Rust 基础语法
变量
变量绑定
变量绑定,在传统语言中,如 var a = 1 称为将 1 赋值给变量 a。let a = 1 但在 Rust 中我们称为变量绑定。
为什么用绑定而不是赋值?这里涉及到了一个核心概念 —— 所有权。
所有权:某一段内存都存在一个主人,每段内存只能由对应的主人来操作管理。
数值 1 会有一小段内存专门用于存储该值,而这一小段内存的主人叫做 a,所以我们成 1 的内存空间被 a 绑定。
不可修改的变量、可修改的变量
不可修改的变量
fn varible() {let x = 5;println!("x = {}", x);x = 6; // 编译时报错println!("x = {}", x);
}
可以修改的变量,使用 mut 修饰。
fn varible() {let mut x = 5;println!("x = {}", x); // 5x = 6;println!("x = {}", x); // 6
}
下划线修饰符 —— 模式匹配
变量定义但未使用,将被警告
let _x = 5;
let y = 6;
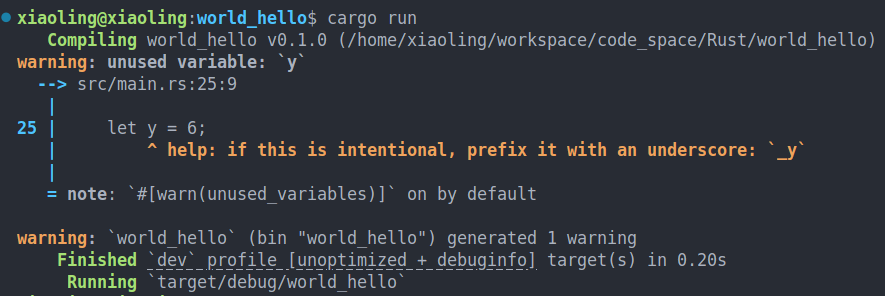
可以看到只有变量
y报警告了,而_x并没有。刚刚开始一个项目,我们并不想让未使用的变量报警告,所以可以使用
_来修改变量。
变量解构
基本介绍
// a 不可改,b 可变
let (a, mut b) : (bool, bool) = (true, true);
println!("a = {:?}, b = {:?}", a, b); // a = true, b = true
b = true;
assert_eq!(a, b);
各种类型的解构
let (a, b, c, d, e);// 元组解构
(a, b) = (1, 2);
println!("a = {}, b = {}", a, b); // a = 1, b = 2// 数组解构
[c, .., d, _] = [1, 2, 3, 4, 5];
// .. 忽略了 2 和 3
// _ 忽略了 5
println!("c = {}, d = {}", c, d); // c = 1, d = 4// 结构体解构
Struct { e, .. } = Struct { e: 5 }; // .. 忽略剩下成员
println!("e = {}", e); // e = 5assert_eq!([1, 2, 1, 4, 5], [a, b, c, d, e]);
变量与常量
Rust 常量使用 const 定义,必须一开始就定义好并且后续无法重新绑定(赋值)!
