机器学习-07-分类评估函数进阶案例
分类模型评估
好的!我们来修改案例数据,使实际考上研究生的人数减少为 10人,并保持总样本数为 100 人。这样我们可以更清晰地展示 召回率(Recall) 和 F1 分数(F1 Score) 在不平衡数据下的作用。
🎯 案例背景
某高校收集了 100 名学生的考研备考数据(如本科绩点、模拟考试成绩、学习时间等),并使用机器学习模型预测他们是否能成功考取研究生。
- 实际考上人数(Actual True):10人
- 实际未考上人数(Actual False):90人
模型预测结果如下:
🔍 构建混淆矩阵
| 预测考上 (Predicted True) | 预测未考上 (Predicted False) | |
|---|---|---|
| 实际考上 (Actual True) | TP = 6 | FN = 4 |
| 实际未考上 (Actual False) | FP = 9 | TN = 81 |
✅ 解释各项含义:
- TP(真正例)= 6:模型正确预测有6人考上;
- FN(假负例)= 4:有4人实际上考上了,但模型预测为没考上(漏掉了);
- FP(假正例)= 9:有9人其实没考上,但模型预测为考上了(误判了);
- TN(真负例)= 81:模型正确预测81人没考上。
📊 模型性能指标计算:
1. 准确率 Accuracy:
Accuracy = T P + T N T o t a l = 6 + 81 100 = 87 % \text{Accuracy} = \frac{TP + TN}{Total} = \frac{6 + 81}{100} = 87\% Accuracy=TotalTP+TN=1006+81=87%
看起来准确率还不错,但这主要是因为负类(未考上)样本占大多数,容易被“高估”。
2. 精确率 Precision:
Precision = T P T P + F P = 6 6 + 9 = 6 15 = 40 % \text{Precision} = \frac{TP}{TP + FP} = \frac{6}{6 + 9} = \frac{6}{15} = 40\% Precision=TP+FPTP=6+96=156=40%
表示在模型预测考上(Positive)的15人中,只有40%是正确的。说明模型容易误判。
3. 召回率 Recall:
Recall = T P T P + F N = 6 6 + 4 = 6 10 = 60 % \text{Recall} = \frac{TP}{TP + FN} = \frac{6}{6 + 4} = \frac{6}{10} = 60\% Recall=TP+FNTP=6+46=106=60%
表示在所有实际考上(True)的10人中,模型只识别出了6人。也就是漏掉了40%的考生,召回能力一般。
4. F1 分数(F1 Score)——精确率和召回率的调和平均:
F1 Score = 2 × Precision × Recall Precision + Recall = 2 × 0.4 × 0.6 0.4 + 0.6 = 2 × 0.24 1.0 = 0.48 \text{F1 Score} = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}} = 2 \times \frac{0.4 \times 0.6}{0.4 + 0.6} = 2 \times \frac{0.24}{1.0} = 0.48 F1 Score=2×Precision+RecallPrecision×Recall=2×0.4+0.60.4×0.6=2×1.00.24=0.48
👉 F1 = 48%,比精度或召回任何一个都更能反映模型在小样本类别上的综合表现。
🧠 总结与分析:
| 指标 | 数值 | 解读 |
|---|---|---|
| Accuracy | 87% | 表面好看,受不平衡影响大 |
