强化学习_Paper_2017_Curiosity-driven Exploration by Self-supervised Prediction
paper Link: ICM: Curiosity-driven Exploration by Self-supervised Prediction
GITHUB Link: 官方: noreward-rl
1- 主要贡献
- 对好奇心进行定义与建模
- 好奇心定义:next state的prediction error作为该state novelty
- 如果智能体真的“懂”一个state,那么给出这个state和所做的action,它应该能很准确的predict出next state是什么。也就是“What I can not predict well, is novel”
- 好奇心定义:next state的prediction error作为该state novelty
- 提出了Intrinsic Curiosity Module(ICM)来估计一个状态的novelty大小,并给予相应的内在奖励(intrinsic reward)
- 研究了3种泛化环境,验证了好奇心在实际环境中的作用
- 稀疏的外在奖励, 好奇心使得与环境少量的互动,就那么好以实现目标;
- 不添加外在奖励的探索,好奇心促使主体更有效地探索;
- 泛化到看不见的场景(例如同一游戏的新级别),在这些场景中,从早期经验中获得的知识可以帮助agnet比重新开始更快地探索新的地方。
2- Intrinsic Curiosity Module (ICM) 框架
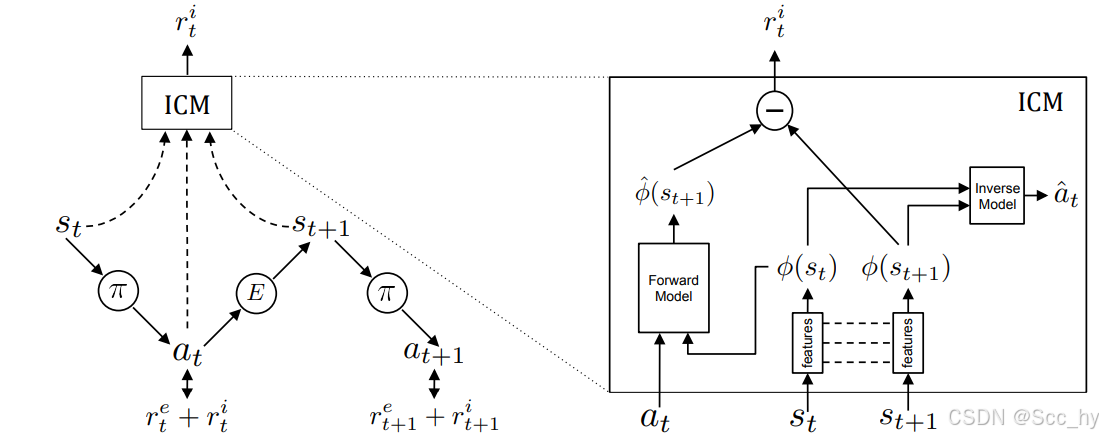
2.1 ICM三大件:
- Encoder( θ E \theta_E θE):
- 将current state转换成feature ϕ ( s t ) \phi(s_t) ϕ(st)
- 将next state转换成feature ϕ ( s t + 1 ) \phi(s_{t+1}) ϕ(st+1)
- Forward Model( θ F \theta_F θF): 给定 ϕ ( s t ) \phi(s_t) ϕ(st) 和 action a t a_t at, 来估计next state feature ϕ ^ ( s t + 1 ) \hat{\phi}(s_{t+1}) ϕ^(st+1)
- 用 min θ F L ( ϕ ^ ( s t + 1 ) , ϕ ( s t + 1 ) ) \min_{\theta_F} L(\hat{\phi}(s_{t+1}), \phi(s_{t+1})) minθFL(ϕ^(st+1),ϕ(st+1))
- r t i = η 2 ∣ ∣ ϕ ^ ( s t + 1 ) − ϕ ( s t + 1 ) ∣ ∣ 2 2 r^i_t = \frac{\eta}{2} ||\hat{\phi}(s_{t+1}) - \phi(s_{t+1})||^2_2 rti=2η∣∣ϕ^(st+1)−ϕ(st+1)∣∣22
- Inverse Model( θ I \theta_I θI): 给定 ϕ ( s t ) \phi(s_t) ϕ(st) 和 ϕ ( s t + 1 ) \phi(s_{t+1}) ϕ(st+1), 来估计action a ^ t \hat{a}_t a^t
- 用 $\min_{\theta_I, \theta_E} L(a_t, \hat{a}_t) $
- 让Encoder输出的表征限制于智能体、改变的空间里
2.2 三大件的作用:
- Encoder显然就是将state编码
- Forward Model就是基于state-Encoder和action给出next state feature, 用真实next state feature和预估的值的差异作为好奇心内在奖励
- 对于见到少的组合给出的预估会不准,即好奇心reward会高
- Inverse Model让Encoder输出的表征限制于智能体、改变的空间里
- 因为Encoder+Forward Model会引入一个Noisy-TV Problem(雪花屏问题):
- 当画面都是噪音的时候,观察者无法对下一个state做出预测
- 即预估和真实next state feature始终差异较大,内在奖励就非常大,会导致观察者很上瘾,一直盯着noisy TV看:比如开枪时火花的随机渲染,智能体可能就会一直停在原地开火,欣赏迸发出的火花
- 所以Inverse Model根据两个相邻的state来推断智能体所选的action a ^ t \hat{a}_t a^t。然后利用inverse prediction error( L ( a t , a ^ t ) L(a_t, \hat{a}_t) L(at,a^t) )来训练Encoder。
- 最终 Encoder就不在意两个不同的噪音的差别,也就不会提供novelty奖励了
- 因为Encoder+Forward Model会引入一个Noisy-TV Problem(雪花屏问题):
反向传播迭代图示
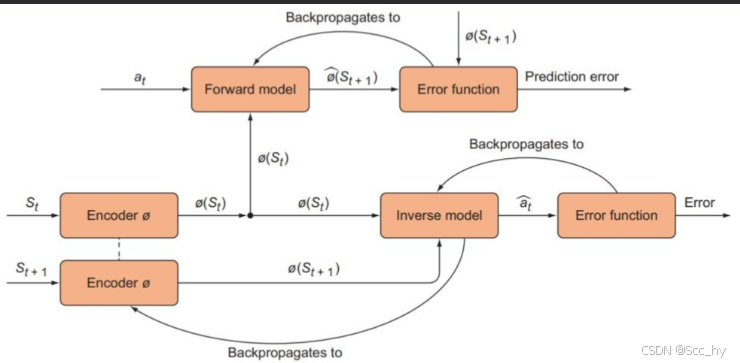
- Forward Model的Prediction error只用来训练forward model,而不用于训练Encoder
- 即 ϕ ^ ( s t + 1 ) = f F ( ϕ ( s t ) , a t ; θ F ) ; min θ F L ( ϕ ^ ( s t + 1 ) , ϕ ( s t + 1 ) ) \hat{\phi}(s_{t+1})= f_{F}(\phi(s_t), a_t; \theta_F);\min_{\theta_F} L(\hat{\phi}(s_{t+1}), \phi(s_{t+1})) ϕ^(st+1)=fF(ϕ(st),at;θF);minθFL(ϕ^(st+1),ϕ(st+1))
