2025五一杯数学建模竞赛选题建议+初步分析
完整内容请看文章最下面的推广群
2025五一杯数学建模竞赛选题建议+初步分析
提示:C君认为的难度和开放度评级如下:
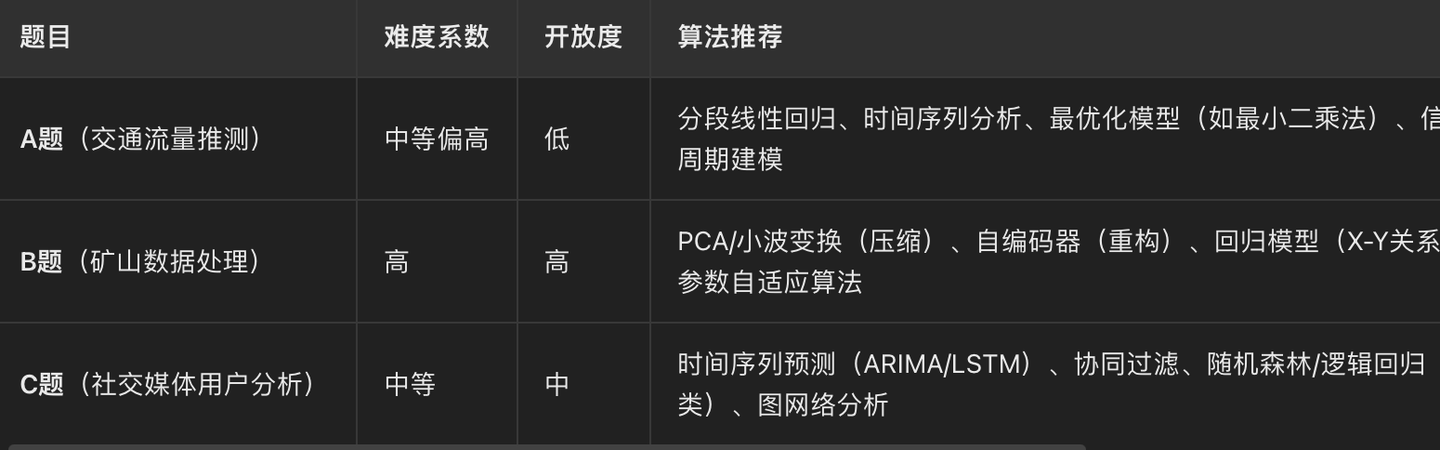
难度:B题 > A题 > C题,开放度:B题 > C题 > A题。综合来看:A题目标明确,数据规律性强,适合数学建模基础较好的团队。B题技术深度高,算法选择空间大,适合数据工程能力强的团队。C题贴近实际应用场景,适合机器学习/数据分析经验丰富的团队。
以下为ABCD题选题建议及初步分析:(要注意的是,本次选题建议会给出每道题目的题目分析、第一问建模过程和推荐算法,然后根据学生不同的专业,针对性给出选题建议)。
综合评价:
-
A题:结构化问题,适合数学建模基础好的团队。
-
B题:技术挑战性强,适合算法与工程能力突出的团队。
-
C题:数据分析典型问题,适合机器学习/统计背景的团队。
A题:支路车流量推测问题
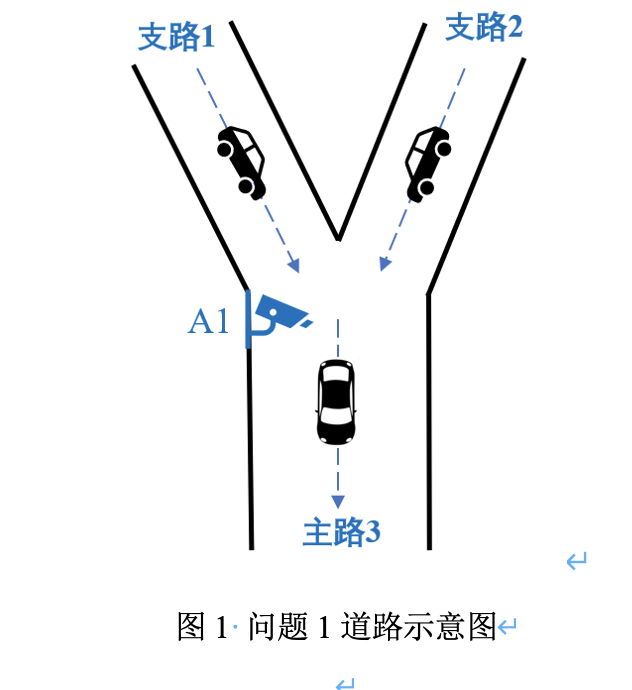
A题核心是通过主路监测数据反推支路车流量,属于逆问题建模,需结合分段函数拟合、时间序列分解和物理约束(如流量叠加、时间延迟)。问题1要求根据主路3的车流量数据,推测支路1(线性增长)和支路2(先增后减)的流量函数。由于主路流量是支路叠加,需建立联立方程组,结合历史趋势约束(严格单调性)。时间序列数据间隔2分钟,函数需连续且分段线性,适合基于约束的优化方法。
C君建议的建模过程为:

