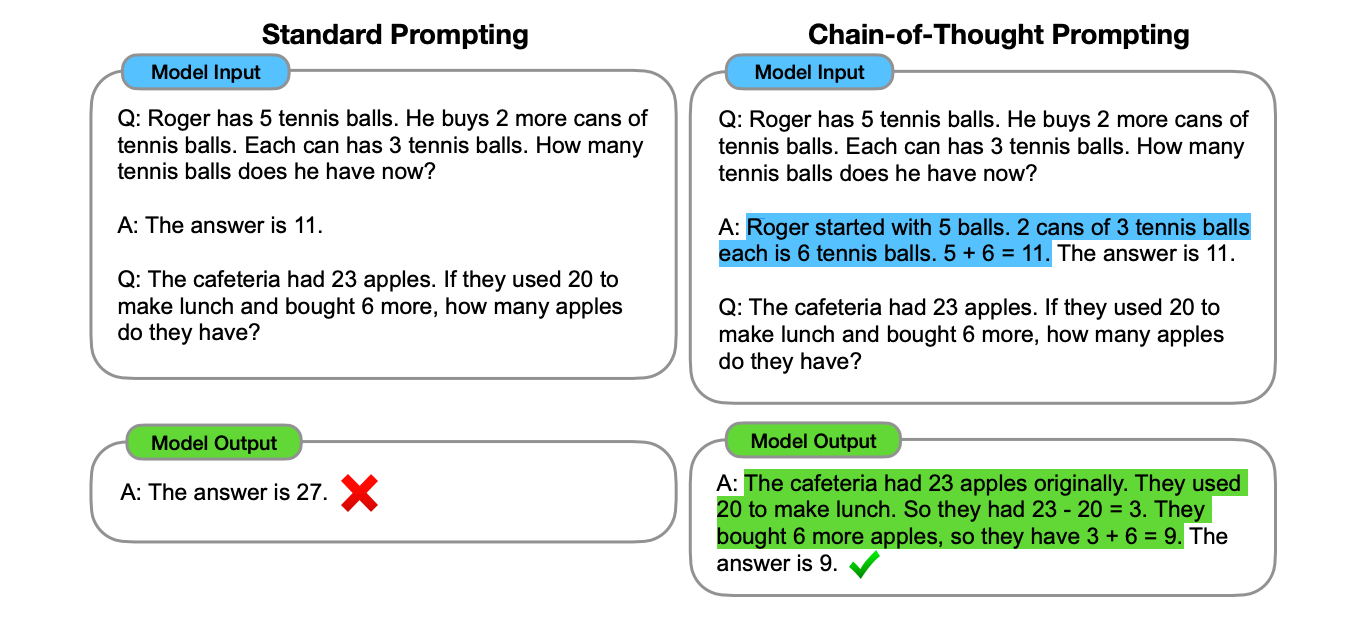
标准提示法 vs CoT 提示法示例(图片来自 ArXiv 论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》)
CoT 提出后,很快就发现其实 LLM 是 Zero-shot 推理者。
也就是说,和最初 CoT 方法不一样,它们并不需要提前看到几个推理例子,才能有更好的表现。
只要在提示中加上“Let’s think step by step(让我们一步一步来思考)”这样的短语,它们就能一步一步地推理解决问题。
这个方法叫做 Zero-shot Chain-of-Thought 提示法。

标准 Zero-shot / Few-shot、原始 CoT 和 Zero-shot CoT 的对比图(图片来自 ArXiv 论文《Large Language Models are Zero-Shot Reasoners》)
