MTV-SCA:基于多试向量的正弦余弦算法
3 正弦余弦算法 (SCA)
正弦余弦算法(SCA)是为全局优化而开发的,并受到两个函数,正弦和余弦的启发。与其他基于启发式种群的算法一样,SCA在问题的预设最小值和最大值边界内随机生成候选解。然后,通过应用方程(1)中显示的两个不同的数学表达式来计算更新的解决方案,以实现探索和开发之间的平衡。
X i t + 1 = { X i t + r 1 × sin ( r 2 ) × ∣ r 3 × P i t − X i t ∣ , r 4 < 0.5 X i t + r 1 × cos ( r 2 ) × ∣ r 3 × P i t − X i t ∣ , r 4 ≥ 0.5 (1) X_i^{t+1} = \begin{cases} X_i^t + r_1 \times \sin(r_2) \times |r_3 \times P_i^t - X_i^t|, & r_4 < 0.5 \\ X_i^t + r_1 \times \cos(r_2) \times |r_3 \times P_i^t - X_i^t|, & r_4 \geq 0.5 \end{cases} \tag{1} Xit+1={Xit+r1×sin(r2)×∣r3×Pit−Xit∣,Xit+r1×cos(r2)×∣r3×Pit−Xit∣,r4<0.5r4≥0.5(1)
其中 X i t X_i^t Xit和 P i t P_i^t Pit分别是第t次迭代中第i个解的位置和目标解, r 1 r_1 r1、 r 2 r_2 r2和 r 3 r_3 r3是随机生成的。方程(1)中表达式的选择由随机数 r 4 r_4 r4决定,它在0和1之间遵循均匀分布。
通过使用 r 1 r_1 r1、 r 2 r_2 r2和 r 3 r_3 r3,SCA调节算法如何被探索和使用。参数 r 1 r_1 r1可用于平衡SCA早期和后期阶段的探索和开发。根据此参数,新解将被导向目标或远离目标。为了在算法的后期阶段识别最优解,它首先指导搜索过程在整个搜索空间中寻找解决方案,或者利用目标解的接近性。当 r 1 r_1 r1大于0时,目标解和解之间的距离将增加,而当 r 1 r_1 r1较小时,距离将减少。 r 1 r_1 r1的计算使用方程(2)进行。
r 1 = a − t × a T (2) r_1 = a - t \times \frac{a}{T} \tag{2} r1=a−t×Ta(2)
其中a是一个常数值,t是当前迭代次数,T是最大迭代次数。解与目标解位置的距离由随机参数 r 2 r_2 r2表示。一般来说, r 1 r_1 r1的较大值表示增加的探索,考虑到当前解和目标解之间的较大距离;相反,较小的值表示探索,考虑到较短的距离。参数 r 3 r_3 r3用于展示距离计算在多大程度上受到目标解的影响。
4 提出的多试验向量基于正弦余弦算法 (MTV-SCA)
尽管SCA在解决优化问题时具有简单性和多功能性,但其效率受到限制,给复杂问题的应用带来了重大挑战。SCA在解的准确性方面存在弱点,收敛速度慢,容易陷入局部最优,缺乏探索能力,无法在探索和开发之间保持平衡。这些缺陷源于SCA搜索策略,导致在处理复杂挑战时性能较弱。最佳当前解是SCA位置更新方程中唯一使用的解,用于估计到下一个搜索区域的距离,为SCA提供了有限的探索能力。此外,SCA并未充分利用当前解位置的信息。同时,利用搜索策略和控制参数来解决具有广泛特征的问题。此外,为了在搜索过程的不同阶段获得最佳性能,使用各种替代策略与各种参数值结合是有益的。
本文介绍了一种基于多试验向量的正弦余弦算法(MTV-SCA),其中单SCA的搜索策略通过多试验向量(MTV)方法得到加强。使用MTV方法的优势在于定义各种不同的搜索策略,每种策略都定制为实现不同的目标,以及在整个搜索过程中的合作。此外,提供各种正弦和余弦函数来调整相应搜索策略的参数值。利用这些函数的目的是实现在开发先前发现的良好解决方案和发现先前未访问的搜索空间部分之间的良好平衡。此外,在提出的MTV-SCA中,每个试验向量生产者(TVP)被分配应用于基于MTV方法的获胜者分配策略的特定部分种群。这种方法确保了来自不同子种群的解决方案之间的信息有效共享,最终在种群分配阶段提高了算法的性能。