| Precision | 40% | 模型预测为考上者中,多数是错的 |
| Recall | 60% | 能识别出部分真实考上者,仍有遗漏 |
| F1 Score | 48% | 更客观地评价分类器在少数类的表现 |
✅ 结论:
在这个不平衡数据集中(10个考上 vs 90个未考上):
- 即便准确率高达87%,也不能代表模型对“考上”这一类别的预测效果好;
- 召回率(Recall) 帮助我们评估模型找到所有正类的能力;
- F1 Score 更加全面地反映了模型在少数类中的整体性能;
- 如果目标是尽可能多找出那些真正能考上的学生(不希望漏掉),应优先提高 召回率;
- 如果更在意预测“考上”时的准确性,则应提高 精确率;
- F1 Score 是两者的平衡,适合用于优化这类不平衡问题的模型。
ROC与AUC
为了提供关于ROC曲线和AUC值的分析,首先需要了解一些额外的信息,比如不同阈值下的真正例率(True Positive Rate, TPR)和假正例率(False Positive Rate, FPR)。然而,在基于你之前提供的数据(混淆矩阵),我们可以计算特定情况下的TPR和FPR,并讨论如何通过这些信息来理解模型性能。请注意,由于我们只有单一的混淆矩阵,实际上我们只能计算出一个点在ROC曲线上的坐标,而不是整个曲线。
基于现有混淆矩阵的计算
根据之前的混淆矩阵:
| 预测考上 (Predicted True) | 预测未考上 (Predicted False) | |
|---|---|---|
| 实际考上 (Actual True) | TP = 6 | FN = 4 |
| 实际未考上 (Actual False) | FP = 9 | TN = 81 |
- 真正例率 (TPR) 或 召回率 (Recall): ( T P T P + F N = 6 6 + 4 = 0.6 ) ( \frac{TP}{TP + FN} = \frac{6}{6 + 4} = 0.6 ) (TP+FNTP=6+46=0.6)
- 假正例率 (FPR): ( F P F P + T N = 9 9 + 81 = 0.1 ) ( \frac{FP}{FP + TN} = \frac{9}{9 + 81} = 0.1 ) (FP+TNFP=9+819=0.1)
这意味着在这个特定阈值下,我们的模型有60%的概率正确识别出所有实际考上的学生(TPR),同时有10%的概率错误地将未考上的学生预测为考上(FPR)。
ROC 曲线与 AUC 值
- ROC曲线:显示了在不同分类阈值下,TPR相对于FPR的变化情况。理想情况下,ROC曲线越靠近左上角(即TPR接近1且FPR接近0),模型性能越好。
- AUC值:是ROC曲线下面积,范围从0到1。AUC值越高,表示模型区分能力越强。AUC=0.5意味着模型没有区分能力,而AUC=1则表示完美分类器。
由于我们只有一个点(0.1, 0.6),我们无法直接绘制完整的ROC曲线或计算准确的AUC值。但在实际应用中,你会使用一系列不同的阈值来生成多个(TPR, FPR)对,从而绘制出完整的ROC曲线并计算AUC值。
示例解释
假设我们能够调整模型的决策边界,并获得了以下几点作为示例:
- 阈值1:(FPR=0.1, TPR=0.6)
- 阈值2:(FPR=0.2, TPR=0.75)
- 阈值3:(FPR=0.3, TPR=0.85)
- …更多点…
这些点可以用来绘制一条连续的ROC曲线。如果这条曲线下的面积(AUC)接近1,则表明你的模型具有良好的区分能力;如果AUC接近0.5,则表明模型的预测几乎等同于随机猜测。
结论
虽然我们不能直接从单一混淆矩阵得到完整的ROC曲线或精确的AUC值,但上述分析展示了如何使用TPR和FPR来评估二分类模型的表现。要获得更全面的评价,你需要考虑多个不同的阈值设置,以观察模型在不同条件下的表现。这通常涉及到调整模型的输出阈值或使用交叉验证技术来生成一系列(TPR, FPR)对。