后来研究人员发现,只用链式推理和贪婪解码还不够。
复杂推理任务可能会有多条不同的路径能得出正确答案——如果多条路径都得出一样的结果,那我们就可以更有信心相信这个答案是对的。
这就带来了一个新的解码策略:Self-Consistency(自洽性),通过对模型进行多次采样,生成多条推理路径,然后选择其中最一致的结果作为最终答案。
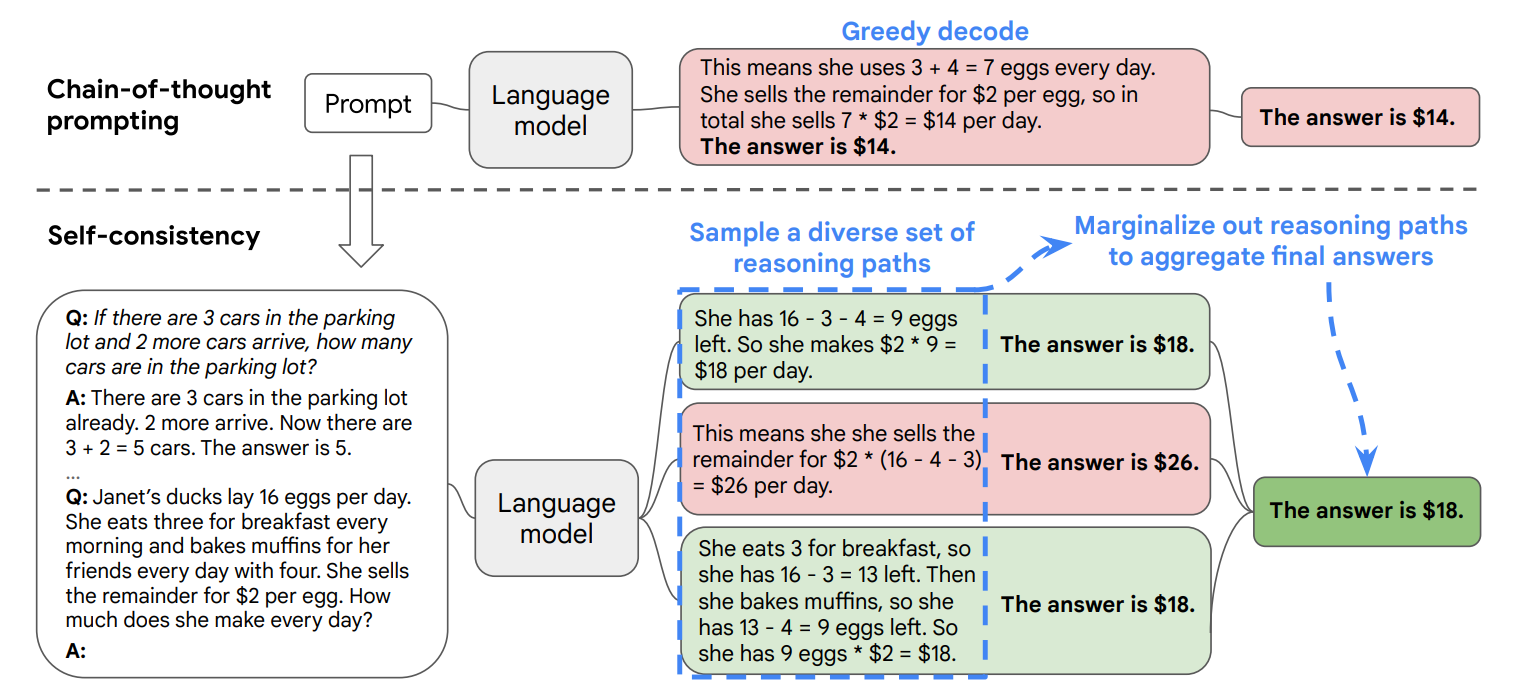
CoT 中的贪婪解码 vs 自洽性解码(图片来自 ArXiv 论文《Self-Consistency Improves Chain of Thought Reasoning in Language Models》)
提示结构开始出现架构化
