RAG技术完全指南(一):检索增强生成原理与LLM对比分析
RAG技术完全指南(一):检索增强生成原理与LLM对比分析
文章目录
- RAG技术完全指南(一):检索增强生成原理与LLM对比分析
- 1. RAG 简介
- 2. 核心思想
- 3. 工作流程
- 3.1 数据预处理(索引构建)
- 3.2 查询阶段
- 3.3 流程图
- 4. RAG VS LLM
- 4.1 RAG vs 传统LLM 对比表
- 4.2 如何选择
- 5. 挑战与改进
- 6. 代码示例(简易 RAG 实现)
- 7. 总结
1. RAG 简介
RAG(检索增强生成) 是一种结合 信息检索(Retrieval) 和 大语言模型生成(Generation) 的技术,旨在提升模型生成内容的准确性和事实性。它通过从外部知识库中动态检索相关信息,并将这些信息作为上下文输入给生成模型,从而减少幻觉并提高回答质量。
2. 核心思想
- 检索(Retrieval):根据用户问题,从外部数据库(如文档、网页、知识图谱)中查找相关片段。
- 生成(Generation):将检索到的内容与问题一起输入 LLM,生成更准确的回答。
类比:就像写论文时先查资料(检索),再结合自己的理解写出内容(生成)。
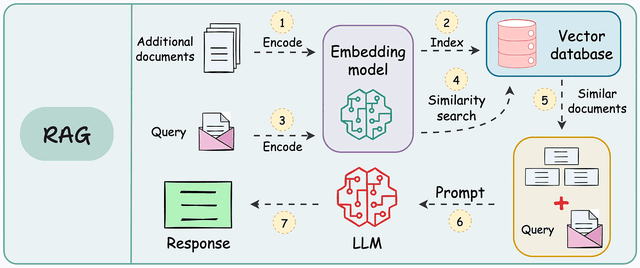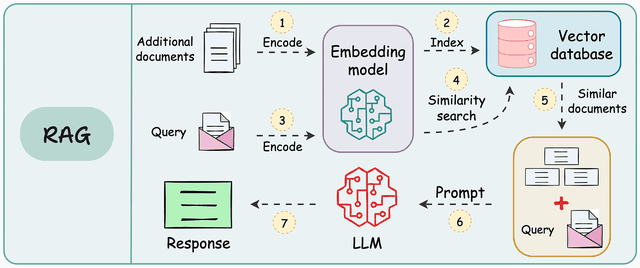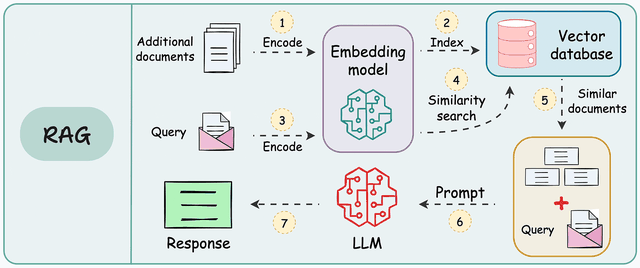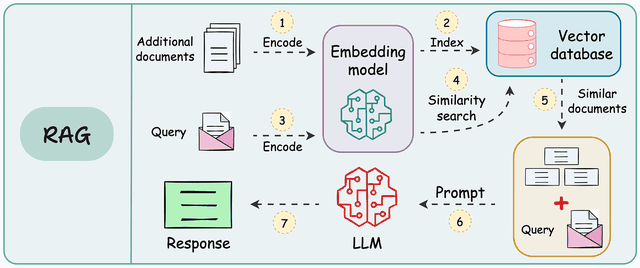
3. 工作流程
3.1 数据预处理(索引构建)
- 将知识库(如 PDF、网页、数据库)拆分成文本块(chunks)。
- 使用 Embedding 模型 将文本转换为向量,存入向量数据库
3.2 查询阶段
- 用户提问:例如 “什么是RAG?”
