Encoder和Decoder的区别
文章目录
- 1. Encoder 和 Decoder 的基本区别
- 2. 结构上的区别
- Encoder 结构:
- Decoder 结构:
- 3. 主要的区别总结
- 4. 在 Transformer 中的具体实现
- Encoder:
- Decoder:
- 5. Transformer Encoder-Decoder 在机器翻译中的应用**
- 6. 总结
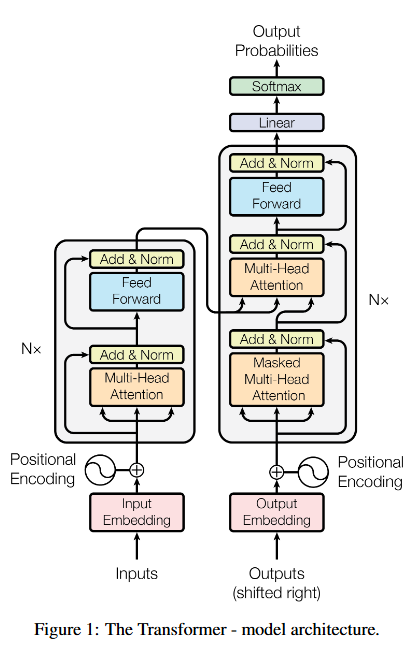
在 Transformer 模型中, Encoder 和 Decoder 是两部分的核心组件,它们在结构和功能上有很大的区别。它们分别负责不同的任务,并且在整个模型的工作流程中有着不同的角色。
1. Encoder 和 Decoder 的基本区别
-
Encoder:接收输入数据,处理输入信息,并将其转换为一个上下文敏感的表示(通常是一个上下文向量或多个上下文向量)。这个表示捕捉了输入序列中的所有重要信息,并传递给 Decoder。
-
Decoder:接收 Encoder 的输出(即上下文表示),并根据这些信息生成最终的输出(例如翻译的文本、图像描述等)。在一些任务中,Decoder 还可能使用自己的输入(例如,在生成式模型中,Decoder 还会根据已经生成的部分输出继续生成新的部分)。
2. 结构上的区别
Encoder 结构:
Encoder 由多个相同的编码层堆叠而成,每个编码层包括以下部分:
- 自注意力层(Self-Attention):通过自注意力机制,编码器能够对输入序列中的每个元素进行加权平均,关注其与其他元素的关系。
- 前馈神经网络(Feedforward Neural Network):在自注意力之后,编码器会使用前馈神经网络对每个位置的输出进行进一步处理。
- 层归一化(Layer Normalization):通过层归一化操作,帮助稳定训练过程。
- 残差连接(Residual Connection):每个子层都有残差连接,它帮助模型在训练时避免梯度消失问题,并加速收敛。
每个 Encoder Layer 都对输入序列应用上述步骤,最终将信息传递给 Decoder。
Encoder 的工作流程:
- 输入序列经过嵌入层映射成向量。
- 这些向量经过多个 自注意力层,处理输入数据中的上下文关系,得到每个词或元素的上下文表示。
Decoder 结构:
Decoder 也是由多个相同的解码层堆叠而成,每个解码层包括以下部分:
- 自注意力层(Self-Attention):和 Encoder 中的自注意力层类似,Decoder 也会通过自注意力机制关注自己的前文输出。但是为了避免模型在生成每个词时看到未来的词,通常会对 Decoder 的自注意力做 掩蔽(masking),即使得模型只能看到当前位置之前的词。
- Encoder-Decoder Attention:这是 Decoder 特有的一层,它使得 Decoder 能够聚焦于 Encoder 输出的上下文表示。这一层的作用是将 Decoder 中的查询与 Encoder 的键(Key)和值(Value)进行匹配,从而让 Decoder 获取 Encoder 中的重要信息。
- 前馈神经网络(Feedforward Neural Network):和 Encoder 中的前馈神经网络一样,Decoder 也使用前馈神经网络进一步处理每个位置的信息。
- 层归一化(Layer Normalization):和 Encoder 相似,Decoder 也会进行层归一化。
- 残差连接(Residual Connection):每个子层也有残差连接,帮助信息传递。
Decoder 的工作流程:
- Decoder 接收 Encoder 的输出(即编码的上下文表示)。