在引入多路径推理的思路下,研究人员提出了 Tree-of-Thoughts(ToT)框架,它采用类似树状结构的方式来探索解题空间。
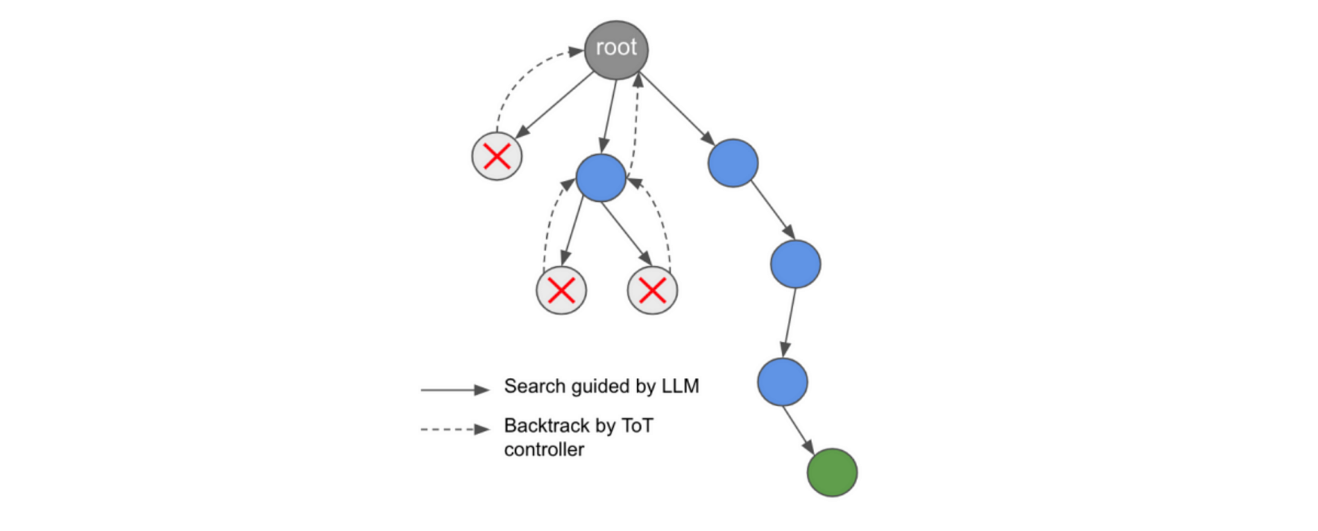
Tree-of-Thought 框架图示(图片来自 ArXiv 论文《Large Language Model Guided Tree-of-Thought》)
它使用名为“Thoughts”的语言片段作为解题过程中的中间步骤。这些步骤会借助搜索算法进行评估,并在必要时进行前瞻与回溯操作。
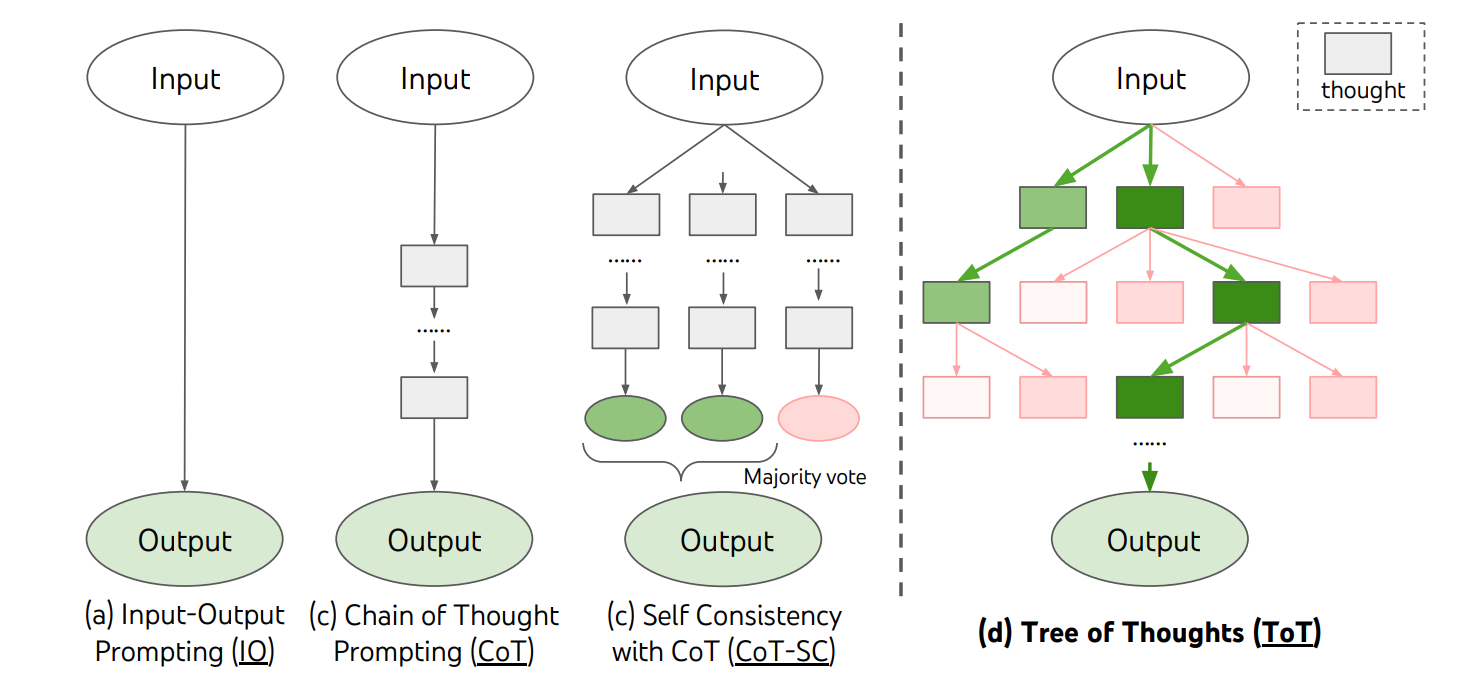
各种推理方法对比(图片来自 ArXiv 论文《Tree of Thoughts: Deliberate Problem Solving with Large Language Models》)