不可修改变量使用 let 修饰,但是可以仅定义,然后后续再绑定(赋值)。
变量遮蔽(屏蔽)
Rust 允许声明相同的变量名,但是后面的变量会屏蔽掉前面的相同变量。
要注意,是屏蔽,而不是覆盖。如 let x = x + 1 并不是在 let x = 5 的内存空间上将 5 修改为 6,而是重新申请的空间!如果 x 使用 mut 修饰,那么就是操作的同一个内存空间。
let x = 5;
let x = x + 1; // 6
{let x = x * 2;println!("[inner] x = {}", x); // 12
}
println!("[outer] x = {}", x); // 6
数值类型
基本数据类型
- 数值类型:有符号整数 (
i8,i16,i32,i64,isize)、 无符号整数 (u8,u16,u32,u64,usize) 、浮点数 (f32,f64)、以及有理数、复数 - 字符串:字符串字面量和字符串切片
&str - 布尔类型:
true和false - 字符类型:表示单个 Unicode 字符,存储为 4 个字节
- 单元类型:即
(),其唯一的值也是()
类型推导与标记
Rust 是一门静态类型语言。
Rust 编译器可以根据变量值和上下文中的使用方式来自动推导出变量的类型。
当无法自动推导的时候,就需要手动标注数据类型。
下面这段代码是将字符串 42 进行解析,而编译器在这里无法推导出我们想要的类型,因此编译器就会报错。
let guess = "42".parse().expect("Not a number!");
修正:给 guess 变量显式指定数据类型(标记数据类型)
// 方式一
let guess: i32 = "42".parse().expect("Not a number!");
// 方式二
let guess = "42".parse::<i32>().expect("Not a number!");
整数类型
| 长度 | 有符号类型 | 无符号类型 |
|---|---|---|
| 8 位 | i8 | u8 |
| 16 位 | i16 | u16 |
| 32 位 | i32 (默认) | u32 |
| 64 位 | i64 | u64 |
| 128 位 | i128 | u128 |
| 视架构而定 | isize | usize |
i integer 有符号整形
u unsigned 无符号类型
isize 和 usize 类型取决于程序运行的计算机 CPU 类型:
- 若 CPU 是 32 位的,则这两个类型是 32 位的。
- 若 CPU 是 64 位,那么它们则是 64 位。
isize 和 usize 的主要应用场景是用作集合的索引。
Rust 的溢出规则:
-
当在 debug 模式编译时,Rust 会检查整型溢出,若存在这些问题,则使程序在编译时 panic (崩溃,Rust 使用这个术语来表明程序因错误而退出)。
-
在当使用
--release参数进行 release 模式构建时,Rust 不检测溢出。相反,当检测到整型溢出时,Rust 会按照补码循环溢出(two’s complement wrapping)的规则处理。比如在
u8的情况下,256 变成 0,257 变成 1,依此类推。程序不会报错,但是其值可能并不是我们期望的那样。
对于整形的溢出,可以使用标准库来显示处理:
-
使用
wrapping_*方法:在所有模式下都按照补码循环溢出规则处理,例如wrapping_add -
如果使用
checked_*方法:时发生溢出,则返回None值 -
使用
overflowing_*方法:返回该值和一个指示是否存在溢出的布尔值 -
使用
saturating_*方法:可以限定计算后的结果不超过目标类型的最大值或低于最小值,例如:assert_eq!(100u8.saturating_add(1), 101); assert_eq!(u8::MAX.saturating_add(127), u8::MAX);
示例
let a: u8 = 255;
let b = a.wrapping_add(20); // 255 + 20 = 275 % 256 = 19
println!("{}", b); // 19
浮点类型
一共两种:
f32: 32 位浮点数,类似 floatf64: 64 位浮点数,类似 double。(默认)
由于浮点数并不像整形那样精确,在浮点型之间进行比较时,如果在数学上不能严格定义,那么就不要直接比较。
一些浮点数陷阱的例子:
// 断言 0.1 + 0.2 与 0.3 相等否?
assert!(0.1 + 0.2 == 0.3);
答案是 false,因为 0.1 + 0.2 是浮点数相加,相加的结果并不能保证一定为 0.3。
fn main() {let abc: (f32, f32, f32) = (0.1, 0.2, 0.3);let xyz: (f64, f64, f64) = (0.1, 0.2, 0.3);println!("abc (f32)");println!(" 0.1 + 0.2: {:x}", (abc.0 + abc.1).to_bits()); // 3e99999aprintln!(" 0.3: {:x}", (abc.2).to_bits()); // 3e99999aprintln!();println!("xyz (f64)");println!(" 0.1 + 0.2: {:x}", (xyz.0 + xyz.1).to_bits()); // 3fd3333333333334println!(" 0.3: {:x}", (xyz.2).to_bits()); // 3fd3333333333333println!();assert!(abc.0 + abc.1 == abc.2); // SUCCESSassert!(xyz.0 + xyz.1 == xyz.2); // FAILED,因为 double 的精度比较高,所以可能存在微小的偏差