- Decoder 根据当前的输入(例如已经生成的词或之前的步骤的输出)生成下一个词,并通过 Encoder-Decoder Attention 层聚焦于与输入相关的信息。
3. 主要的区别总结
| 组件 | Encoder | Decoder |
|---|---|---|
| 输入 | 输入序列(例如文本、图像等)。 | Decoder 的输入通常是 Encoder 的输出 和 先前的生成结果(如已经生成的词)。 |
| 自注意力 | 普通自注意力(Self-Attention)。 | 自注意力(Masked Self-Attention),即仅查看之前生成的词。 |
| Encoder-Decoder Attention | 无 | 有,Decoder 会使用 Encoder 的输出信息来生成每个词。 |
| 输出 | 对输入序列的上下文敏感表示。 | 生成目标序列(例如翻译的文本)。 |
| 目标 | 提取输入序列中的语义信息。 | 根据 Encoder 提供的上下文信息生成目标输出。 |
4. 在 Transformer 中的具体实现
Encoder:
- 输入嵌入层:首先通过嵌入层将输入序列(例如文本)转化为词向量。
- 位置编码(Positional Encoding):由于 Transformer 不具备循环结构,它依赖于位置编码来标记输入序列中每个词的顺序。
- 自注意力:每个输入元素都会对其他元素进行加权平均,表示它们之间的关系。
- 前馈神经网络:对每个位置的输出进行处理,以增强其表示能力。
- 层归一化和残差连接:在每一层自注意力和前馈神经网络后,都进行层归一化,并使用残差连接。
Decoder:
- 输入嵌入层和位置编码:和 Encoder 类似,输入序列(例如目标语言的文本)会先被转换为词向量,并通过位置编码加入顺序信息。
- 自注意力(Masked):Decoder 的自注意力层会限制信息流,使得模型只能看到当前生成的词及其之前的词,避免未来的信息泄漏。
- Encoder-Decoder Attention:Decoder 的自注意力之后,还会有一层 Encoder-Decoder Attention,它通过注意力机制将 Decoder 的查询与 Encoder 的键和值进行匹配,以获取与输入相关的信息。
- 前馈神经网络:和 Encoder 类似,经过自注意力后,Decoder 会通过前馈神经网络进一步处理。
- 线性层和 Softmax:最后,Decoder 会使用线性变换和 softmax 层来生成每个时间步的输出(通常是下一个词的概率分布)。
5. Transformer Encoder-Decoder 在机器翻译中的应用**
以机器翻译为例,假设我们有一个英语句子 “Hello, how are you?”,目标是将其翻译成法语。
-
Encoder:接收英语句子作为输入,逐词进行处理,将每个单词转换为一个高维的上下文敏感的表示,最终输出一个上下文表示(对整个句子的编码)。
-
Decoder:接收 Encoder 输出的上下文表示和目标语言(法语)的部分生成结果(例如 “Bonjour”)。然后 Decoder 会根据 Encoder 的信息生成下一个词(比如 “comment”),再根据之前生成的结果生成下一个词(比如 “allez”),依此类推,直到生成完整的翻译句子。
6. 总结
- Encoder:负责对输入数据进行编码,将其转换为上下文敏感的表示,并将其传递给 Decoder。
- Decoder:接收 Encoder 的输出,并根据目标任务(如翻译、文本生成等)生成最终的输出序列。
- 区别:Encoder 专注于输入序列的表示,Decoder 专注于生成输出序列,并且它还会利用 Encoder 的信息来生成更精确的结果。