Gradio全解20——Streaming:流式传输的多媒体应用(4)——基于Groq的带自动语音检测功能的多模态Gradio应用
Gradio全解20——Streaming:流式传输的多媒体应用(4)——基于Groq的带自动语音检测功能的多模态Gradio应用
- 本篇摘要
- 20. Streaming:流式传输的多媒体应用
- 20.4 基于Groq的带自动语音检测功能的多模态Gradio应用
- 20.4.1 组件及配置
- 1. 核心组件
- 2. 环境配置
- 20.4.2 构建步骤
- 1. 无缝对话的状态管理
- 2. 在Groq上使用Whisper转录音频
- 3. 通过LLM集成添加对话智能
- 4. 使用语音活动检测实现免提交互
- 5. 使用Gradio构建用户界面
- 6. 处理录音和响应
- 20.4.4 操作运行
- 参考文献:
本章目录如下:
- 《Gradio全解20——Streaming:流式传输的多媒体应用(1)——流式传输音频:魔力8号球》;
- 《Gradio全解20——Streaming:流式传输的多媒体应用(2)——构建对话式聊天机器人》;
- 《Gradio全解20——Streaming:流式传输的多媒体应用(3)——实时语音识别技术》;
- 《Gradio全解20——Streaming:流式传输的多媒体应用(4)——基于Groq的带自动语音检测功能的多模态Gradio应用》;
- 《Gradio全解20——Streaming:流式传输的多媒体应用(5)——基于WebRTC的摄像头实时目标检测》;
- 《Gradio全解20——Streaming:流式传输的多媒体应用(6)——构建视频流目标检测系统》。
本篇摘要
本章讲述流式传输的应用,包括音频、图像和视频格式的流式传输。
20. Streaming:流式传输的多媒体应用
本章讲述流式传输的应用,包括音频、图像和视频格式的流式传输。音频应用包括流式传输音频、构建音频对话式聊天机器人、实时语音识别技术和自动语音检测功能;图像应用包括基于WebRTC的摄像头实时目标检测;视频应用包括构建视频流目标检测系统。
20.4 基于Groq的带自动语音检测功能的多模态Gradio应用
多数语音应用程序目前的工作方式是用户点击录制按钮后说话,然后停止录制。虽然这种方式很有效,但与语音交互最自然的方式是应用程序动态检测用户何时在说话,以便用户无需持续点击录制按钮即可进行双向对话。现代语音应用应当突破传统的"点击录音"模式,实现更自然流畅的交互体验。通过结合Groq的高速推理能力和自动语音检测技术,我们可以构建一种更直观的交互模式——用户只需随时开口说话,即可与AI进行交互。
本节将讲解如何开发一个集成Groq和自动语音检测功能的多模态Gradio应用,读者也可以通过youtube视频教程观看完整应用演示: Building a Multimodal Voice Enabled Calorie Tracking App with Groq and Gradio。需要鸣谢的是,本项目的语音活动检测(VAD)和Gradio代码参考了WillHeld的Diva-audio-chat项目,项目地址:WillHeld/diva-audio-chat。
20.4.1 组件及配置
在开始之前,先讲解下需要用到的核心组件,然后进行环境配置。
1. 核心组件
创建语音与文本的自然交互需要动态且低延迟的响应,因此我们需要自动语音检测和快速推理。借助@ricky0123/vad-web自动语音检测以及Groq极快响应速度,这两个要求都得到了满足,而Gradio则便于创建功能强大的应用程序。
本节将向读者展示如何构建一个卡路里跟踪应用程序,在该应用中,用户可以随时与AI对话,AI会自动检测用户开始和停止对话的时间,并提供文本响应,还可以通过提问引导用户,以便用户对上一餐进行卡路里估算。
本应用的核心组件有:
- Gradio:提供Web界面与音频处理能力;
- @ricky0123/vad-web:实现语音活动检测(VAD)功能;
- Groq:为自然对话提供高速的大语言模型推理支持;
- Whisper:完成语音到文本的转换。
@ricky0123/vad-web是基于Javascript的语音活动检测(Voice Activity Detection:VAD),它仅需几行代码即可实现对包含用户语音的音频片段执行回调。本软件包旨在提供可在浏览器中运行的精准、用户友好的语音活动检测器(VAD),通过该软件包,用户可以请求用户授予麦克风权限、开始音频录制、将有语音的音频片段发送至服务器处理、在用户说话时显示特定动画或指示器
(注:为专注于浏览器应用场景,已决定停止对Node环境的支持)。底层实现基于ONNX Runtime Web/ONNX Runtime Node.js之上运行Silero VAD,更多信息参阅Voice Activity Detection for Javascript。