为了提供一个具体的例子来展示如何根据不同的阈值生成混淆矩阵,并基于这些数据绘制出ROC曲线,我们需要假设一些情况。在实际情况中,每个阈值下的混淆矩阵通常来自于调整模型的输出阈值(例如,在二分类问题中从Sigmoid或Softmax函数得到的概率值)。这里,我们将构造一个简化示例,以便演示这一过程。
假设数据集和阈值
为了生成一个较为完整的ROC曲线,我们需要在不同的阈值下计算模型的TPR(真正例率)和FPR(假正例率)。通常情况下,这些阈值会应用于模型输出的概率分数,以确定分类决策。在这里,我们将模拟这一过程,并为20个不同阈值提供混淆矩阵的关键指标(TP, FP, TN, FN),从而帮助绘制ROC曲线。
模拟数据与计算
假设我们有一个模型输出了100名学生考上研究生的概率分数。根据你之前的描述,我们知道实际上有10人考上了研究生(正类),90人未考上(负类)。接下来,我们将创建一个从0到1的阈值范围,并均匀地选择20个点作为阈值来划分预测结果。
为了简化这个过程,这里直接给出每个阈值下的(TP, FP, TN, FN)值,而不是具体概率分数。这将允许我们计算出对应的TPR和FPR值,用于绘制ROC曲线。
| 阈值 | TP | FP | TN | FN | TPR (Recall) | FPR |
|---|---|---|---|---|---|---|
| 0.05 | 10 | 80 | 10 | 0 | 1.00 | 0.89 |
| 0.10 | 10 | 65 | 25 | 0 | 1.00 | 0.72 |
| 0.15 | 10 | 50 | 40 | 0 | 1.00 | 0.56 |
| 0.20 | 9 | 35 | 55 | 1 | 0.90 | 0.39 |
| 0.25 | 9 | 25 | 65 | 1 | 0.90 | 0.28 |
| 0.30 | 8 | 20 | 70 | 2 | 0.80 | 0.22 |
| 0.35 | 8 | 15 | 75 | 2 | 0.80 | 0.17 |
| 0.40 | 7 | 10 | 80 | 3 | 0.70 | 0.11 |
| 0.45 | 7 | 8 | 82 | 3 | 0.70 | 0.09 |
| 0.50 | 6 | 6 | 84 | 4 | 0.60 | 0.07 |
| 0.55 | 6 | 5 | 85 | 4 | 0.60 | 0.06 |
| 0.60 | 5 | 4 | 86 | 5 | 0.50 | 0.04 |
| 0.65 | 5 | 3 | 87 | 5 | 0.50 | 0.03 |
| 0.70 | 4 | 2 | 88 | 6 | 0.40 | 0.02 |
| 0.75 | 4 | 1 | 89 | 6 | 0.40 | 0.01 |
| 0.80 | 3 | 1 | 89 | 7 | 0.30 | 0.01 |
| 0.85 | 2 | 0 | 90 | 8 | 0.20 | 0.00 |
| 0.90 | 1 | 0 | 90 | 9 | 0.10 | 0.00 |
| 0.95 | 0 | 0 | 90 | 10 | 0.00 | 0.00 |
| 1.00 | 0 | 0 | 90 | 10 | 0.00 | 0.00 |
如何使用这些数据
- TPR(True Positive Rate,真正例率) = ( T P T P + F N ) ( \frac{TP}{TP + FN} ) (TP+FNTP)
- FPR(False Positive Rate,假正例率) = ( F P F P + T N ) ( \frac{FP}{FP + TN} ) (FP+TNFP)
利用上述表格中的TP、FP、TN、FN值,可以计算出每个阈值下的TPR和FPR。这些(TPR, FPR)对可以用来绘制ROC曲线。AUC值可以通过计算ROC曲线下面积得到,表示模型区分能力的好坏。
