Full cycle of a machine learning project|机器学习项目的完整周期
-----------------------------------------------------------------------------------------------
这是我在我的网站中截取的文章,有更多的文章欢迎来访问我自己的博客网站rn.berlinlian.cn,这里还有很多有关计算机的知识,欢迎进行留言或者来我的网站进行留言!!!
-----------------------------------------------------------------------------------------------
一、机器学习项目完整周期
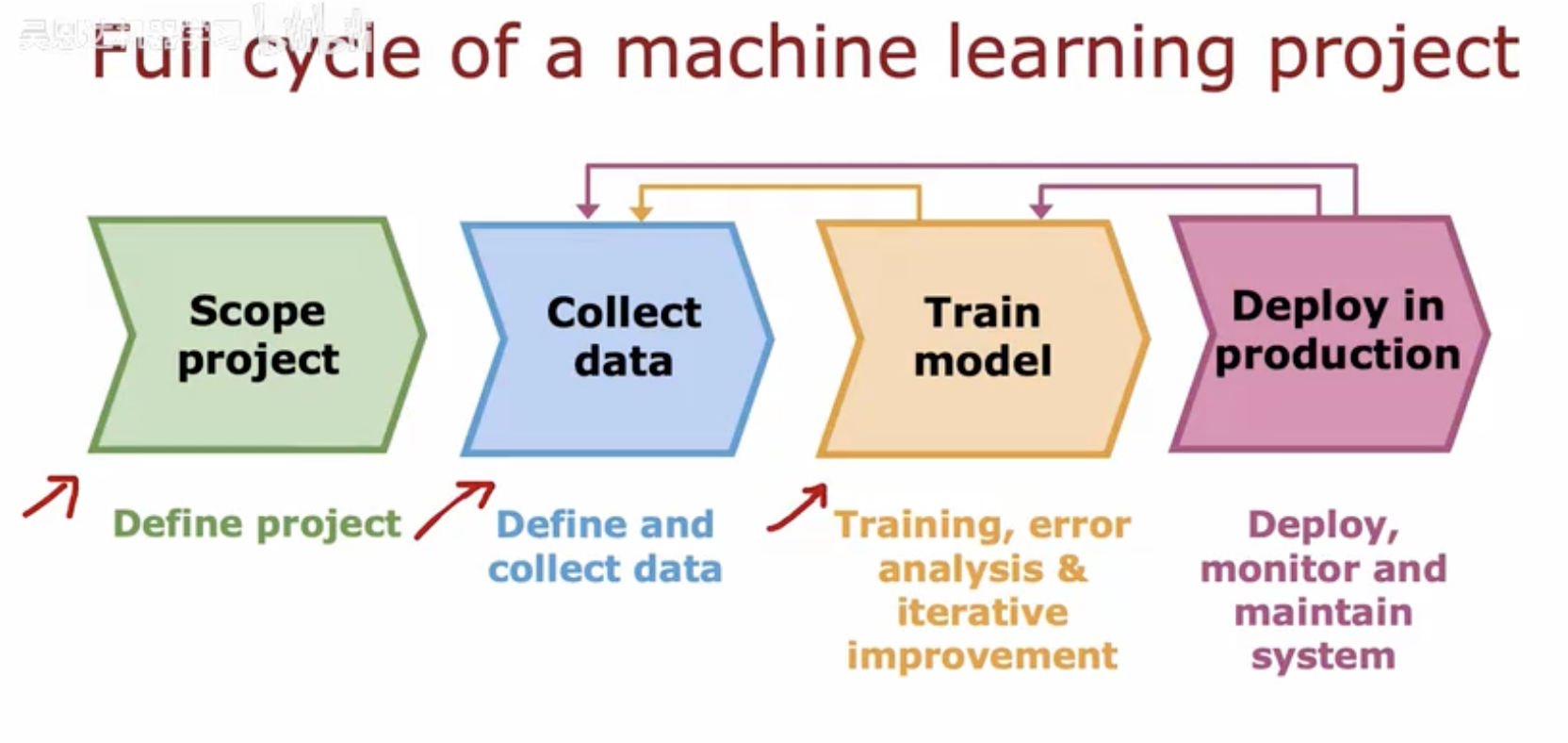
1. 定义项目(Scope project)
-
描述:这是项目的起始阶段,主要任务是定义项目的目标和范围。
-
箭头指向:从“定义项目”指向“收集数据”,表示在明确了项目目标和范围之后,下一步是收集数据。
2. 收集数据(Collect data)
-
描述:在这个阶段,需要定义所需的数据并进行收集,为模型训练做准备。
-
箭头指向:从“收集数据”指向“训练模型”,表示数据收集完成后,下一步是使用这些数据来训练模型。
-
反馈箭头:从“训练模型”指向“收集数据”,表示在模型训练过程中,可能需要返回到数据收集阶段,进行更多的数据收集或数据清洗,以改进模型。
3. 训练模型(Train model)
-
描述:此阶段包括模型的训练、错误分析以及迭代改进,以提高模型的性能。
-
箭头指向:从“训练模型”指向“部署到生产环境”,表示模型训练完成后,下一步是将模型部署到生产环境中。
-
反馈箭头:从“部署到生产环境”指向“训练模型”,表示在模型部署后,可能需要根据生产环境中的反馈进行模型的进一步训练和优化。
4. 部署到生产环境(Deploy in production)
-
