【自然语言处理与大模型】LlamaIndex的数据连接器和对话引擎
LlamaIndex 是领先的开发框架,专为结合大型语言模型(LLM)与个性化工作流打造高效的数据驱动型智能代理而设计。一般我们用它来做RAG检索增强生成。
(1)RAG的介绍
大型语言模型(LLM)虽然在海量数据上进行了训练,但通常并未基于自己的特定数据进行学习。为了解决这一问题,检索增强生成(Retrieval-Augmented Generation,RAG)技术通过将您的数据整合到 LLM 已有的知识中,实现对模型输入的个性化增强。
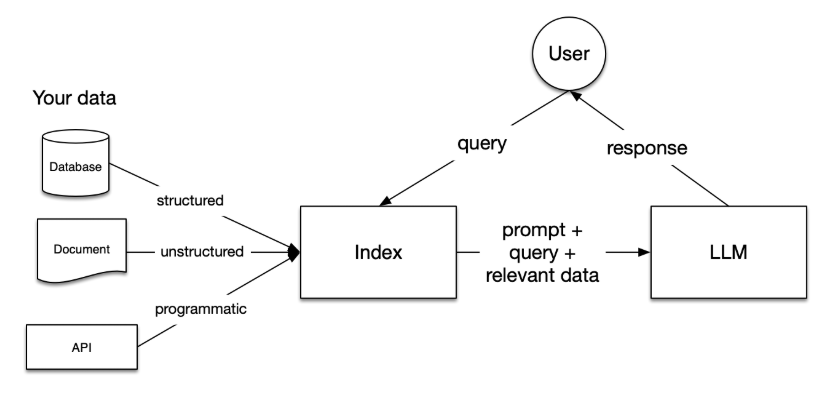
在构建大多数大型应用时,RAG通常包含五个核心阶段。这些阶段构成了整个流程的基础:
1. 数据加载(Loading)
这是将数据从原始来源导入工作流程的过程。无论数据存储在文本文件、PDF、网页、数据库还是通过 API 提供,LlamaIndex 都提供了丰富的工具来完成这一任务。LlamaHub 更是提供了数百种现成的数据连接器,便于快速集成各类数据源。
2. 索引构建(Indexing)
索引阶段的目的是创建一种高效的数据结构,以便后续查询使用。对于 LLM 应用而言,这通常涉及将数据转化为语义向量(vector embeddings),并结合多种元数据策略,从而实现对上下文相关数据的快速准确检索。
3.数据存储(Storage)
一旦数据被索引,通常需要将索引结果及相关的元数据持久化存储下来,以避免重复执行耗时的索引过程。LlamaIndex 支持多种本地和远程存储方式,确保数据可复用且易于管理。
4. 查询处理(Querying)
针对不同的索引策略,您可以采用多种方式进行查询操作。LlamaIndex 提供了灵活的查询接口,支持子查询、多步骤查询、混合检索策略等,帮助您充分利用 LLM 和底层数据结构的能力。
5. 效果评估(Evaluation)
在任何系统中,评估都是不可或缺的一环。它可以帮助您客观地衡量不同策略的效果,或在进行更改后评估其影响。通过评估机制,您可以量化查询响应的准确性、信息忠实度以及响应速度,从而持续优化系统性能。

(2)LlamaIndex如何实现RAG?
① 加载HF模型
使用 LlamaIndex 中的 HuggingFaceLLM 类来加载一个本地的大规模语言模型(LLM),并利用它来进行对话是必须要掌握的技能。
from llama_index.core.llms import ChatMessage
from llama_index.llms.huggingface import HuggingFaceLLM#使用HuggingFaceLLM加载本地大模型
llm = HuggingFaceLLM(model_name="/home/Qwen/Qwen1.5-1.8B-Chat",tokenizer_name="/home/Qwen/Qwen1.5-1.8B-Chat",model_kwargs={"trust_remote_code":True},tokenizer_kwargs={"trust_remote_code":True}
)
#调用模型chat引擎得到回复
rsp = llm.chat(messages=[ChatMessage(content="llamaindex是什么?")])print(rsp)② 数据连接器
数据连接器的作用是将不同数据源的数据提取到LlamaIndex中,最简单易用的阅读器是内置的 SimpleDirectoryReader。它可以遍历指定目录中的所有文件,并为每个文件创建对应的文档对象。该阅读器原生集成于 LlamaIndex 中,支持多种文件格式,包括 Markdown、PDF、Word 文档、ppt、图像、音频以及视频等。
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import Settings,SimpleDirectoryReader,VectorStoreIndex
from llama_index.llms.huggingface import HuggingFaceLLM# 初始化一个HuggingFaceEmbedding对象,用于将文本转换为向量表示
embed_model = HuggingFaceEmbedding(#指定了一个预训练的sentence-transformer模型的路径model_name="/home/sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2"
)# 将创建的嵌入模型赋值给全局设置的embed_model属性,这样在后续的索引构建过程中,就会使用这个模型
Settings.embed_model = embed_model# 使用HuggingFaceLLM加载本地大模型
llm = HuggingFaceLLM(model_name="/home/Qwen/Qwen1.5-1.8B-Chat",tokenizer_name="/home/Qwen/Qwen1.5-1.8B-Chat",model_kwargs={"trust_remote_code": True},tokenizer_kwargs={"trust_remote_code": True}
)# 设置全局的llm属性,这样在索引查询时会使用这个模型。
Settings.llm = llm# 从指定目录读取文档,将数据加载到内存
documents = SimpleDirectoryReader("/home/data").load_data()
# print(documents)# 创建一个VectorStoreIndex,并使用之前加载的文档来构建向量索引
# 此索引将文档转换为向量,并存储这些向量(内存)以便于快速检索
index = VectorStoreIndex.from_documents(documents)# 创建一个查询引擎,这个引擎可以接收查询并返回相关文档的响应。
query_engine = index.as_query_engine()
rsp = query_engine.query("llamaindex是什么?")
print(rsp)