Groq创立于2016年,提供云端和本地AI计算中心的高速AI推理服务,其核心产品是LPU(Language Processing Unit),这是一款专为大型语言模型推理设计的专用ASIC芯片。Groq的LPU以其高性能和成本效益著称,能够在AI推理领域挑战传统GPU的统治地位。Groq的模型广泛应用于自然语言处理任务,包括文本生成、翻译和情感分析等。其API支持多种语言转录和翻译,特别适合需要高速响应的实时应用场景35。此外,Groq还提供了免费的Whisper Large-V3模型,支持语音转文本和翻译功能,用户可以通过其Playground或本地项目中使用API进行体验。关于Groq使用请参考:Groq - Text Chat - Chat Completion Models,API免费申请地址:https://console.groq.com/keys。
Whisper是由OpenAI的Alec Radford等人提出的先进自动语音识别(ASR)与语音翻译模型,相关论文为《Robust Speech Recognition via Large-Scale Weak Supervision 》,该模型在超过500万小时的标注数据上训练而成,展现出强大的零样本泛化能力,可适应多种数据集和领域,更多信息请参阅:openai/whisper-large-v3-turbo。
2. 环境配置
首先安装并导入核心库,同时配置Groq API客户端:
requirements.txt
gradio groq numpy soundfile librosa spaces xxhash datasets
app.py
import groq
import gradio as gr
import soundfile as sf
from dataclasses import dataclass, field
import os# Initialize Groq client securely
os.environ["GROQ_API_KEY"] = "your groq api key"
api_key = os.environ.get("GROQ_API_KEY")
if not api_key:raise ValueError("Please set the GROQ_API_KEY environment variable.")
client = groq.Client(api_key=api_key)
这里我们引入了关键库以与Groq API交互,使用Gradio构建一个流畅的用户界面并处理音频数据。我们通过环境变量安全地访问Groq API密钥,这是避免API密钥泄露的最佳安全实践。
20.4.2 构建步骤
此应用构建较为繁琐,下面逐步讲解。
1. 无缝对话的状态管理
为保持对话历史记录(使聊天机器人记住过往交互)并管理录音状态(如当前是否激活录音)等,我们需要创建AppState类:
@dataclass
class AppState:conversation: list = field(default_factory=list)stopped: bool = Falsemodel_outs: Any = None
该AppState类是管理对话历史和跟踪录音状态的有效工具,每个实例将维护独立的会话列表,确保聊天历史隔离在各自会话中。
2. 在Groq上使用Whisper转录音频
接下来,我们将创建一个函数,使用Groq上托管的强大转录模型Whisper将用户的音频输入转录为文本。此转录还将帮助我们判断输入中是否包含有意义的语音,以下是具体方法:
def transcribe_audio(client, file_name):if file_name is None:return Nonetry:with open(file_name, "rb") as audio_file:response = client.audio.transcriptions.with_raw_response.create(model="whisper-large-v3-turbo",file=("audio.wav", audio_file),response_format="verbose_json",)completion = process_whisper_response(response.parse())return completionexcept Exception as e:print(f"Error in transcription: {e}")return f"Error in transcription: {str(e)}"