后来人们又用图代替树,提出了 Graph-of-Thoughts 框架,更好地建模解题空间。
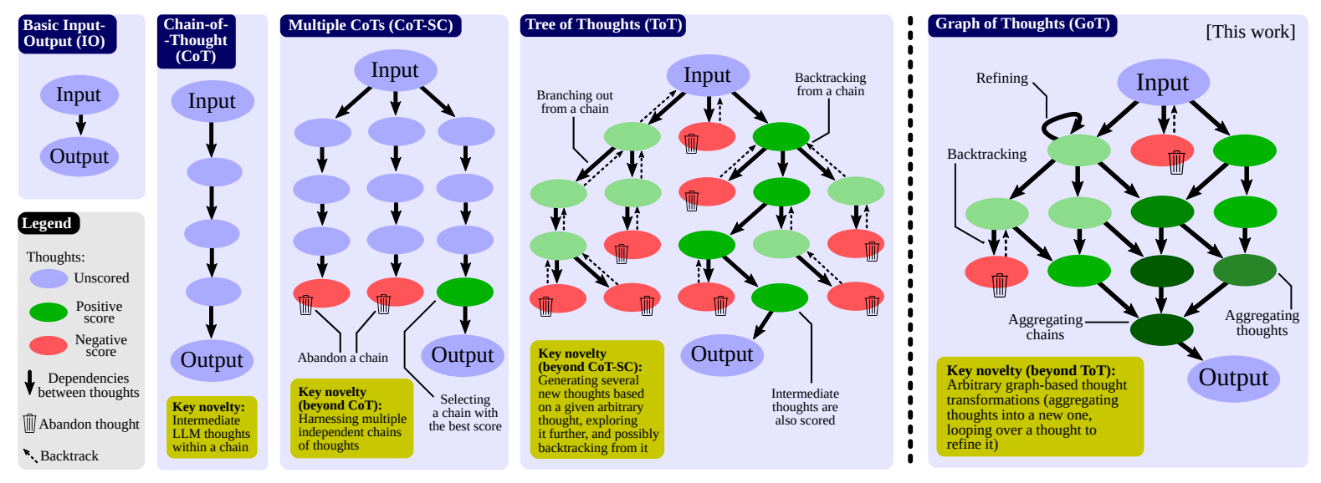
Graph-of-Thought 与其他推理方法对比(图片来自 ArXiv 论文《Graph of Thoughts: Solving Elaborate Problems with Large Language Models》)
🌱 借助这些推理框架设计大模型系统,已经逐渐成为实践派的核心思路。
如果你也在思考如何将提示工程落地到产品流程中:
🔧 我专注于 AI 模型部署与集成落地,从推理引擎到模型训练,从硬件设计到系统平台搭建。
📩 需要交流项目经验?后台私信我,愿意为你提供一对一建议。
但这还没完!
提示并不是帮助 LLM 提高推理能力的唯一方式,还有很多其他方法,可以参考这篇综述。
那延迟怎么办?
