PCA降维详解
1. PCA基本概念
**主成分分析(Principal Component Analysis, PCA)**是一种常用的无监督降维技术,通过线性变换将高维数据投影到低维空间,同时保留数据的主要特征。
核心思想
- 将原始特征空间中的相关变量转换为线性不相关的新变量(主成分)
- 按照方差大小排序主成分,保留方差大的成分,舍弃方差小的成分
- 新变量是原始变量的线性组合
2. PCA数学原理
2.1 数据标准化
首先对数据进行中心化处理(均值为0):
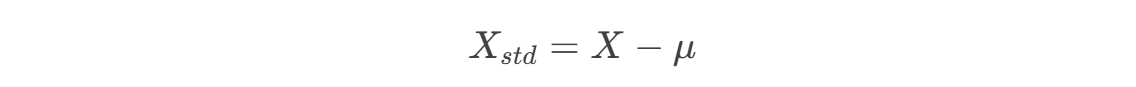
2.2 计算协方差矩阵
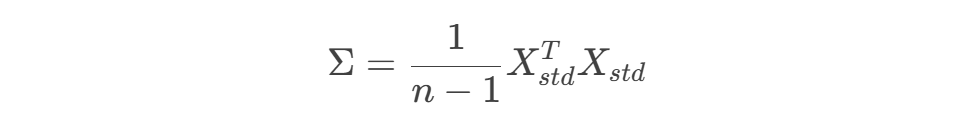
2.3 特征值分解
求解协方差矩阵的特征值和特征向量:
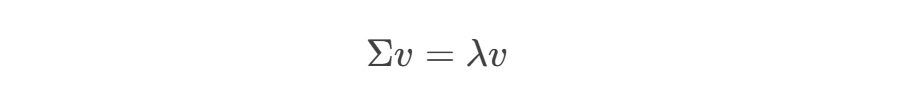
其中:
- λ是特征值(表示主成分的方差大小)
- v是对应的特征向量(表示主成分方向)
2.4 选择主成分
按特征值从大到小排序,选择前k个特征值对应的特征向量组成投影矩阵W
2.5 数据转换
将原始数据投影到新的低维空间:
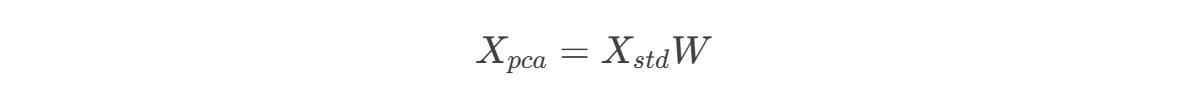
3. PCA在Python中的实现
3.1 使用scikit-learn实现PCA
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt# 加载数据
iris = load_iris()
X = iris.data
y = iris.target# 数据标准化
scaler = StandardScaler()
X_std = scaler.fit_transform(X)# 应用PCA
pca = PCA(n_components=2) # 降为2维
X_pca = pca.fit_transform(X_std)# 可视化
plt.figure(figsize=(8,6))
plt.scatter(X_pca[:,0], X_pca[:,1], c=y, cmap='viridis')
plt.xlabel('First Principal Component')
plt.ylabel('Second Principal Component')
plt.title('PCA of IRIS Dataset')
plt.colorbar()
plt.show()
3.2 重要属性解释
# 解释方差比例
print("解释方差比例:", pca.explained_variance_ratio_)# 累计解释方差比例
print("累计解释方差比例:", sum(pca.explained_variance_ratio_))# 主成分方向(特征向量)
print("主成分方向:\n", pca.components_)# 特征值
print("特征值:", pca.explained_variance_)
4. PCA关键参数
n_components
- 要保留的主成分数量
- 可以设为整数,也可以设为0-1之间的小数(表示保留的方差比例)
whiten
- 是否对数据进行白化处理(使每个特征的方差为1)
svd_solver
- SVD求解器选择:‘auto’, ‘full’, ‘arpack’, ‘randomized’
5. PCA应用场景
- 数据可视化:将高维数据降为2D/3D便于可视化
- 特征提取:减少特征数量,提高模型效率
- 去噪:去除方差小的成分可能包含的噪声
- 数据压缩:减少存储空间需求
6. PCA优缺点
优点
- 降低数据复杂度,提高算法效率
- 去除特征间的相关性
- 改善过拟合问题
- 无需标签信息(无监督)
缺点
- 主成分解释性可能较差
- 对异常值敏感
- 线性假设可能不适用于所有数据
- 丢失部分信息(非线性结构)
7. PCA实战技巧
7.1 如何选择主成分数量
# 绘制碎石图(Scree Plot)帮助选择
pca = PCA().fit(X_std)
plt.plot(np.cumsum(pca.explained_variance_ratio_))
plt.xlabel('Number of Components')
plt.ylabel('Cumulative Explained Variance')
plt.show()
通常选择累计解释方差达到85%-95%的主成分数量。
7.2 核PCA(Kernel PCA)
对于非线性数据,可以使用核技巧:
from sklearn.decomposition import KernelPCAkpca = KernelPCA(n_components=2, kernel='rbf', gamma=15)
X_kpca = kpca.fit_transform(X_std)
8. 注意事项
- 数据标准化:PCA对数据尺度敏感,必须先标准化
- 信息损失:降维必然导致信息损失,需权衡
- 解释性:主成分是原始特征的线性组合,物理意义可能不明确
- 异常值处理:PCA对异常值敏感,需预先处理
PCA是数据预处理和特征工程的强大工具,合理使用可以显著提高机器学习模型的性能和可解释性。