此函数打开音频文件并将其发送到Groq的Whisper模型进行转录,同时请求详细的JSON输出;这里需要verbose_json以获取信息来判断音频中是否包含语音。我们还会处理任何潜在的错误,以确保如果API请求出现问题,应用程序不会完全崩溃。对于Whisper模型返回的信息需要进一步处理,处理函数process_whisper_response实现如下:
def process_whisper_response(completion):"""Process Whisper transcription response and return text or null based on no_speech_probArgs:completion: Whisper transcription response objectReturns:str or None: Transcribed text if no_speech_prob <= 0.7, otherwise None"""if completion.segments and len(completion.segments) > 0:no_speech_prob = completion.segments[0].get('no_speech_prob', 0)print("No speech prob:", no_speech_prob)if no_speech_prob > 0.7:return Nonereturn completion.text.strip()return None
这里解读音频数据响应。process_whisper_response函数接收Whisper返回的完成结果,并检查音频是仅包含背景噪音还是包含实际的转录语音。它使用0.7的阈值来解读no_speech_prob,如果没有语音,将返回None;否则,它将返回人类对话响应的文本转录。
3. 通过LLM集成添加对话智能
我们的聊天机器人需要提供智能、友好的响应,并保持自然的对话流。我们将使用Groq托管的Llama-4来实现这一点:
def generate_chat_completion(client, history):messages = []messages.append({"role": "system","content": "In conversation with the user, ask questions to estimate and provide (1) total calories, (2) protein, carbs, and fat in grams, (3) fiber and sugar content. Only ask *one question at a time*. Be conversational and natural.",})for message in history:messages.append(message)try:completion = client.chat.completions.create(model="meta-llama/llama-4-scout-17b-16e-instruct",messages=messages,)return completion.choices[0].message.contentexcept Exception as e:return f"Error in generating chat completion: {str(e)}"
我们定义了一个系统提示来指导聊天机器人的行为,确保它一次只问一个问题,并保持对话的自然性。此处也包括错误处理,以确保应用程序能够优雅地处理任何问题。
4. 使用语音活动检测实现免提交互
为了使我们的聊天机器人实现免提操作,我们将添加语音活动检测(VAD),以自动检测用户何时开始或停止说话。以下是如何使用JavaScript中的ONNX实现自动检测的方法:
js = """
async function main() {const script1 = document.createElement("script");script1.src = "https://cdn.jsdelivr.net/npm/onnxruntime-web@1.14.0/dist/ort.js";document.head.appendChild(script1)const script2 = document.createElement("script");script2.onload = async () => {console.log("vad loaded") ;var record = document.querySelector('.record-button');record.textContent = "Just Start Talking!"record.style = "width: fit-content; padding-right: 0.5vw;"const myvad = await