【AI论文】KeySync:一种在高分辨率下实现无泄漏唇形同步的稳健方法
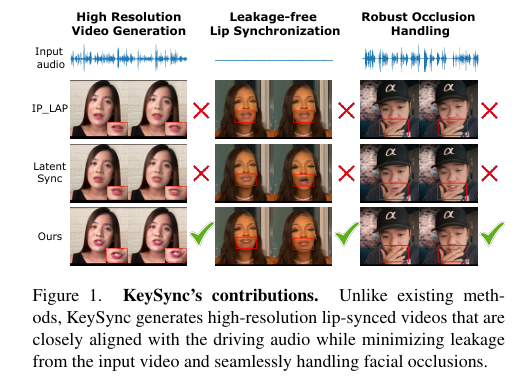
摘要:唇同步,即把现有视频中的嘴唇动作与新的输入音频对齐的任务,通常被视为音频驱动面部动画的一个更简单的变体。 然而,除了存在谈话头一代的常见问题(例如时间一致性)外,唇形同步还带来了新的重大挑战,例如输入视频中的表情泄漏和面部遮挡,这可能会严重影响自动配音等现实应用,但在现有工作中往往被忽视。 为了解决这些缺点,我们提出了KeySync,这是一个两阶段框架,成功地解决了时间一致性问题,同时还使用精心设计的掩蔽策略,将泄漏和遮挡的解决方案结合起来。 我们证明,KeySync在唇部重建和交叉同步方面取得了最先进的结果,根据我们的新型泄漏度量LipLeak,提高了视觉质量并减少了表情泄漏。 此外,我们展示了我们的新掩蔽方法在处理遮挡方面的有效性,并通过几个消融研究验证了我们的架构选择。 代码和模型权重可以在https://antonibigata.github.io/KeySync中找到。Huggingface链接:Paper page,论文链接:2505.00497
一、研究背景和目的
研究背景:
唇同步(Lip Synchronization)作为音频驱动面部动画(Audio-driven Facial Animation)的一个重要分支,其任务是将现有视频中的唇部动作与新的输入音频进行精确对齐。尽管这一任务在概念上看似简单,但实际上它面临着诸多挑战,这些挑战在现有的谈话头生成(Talking Head Generation)技术中尤为突出。
首先,唇同步技术需要解决时间一致性问题(Temporal Consistency),即在连续帧之间保持唇部动作的平滑过渡,避免出现不自然的跳跃或抖动。这一问题在现有方法中尚未得到充分解决,许多方法依赖于帧级处理,缺乏对视频整体时间连贯性的有效建模。
其次,唇同步技术还面临着表情泄漏(Expression Leakage)和面部遮挡(Facial Occlusions)两大难题。表情泄漏指的是在生成的视频中,原始视频中的表情特征意外地保留下来,与新的音频内容不匹配,从而破坏了唇同步的准确性。面部遮挡则是指视频中可能存在的遮挡物(如手、麦克风等)遮挡了唇部区域,使得唇同步模型难以准确捕捉唇部动作。
尽管音频驱动面部动画技术在近年来取得了显著进展,特别是随着生成对抗网络(GANs)和扩散模型(Diffusion Models)的引入,但唇同步技术的发展相对滞后。现有的唇同步方法往往局限于低分辨率输出,且难以有效处理时间一致性和表情泄漏等问题,这严重限制了其在自动化配音等实际应用中的推广。
研究目的:
本研究旨在提出一种名为KeySync的稳健唇同步方法,以解决现有方法中的时间一致性、表情泄漏和面部遮挡等问题。具体而言,KeySync的目标包括:
-
提高时间一致性:通过采用两阶段框架,KeySync能够生成在时间上更加连贯的唇同步视频,减少帧间的不自然过渡。
-
减少表情泄漏:通过设计一种新颖的掩蔽策略,KeySync能够有效地抑制原始视频中的表情泄漏,确保生成的唇部动作与新的音频内容高度匹配。
-
处理面部遮挡:KeySync引入了一种基于视频分割的遮挡处理方法,能够在推理阶段自动检测并处理遮挡物,从而生成更加自然的唇同步视频。
-
实现高分辨率输出:与现有方法相比,KeySync能够在更高的分辨率下生成唇同步视频,满足实际应用中的需求。
二、研究方法
1. 两阶段框架设计:
KeySync采用了一种两阶段框架来生成唇同步视频。第一阶段是关键帧生成(Keyframe Generation),该阶段从输入视频中选取一系列关键帧,并通过扩散模型生成与输入音频相匹配的唇部动作。关键帧的选择基于时间间隔和音频内容,确保每个关键帧都能准确反映音频的语音内容。
第二阶段是插值(Interpolation),该阶段在相邻的关键帧之间进行插值,生成中间帧,从而构建出完整的唇同步视频。插值过程同样基于扩散模型,通过学习关键帧之间的时间动态变化,生成平滑过渡的中间帧。
2. 掩蔽策略设计:
为了解决表情泄漏问题,KeySync设计了一种新颖的掩蔽策略。该策略首先通过面部标志点检测确定唇部区域,并扩展至包括下巴和部分脸颊区域,以确保掩蔽区域足够大以覆盖所有可能的唇部动作。同时,掩蔽区域还向下延伸至图像底部,以防止下巴动作导致的泄漏。
此外,为了处理面部遮挡问题,KeySync在推理阶段引入了一种基于视频分割的遮挡处理方法。该方法使用一个预训练的视频分割模型来自动检测并分割出遮挡物,然后从掩蔽区域中排除这些遮挡物。这样,KeySync就能够在生成唇部动作时忽略遮挡物的影响,从而生成更加自然的唇同步视频。
3. 损失函数设计:
