n8n 中 Compare Datasets 节点使用详解
n8n 中 Compare Datasets 节点使用详解
- 一、节点核心参数配置
- 1. 指定对比字段
- 2. 差异处理策略
- 二、模糊比较与精确比较
- Fuzzy Compare(模糊比较)
- 三、项比较的双阶段逻辑
- 四、节点高级选项详解
- 1. 跳过对比的字段(Fields to Skip Comparing)
- 2. 禁用点号表示法(Disable Dot Notation)
- 3. 处理重复数据(Multiple Matches)
- 五、输出结果分类解析
- 六、典型应用场景
- 七、注意事项
- 八、总结
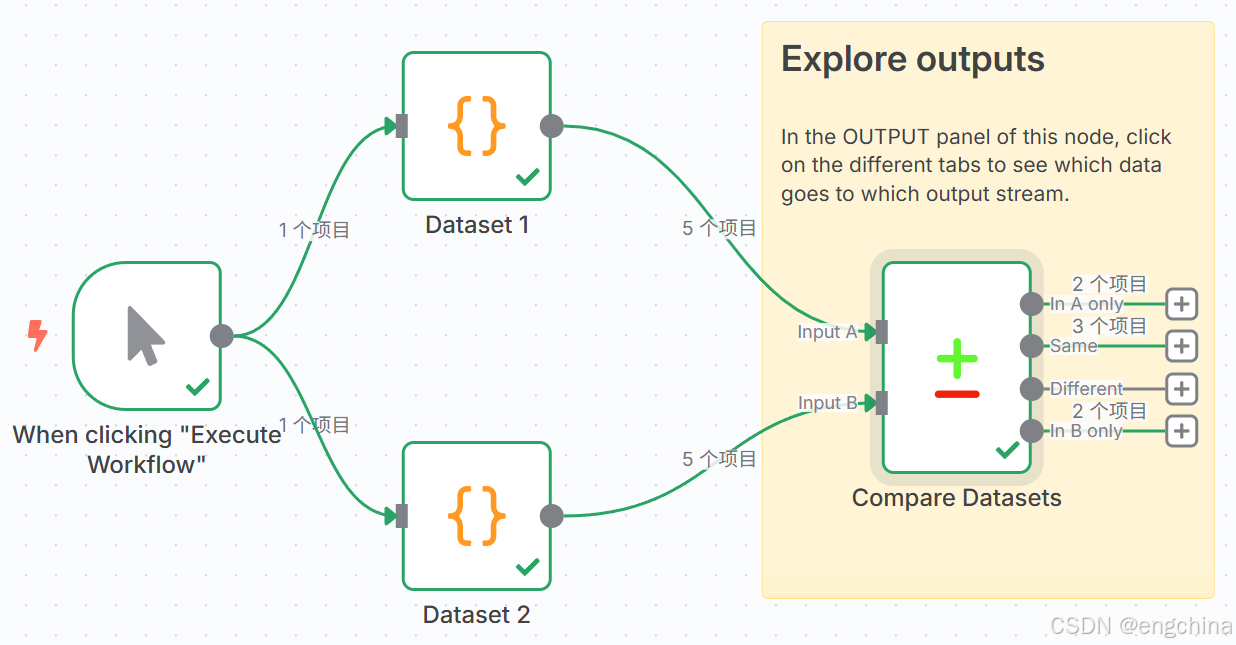
在数据处理过程中,经常需要对两个数据集进行对比分析。n8n 的 Compare Datasets 节点为开发者提供了强大的数据集对比功能,能够快速识别两个输入流中的相同、差异和唯一数据。本文将详细解析该节点的配置参数、比较逻辑及输出结构,帮助开发者高效利用这一工具。
一、节点核心参数配置
1. 指定对比字段
- Input A Field:选择输入流A中需要对比的字段名称(如
person.name)。 - Input B Field:选择输入流B中需要对比的字段名称(如
person.name)。 - 多字段对比:通过 Add Fields to Match 添加多个对比字段,实现复合条件匹配。
示例:若对比
person.language字段,当输入流A的language为de,输入流B的language为en时,系统会判定为不同数据。
2. 差异处理策略
提供四种差异处理模式:
- Use Input A Version:以输入流A为数据源(优先保留A的值)。
- Use Input B Version:以输入流B为数据源(优先保留B的值)。
- Mix of Versions:
- 通过 Prefer 选择主数据源(A或B)。
- 在 For Everything Except 中指定例外字段,从另一数据源获取值。
- Include Both Versions:同时保留A和B的值,输出结构会更复杂但保留完整数据。
二、模糊比较与精确比较
Fuzzy Compare(模糊比较)
- 开启后:允许字段类型差异的容忍度。例如:
- 数字
3与字符串"3"被视为相同。 - 日期格式差异(如
2023-01-01与2023/01/01)也会被识别为匹配。<
- 数字