- 对 ϕ ( s t ) , ϕ ( s t + 1 ) \phi(s_{t}), \phi(s_{t+1}) ϕ(st),ϕ(st+1) detach
- Inverse Model的Inverse prediction error既用来训练Inverse model,也用来Encoder
- 即 min θ I , θ E L ( a t , a ^ t ) \min_{\theta_I, \theta_E} L(a_t, \hat{a}_t) minθI,θEL(at,a^t)
- a ^ t = f I ( ϕ ( s t ) , ϕ ( s t + 1 ) ; θ I ) = f I ( ϕ ( s t ) , f E ( s t + 1 ; θ E ) ) ; θ I ) \hat{a}_t = f_{I}( \phi(s_t), \phi(s_{t+1}); \theta_I) = f_{I}( \phi(s_t), f_{E}(s_{t+1}; \theta_E)); \theta_I) a^t=fI(ϕ(st),ϕ(st+1);θI)=fI(ϕ(st),fE(st+1;θE));θI)
- 对 ϕ ( s t ) \phi(s_{t}) ϕ(st) detach
3- python code
ICM code
from torch import nn
import torch
import torch.nn.functional as Fclass cnnICM(nn.Module):def __init__(self, channel_dim,state_dim, action_dim):super(cnnICM, self).__init__()self.state_dim = state_dimself.channel_dim = channel_dimself.action_dim = action_dimself.cnn_encoder_feature = nn.Sequential(nn.Conv2d(channel_dim, 32, kernel_size=8, stride=4),nn.ReLU(),nn.Conv2d(32, 64, kernel_size=4, stride=2),nn.ReLU(),nn.Conv2d(64, 64, kernel_size=3, stride=1),nn.ReLU(),nn.Flatten())cnn_out_dim = self._get_cnn_out_dim()self.cnn_encoder_header = nn.Sequential(nn.Linear(cnn_out_dim, 512),nn.ReLU())# 离散动作self.action_emb = nn.Embedding(self.action_dim, self.action_dim)self.forward_model = nn.Sequential(nn.Linear(512 + action_dim, 256),nn.ReLU(),nn.Linear(256, 512),)self.inverse_model = nn.Sequential(nn.Linear(512 + 512, 256),nn.ReLU(),nn.Linear(256, action_dim),nn.Softmax())@torch.no_graddef _get_cnn_out_dim(self):pic = torch.randn((1, self.channel_dim, self.state_dim, self.state_dim))return self.cnn_encoder_feature(pic).shape[1] def encode_pred(self, state):return self.cnn_encoder_header(self.cnn_encoder_feature(state))def forward_pred(self, phi_s, action):return self.forward_model(torch.concat([phi_s, self.action_emb(action)], dim=1))def inverse_pred(self, phi_s, phi_s_next):return self.inverse_model(torch.concat([phi_s, phi_s_next], dim=1))def forward(self, state, n_state, action, mask):# 离散动作action = action.type(torch.LongTensor).reshape(-1).to(state.device)# encodephi_s = self.encode_pred(state)phi_s_next = self.encode_pred(n_state)# forward 不用于训练Encoderhat_phi_s_next = self.forward_pred(phi_s.detach(), action)# intrinisc reward & forward_loss r_i = 0.5 * nn.MSELoss(reduction='none')(hat_phi_s_next, phi_s_next.detach())r_i = r_i.mean(dim=1) * mask forward_loss = r_i.mean()# inverse 同时用于训练Encoderhat_a = self.inverse_pred(phi_s.detach(), phi_s_next)# inverse loss inv_loss = (nn.CrossEntropyLoss(reduction='none')(hat_a, action) * mask).mean()return r_i, inv_loss, forward_loss