KeySync采用了两种损失函数来优化模型性能:一种是潜在空间损失(Latent Space Loss),用于衡量生成帧与真实帧在潜在空间中的差异;另一种是RGB空间损失(RGB Space Loss),用于衡量生成帧与真实帧在像素空间中的差异。通过结合这两种损失函数,KeySync能够在保持时间一致性的同时,提高生成视频的视觉质量。
4. 音频编码器选择:
在音频编码方面,KeySync选择了HuBERT作为音频编码器。HuBERT是一种自监督学习的语音表示学习模型,能够有效地将音频信号转换为适合扩散模型处理的特征表示。通过与其他音频编码器(如Wav2vec2、WavLM等)的比较实验,KeySync验证了HuBERT在唇同步任务中的优越性能。
三、研究结果
1. 定量分析结果:
在定量分析方面,KeySync在多个评价指标上均取得了显著优于现有方法的结果。具体而言,在CMMD(一种改进的FID指标)、TOPIQ(一种面向面部数据的图像质量评估指标)、VL(方差拉普拉斯算子,用于评估图像清晰度)和FVD(视频质量评估指标)等指标上,KeySync均表现出了更高的图像和视频质量。同时,在LipScore(一种用于评估唇同步准确性的指标)和LipLeak(本研究提出的一种用于评估表情泄漏的指标)上,KeySync也取得了显著优于现有方法的结果。
特别是在跨同步(Cross-sync)任务中,KeySync的表现尤为突出。跨同步任务是指使用与输入视频不匹配的音频进行唇同步生成,这在实际应用中更为常见。KeySync在跨同步任务中不仅保持了较高的LipScore,还显著降低了LipLeak值,表明其在处理表情泄漏方面的有效性。
2. 定性分析结果:
在定性分析方面,KeySync生成的唇同步视频在视觉上更加自然和连贯。与现有方法相比,KeySync生成的唇部动作与输入音频更加匹配,且没有出现明显的表情泄漏或面部遮挡问题。此外,KeySync还能够在高分辨率下生成唇同步视频,满足了实际应用中的需求。
3. 用户研究结果:
为了验证KeySync在实际应用中的效果,本研究还进行了一项用户研究。用户研究结果表明,KeySync在唇同步准确性、时间一致性和视觉质量等方面均获得了用户的高度评价。与现有方法相比,用户更倾向于选择KeySync生成的唇同步视频。
四、研究局限
尽管KeySync在唇同步任务中取得了显著成果,但仍存在一些局限性需要进一步改进:
- 极端头部姿势下的性能下降:
KeySync在处理极端头部姿势(如大幅度侧脸或仰头)时,其性能会出现一定程度的下降。这主要是由于训练数据集中主要包含正面头部姿势的视频,导致模型在处理极端头部姿势时缺乏足够的泛化能力。未来研究可以通过收集更多包含极端头部姿势的训练数据或采用数据增强技术来改进这一问题。
- 非人类面部表情的处理能力有限:
尽管KeySync在处理人类面部表情方面表现出了较高的准确性,但在处理非人类面部表情(如卡通角色或虚拟形象)时,其性能会受到一定限制。这主要是由于非人类面部表情与人类面部表情在结构和特征上存在较大差异,导致模型难以直接应用。未来研究可以探索针对非人类面部表情的特定模型或方法。
- 实时性能有待提升:
尽管KeySync在生成唇同步视频方面取得了显著成果,但其推理速度仍相对较慢,难以满足实时应用的需求。未来研究可以通过优化模型结构、采用更高效的推理算法或利用硬件加速技术来提升KeySync的实时性能。
五、未来研究方向
针对KeySync的局限性和唇同步技术的未来发展需求,未来研究可以从以下几个方面展开:
- 多模态融合学习:
未来研究可以探索将唇同步任务与其他相关任务(如语音识别、面部表情识别等)进行多模态融合学习。通过共享底层特征表示和高层语义信息,多模态融合学习有望进一步提升唇同步技术的准确性和鲁棒性。
- 自适应掩蔽策略:
针对不同视频内容和遮挡情况,未来研究可以探索设计自适应掩蔽策略。通过动态调整掩蔽区域的大小和形状,自适应掩蔽策略有望更好地处理各种复杂的遮挡情况,并进一步提高唇同步技术的准确性。
- 跨语言唇同步技术:
随着全球化的发展,跨语言唇同步技术变得越来越重要。未来研究可以探索如何将KeySync等技术应用于跨语言唇同步任务中,通过处理不同语言之间的语音和唇部动作差异,实现更加自然和准确的跨语言唇同步效果。
- 实时唇同步系统开发:
为了满足实时应用的需求,未来研究可以致力于开发实时唇同步系统。通过优化模型结构、采用更高效的推理算法或利用硬件加速技术,实时唇同步系统有望在保持较高准确性的同时,实现更快的推理速度和更低的延迟。
- 伦理和社会影响研究:
随着唇同步技术的不断发展,其伦理和社会影响也日益受到关注。未来研究可以探索如何确保唇同步技术的合理使用,避免其被用于恶意目的(如深度伪造、虚假信息传播等)。同时,还可以研究如何通过技术手段(如水印、数字签名等)来增强唇同步技术的可追溯性和可信度。