探索推理空间是个计算开销很大的任务,会显著增加响应延迟。
于是有了一个叫 Skeleton-of-Thought(SoT)的思路,先让 LLM 生成一个回答的“骨架”或提纲。
然后再并行调用 API 或用 batch 解码,来补充每个骨架点的内容。
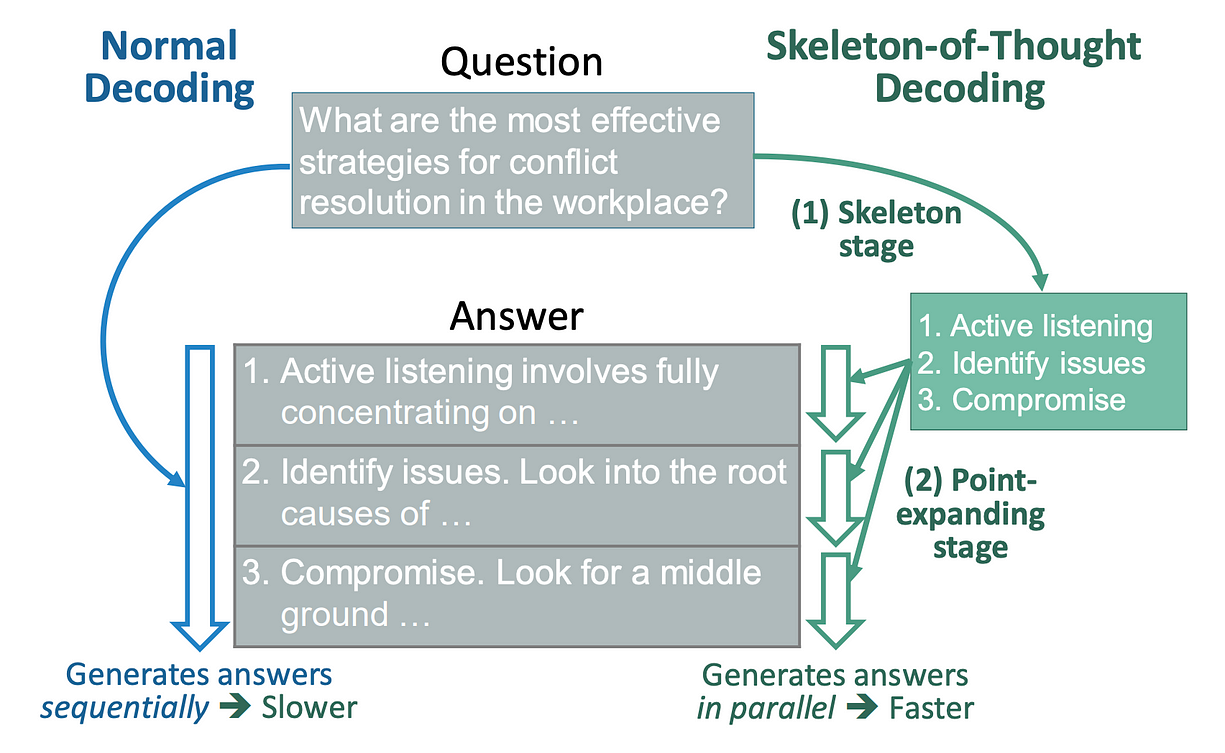
Skeleton-of-Thought(SoT)整体思路与标准解码方式的对比图(图片来自 ArXiv 论文《Skeleton-of-Thought: Prompting LLMs for Efficient Parallel Generation》)
推理模型有时候还会对简单问题“想太多”,生成很多没必要的推理 token,导致响应时间变长。
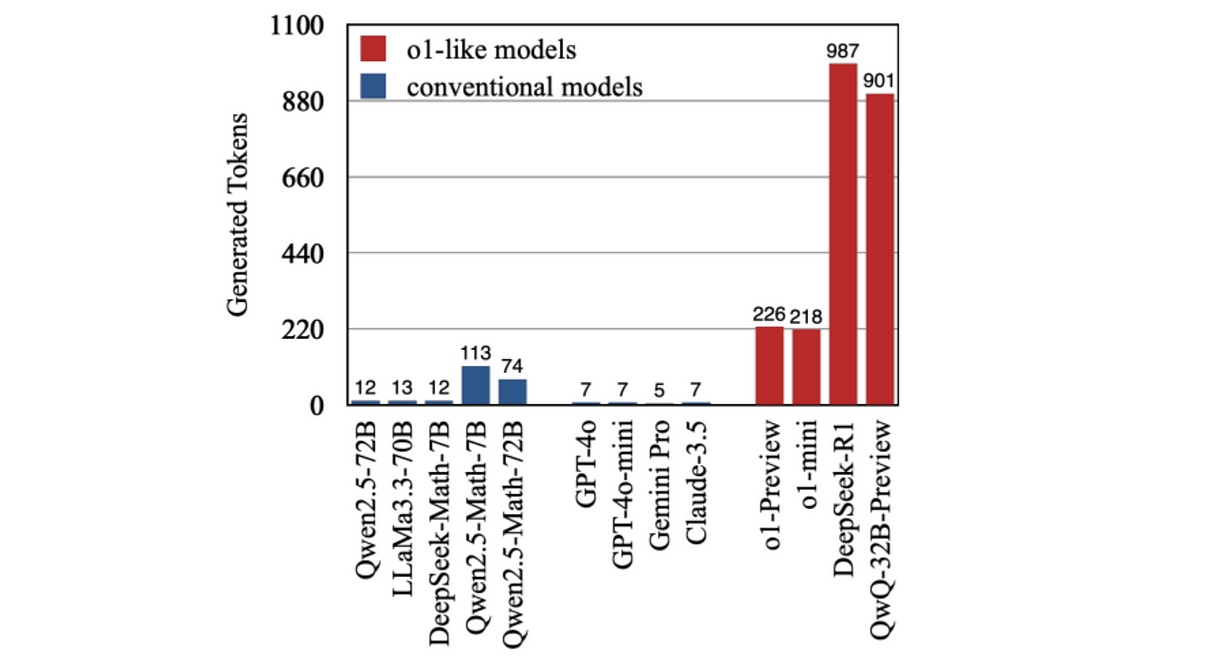
例题“2+3=?”生成的 token(图片来自 ArXiv 论文《Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs》)
QwQ-32-B-Preview 模型为了解这个简单的加法问题居然推理得这么复杂,是不是很离谱?