}
abc (f32)0.1 + 0.2 = 3e99999a0.3 = 3e99999a
abc (f64)0.1 + 0.2 = 3fd33333333333340.3 = 3fd3333333333333thread 'main' panicked at src/main.rs:90:5:
assertion failed: xyz.0 + xyz.1 == xyz.2
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
NaN
NaN 表示:数学上不存在的结果。
let x = (-33.0_f32).sqrt(); // 对负数 sqrt,这必然在数学上不合法。因此 x = NaN
let y = x + 10_f32; // 所有与 NaN 的交互,最终都是 NaNprintln!("{}", y); // NaN
assert_eq!(x, x); // ERROR
可使用 is_nan() 来判断一个数值是否为 NaN。
let x = (-33.0_f32).sqrt();if !x.is_nan() {let y = x + 10_f32;println!("{}", y);
} else {println!("x is NaN");
}
序列(Range)
作用:连续生成一串数字或字符。
限制:只允许生成数字或字符,因为生成的序列必须是连续的。
for i in 1..=5 {print!("{} ", i);
}println!();for ch in 'a'..='z' {print!("{} ", ch);
}
使用 AS 完成类型转换
Rust 中可以使用 As 来完成一个类型到另一个类型的转换,其最常用于将原始类型转换为其他原始类型,但是它也可以完成诸如将指针转换为地址、地址转换为指针以及将指针转换为其他指针等功能。你可以在这里了解更多相关的知识。
与其它语言的区别
- Rust 类型转换必须是显示的,并不存在隐式转换的说话,如它永远不会将你的 16bit 转为 32bit 整数。
- Rust 在数值上可以调用方法,如
13.14_f32.round()取整。
字符、布尔、单元类型
字符类型
支持 Unicode 值的范围从 U+0000 ~ U+D7FF 和 U+E000 ~ U+10FFFF 。
由于 Unicode 都是 4 个字节编码,因此字符类型也是占用 4 个字节。
let ch = 'x';
let ch: char = 'x';
布尔类型
大小:1 字节
let flag = true;
let flag: bool = false;
单元类型
一个组括号 () 这就成为单元类型。唯一的值也是 ()。
作用:表示无意义的返回值。(每个函数都必须要有返回值)
内存大小:0 字节
let unit: () = ();
assert!(size_of_val(&unit) == 0); // SUCCESS
fn main() 函数默认返回 () 单元类型,所以我们不能说 main 函数没有返回值!
Rust 中没有返回值的函数称为发散函数( diverging functions) 。
语句和表达式
语句和表达式
fn add_with_extra(x: i32, y: i32) -> i32 {let x = x + 1; // 语句let y = y + 5; // 语句x + y // 表达式
}
函数式编程,以函数的最后一条表达式返回的结果作为函数的返回值。
表达式也可以是语句的一部分,如上面的 x + 1 和 y + 5 这些都是表达式,表达式返回的结果赋给了对应的变量。
而最后一条语句的表达式将结果返回给函数本身(即,函数返回值)。
除了函数外,在语句块中也可以将表达式结果返回:
let y = {let x = 3;x + 1
};println!("y = {}", y); // 4
注意事项:
let y = {let x = 3;x + 1; // 错误的,加了分号就变成了语句
};fn add_with_extra(x: i32, y: i32) -> i32 {let x = x + 1;let y = y + 5;x + y; // 错误的,加了分号就变成了语句
}
表达式需要注意的一点:如果需要表达式返回,则不允许加分号!
如果表达式不返回任何值,那么会隐式的返回一个
()。
三元表达式
let flag: bool = true;
let res = if flag { "真的" } else { "假的" };
println!("{}", res);
函数
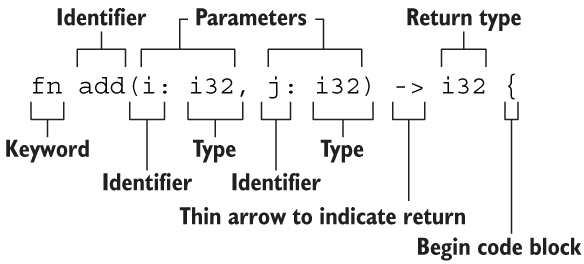
要点:
- 函数名和变量名使用蛇形命名法(snake case),例如
fn add_two() {} - 函数的位置可以随便放,Rust 不关心我们在哪里定义了函数,只要有定义即可
- 每个函数参数都需要标注类型
发散函数
当用 ! 作函数返回类型的时候,表示该函数永不返回( diverging functions ),特别的,这种语法往往用做会导致程序崩溃的函数:
fn dead_end() -> ! {panic!("你已经到了穷途末路,崩溃吧!");
}
下面的函数创建了一个无限循环,该循环永不跳出,因此函数也永不返回:
fn forever() -> ! {loop {//...};
}