描述:最后,将训练好的模型部署到生产环境中,并进行监控和维护,确保系统稳定运行。
-
反馈箭头:从“部署到生产环境”指向“定义项目”,表示在模型部署并运行一段时间后,可能需要根据实际运行情况重新审视项目的目标和范围,进行项目的重新规划或调整。
这些箭头展示了机器学习项目周期中的迭代和反馈机制,强调了在项目的不同阶段之间可能需要进行的循环和调整。
二、机器学习模型部署流程及MLOps关键任务
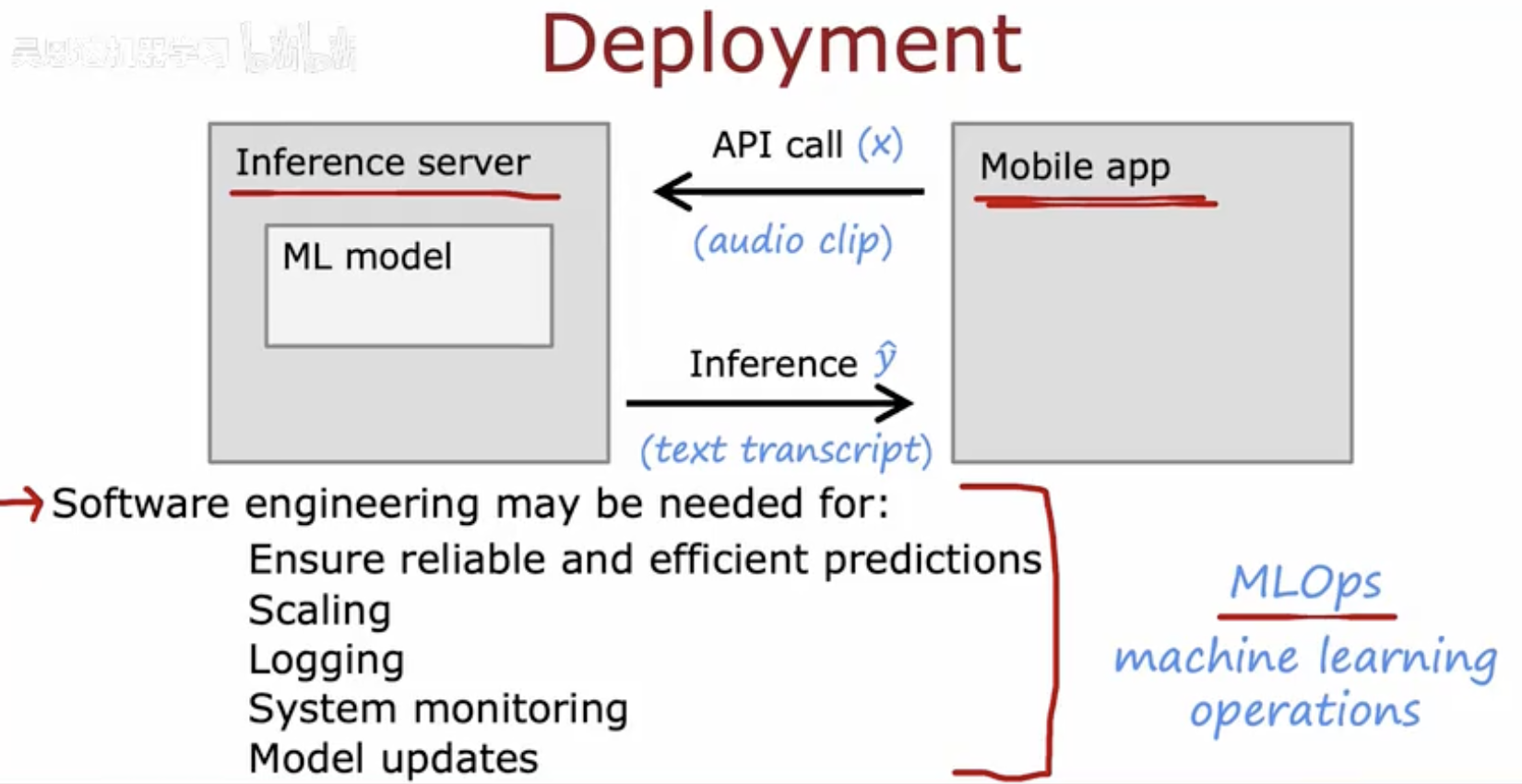
部署流程
-
推理服务器(Inference Server):
-
包含机器学习模型(ML model)。
-
负责处理来自移动应用的推理请求。
-
-
移动应用(Mobile App):
-
通过API调用与推理服务器交互。
-
发送音频剪辑(audio clip)到推理服务器。
-
-
API调用(API Call):
-
移动应用向推理服务器发送音频剪辑的API调用。
-
这是移动应用与推理服务器之间的通信接口。
-
-
推理(Inference):
-
推理服务器接收音频剪辑并进行处理。
-
生成文本转录(text transcript)并返回给移动应用。
-
软件工程需求
为了确保机器学习模型在生产环境中的可靠和高效运行,可能需要以下软件工程支持:
-
确保可靠和高效的预测:确保模型在实际应用中能够提供准确和快速的预测结果。
-
扩展性(Scaling):系统能够处理增加的负载,如更多的用户请求或更大的数据量。
-
日志记录(Logging):记录系统运行过程中的信息,以便进行问题诊断和性能分析。
-
系统监控(System monitoring):持续监控系统性能和健康状况,及时发现并解决问题。
-
模型更新(Model updates):定期更新模型以提高性能或适应新的数据分布。
这些软件工程需求通常由机器学习运维(MLOps)团队负责,以确保机器学习模型在生产环境中的稳定运行和持续优化。
三、总结
在机器学习项目中,从概念到部署的完整周期包括四个关键阶段:定义项目、收集数据、训练模型和部署到生产环境。每个阶段都是项目成功的关键,并且它们之间存在反馈循环,允许项目在必要时进行迭代和优化。