QwQ-32-B-Preview 在简单算术问题上的“过度思考”(图片来自同上论文)
为了解决这个问题,有人尝试通过限制推理 token 的预算来控制模型行为,但 LLM 经常不听话。
也有人引入另一个 LLM,先根据问题复杂度动态估算 token 预算,然后再回答问题——但这反而又增加了延迟。
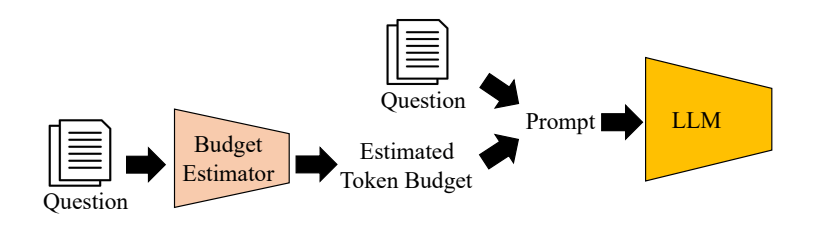
Token-Budget-Aware LLM Reasoning(TALE)整体框架(图片来自 ArXiv 论文《Token-Budget-Aware LLM Reasoning》)
有没有办法把这些经验都融合起来,简化成一个统一的方法?
这就是 Chain-of-Draft(CoD)提示的诞生
回到原点,CoT 是一个非常出色的推理提示方式。
但它太啰嗦了,模型在回答前可能会生成几千个推理 token。
这其实不符合人类的思维方式。
人类在推理时通常不会说那么多话,而是倾向于把最核心的中间思路简单记下来(draft)。
这就是 Chain-of-Draft(CoD)提示的灵感来源。
它只要求模型一步一步思考,并限制每一步推理不超过五个词。
为了让模型明白怎么做,研究人员手工写了一些 Chain-of-Draft 的 few-shot 示例,放进提示中。
令人意外的是,这个限制并不是通过硬性手段强加的,模型只是通过 prompt 被“建议”这么做。
这和传统 few-shot 提示不同,后者通常是提供一堆 query-response 对,让模型直接回答问题,不需要解释。
也和 CoT 不一样,CoT 提供了 query-response 中间推理步骤,然后让模型回答问题。
这几种方式的区别,可以从下面的图片中更直观地感受到,都是让模型解一个简单算术题。



那 CoD 的效果到底怎么样?