- 检索相关文档:
- 用相同的 Embedding 模型将问题转换为向量。
- 在向量数据库中计算相似度(如余弦相似度),返回最匹配的文本片段。
- 生成回答:
- 将检索到的文本 + 用户问题一起输入 LLM。
- LLM 结合检索内容生成最终回答。
3.3 流程图
以下是 RAG 的工作流程图:
4. RAG VS LLM
以下是 RAG(检索增强生成) 与传统 大语言模型(LLM) 的对比表格,清晰展示两者的优劣势及适用场景:
4.1 RAG vs 传统LLM 对比表
| 对比维度 | RAG(检索增强生成) | 传统大语言模型(如GPT-4、Llama) |
|---|---|---|
| 知识实时性 | ✅ 可动态更新知识库(依赖外部数据源) | ❌ 仅依赖预训练数据,无法主动更新 |
| 事实准确性 | ✅ 基于检索内容生成,减少幻觉(可引用来源) | ❌ 可能生成虚假信息(幻觉问题显著) |
| 领域适应性 | ✅ 灵活接入专业数据(医学、法律等) | ❌ 通用性强,但专业领域需微调(成本高) |
| 计算成本 | ⚠️ 需维护向量数据库+检索步骤(额外开销) | ✅ 仅生成步骤,推理成本低 |
| 响应速度 | ❌ 检索+生成两步,延迟较高 | ✅ 纯生成,响应更快 |
| 可解释性 | ✅ 可返回参考来源(支持溯源) | ❌ 黑箱生成,无法提供依据 |
| 长尾问题处理 | ✅ 通过检索补充罕见知识 | ❌ 依赖模型记忆,长尾知识覆盖率低 |
| 数据隐私 | ⚠️ 依赖外部数据源,需安全管控 | ✅ 纯模型推理,隐私风险更低 |
| 实现复杂度 | ❌ 需搭建检索系统(分块、Embedding、向量数据库) | ✅ 直接调用API或部署模型,简单易用 |
| 典型应用场景 | 客服问答、学术研究、法律咨询、动态知识库 | 创意写作、代码生成、通用对话、无需更新的场景 |
4.2 如何选择
- 选 RAG:
- 需要高准确性、可溯源的回答(如医疗、法律、学术/研究助手)。
- 知识需频繁更新(如新闻、产品文档)。
- 选传统LLM:
- 追求低延迟和简单部署(如聊天机器人)。
- 创意生成任务(如写故事、营销文案)。
5. 挑战与改进
| 挑战 | 解决方案 |
|---|---|
| 检索效率低 | 使用更快的向量数据库(如 FAISS) |
| 检索内容不精准 | 优化分块策略(chunk size)和 Embedding 模型 |
| 生成模型忽略检索内容 | 在 Prompt 中强调“必须基于检索内容回答” |
| 多模态数据支持 | 结合文本+图像检索(如 CLIP 模型) |
6. 代码示例(简易 RAG 实现)
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np# 1. 加载 Embedding 模型
model = SentenceTransformer("all-MiniLM-L6-v2")# 2. 模拟知识库
documents = ["量子计算利用量子比特(qubit)进行并行计算。","2023年,IBM 发布了433量子比特处理器。","RAG 技术结合检索与生成提升LLM准确性。",
]
doc_embeddings = model.encode(documents) # 向量化知识库# 3. 用户查询
query = "哪一年IBM发布了量子比特处理器?"
query_embedding = model.encode(query)# 4. 检索最相似文档
similarities = cosine_similarity([query_embedding], doc_embeddings)[0]
most_relevant_idx = np.argmax(similarities)
retrieved_text = documents[most_relevant_idx]# 5. 生成回答(模拟LLM)
prompt = f"基于以下信息回答问题:{retrieved_text}\n\n问题:{query}"
print("检索到的内容:", retrieved_text)7. 总结
- RAG = 检索(Retrieval) + 生成(Generation),动态增强 LLM 的知识。
- 核心价值:解决 LLM 的幻觉问题,支持实时更新和领域适配。
- 关键组件:Embedding 模型、向量数据库、检索策略、生成模型。
RAG 是当前最流行的增强 LLM 方案之一,广泛应用于企业知识库、教育、研究等领域。