-
定义项目(Scope project):明确项目的目标和范围是第一步。这为整个项目设定了方向,并帮助团队集中精力在最重要的任务上。
-
收集数据(Collect data):数据是机器学习模型的基石。在这个阶段,团队需要定义所需的数据类型,并进行收集。数据的质量直接影响模型的性能,因此数据收集和清洗是至关重要的。
-
训练模型(Train model):使用收集到的数据训练模型,并进行错误分析和迭代改进。这个阶段的目标是优化模型,使其能够准确地执行预定任务。
-
部署到生产环境(Deploy in production):将训练好的模型部署到生产环境中,并进行监控和维护。这是模型从开发环境转移到实际应用的关键步骤。
在部署阶段,机器学习模型通常通过推理服务器与移动应用或其他客户端进行交互。推理服务器接收API调用,处理数据,并返回预测结果。为了确保模型的可靠性和效率,软件工程的支持是必不可少的,这包括确保预测的可靠性、系统的可扩展性、日志记录、系统监控和模型更新等任务。这些任务通常由MLOps(机器学习运维)团队负责,以确保模型在生产环境中的稳定运行和持续优化。
总结来说,机器学习项目的成功不仅依赖于模型的技术性能,还依赖于项目管理、数据处理、模型训练和生产部署等各个环节的协调和执行。通过迭代和反馈机制,项目团队能够不断改进模型,以满足实际应用的需求。
-----------------------------------------------------------------------------------------------
这是我在我的网站中截取的文章,有更多的文章欢迎来访问我自己的博客网站rn.berlinlian.cn,这里还有很多有关计算机的知识,欢迎进行留言或者来我的网站进行留言!!!
-----------------------------------------------------------------------------------------------