微软Phi-4-reasoning技术报告解读
Phi-4-reasoning技术报告解读
一、引言
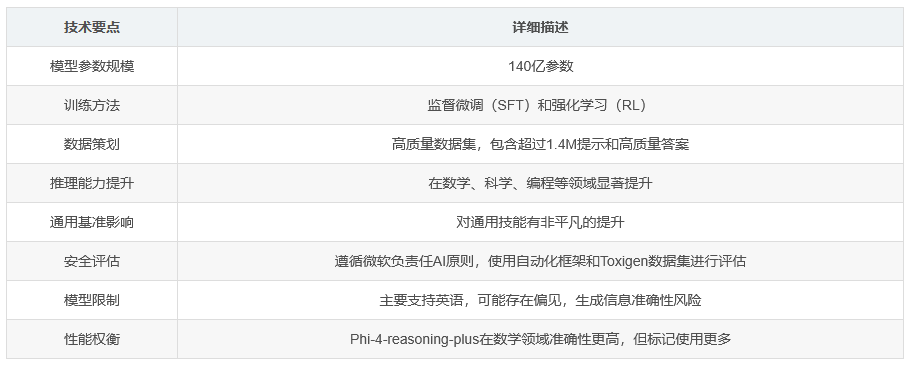
Phi-4-reasoning是一个拥有140亿参数的推理模型,专注于解决需要多步骤分解、内部反思和探索多种解题策略的复杂任务。该模型基于Phi-4模型,通过监督微调(SFT)和强化学习(RL)两种训练方法进行优化,以提高其在数学、科学、编程等领域的推理能力。Phi-4模型最初通过大规模创新合成数据集进行预训练,这些数据集特别强调推理和复杂问题解决能力。Phi-4-reasoning在多个推理基准测试中的表现超越了多个更大规模的模型,包括DeepSeekR1-Distill-Llama-70B模型,并接近完整的DeepSeek-R1模型的性能水平。
二、数据方法论
Phi-4-reasoning模型的训练数据方法论强调高质量数据的策划,包括创意设计的合成生成和经过筛选的有机数据。训练数据的策划过程包括以下几个关键步骤:
-
种子数据库的构建:从各种网络资源中收集问题,并通过LLM评估和过滤流程进行筛选,优先考虑需要复杂多步骤推理的提示。
-
合成种子数据:将部分筛选后的种子转换为新的合成数据集,以更好地与目标推理技能对齐。
-
数据去污染:对训练数据进行全面的去污染处理,以避免对常用推理基准的污染。
三、模型训练方法
Phi-4-reasoning通过监督微调(SFT)和强化学习(RL)两种方法进行训练:
监督微调(SFT)
-
模型架构修改:在Phi-4模型的基础上,重新分配两个占位符作为“思考”和“结束思考”标记,以容纳额外的推理标记。同时,将模型支持的最大标记长度从16K扩展到32K。
-
训练数据:使用合成生成的长链思考推理痕迹和高质量答案,涵盖数学、编程和安全等领域。
-
训练过程:在约16K步的训练过程中,模型逐渐学会了使用“思考”标记,并在训练过程中提高了推理能力。
强化学习(RL)
Phi-4-reasoning-plus通过基于结果的强化学习进一步增强推理能力。强化学习专注于数学推理,使用72,401个数学问题作为种子数据集。奖励函数旨在激励正确性、惩罚不良行为(如重复和过度长度),并鼓励适当的响应格式。
四、实验评估
评估方法
Phi-4-reasoning模型在多个推理基准测试中进行了评估,包括数学、科学、编程、规划和空间理解等领域。评估结果显示,Phi-4-reasoning和Phi-4-reasoning-plus在多个基准测试中均优于Phi-4模型,并且在某些情况下与更大规模的模型相媲美或超越它们。
主要发现
-
推理任务性能提升:Phi-4-reasoning和Phi-4-reasoning-plus在数学、科学推理、编程、算法问题解决和规划等方面相较于Phi-4模型有显著提升。
-
对通用基准的影响:推理能力的提升对通用技能也有非平凡且通常较大的益处。
-
推理深度与准确性权衡:Phi-4-reasoning-plus在数学领域具有更高的准确性,但平均使用的标记数比Phi-4-reasoning多1.5倍。
五、安全评估
Phi-4-reasoning模型遵循微软的负责任AI原则。评估包括自动化负责任AI指标测量框架和Toxigen数据集,结果显示Phi-4-reasoning在有害内容生成和身份群体相关毒性检测方面相较于Phi-4模型有轻微退步,但在毒性与中性内容检测的平衡性上表现更好。
六、限制
Phi-4-reasoning继承了Phi-4模型的一些限制,例如主要支持英语文本、可能延续训练数据中的偏见、生成不准确或过时信息的风险。此外,推理模型需要更多的计算时间和资源,响应速度较慢,并且可能产生与自身推理链相矛盾的响应。
七、贡献与致谢
-
数据和监督微调:Mojan Javaheripi, Arindam Mitra等人负责数据策划和监督微调。
-
强化学习:Yue Wu, Harkirat Behl等人负责强化学习部分。
-
评估和分析:Vidhisha Balachandran, Lingjiao Chen等人负责模型评估和分析。
-
基础设施和发布:Yash Lara, Gustavo de Rosa等人负责基础设施和模型发布。
-
项目领导:Ahmed Awadallah负责项目领导。
八、结论
Phi-4-reasoning模型展示了在多个推理任务中的强大性能,通过精心策划的数据和训练方法,证明了小规模模型也能在推理领域与更大规模的模型竞争。然而,模型在某些领域仍有改进空间,如生物学和化学的推理能力,以及在更长上下文中的表现。