推荐算法:1 时间序列分解(Prophet):分解主路流量为趋势项(支路1)和分段趋势项(支路2),支持自动分段点检测。2 动态模式分解(DMD):从主路数据中提取支路的动态模式,适用于多时段分段建模。3 传统算法:带约束的最小二乘法(Constrained Least Squares)。
大家可以使用这些可视化方法:
-
时间序列叠加图:主路实测数据与模型预测对比,标注分段点。
-
残差热力图:展示不同时间段模型误差分布,辅助分段点修正。
-
参数敏感性分析图:如t₀变化对MSE的影响,验证模型鲁棒性。
此题专业性较强,适合有交通工程/自动化的团队。
B题:矿山数据处理问题

B题要求多源异构矿山数据的压缩、去噪和重构,属于高维数据建模,需平衡精度与效率。要求对数据A进行变换逼近数据B,可能涉及特征对齐或生成模型;问题2-5需设计压缩-还原算法,处理矿山数据的空间相关性和噪声。核心难点是:数据维度高(如地质属性、时相数据),需设计轻量级降维方法;重构需保留可解释性(如地质特征)。
C君推荐的建模过程为:

推荐算法有:1对抗生成网络(GAN):学习数据A到B的分布映射,保留细节特征。2 Transformer模型:处理多维时序数据,捕捉长距离依赖关系。3 传统算法:主成分分析(PCA)+ 核回归(Kernel Regression)。
可视化推荐:
-
t-SNE降维图:展示数据A/B在隐空间的分布对齐效果。
-
误差分布直方图:统计变换后误差的均值和方差,定位系统性偏差。
-
特征重要性图:基于SHAP值分析变换模型的关键输入特征。
这道题目的数据处理是重中之重 大家需要认真去处理。计算量大,适合系统建模能力强的团队。
C题:社交媒体平台用户分析问题
C题聚焦用户-博主动态行为预测,属于时序分类与推荐系统问题,需建模用户活跃模式、兴趣漂移和社交网络效应。
问题1预测新增关注数,需融合用户历史行为(观看、点赞、评论)和博主内容特征;问题3-4需预测用户在线状态及互动时段,涉及时间序列分类。主要难点有:数据稀疏(用户间歇性活跃)、行为多模态(四种行为类型)、隐式反馈(观看不一定记录)。
第一问前大家需要对数据进行分析和数值化处理,也就是EDA(探索性数据分析)。对于数值型数据,大家用归一化、去除异常值等方式就可以进行数据预处理。而对于非数值型数据进行量化,大家可以使用以下方法:
1标签编码
标签编码是将一组可能的取值转换成整数,从而对非数值型数据进行量化的一种方法。例如,在机器学习领域中,对于一个具有多个类别的变量,我们可以给每个类别赋予一个唯一的整数值,这样就可以将其转换为数值型数据。
2独热编码onehot
独热编码是将多个可能的取值转换成二进制数组的一种方法。在独热编码中,每个可能取值对应一个长度为总共可能取值个数的二进制数组,其中只有一个元素为1,其余元素均为0。例如,对于一个性别变量,可以采用独热编码将“男”和“女”分别转换为[1, 0]和[0, 1]。
3分类计数
分类计数是将非数值型数据转换为数值型数据的一种简单方法。在分类计数中,我们根据某些特定属性(比如学历、职业等)来对数据进行分类,然后统计每个类别的数量或频率。例如,在调查问卷中,我们可以对某个问题的回答按照“是”、“否”和“不确定”三个类别进行分类,并计算每个类别的数量或频率。
4主成分分析
主成分分析是将多维数据转换为低维度表示的一种方法。在主成分分析中,我们通过找到最能解释数据变异的主成分来对原始数据进行降维处理。这样就可以将非数值型数据转换为数值型数据。
而第一问建议大家使用一些可视化方法,可以使用常见的EDA可视化方法:
-
直方图和密度图:展示数值变量的分布情况。
-
散点图:展示两个连续变量之间的关系。
-
箱线图:展示数值变量的分布情况和异常值。
-
条形图和饼图:展示分类变量的分布情况。
-
折线图:展示随时间或顺序变化的趋势。
-
热力图:展示不同变量之间的相关性。
-
散点矩阵图:展示多个变量之间的散点图矩阵。
-
地理图:展示地理位置数据和空间分布信息。
C君推荐的建模过程:

可使用的算法:1 时序图神经网络(TGN):动态更新用户-博主交互图的嵌入表示。2 深度时空聚类(DeepST):挖掘用户活跃时段模式,预测在线状态。3 传统算法:XGBoost + 时间序列特征(滞后项、滑动窗口统计)。
C题侧重图网络+时序预测,TGN/GAT为前沿选择。这道题目适合所有专业的同学进行选择,是本次比赛的首选题目。
其中更详细的思路,各题目思路、代码、讲解视频、成品论文及其他相关内容,可以点击下方群名片哦!