vad.MicVAD.new({onSpeechStart: () => {var record = document.querySelector('.record-button');var player = document.querySelector('#streaming-out')if (record != null && (player == null || player.paused)) {console.log(record);record.click();}},onSpeechEnd: (audio) => {var stop = document.querySelector('.stop-button');if (stop != null) {console.log(stop);stop.click();}}})myvad.start()}script2.src = "https://cdn.jsdelivr.net/npm/@ricky0123/vad-web@0.0.22/dist/bundle.min.js";script1.onload = () => {console.log("onnx loaded") document.head.appendChild(script2)};
}
"""
此脚本加载VAD模型,并设置函数以自动开始和停止录音。当用户开始说话时,它会触发录音;当用户停止说话时,它会结束录音。但作者在使用时,自动录音的时间很短,有能力的读者可尝试调整这部分代码,以加长录音时间。
5. 使用Gradio构建用户界面
现在使用Gradio创建一个直观且视觉上吸引人的用户界面,该界面将包括用于捕捉语音的音频输入、用于显示响应的聊天窗口以及用于保持同步的状态管理:
with gr.Blocks(theme=theme, js=js) as demo:with gr.Row():input_audio = gr.Audio(label="Input Audio",sources=["microphone"],type="numpy",streaming=False,waveform_options=gr.WaveformOptions(waveform_color="#B83A4B"),)with gr.Row():chatbot = gr.Chatbot(label="Conversation", type="messages")state = gr.State(value=AppState())
在这段代码块中,我们使用Gradio的Blocks API创建一个包含音频输入、聊天显示和应用程序状态管理器的界面。波形图的自定义颜色为界面增添了美观的视觉效果。
6. 处理录音和响应
最后,让我们连接录音和响应组件,以确保应用程序对用户输入做出流畅的反应,并实时提供响应:
stream = input_audio.start_recording(process_audio,[input_audio, state],[input_audio, state],)respond = input_audio.stop_recording(response, [state, input_audio], [state, chatbot])
这些代码行设置了事件监听器,用于开始和停止录音、处理音频输入以及生成响应。通过连接这些事件,我们创造了一个连贯的体验,用户只需说话,聊天机器人就会处理其余部分。
20.4.4 操作运行
当用户打开应用程序时,语音活动检测(VAD)系统会自动初始化并开始监听语音。一旦用户开始说话,它会自动触发录音;当用户停止说话时,录音结束,并执行以下步骤:
- 使用Whisper对音频进行转录;
- 转录的文本被发送到大型语言模型(LLM);
- LLM生成关于卡路里跟踪的响应;
- 响应显示在聊天界面中。
运行界面如下:
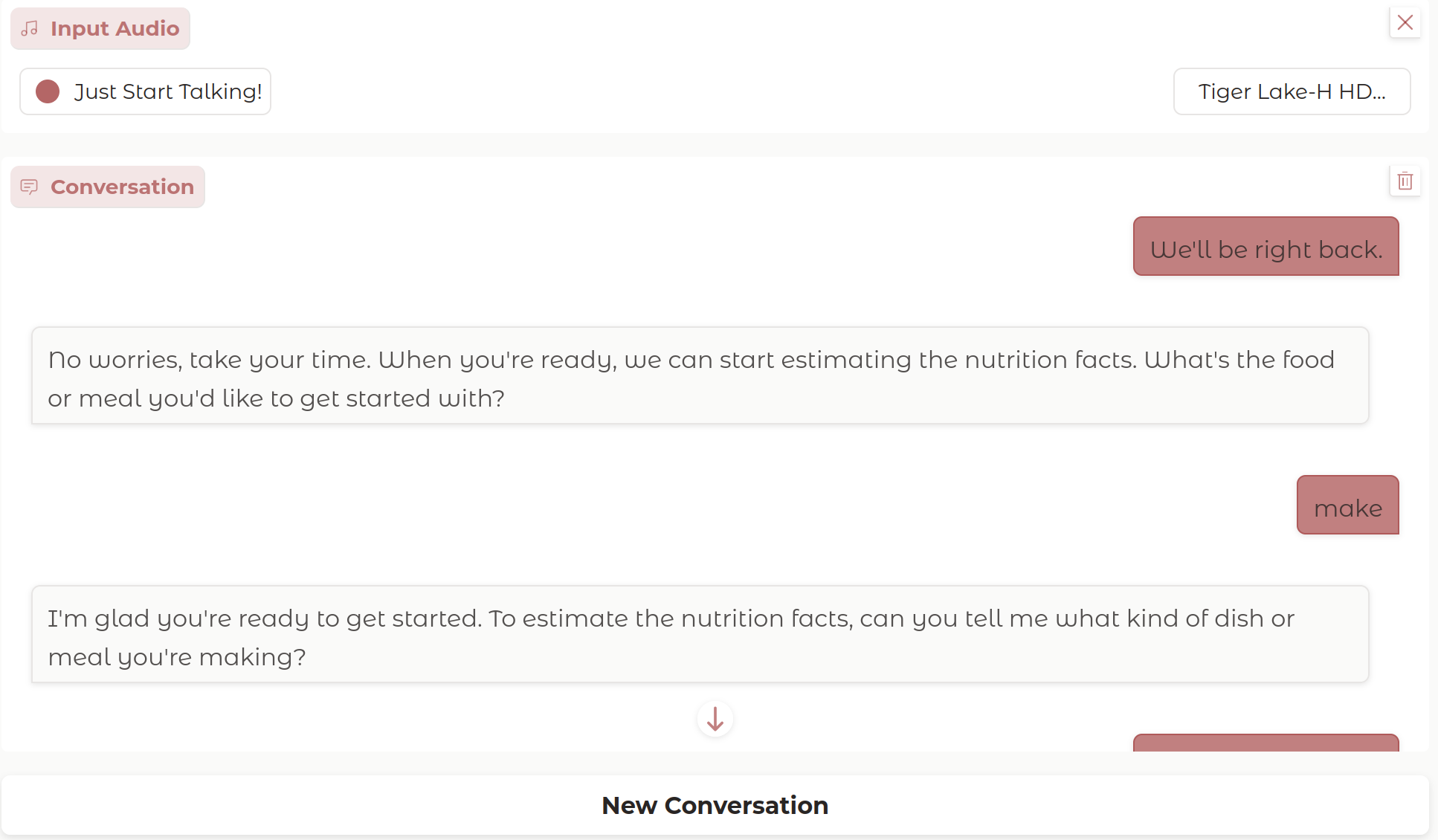
通过这些内容,应用程序创造了一个自然的双向对话,用户只需谈论饮食,就能立即获得营养内容的反馈。它展示了如何创建一个响应迅速且直观的自然语音界面,并通过结合 Groq 的快速推理和自动语音检测,消除了手动录音控制的需要,同时保持了高质量的交互。最终的成果就是,应用程序变成了一个实用的卡路里跟踪助手,用户可以像与人类营养师交谈一样自然地与之对话。
应用的GitHub仓库链接为:Groq Gradio Basics。源程序在运行时,由于版本及语法等原因存在一些报错,作者调整后放在CSDN资源下载:steaming-groq_calorie_bot。
参考文献:
- Streaming AI Generated Audio
- Run Inference on servers
- Spaces ZeroGPU: Dynamic GPU Allocation for Spaces