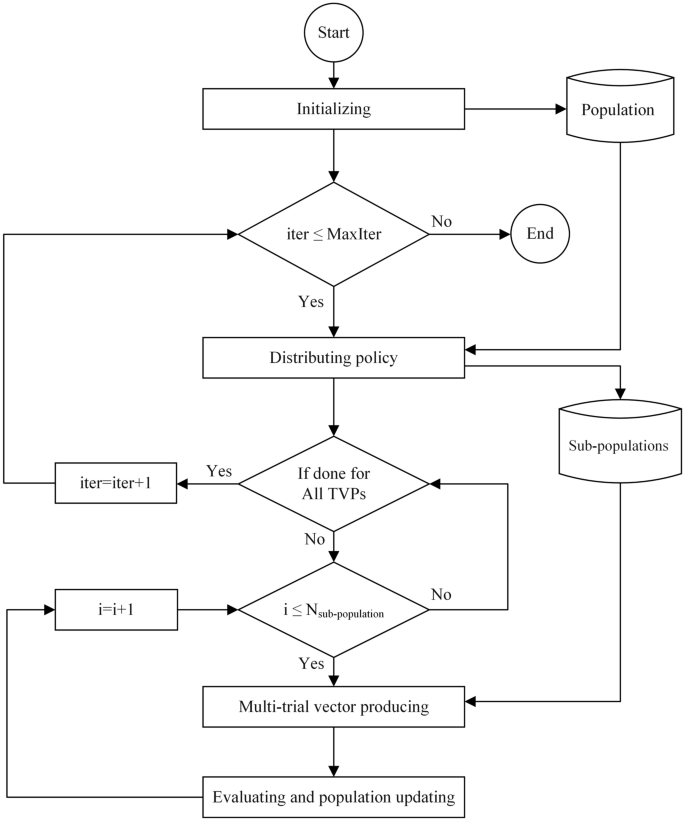
图1展示了MTV-SCA的流程图,包括四个步骤:初始化、分布、多试验向量生产和种群评估。一旦N个解决方案在搜索空间中初始化,每个TVP的子种群大小在每次迭代期间计算。接下来,在多试验向量生产步骤中,通过SCA-TVP或Pool-TVP中的一个或多个策略为每个解决方案生成候选解决方案。在Pool-TVP中,我们设计了四种新的搜索策略,分别命名为S1-TVP、S2-TVP、S3-TVP和S4-TVP,以便对其子种群的解决方案进行有效搜索。此外,S1-TVP旨在实现平衡的探索和开发,并避免陷入局部最优,S2-TVP有效地探索搜索空间,而S3-TVP维持搜索新解决方案与改进当前解决方案之间的平衡状态。此外,S4-TVP旨在平衡搜索空间的探索和开发,并防止过早收敛。此外,每个TVP利用正弦和余弦函数,目的是在开发先前获得的最优解决方案和发现搜索空间中未访问区域之间保持权衡。S1-TVP中使用的Chebyshev方法引入了搜索过程中的随机性和多样性,这可以使算法更有效地探索搜索空间的不同区域。正弦系数提供搜索半径和方向的周期性调整,使算法能够更彻底地搜索并避免陷入局部最优。余弦系数平衡探索和开发,帮助改进解决方案,并专注于搜索空间中前景广阔的区域。然后,在种群评估和更新步骤中,计算候选解决方案的适应度并与之前的值进行比较。作为最后一步,如果候选解决方案的适应度小于解决方案的当前位置,则候选解决方案替换解决方案。否则,解决方案的位置和适应度值保持不变。
初始化:N个解决方案在D维搜索空间中随机初始化,考虑下界(L)和上界(U)边界,使用公式(3)。
x i j = L j + ( U j − L j ) × rand ( 0 , 1 ) (3) x_{ij} = L_j + (U_j - L_j) \times \text{rand}(0, 1) \tag{3} xij=Lj+(Uj−Lj)×rand(0,1)(3)
其中 x i j x_{ij} xij是第i个解决方案的第j维的值。第j维的最小值和最大值分别表示为 L j L_j Lj和 U j U_j Uj,而rand是一个在[0,1]范围内均匀分布的随机值。问题的大小和维度分别由N和D表示。N×D矩阵,称为X,用于保存生成的解决方案的位置。适应度函数, f ( X i ( t ) ) f(X_i(t)) f(Xi(t)),用于在种群初始化和每次迭代后确定解决方案 X i X_i Xi的适应度值。
分布:为了确定子种群SC-TVP和Pool-TVP的大小,必须考虑经过n次迭代后改进的解决方案的数量,n是一个特定的迭代次数。改进率ImpRate是改进解决方案的适应度与前n次迭代中总函数评估数的比率。TVP ImpRate由公式(4)确定。
ImpRate S C − T V P = N ImprovedsolutionsbySC-TVP N S C − T V P × N F E s (4) \text{ImpRate}_{SC-TVP} = \frac{N_{\text{ImprovedsolutionsbySC-TVP}}}{N_{SC-TVP} \times N_{FEs}} \tag{4} ImpRateSC−TVP=NSC−TVP×NFEsNImprovedsolutionsbySC-TVP(4)
ImpRate P o o l − T V P = N ImprovedsolutionsbyPool-TVP N P o o l − T V P × N F E s (5) \text{ImpRate}_{Pool-TVP} = \frac{N_{\text{ImprovedsolutionsbyPool-TVP}}}{N_{Pool-TVP} \times N_{FEs}} \tag{5} ImpRatePool−TVP=NPool−TVP×NFEsNImprovedsolutionsbyPool-TVP(5)
其中改进率分别表示为ImpRate S C − T V P _{SC-TVP} SC−TVP和ImpRate P o o l − T V P _{Pool-TVP} Pool−TVP,子种群大小分别表示为 N S C − T V P N_{SC-TVP} NSC−TVP和 N P o o l − T V P N_{Pool-TVP} NPool−TVP,每个TVP在前n次迭代中执行的函数评估数分别表示为 N F E s N_{FEs} NFEs。
MTV-SCA的分布规则如公式(5)所述,考虑到MTV-SCA的分布策略,因此,具有较高ImpRate的子种群具有较大的子种群。
如果 ImpRate S C − T V P > ImpRate P o o l − T V P \text{ImpRate}_{SC-TVP} > \text{ImpRate}_{Pool-TVP} ImpRateSC−TVP>ImpRatePool−TVP 则 N S C − T V P = N Pad-TVP = λ × N N_{SC-TVP} = N_{\text{Pad-TVP}} = \lambda \times N NSC−TVP=NPad-TVP=λ×N
如果 ImpRate S C − T V P < ImpRate P o o l − T V P \text{ImpRate}_{SC-TVP} < \text{ImpRate}_{Pool-TVP} ImpRateSC−TVP<ImpRatePool−TVP 则 N S C − T V P = ( λ × N ) / 2 , N Pool-TVP = ( λ × N ) + ( λ × N ) / 2 N_{SC-TVP} = (\lambda \times N) / 2, N_{\text{Pool-TVP}} = (\lambda \times N) + (\lambda \times N) / 2 NSC−TVP=(λ×N)/2,NPool-TVP=(λ×N)+(λ×N)/2
其中N是解决方案的总数,子种群的大小通过考虑TVP的改进率 N S C − T V P N_{SC-TVP} NSC−TVP和 N P o o l − T V P N_{Pool-TVP} NPool−TVP,以及变异系数λ来考虑。计算子种群XSC和XPool的大小后,创建子种群。
多试验向量生产:搜索策略和参数值对算法解决优化问题的效率有显著影响。然而,问题的单峰性、多峰性、可分性和不可分性意味着各种搜索策略和控制参数值对于各种优化任务是必需的。此外,具有不同控制参数值的多种搜索策略可能优于在解决特定问题时在不同发展阶段使用单一搜索策略。受这些观察的启发,我们为经典SCA提出了一组试验向量生产者和控制参数,以在每次迭代中生成一个活跃的种群。随着迭代的进行, X i X_i Xi的位置由SC-TVP和Pool-TVP的策略分别调整。SC-TVP增强了搜索有希望的搜索空间区域的能力,并在局部区域找到新的解决方案。Pool-TVP在开发、逃离局部最优和实现探索与开发之间平衡方面发挥作用。
首先介绍初步信息,然后全面解释所提出的TVP。在所提出的S1-TVP和S2-TVP中,每个转换矩阵,分别表示为M和M’,用于为每个子种群生成候选试验向量。矩阵M,具有维度N×D,是从D×D的下三角矩阵创建的,其中所有元素都等于1。这个D×D矩阵被复制(N/D)次以形成一个方阵。如果M中还有剩余的行,它们用方阵的第一行填充。然后,对M的行应用随机排列。通过这种方式,通过用M中相应元素的逆替换每个元素获得M’矩阵。
对于每个属于XSC i t _i^t it的解决方案,一个试验向量 V S 2 i t + 1 VS2_i^{t+1} VS2it+1生成如下:
C S C i t + 1 = { X S C i t + r 1 × sin ( r 2 ) × ∣ r 3 × P t − X S C i t ∣ , r 4 < 0.5 X S C i t + r 1 × cos ( r 2 ) × ∣ r 3 × P t − X S C i t ∣ , r 4 ≥ 0.5 (6) CSC_i^{t+1} = \begin{cases} XSC_i^t + r_1 \times \sin(r_2) \times |r_3 \times P^t - XSC_i^t|, & r_4 < 0.5 \\ XSC_i^t + r_1 \times \cos(r_2) \times |r_3 \times P^t - XSC_i^t|, & r_4 \geq 0.5 \end{cases} \tag{6} CSCit+1={XSCit+r1×sin(r2)×∣r3×Pt−XSCit∣,XSCit+r1×cos(r2)×∣r3×Pt−XSCit∣,r4<0.5r4≥0.5(6)
其中CSC i t + 1 _i^{t+1} it+1表示为XSC i t _i^t it生成的候选解决方案, r 1 r_1 r1由公式(2)计算, r 2 r_2 r2、 r 3 r_3 r3和 r 4 r_4 r4是随机数,P t ^t t是第t次迭代中目标解的位置。
池试验向量生产者(Pool-TVP):Pool-TVP是不同试验向量生产者的集合S1-TVP、S2-TVP、S3-TVP和S4-TVP,具有各种正弦和余弦函数作为搜索策略的控制参数。建议的XPool分配给四个TVP涉及每次迭代中解决方案的随机分配。根据Pool的大小,将解决方案分配给TVP,从而创建子种群XS1、XS2、XS3和XS4。试验向量生产者在搜索过程的不同阶段表现出不同的性能特征,同时面对特定问题。提出S1-TVP旨在帮助算法在探索和开发之间保持平衡,避免陷入局部最优。S1-TVP具有最快的收敛速度,并且在解决单峰问题时表现良好。另一方面,S2-TVP在探索搜索空间方面有效,并且收敛速度较慢,具有更高的探索能力。S3-TVP在探索和开发之间取得良好平衡,具有更高的收敛速度,并且适用于解决多峰问题。S4-TVP旨在平衡搜索空间的探索和开发,并提供过早收敛。
S1-TVP:提出S1-TVP的目的是使算法能够在探索和开发之间保持平衡,并避免陷入局部最优。通过考虑种群的最佳解决方案和两个随机选择的解决方案之间的缩放差异来实现这一点。该策略结合了当前最佳位置、随机选择解决方案的差异以及随机生成的候选解决方案,以产生候选解决方案并将其移向潜在更好的解决方案。此外,Chebyshev和随机控制参数在探索和开发之间提供平衡,从而实现更有针对性的搜索搜索空间的最佳区域。
对于每个属于XS1 i t _i^t it的解决方案,一个试验向量 V S 1 i t + 1 VS1_i^{t+1} VS1it+1通过公式(7)计算:
V S 1 i t + 1 = P t + Chebyshev ( t ) × ( X r 1 t − X r 2 t ) + rand × ( X r 3 t − X r 4 t ) (7) VS1_i^{t+1} = P^t + \text{Chebyshev}(t) \times (X_{r1}^t - X_{r2}^t) + \text{rand} \times (X_{r3}^t - X_{r4}^t) \tag{7} VS1it+1=Pt+Chebyshev(t)×(Xr1t−Xr2t)+rand×(Xr3t−Xr4t)(7)
其中P t ^t t是迄今为止的最佳解决方案, X r 1 t X_{r1}^t Xr1t、 X r 2 t X_{r2}^t Xr2t、 X r 3 t X_{r3}^t Xr3t和 X r 4 t X_{r4}^t Xr4t是从当前种群X中随机选择的解决方案。Chebyshev,由公式(13)计算,是一个生成值的函数,这些值在-1和1之间振荡,振荡频率随着迭代次数增加。Chebyshev的使用使算法能够在平坦区域更有效地探索搜索空间,并在崎岖区域采取更小的步骤。
Chebyshev ( t + 1 ) = cos ( t × cos − 1 ( Chebyshev ( t ) ) ) (8) \text{Chebyshev}(t + 1) = \cos(t \times \cos^{-1}(\text{Chebyshev}(t))) \tag{8} Chebyshev(t+1)=cos(t×cos−1(Chebyshev(t)))(8)
该解决方案 X S 1 i t XS1_i^t XS1it的候选试验向量通过公式(9)计算:
C S C i t + 1 = M i × X S 1 i t + 1 + M ‾ i × V S 1 i t + 1 (9) CSC_i^{t+1} = M_i \times XS1_i^{t+1} + \overline{M}_i \times VS1_i^{t+1} \tag{9} CSCit+1=Mi×XS1it+1+Mi×VS1it+1(9)
其中M和 M ‾ i \overline{M}_i Mi是第i个解决方案的相应值, C S C i t + 1 CSC_i^{t+1} CSCit+1是为S1-TVP子种群生成的候选试验向量。
S2-TVP:该策略涉及从种群中随机选择三个个体,并创建一个新的试验向量,通过添加两个个体与第三个个体之间的缩放差异。该策略已被证明在探索搜索空间方面非常有效,特别是在处理复杂和高维优化问题时。突变策略使算法能够移动当前种群并探索搜索空间的新区域。此外,它能够快速有效地探索搜索空间,这意味着它可以在更短的时间内找到好的解决方案,而不是收敛到其他启发式算法。
对于每个属于XS2 i t _i^t it的解决方案,一个试验向量 V S 2 i t + 1 VS2_i^{t+1} VS2it+1生成如下:
V S 2 i t + 1 = X r 1 t + rand × ( X r 2 t − X r 3 t ) (10) VS2_i^{t+1} = X_{r1}^t + \text{rand} \times (X_{r2}^t - X_{r3}^t) \tag{10} VS2it+1=Xr1t+rand×(Xr2t−Xr3t)(10)
其中rand是一个随机生成的数字, X r 1 t X_{r1}^t Xr1t、 X r 2 t X_{r2}^t Xr2t和 X r 3 t X_{r3}^t Xr3t是当前种群X中的随机选择的解决方案。该解决方案 X S 2 i t XS2_i^t XS2it的候选试验向量通过公式(11)计算:
C S 2 i t + 1 = M i × X S 2 i t + 1 + M ‾ i × V S 2 i t + 1 (11) CS2_i^{t+1} = M_i \times XS2_i^{t+1} + \overline{M}_i \times VS2_i^{t+1} \tag{11} CS2it+1=Mi×XS2it+1+Mi×VS2it+1(11)
其中M和 M ‾ i \overline{M}_i Mi是第i个解决方案的相应值, C S 2 i t + 1 CS2_i^{t+1} CS2it+1是为S2-TVP子种群生成的候选试验向量。
S3-TVP:S3-TVP在探索和开发之间取得良好平衡,并具有更高的收敛速度。这是因为它在突变过程中使用当前和随机解决方案。这是因为它在突变过程中使用随机解决方案,这有助于探索搜索空间的不同区域。当前解决方案 X S 3 i t XS3_i^t XS3it在子种群XS3 i t _i^t it中被随机向量 X r 1 t X_{r1}^t Xr1t的方向移动,然后被当前种群中的两个其他随机选择的解决方案 X r 2 t X_{r2}^t Xr2t和 X r 3 t X_{r3}^t Xr3t之间的缩放差异所扰动。该解决方案 X S 3 i t XS3_i^t XS3it的候选试验向量通过公式(12)计算:
C S 3 i t + 1 = X S 3 i t + sinusoidal ( t ) × ( X r 1 t − X S 3 i t ) + rand × ( X r 2 t − X r 3 t ) (12) CS3_i^{t+1} = XS3_i^t + \text{sinusoidal}(t) \times (X_{r1}^t - XS3_i^t) + \text{rand} \times (X_{r2}^t - X_{r3}^t) \tag{12} CS3it+1=XS3it+sinusoidal(t)×(Xr1t−XS3it)+rand×(Xr2t−Xr3t)(12)