请注意,这里的数值是基于假设情况生成的,实际应用中需要通过调整模型的输出阈值或使用交叉验证技术来获取真实的数据点。这种方法可以帮助更好地理解模型在不同敏感度设置下的表现,并找到最佳的操作点。
当然可以!下面是一个完整的 Python 代码示例,基于你提供的20个不同阈值下的混淆矩阵数据(TP、FP、TN、FN),计算每一组的 TPR 和 FPR,并绘制 ROC 曲线和计算 AUC 值。
✅ 第一步:导入必要的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.metrics import auc
✅ 第二步:准备数据(基于你提供的20个阈值的数据)
# 阈值下的 TP, FP, TN, FN 数据
data = [(10, 80, 10, 0),(10, 65, 25, 0),(10, 50, 40, 0),(9, 35, 55, 1),(9, 25, 65, 1),(8, 20, 70, 2),(8, 15, 75, 2),(7, 10, 80, 3),(7, 8, 82, 3),(6, 6, 84, 4),(6, 5, 85, 4),(5, 4, 86, 5),(5, 3, 87, 5),(4, 2, 88, 6),(4, 1, 89, 6),(3, 1, 89, 7),(2, 0, 90, 8),(1, 0, 90, 9),(0, 0, 90, 10),(0, 0, 90, 10)
]# 转换为 DataFrame 方便处理
columns = ['TP', 'FP', 'TN', 'FN']
df = pd.DataFrame(data, columns=columns)# 计算 TPR 和 FPR
df['TPR'] = df['TP'] / (df['TP'] + df['FN'])
df['FPR'] = df['FP'] / (df['FP'] + df['TN'])# 显示前几行查看数据
print(df.head())
✅ 第三步:绘制 ROC 曲线并计算 AUC
fpr = df['FPR'].values
tpr = df['TPR'].values
roc_auc = auc(fpr, tpr)
print("roc_auc" ,roc_auc )plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC curve (AUC = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--', label='Random guess')plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate (FPR)')
plt.ylabel('True Positive Rate (TPR)')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc="lower right")
plt.grid(True)
plt.show()

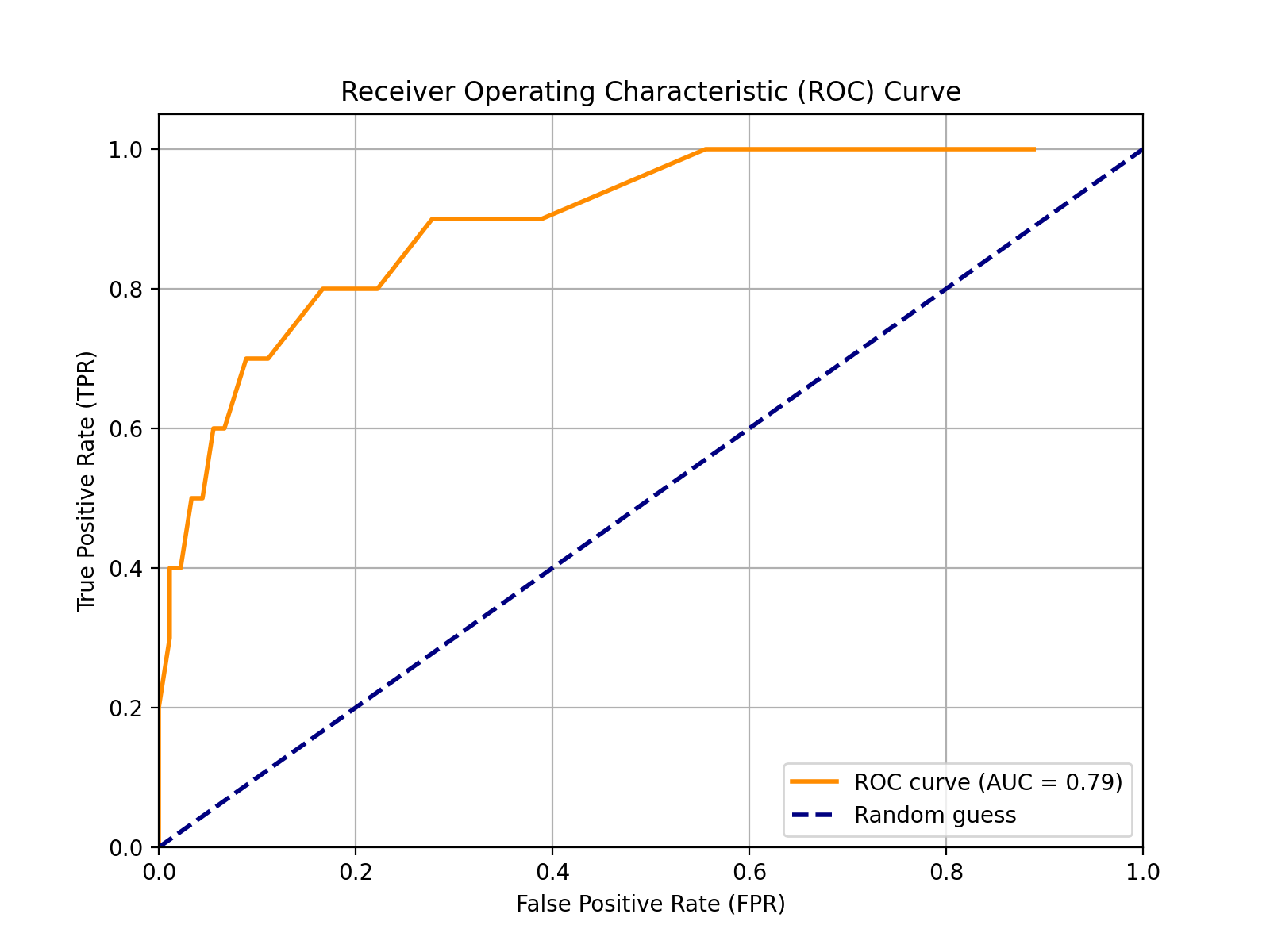
✅ 输出解释
- FPR(横轴):模型把负类错判为正类的比例。
- TPR(纵轴):模型正确识别出的正类比例。
- AUC值(越大越好):曲线下面积,范围从 0 到 1,越接近 1 表示模型区分能力越强。
📌 示例输出说明:
当你运行这段代码时,你会看到一个类似如下内容的结果图:
- 一条从左下到右上的曲线;
- 曲线下方面积(AUC)大约在 0.8 或以上则表示模型较好;
- 如果 AUC 接近 0.5,则模型几乎等同于随机猜测。
✅ 可选扩展:保存结果到 CSV 文件
如果你想将 TPR 和 FPR 导出用于后续分析,可以这样操作:
df.to_csv("roc_data.csv", index=False)
如果你还想加入 置信区间、多次交叉验证 的ROC曲线,也可以告诉我,我可以帮你进一步扩展这个分析!