研究人员用 GPT-4o 和 Claude 3.5 Sonnet,分别用三种方式来进行提示测试。
每种提示方法对应的 system prompt 如下图所示:

Standard、CoT 和 CoD 的 system prompt 对比图
CoD 在算术推理任务 GSM8K 数据集上达到了 91% 的准确率,同时比 CoT 减少了 80% 的 token 使用量,在几乎不损失准确率的前提下显著降低延迟(GPT-4o 中,CoD 为 91.1%,CoT 为 95.4%)。
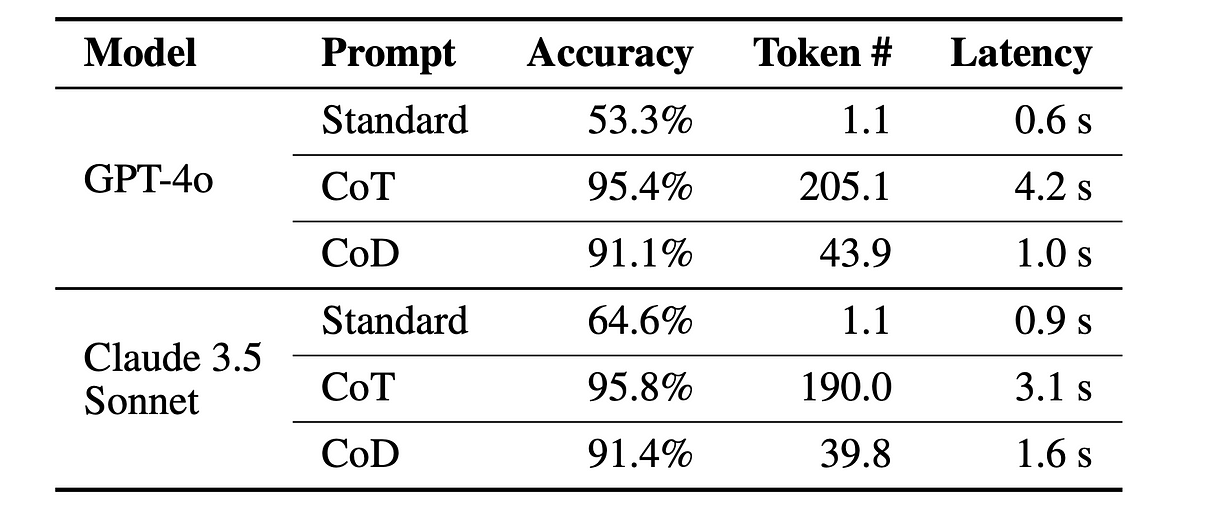
不同提示方法在 GSM8K 测试集上的评估结果
在 BIG-bench 的常识推理任务(日期与体育理解)中,CoD 在保持甚至提升准确率的同时,大大降低了延迟和 token 使用量。
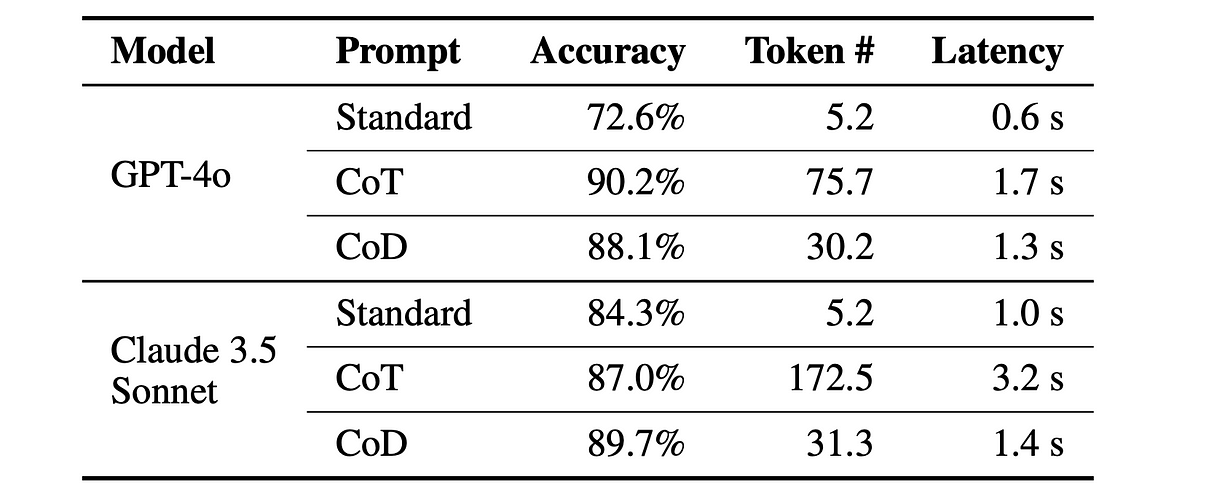
BIG-bench 日期理解任务评估结果
注意看,在体育理解任务上,用 Claude 3.5 Sonnet 提示时,CoD 把 CoT 平均输出 token 从 189.4 个压缩到了 14.3 个,缩减了 92.4%,是不是太强了!
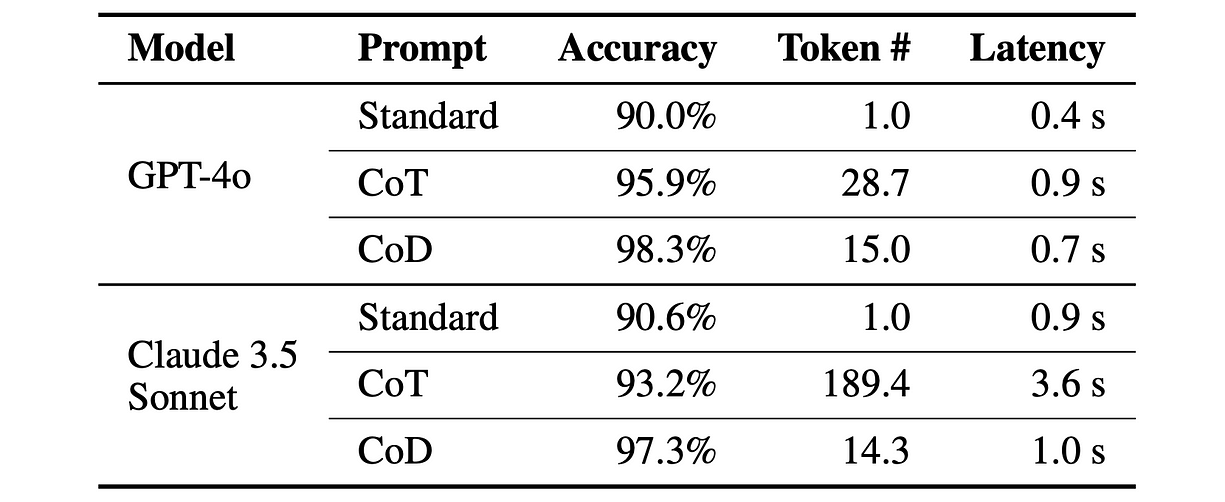
BIG-bench 体育理解任务评估结果
最后,在符号推理任务“抛硬币”测试中(预测一系列翻转后硬币的最终状态),CoD 的准确率达到 100%,同时使用的 token 显著少于其他方法。

研究者构建的 Coin-flipping 数据集示例
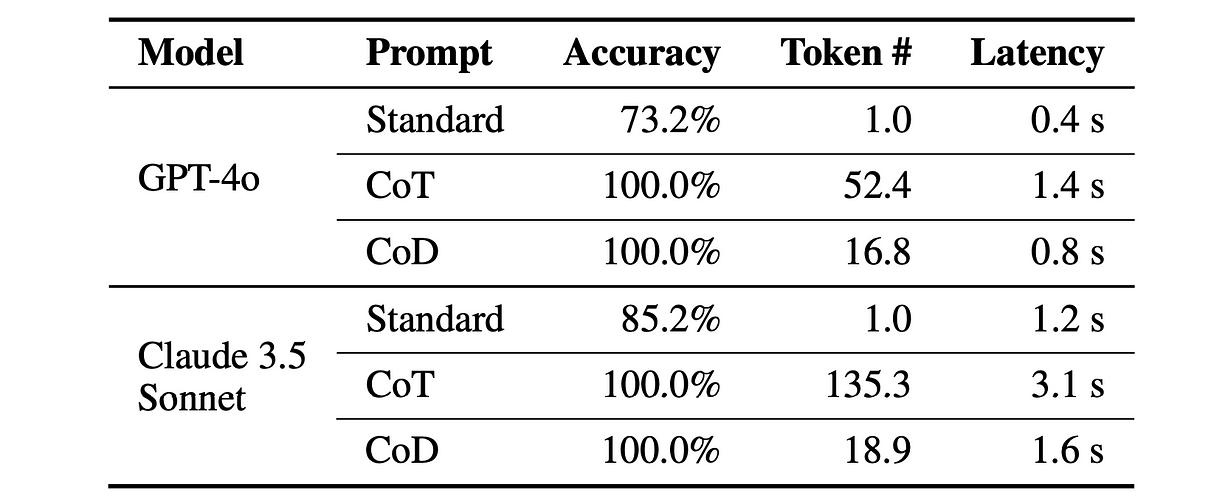
研究者构建的 250 条 Coin-flip 测试集上的评估结果
这些结果简直炸裂!
CoD 提示方式不仅能带来超高准确率,还极大减少了延迟,非常适用于对时间与算力有要求的应用场景。
这些 CoD 数据还可以用于训练 LLM,让它们在推理时表现得更好(比如借鉴 DeepSeek-R1 的强化学习训练方式),从而让模型变得更快、更省、更强、更可扩展。
🤖 CoD 提示的提出不仅优化了推理过程,也启发我们重新思考“工程落地”这件事:
怎么让模型更快、更便宜、更准确地为产品服务?
📌 这正是我过去10年工程路径的关注重点。
🔧 技术实战派|AI软硬件一体解决者
🧠 从芯片设计、电路开发、GPU部署 → Linux系统、推理引擎 → AI模型训练与应用
🚀 想搞懂真正能落地的AI系统?欢迎关注我,私信“AI落地”获取资料包