其中 C S 3 i t + 1 CS3_i^{t+1} CS3it+1表示为第i个解决方案 X S 3 i t XS3_i^t XS3it提供的候选解决方案, sinusoidal ( t ) \text{sinusoidal}(t) sinusoidal(t)是用于调整搜索半径和方向的系数,由公式(13)计算。
Sinusoidal ( t + 1 ) = C × ( Sinusoidal ( t ) ) 2 × sin ( t × Sinusoidal ( t ) ) (13) \text{Sinusoidal}(t + 1) = C \times (\text{Sinusoidal}(t))^2 \times \sin(t \times \text{Sinusoidal}(t)) \tag{13} Sinusoidal(t+1)=C×(Sinusoidal(t))2×sin(t×Sinusoidal(t))(13)
正弦函数[113]可以通过允许算法更彻底地探索搜索空间来帮助防止过早收敛。通过定期增加搜索半径和更改搜索方向,算法可以避免陷入局部最优,并继续搜索全局最优。
S4-TVP:平衡搜索空间的探索和开发并避免过早收敛的目标是通过该策略维持的。它根据当前位置、两个随机选择的解决方案以及依赖于当前迭代次数和总迭代次数的正弦和余弦函数的组合来更新 X S 4 i t XS4_i^t XS4it的位置。该解决方案 X S 4 i t XS4_i^t XS4it的候选试验向量通过公式(14)计算:
C S 4 i t + 1 = X S 4 i t + ( cos ( t / MaxIter ) ) × sin ( rand × ( t / MaxIter ) ) × ( X r 1 t − X r 2 t ) (14) CS4_i^{t+1} = XS4_i^t + (\cos(t / \text{MaxIter})) \times \sin(\text{rand} \times (t / \text{MaxIter})) \times (X_{r1}^t - X_{r2}^t) \tag{14} CS4it+1=XS4it+(cos(t/MaxIter))×sin(rand×(t/MaxIter))×(Xr1t−Xr2t)(14)
其中t是当前迭代次数,MaxIter是总迭代次数, X r 1 t X_{r1}^t Xr1t和 X r 2 t X_{r2}^t Xr2t是当前种群X中随机选择的解决方案。 cos ( MaxIter ) × sin ( rand × ( t / MaxIter ) ) \cos(\text{MaxIter}) \times \sin(\text{rand} \times (t / \text{MaxIter})) cos(MaxIter)×sin(rand×(t/MaxIter))用于提供控制参数的动态调整,以平衡探索和开发,并避免过早收敛,从而提高所提出TVP的效率。前一部分从0到-1随着Master接近Master变化,允许逐渐减少搜索半径,这有助于细化解决方案并专注于搜索空间中前景广阔的区域。后一部分从控制参数调整中随机选择一个元素。随机值rand在0和1之间均匀分布,为正弦函数生成随机角度。这种随机性有助于避免陷入局部最优,通过探索搜索空间的不同区域。

种群评估和更新:在每个优化周期之后,计算当前候选解决方案种群的目标函数,并与先前的适应度值进行比较。最优候选解决方案随后被保留用于后续迭代,因为它们被证明是最有效的。这个过程很重要,因为它有助于确保候选解决方案种群保持多样性,同时也改善了整体适应度。通过选择下一代的最佳解决方案,算法能够在探索搜索空间的新区域的同时,也开发已经识别的有前景的区域。
Nadimi-Shahraki, M.H., Taghian, S., Javaheri, D. et al. MTV-SCA: multi-trial vector-based sine cosine algorithm. Cluster Comput 27, 13471–13515 (2024). https://doi.org/10.1007/s10586-024-04602-4