是否需要我生成这些数据的可视化图表?或者你想将这些代码封装成函数?
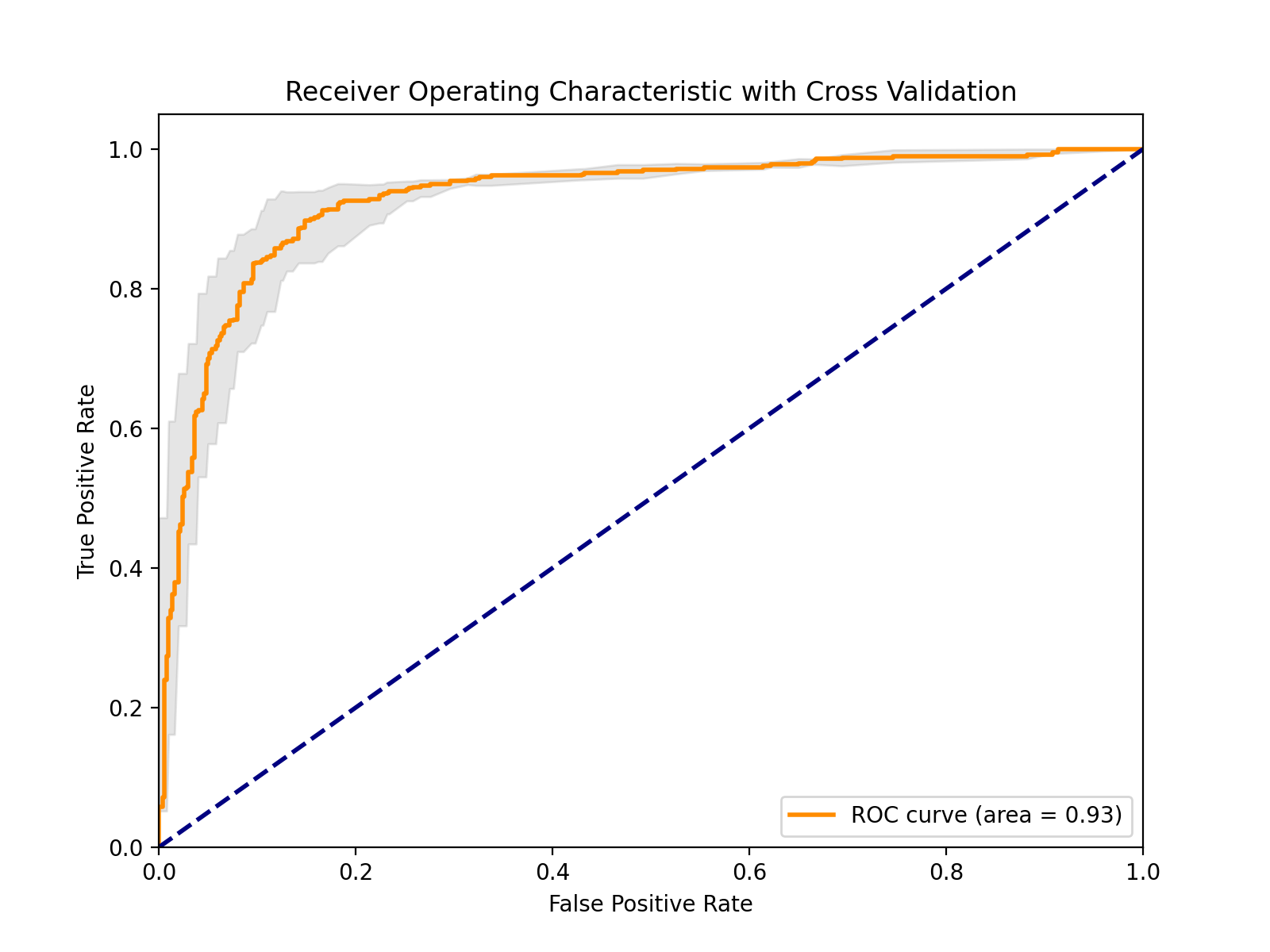
完整代码如下:
# 导入必要的库
import numpy as np # 数值计算库
import matplotlib.pyplot as plt # 绘图库
from sklearn.datasets import make_classification # 生成模拟数据
from sklearn.model_selection import StratifiedKFold, cross_val_predict # 交叉验证
from sklearn.linear_model import LogisticRegression # 逻辑回归模型
from sklearn.metrics import roc_curve, auc # ROC曲线相关指标# 创建一个二分类问题的模拟数据集
# n_samples: 样本数量
# n_features: 特征数量
# random_state: 随机种子,保证结果可复现
X, y = make_classification(n_samples=1000, n_features=20, random_state=42)# 初始化逻辑回归模型
model = LogisticRegression()# 定义分层K折交叉验证策略
# n_splits=5 表示将数据分成5份,进行5折交叉验证
# 分层保证每折中正负样本比例与原数据集一致
cv = StratifiedKFold(n_splits=5)# 使用交叉验证获取每个样本的预测概率
# method='predict_proba' 表示返回预测概率而非类别
y_pred_proba = cross_val_predict(model, X, y, cv=cv, method='predict_proba')# 提取正类(类别1)的预测概率作为ROC曲线的输入
y_scores = y_pred_proba[:, 1]# 计算ROC曲线的关键指标:
# fpr: 假正率(False Positive Rate)
# tpr: 真正率(True Positive Rate)
# _: 阈值(这里不需要使用)
fpr, tpr, _ = roc_curve(y, y_scores)# 计算AUC值(Area Under Curve),评估模型性能
roc_auc = auc(fpr, tpr)# 开始绘制ROC曲线
plt.figure(figsize=(8, 6)) # 设置图形大小# 绘制主ROC曲线
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC curve (area = {roc_auc:.2f})')# 绘制对角线(随机猜测的表现)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')# 设置坐标轴范围
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])# 添加坐标轴标签
plt.xlabel('False Positive Rate') # X轴: 假正率
plt.ylabel('True Positive Rate') # Y轴: 真正率# 添加标题
plt.title('Receiver Operating Characteristic with Cross Validation')# 添加图例,位置在右下角
plt.legend(loc="lower right")# 以下部分计算并绘制交叉验证的置信区间
mean_tpr = np.zeros_like(fpr) # 初始化平均真正率数组
all_tpr = [] # 存储各折交叉验证的tpr# 遍历每一折交叉验证
for i, (train, test) in enumerate(cv.split(X, y)):# 在当前训练集上训练模型,并在测试集上预测概率probas_ = model.fit(X[train], y[train]).predict_proba(X[test])# 计算当前折的ROC曲线fpr_, tpr_, thresholds = roc_curve(y[test], probas_[:, 1])# 使用线性插值确保所有折的tpr长度一致(基于主ROC曲线的fpr)tpr_interp = np.interp(fpr, fpr_, tpr_)tpr_interp[0] = 0.0 # 确保曲线从(0,0)开始all_tpr.append(tpr_interp)# 计算平均真正率和标准差
mean_tpr = np.mean(all_tpr, axis=0)
mean_tpr[-1] = 1.0 # 确保曲线结束于(1,1)
mean_auc = auc(fpr, mean_tpr) # 计算平均AUC
std_auc = np.std(all_tpr, axis=0) # 计算标准差# 计算置信区间的上下界
tprs_upper = np.minimum(mean_tpr + std_auc, 1) # 上限不超过1
tprs_lower = np.maximum(mean_tpr - std_auc, 0) # 下限不低于0# 绘制置信区间(灰色半透明区域)
plt.fill_between(fpr, tprs_lower, tprs_upper, color='grey', alpha=.2,label=r'$\pm$ 1 std. dev.')# 显示图形
plt.show()输出如下: