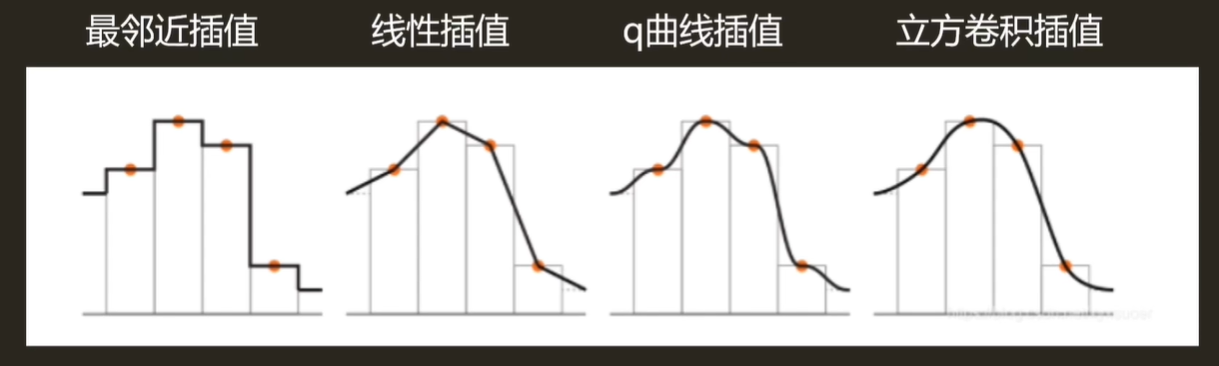
自由学习记录(92)
Unity Shader 的多 Pass 执行模型,
你不能像 C# 里那样“先算好存变量 → 后面 Pass 再直接访问”。
-
每个 Pass 都会重新跑一次顶点/片元着色器流程,渲染目标是你在
Pass里定义的ColorMask/Blend/RenderTarget。 -
Pass 与 Pass 之间 没有共享变量(比如你在前一个
frag里算出的worldPos),因为这些运行在 GPU 大量片元并行计算中,结果直接写到渲染目标纹理里,而不是存到某个“共享内存”。
所以你没法在第一个 Pass 的 frag 里 return 出来的 worldPos,然后在第二个 Pass 的 frag 里直接 访问。
不对,这不是这样的,这样也没有效果,重点是要让高出的像素知道自己是高出的
1. 纯后处理(简单)
-
每个像素都算世界坐标 → 拿它的
y值和雾的基准高度对比。 -
这样能实现“离地越高雾越淡,越贴近地面雾越浓”。
-
但是:这只能看单个像素的高度,不能知道旁边有没有山或峡谷,缺乏体积穿透感。
2. 屏幕空间 + Raymarch(高级)
-
不仅用深度对应的表面点,还在相机射线上做若干次步进采样,把沿途的高度场贡献累积起来。
-
这样可以得到更真实的“地形被雾淹没”的感觉。
-
成本是要在片元里做循环采样(性能更贵)。
为什么“像素之间不清楚彼此的高度”?
因为在 GPU 的片元阶段,每个像素的着色完全独立,没有“共享变量”或“邻居关系”。
想要知道“其他像素的值”,你必须:
-
写入一张纹理,再采样这张纹理(类似 GBuffer 的做法)。
-
或者在同一个片元里用数学公式近似整个雾的体积效果(比如指数高度雾解析解)。

实际上的坐标都是深度图计算出来的,而像素什么都没有,除了采样固定uv的地方,自己采样了
这就是。。。。


百人计划的纹理,前置
-
屏幕分辨率:100×100
→ 也就是说,最后你只能画 10000 个像素。 -
纹理大小:2048×2048
→ 非常细。每个屏幕像素要从一大张图里找一个位置采样颜色。 -
问题:当屏幕上的相邻像素,映射到纹理的坐标差很大时(比如差 20 多个纹理像素),就会出现 “同一屏幕像素群,采样到的纹理像素差别极大”。
颜色丢失与闪烁的原因
-
颜色丢失 (loss of detail):
因为屏幕像素远比纹理像素少,很多纹理细节根本没机会显示出来。
→ 就像把一张精细的花纹压缩成很小的格子,会丢掉纹理里的线条。 -
闪烁 (flickering / aliasing):
当你移动相机或模型时,每一帧屏幕像素映射到的纹理坐标会发生细微变化。-
这时可能上一帧采样到 纹理像素 A,下一帧就跳到差 20 多像素远的 纹理像素 B。
-
屏幕像素的颜色就会在不同的帧之间跳来跳去。
-
人眼看起来就是“闪烁”、“抖动”或“摩尔纹”。
-
👉 本质:这是采样不稳定的问题,因为取样间隔大于纹理的细节频率,违反了采样定理 → 产生混叠(aliasing)。
解决办法(纹理过滤)
-
双线性插值 (bilinear interpolation):
让采样点在周围 4 个像素之间插值,不再“跳”。能缓解但不能根治缩小闪烁。 -
三线性插值 (trilinear):
在不同 mipmap 层之间也做插值。 -
mipmap:
预先生成多级低分辨率纹理(1024×1024,512×512 …)。
当屏幕像素对应纹理跨度很大时,直接用低一级 mipmap,而不是在大图里跳点采样。 -
各向异性过滤 (anisotropic filtering):
针对倾斜表面(比如地板),能减少“远处地板花纹闪烁”的问题。
studio_video_1615777340934_哔哩哔哩_bilibili

When filtering is turned on, the textures are modified to match the player’s viewing angle, creating a more defined vanishing point and a crisper appearance for objects farther from the “camera.” Unlike older filtering techniques, which treat textures as if they are perpendicular to the camera, anisotropic filtering modifies the textures to account for perspective.
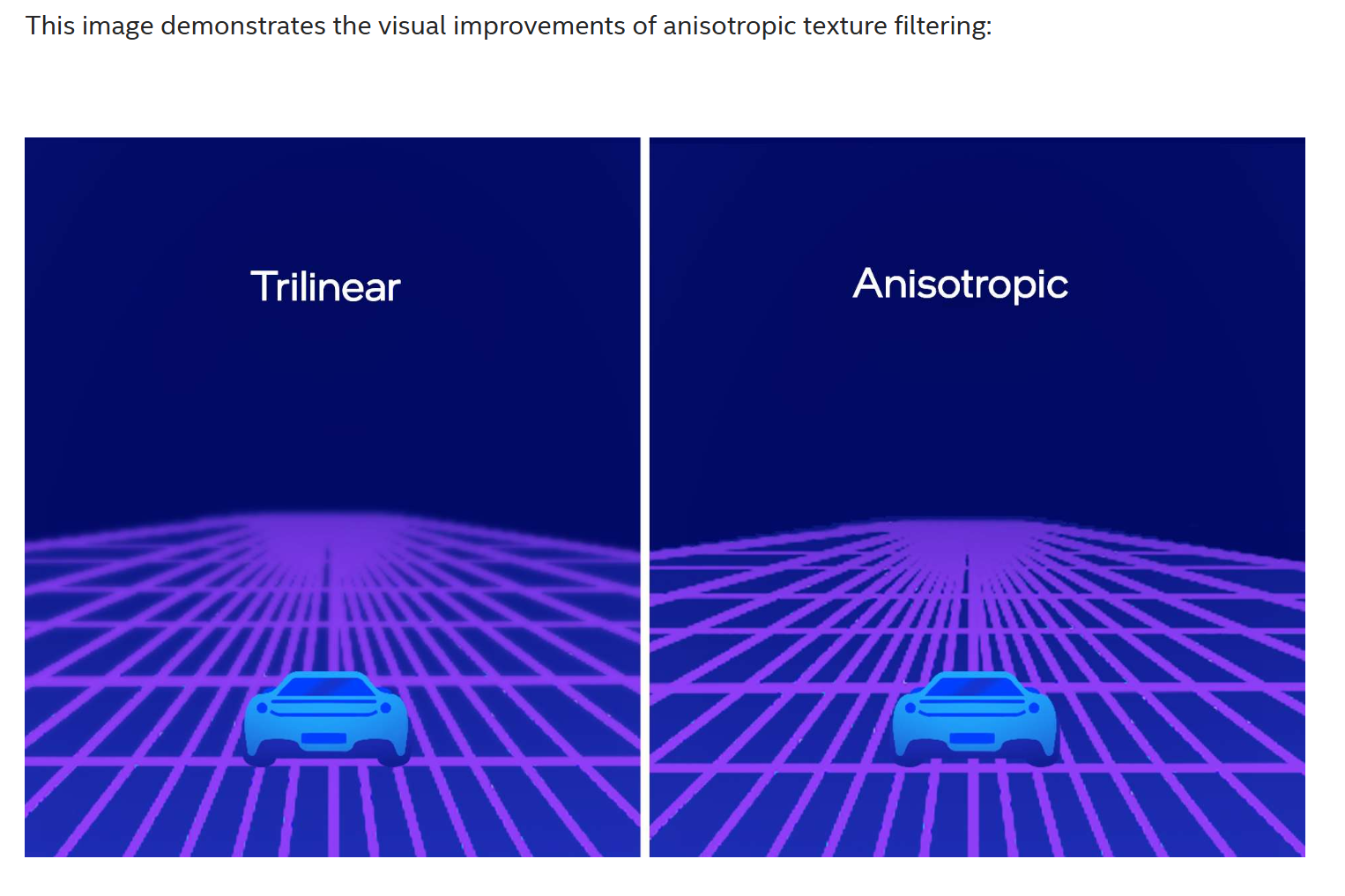
The benefits of texture filtering are even more apparent when the player is in motion. Without filtering, obvious “bands” in quality appear on the ground as closer textures transition to farther textures. With filtering, textures appear smoother and the lines are more subtle.
What Anisotropic Filtering Setting Should You Use?
How Does Anisotropic Filtering Differ from Bilinear and Trilinear Filtering?
Both bilinear and trilinear filtering are isotropic (or “uniform in orientation”) filtering techniques that assume texels are square within the rendered space. Anisotropic filtering allows different values on different axes, rather than uniform values.
That means it allows for non-square applications of textures, such as in rectangular or trapezoidal shapes, with more lifelike results for textures viewed at steep angles.
Using bilinear or trilinear filtering can result in a blurrier image than anisotropic filtering. If your PC is struggling with x16 anisotropic filtering, it’s worth trying out lower values like x4 before falling back on the earlier forms of filtering.
anisotropic filtering (AF) shows its advantage when a texture is at an oblique angle to the camera (e.g., a ground plane receding into the distance). Bilinear and trilinear can still render the texture, but the math behind which texels get sampled is different
-
双线性过滤(Bilinear)
-
只在单一 mip 层级上取样。
-
取周围 2×2 共 4 个 texel 做插值。
-
假设屏幕像素在纹理空间里的“覆盖区域”是一个正方形。
-
结果:正面看贴图效果还行,但斜着看时会把很多细节糊成一团 → 模糊。
-
-
三线性过滤(Trilinear)
-
在 两个相邻的 mip 层级上各自做一次双线性,再插值。
-
消除了“mipmap 层级切换的硬线条”。
-
但是 footprint(像素在纹理空间的投影区域)仍然被当成正方形。
-
结果:斜角时依然模糊。
-
-
各向异性过滤(Anisotropic)
-
先计算像素在纹理空间的真实 footprint(透视变换后往往是拉长的椭圆)。
-
在这个椭圆的长轴方向上进行更多采样(可达 4x、8x、16x)。
-
这样就能保留远处地面、道路、地砖这类“斜着延伸”表面的清晰细节。
-
差别发生在哪里?
-
在代码里:
-
Shader 里调用
tex2D()/Texture.Sample()时,并没有写不同的函数。 -
真正的差别在于 SamplerState / 采样器设置:
-
bilinear/trilinear → GPU 取 4 或 8 个 texel。
-
anisotropic → GPU 取更多 texel,并按长轴方向分布。
-
-
-
在硬件里:
-
GPU 的纹理单元(texture unit)有不同的过滤电路,按照 sampler state 来决定采样模式。
-
为什么双线性/三线性也能“显示”斜角纹理?
-
它们当然能显示,但因为始终当 footprint 是正方形,所以在斜角情况下,纵向细节会被平均掉 → 看起来糊。
-
各向异性过滤的优势就是:用椭圆形 footprint 取样,避免了这种模糊。
「椭圆形采样」指的就是 各向异性过滤(AF)在数学上对像素 footprint 的近似
什么是 footprint?
当一个屏幕像素对应到纹理空间时,它不是一个点,而是一个小区域(因为屏幕像素覆盖了模型上一小块表面)。
-
如果表面正对相机,投影到纹理空间就是一个 近似正方形。
-
如果表面斜着延伸(比如地板远处),投影会被透视拉长 → 长条状/椭圆形区域。
双/三线性过滤的假设
-
它们都假设这个 footprint 是 正方形。
-
所以只取正方形范围内的 4 个 texel(或两个 mip 层的 8 个)。
-
当实际 footprint 被拉长时,它们的采样分布无法覆盖长方向 → 把多个细节平均成模糊。
为什么要确认 footprint 形状?
一个屏幕像素在纹理空间对应的区域称为 pixel footprint。
显卡需要知道这个 footprint 的大小和形状,才能决定用哪个 mipmap 层、取多少 texel。
Footprint 是如何计算出来的
关键在于:屏幕坐标 → 纹理坐标的导数。
在像素着色时,GPU 已知每个片段的 (u, v) 纹理坐标。
它会计算相邻像素之间的变化率:

从导数到椭圆
这个矩阵 JJJ 把屏幕上的一个小方块(像素区域)映射到纹理空间。
-
如果纹理正对相机,变换结果接近正方形。
-
如果纹理倾斜,结果就是一个被拉伸/旋转的平行四边形。
显卡会近似把这个平行四边形当作一个 椭圆:
-
椭圆的 长轴和短轴方向 来自于矩阵 JJJ 的特征向量。
-
椭圆的 长短轴长度 来自于矩阵 JJJ 的奇异值(singular values)。
这就是所谓的 elliptical footprint (EWA filtering, Elliptical Weighted Average)。
各种过滤方式的区别就在这里
-
Bilinear / Trilinear:
-
忽略方向性,把 footprint 近似成一个正方形。
-
用 footprint 的“最大边长”来决定 mipmap 级别。
-
-
Anisotropic Filtering:
-
考虑椭圆的长轴方向。
-
在长轴方向上分段采样(多次 texel fetch)。
-
这样能覆盖更多细节,而不是直接模糊掉。
-

这表示:屏幕上往 x 方向走 1 个像素时,UV 会增加 (0.2, 0.05);往 y 方向走 1 个像素时,UV 会增加 (0.0, 0.1)。
2. 投影到纹理空间的形状
-
如果用 (Δx, Δy) = (1,0),得到 ΔUV = (0.2, 0.05)。
-
如果用 (Δx, Δy) = (0,1),得到 ΔUV = (0.0, 0.1)。
这两个向量在 UV 空间生成了一个平行四边形。
-
它的一条边长 ≈ √(0.2²+0.05²) = 0.206
-
另一条边长 = 0.1
显然长短比例 ≈ 2:1,不是正方形,而是拉长的形状。
3. 转换成椭圆近似
GPU 会取 Jacobian 的特征值(等价于奇异值),得到 footprint 的主方向和长短轴:
-
长轴方向 ≈ 向量 (0.2, 0.05)(沿着 U 为主)。
-
长轴长度 ≈ 0.206
-
短轴方向 ≈ 接近 V 方向。
-
短轴长度 ≈ 0.1
于是,屏幕上这一个像素对应纹理空间里 椭圆状的区域,长宽比大约 2:1。
-
Bilinear:忽略方向性,把 footprint 当正方形 → 用 0.206 来决定 mipmap。结果:在 V 方向上取样不足 → 细节丢失。
-
Trilinear:多做一次 mip 插值,但 footprint 还是当正方形 → 斜角仍模糊。
-
Anisotropic:意识到长宽比 ≈ 2:1 → 沿长轴方向多取样点,比如取 4 次 → 能覆盖椭圆区域,保留更多细节。
有点味道了
-
Energy Conservation能量守恒
-
在 x 方向上屏幕像素前进 1 格,纹理坐标增加 (0.2, 0.05)。
👉 意味着:像素沿屏幕横向推进时,纹理坐标既往 U 方向多走一点,也顺带往 V 方向偏一点。 -
在 y 方向上屏幕像素前进 1 格,纹理坐标只增加 (0.0, 0.1)。
👉 意味着:像素沿屏幕竖向推进时,纹理坐标主要就是往 V 方向走。
于是,你能直观地看到:屏幕上的小正方形像素,在纹理空间里被“拉伸、扭斜”成一个平行四边形。
这就是 GPU 所说的 footprint:一个屏幕像素投影到纹理里的真实覆盖范围。
过滤算法的差别,不在于能不能渲染出结果,而在于它对这个“footprint”的形状有没有认真对待。
-
Bilinear/Trilinear:假装 footprint 永远是正方形。
-
Anisotropic:真的去看 footprint 的长宽比例,然后在长方向上加采样。
-
双线性 / 三线性:
它们确实就是在用一个简单近似来处理 footprint,把真实的平行四边形/椭圆直接当成“正方形”。-
算法上更便宜,计算开销低。
-
代价是:斜角处,采样覆盖不够 → 细节模糊、摩尔纹。
-
换句话说,它们是“能用就行”的近似。
-
各向异性过滤:
它真正把 Jacobian(导数矩阵)计算出来,考虑长短轴的差异。-
方向性被保留。
-
取样点分布更合理。
-
代价是:采样次数更多,显存带宽压力大。
-
这就是为什么 AF 能在视觉上“救活”远处的地面砖缝、柏油路纹理,而 bilinear/trilinear 只能糊成一片。
滤波算法的分界点不是“能不能显示”,而是“是否尊重了 footprint 的真实形状”。
-
bilinear/trilinear → 不尊重,直接近似为正方形。
-
anisotropic → 尊重,用椭圆/长轴方向来分配采样。
积分图(Summed-Area Table, SAT),其实是纹理过滤里另一条“更严谨”的路线,和各向异性过滤(AF)有点异曲同工。

因为有了这个预积分表,你可以在 O(1) 时间 得到任意矩形区域的均值:
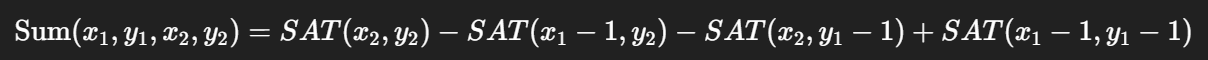
这样一来,你就能随时对任意形状的 footprint(至少是矩形近似)做平均,而不用每次重新去采样一堆 texel。
和传统过滤的关系
-
Bilinear/Trilinear:只做 4 次或 8 次采样,近似平均。
-
各向异性过滤:在长轴方向上做多次采样,近似椭圆平均。
-
积分图:直接能在常数时间里得到任意矩形区域的平均值,理论上更“完美”。
如果能在 GPU 硬件中支持 SAT,就可以对 footprint 做更精准的过滤,而不是依赖那么多的采样点。
实际应用
-
计算机视觉:积分图常用来快速做局部均值/方差计算(比如 Haar 特征检测)。
-
图形学:研究过用 SAT 来替代各向异性过滤(叫做 Summed-Area Table Filtering)。
-
优点:采样结果更准确。
-
缺点:存储开销太大(每个像素要存储累积和 → 精度要求高 → 显存爆炸)。
-
所以主流 GPU 没有采用 SAT,而是走了 AF 的近似方案。
-
积分图 (SAT):用预积分让任意区域均值计算变成 O(1)。
在纹理过滤中,它是 比各向异性更“数学严谨” 的方案,但太耗存储,不现实。
-
因此:
-
实际硬件里 → 用 AF(椭圆采样近似)。
-
离线渲染或研究里 → 可以用 SAT 追求高精度。
-
积分图 (Summed-Area Table, SAT) 的逻辑用更直观的例子解释一下。
普通情况下怎么求区域和?
假设你有一张 5×5 的图片,每个格子里都是一个数。
如果我问你:从 (1,1) 到 (3,3) 这个小方块里所有数加起来是多少?
-
普通方法:要一个个去加,9 个数字都算一遍 → O(n²) 时间。
A gentleman gets along with others, but does not necessarily agree with them
君子和而不同 Gentlemen seek harmony but not uniformity.
和则两利 Reconciliation benefits both.
不懂(0,0) 到 (x,y) 这个矩形里所有数的总和。我就专门针对你卡住的这句话来解释:

积分图 (Summed-Area Table, SAT) 的定义
SAT 的每个位置 (x,y) 存的不是原始像素,而是从左上角 (0,0) 到 (x,y) 之间的所有值的和。
比如:
-
SAT(0,0)= I(0,0) = 1 -
SAT(1,0)= I(0,0) + I(1,0) = 1 + 2 = 3 -
SAT(2,0)= I(0,0)+I(1,0)+I(2,0) = 1+2+3=6 -
SAT(1,1)= I(0,0)+I(1,0)+I(0,1)+I(1,1) = 1+2+4+5 = 12
这样往下填,就得到了 SAT 表。
为什么这样做?
因为如果你要算一个矩形区域的和,比如 (1,1) 到 (2,2):

那这个sat表每帧都要得到新的,也很费时间啊,只是相比每个像素都都自己nxn,运算的时间更短了
SAT 的代价是前置的构建时间,换来的好处是后续查询非常快。
构建开销
-
生成 SAT 的时候,确实要遍历整张图像,每个点累积前面的和。
-
时间复杂度 = O(W×H)(图像的宽×高)。
-
如果图像是动态的,每帧都重新生成 SAT → 会非常昂贵。
所以 SAT 更适合:
-
静态纹理(离线计算一次,存下来)。
-
半实时场景(比如光照、阴影的预计算)。
图形学中的取舍
-
实时渲染 (游戏、Unity/UE4)
-
基本不会用 SAT 来做纹理过滤,因为:
-
每帧生成 SAT 太贵。
-
显存消耗大。
-
硬件已有更高效的 AF 专用单元。
-
-
-
离线渲染 / 图像处理
-
SAT 非常有用(比如模糊、积分卷积、特征检测)。
-
因为能一次构建,多次使用,均值计算几乎不要成本。
-
studio_video_1615777340934_哔哩哔哩_bilibili
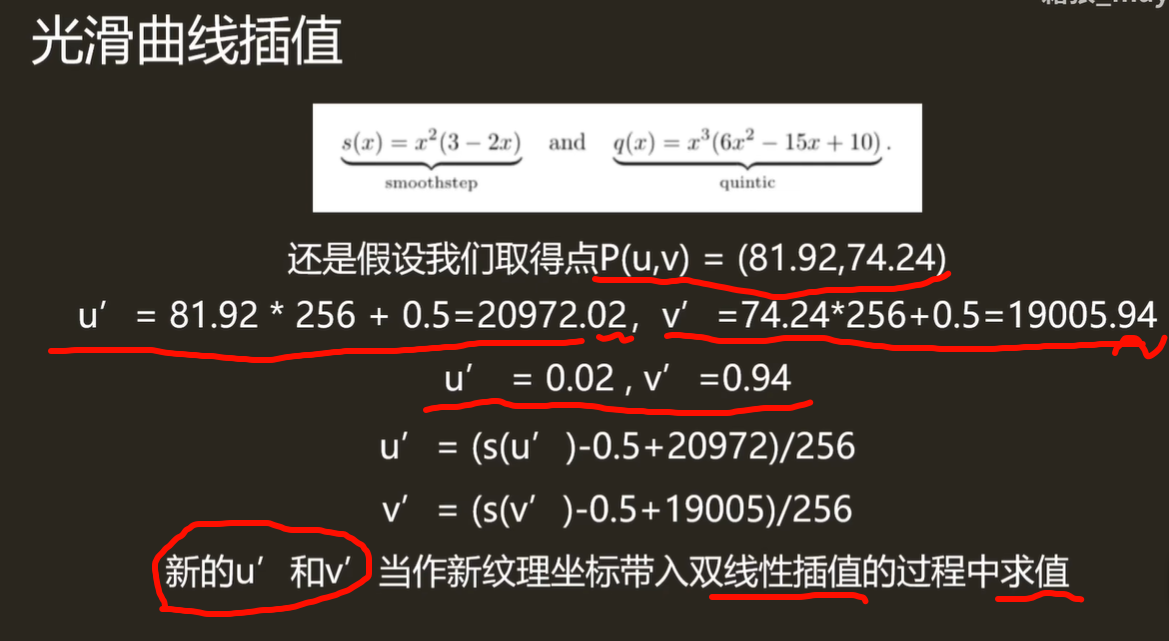

为什么要 +0.5
像素索引通常表示的是 像素左上角的位置,但实际采样更合理的是对准 像素中心。
-
像素 0 实际覆盖范围是 [0,1)。
-
这个像素的中心在 0.5。
所以我们要在转换时加 0.5,让采样点落在像素中心。


. W 和 H 从哪里来?
-
它们不是虚空来的,而是指“某一层纹理的分辨率”。
-
如果你在操作一张 256×256 的 mipmap 层,就有 W=256,H=256W=256, H=256W=256,H=256。
-
如果是 1024×512 的贴图,那就是 W=1024,H=512W=1024, H=512W=1024,H=512。
所以 W、H 是根据你正在采样的那张贴图的尺寸决定的。
什么时候用哪种?
-
引擎里大部分 API(Unity、UE、GLSL/HLSL 的
tex2D等)用的都是 归一化 uv,因为这样和具体分辨率无关。 -
教材推导 / 硬件内部计算 时,常常换算到 像素坐标系,方便直接讨论“整数索引 + 小数部分”这种事情。
原始像素坐标系里的 u,vu,vu,v
-
例子里一开始给的是 u=81.92,v=74.24u=81.92, v=74.24u=81.92,v=74.24。
-
它的含义是:在“像素索引”坐标系里,落在第 81 到 82 列之间(偏 0.92),第 74 到 75 行之间(偏 0.24)。
-
小数部分 (0.92, 0.24) 就是插值时的权重。
“新小数部分”和“旧小数部分”
-
在原始像素坐标里,小数是 0.92, 0.24。
-
映射到另一层(256 纹理分辨率)之后,小数又变成了 0.02, 0.94。
这两个小数部分数值不同,但逻辑上等价:
-
它们都表示“在某个 texel 内部偏移多少”。
-
差别只是:一个是粗分辨率的格子(原始坐标系),一个是细分辨率的格子(256 尺寸下)。
为什么会变
原因是你换了 坐标系的刻度。
-
在原始系统里,一个格子宽度 = 1。
所以 0.920.920.92 表示“在这个 1 宽的格子里,走了 92%”。 -
乘以 256 后,一个格子宽度还是 1,但你已经把整个坐标轴拉伸了 256 倍。
所以原本 0.92 的位置,被重新投射到更细的格子系统里,就会落到另一个小数值(这里是 0.02)。
它们数值不同,但都在描述“相对格子内部的位置”。
想象一根尺子:
-
用 厘米刻度量,一个点在 81.92 cm → 小数部分 0.92 cm。
-
把尺子换成 毫米刻度,同一个点是 819.2 mm → 小数部分 0.2 mm。
虽然小数部分不一样,但它们都准确地表达了“点在某个格子里的相对偏移”。
unity中每张图都可以选择是否使用各向异性过滤采样,还是说这个是整体的设置
贴图级别(每张图单独设置)
-
Texture Import Settings 面板里有一项 Aniso Level(范围 1~16):
-
1表示禁用各向异性过滤(只用双/三线性)。 -
2~16表示启用 AF,数值越大,采样越锐利,代价是显存带宽开销更大。
-
-
这个设置是 存储在贴图资源上的,因此每张纹理都可以单独决定是否启用 AF,以及用多少级。
👉 所以,比如地面砖块纹理你可以开 AF=8,而 UI 图标这种正对相机的,就没必要开。
全局级别(Quality Settings 控制上限)
-
Unity 的 Edit → Project Settings → Quality 里有一个 Anisotropic Textures 设置:
-
Disable:完全禁用 AF,不管贴图上怎么设。
-
Enable:允许 AF,但具体等级由贴图的 Import Settings 决定。
-
Force On:强制所有纹理都用 AF(按各自的 Aniso Level)。
-
也就是说,全局设置是一个“硬阀门”,贴图上的设置是“具体数值”。
Shader 里的使用方式
你在 HLSL/ShaderLab 里写 sampler2D,真正的采样模式(双/三线性 vs 各向异性)由 SamplerState 决定,而 Unity 会根据 Import Settings + Quality Settings 自动生成合适的 sampler。
总结:
-
每张图都可以独立选择(通过 Import Settings 的 Aniso Level)。
-
全局设置可以禁止或强制,起到总开关作用。
https://www.intel.com/content/www/us/en/gaming/resources/what-is-anisotropic-filtering.html
How Do You Enable Anisotropic Filtering?如何启用各向异性过滤?
Most modern games allow anisotropic filtering out of the box. You can find it in the graphics settings menu under “Anisotropic Texture Filtering,” “Texture Filtering,” or “AF,” then set to a preferred value (like x8 or x16).大多数现代游戏默认开启各向异性过滤。您可以在图形设置菜单中找到它,通常在“各向异性纹理过滤”、“纹理过滤”或“AF”选项下,然后将其设置为首选值(如x8或x16)。
To improve the look of older games that don’t offer texture filtering in the settings menu, you can often apply texture filtering through your graphics card’s software. Try opening the 3D settings within the control panel of your graphics card software, then create a profile for the game you’re playing and enable anisotropic filtering within that.为了改善那些在设置菜单中不提供纹理过滤功能的旧游戏的视觉效果,您通常可以通过显卡的软件应用纹理过滤。尝试在显卡软件的控制面板中打开3D设置,然后为您正在玩的游戏创建一个配置文件,并在其中启用各向异性过滤。
When to Use Anisotropic Filtering何时使用各向异性过滤
Anisotropic filtering can have a significant visual impact for a relatively small performance hit, especially compared to options like texture or shadow quality.各向异性过滤可以在相对较小的性能损失下产生显著视觉效果,尤其是与纹理或阴影质量等选项相比。
However, both the visual benefits of anisotropic filtering and its impact on FPS vary greatly with different games and different PCs. It’s always worth testing out different values, such as x4 or x8, to see what works best with your system.然而,各向异性过滤的视觉效果及其对帧率的影响在不同游戏和不同电脑上差异很大。始终值得一试不同的值,例如x4或x8,看看哪个最适合您的系统。
Upgrading your GPU is a great way to unlock new levels of graphical fidelity in your favorite games. If you’re struggling to run anisotropic filtering at your preferred settings, consider upgrading to a system with an Intel® Arc™ GPU. Using Intel® Deep Link technology, Intel® GPUs and CPUs work together to boost gaming performance, battery life, and content creation. Read more here.升级您的GPU是提升您喜爱的游戏图形品质的绝佳方法。如果您在以偏好设置运行各向异性过滤时遇到困难,考虑升级到配备英特尔® 雷神™ GPU的系统。利用英特尔® 深度链接技术,英特尔® GPU和CPU协同工作,提升游戏性能、电池寿命和内容创作。了解更多信息请点击此处。
Inigo Quilez :: computer graphics, mathematics, shaders, fractals, demoscene and more
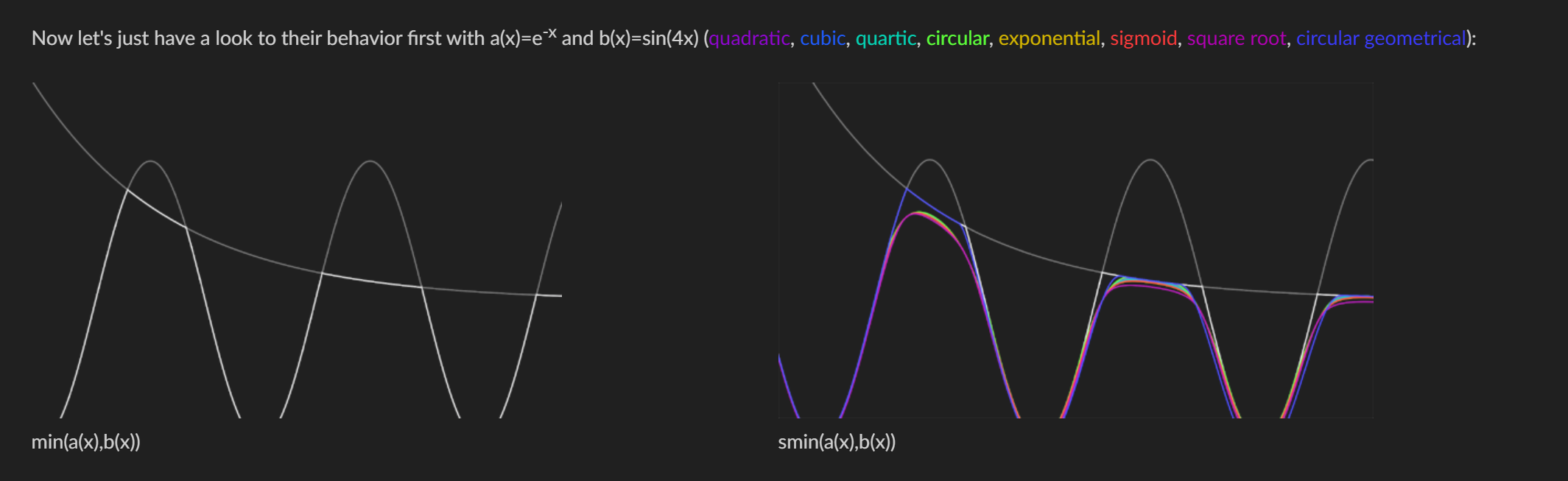
把“Quílez 光滑曲线”系统地落到两条主线上:
一维的平滑整形(smoothstep 系列)
SDF 的光滑布尔/光滑最小值(smin/smax)
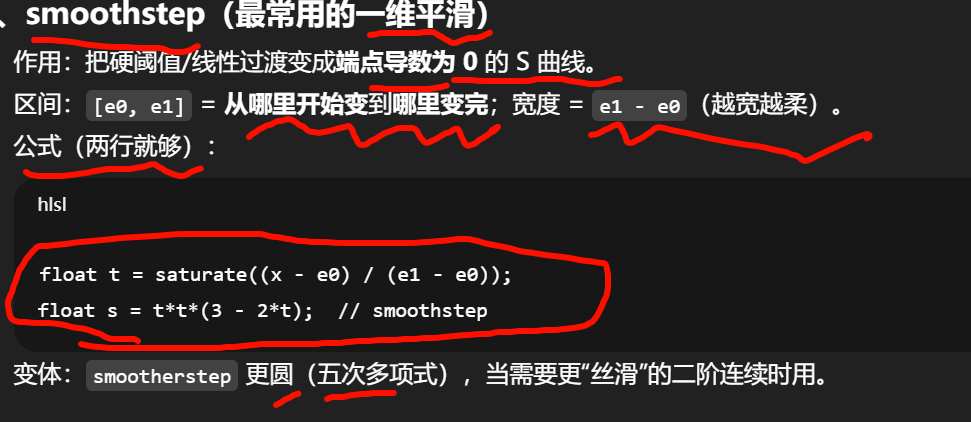
一维平滑整形:smoothstep / smootherstep / inverse
目标:把 [0,1] 上的线性变化换成端点导数为 0 的 S 曲线,避免“硬折 / 接缝”。

If there is no scattering and the absorption is low, rays can pass directly through the surface. This is the case with glass. For example, imagine you are swimming in a clean pool. You can open your eyes and see a great distance through the clear water. However, if that same pool is relatively dirty, the dirt particles will scatter the light and lower the clarity of the water, and the distance you can see will be reduced as a result.如果没有散射且吸收较低,光线可以直接穿过表面。玻璃就是这样。例如,想象你在干净的游泳池里游泳。你可以睁开眼睛,透过清澈的水看到很远的距离。然而,如果同样的游泳池相对较脏,污垢颗粒会散射光线并降低水的清晰度,因此你能看到的距离会相应减少。
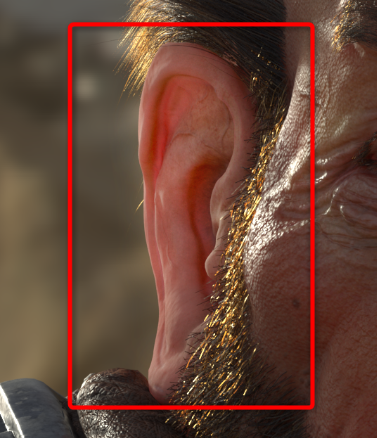
When light is scattered, the ray direction changes randomly, and the amount of deviation depends on the material. Scattering randomizes light direction, but doesn’t change its intensity. An ear is a good example of this phenomenon. The ear is thin (absorption is low), so you can see the scattered light radiating from the back of the ear, as shown in Figure 02.当光线被散射时,光线方向会随机改变,偏移量取决于材料。散射会使光线方向随机化,但不会改变其强度。耳朵就是一个很好的例子。耳朵很薄(吸收率低),因此你可以看到从耳朵后面辐射出的散射光,如图02所示。
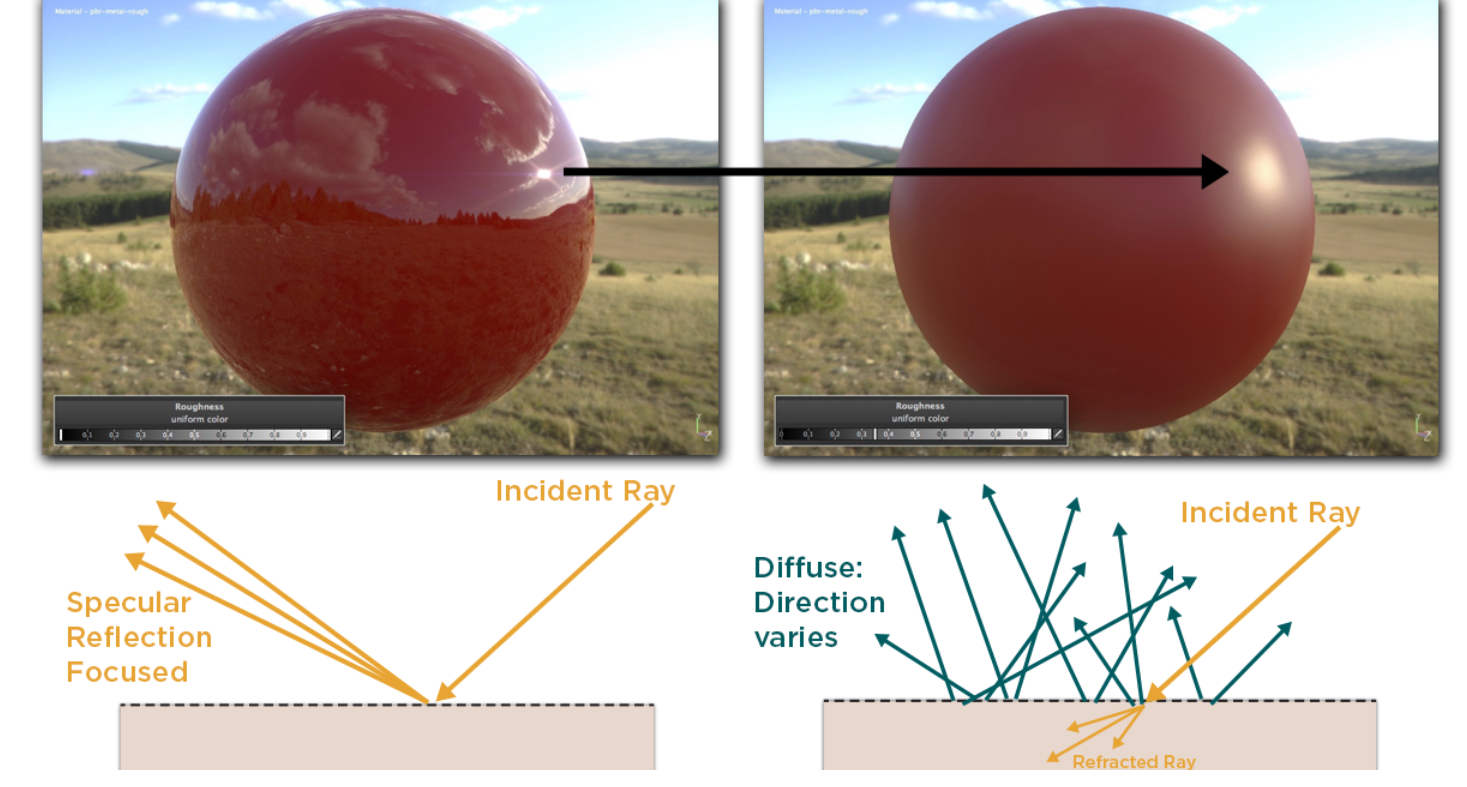
Rougher surfaces will have highlights that are larger, and that appear dimmer. Smoother surfaces will keep specular reflections focused, and they will appear to look brighter or more intense when viewed from the proper angle. However, the same total amount of light is reflected in both cases (Figure 04)表面越粗糙,高光区域就越大,看起来也更暗淡。表面越光滑,镜面反射就会更集中,从适当的角度看,它们会显得更亮或更强烈。然而,这两种情况下反射的光总量是相同的(图04)
Refraction is a change in a light ray’s direction. When light moves from one medium to another it changes speed and direction. The index of refraction, or IOR, is an optical measurement that describes the change in the direction a light ray is traveling. Essentially, the IOR value is used to determine how much the ray will be bent when it passes through one medium to another. For example, water has an IOR of 1.33, whereas plate glass has an IOR of 1.52. In figure 05 you can see a rendering of a straw placed in a glass of water. The straw appears bent due to refraction as the light travels through different mediums (air, water and glass).折射是光束方向的变化。当光从一种介质移动到另一种介质时,它会改变速度和方向。折射率,或称IOR,是一种光学测量,描述了光束行进方向的变化。本质上,折射率值用于确定光束穿过一种介质到另一种介质时弯曲的程度。例如,水的折射率为1.33,而平板玻璃的折射率为1.52。在图05中,您可以看到一个放在水杯中的吸管的渲染效果。吸管看起来是弯曲的,因为光在通过不同的介质(空气、水和玻璃)时发生了折射。

smoothstep 里的 [e0, e1] 是什么
-
e0:过渡 开始 的位置(输入 ≤ e0 → 输出固定为 0)。
-
e1:过渡 结束 的位置(输入 ≥ e1 → 输出固定为 1)。
-
(e1 − e0):过渡的“软边宽度”(羽化宽度、feather)。
中间 e0<x<e1e0<x<e1e0<x<e1 的那一段,用一条 S 曲线从 0 平滑升到 1。
一句话:[e0, e1] 就是把哪一段 “线性区间” 变成光滑过渡段;段外直接钳到 0 或 1。
inverse smoothstep(可选记)
-
用途:把已经 smoothstep 过的值反解回线性
t(做反查/匹配阈值有用)。 -
不常用就先不背,知道“有这个工具”即可。
SDF 的光滑布尔(smin/smax)
-
场景:SDF 里做软并/软交/软差,让两个形体平滑融合,而不是硬边。
-
最实用的
smin(多项式版本,快、好调):
float smin_poly(float a, float b, float k) {float h = clamp(0.5 + 0.5*(b - a)/k, 0.0, 1.0);return lerp(b, a, h) - k*h*(1.0 - h);
}-
-
a,b是两个 SDF,k>0是融合带宽(世界单位,越大越“融化”)。 -
smax(a,b,k) = -smin(-a,-b,k);交集/差集可据此组合。
-
-
重要性质:多项式
smin会低估距离(最坏误差 ≈k/4);做 sphere tracing 时把步长略收敛一点更稳(比如减去k*0.25或乘个 <1 系数)。
怎么选哪个?
-
做阈值、淡入淡出、软边缘 →
smoothstep(或smootherstep)。 -
做几何融合(SDF) →
smin(多项式优先;需要“顺序无关/更圆”再考虑指数型 log-sum-exp 版本)
最容易踩的坑
-
忘记
saturate/clamp,导致区间外产生怪值。 -
羽化宽度太窄,看起来仍像硬边、会抖。
-
把 smoothstep 当抗锯齿/模糊用(它只是一维整形)。
-
SDF
smin的k与场景单位不一致;或做了非均匀缩放却没在同一空间里融合。 -
Ray marching 时没考虑
smin的距离低估,步进不稳。
两句口令(背下就能用)
-
“先归一,再 S”:
t = saturate((x-e0)/(e1-e0)); s = t*t*(3-2*t); -
“SDF 融合用 smin,带宽用 k 控”;记住最坏误差 ≈ k/4,步长要保守一点。
-
构图/配色灵感
-
AI 可以快速生成不同的构图和配色方案。
-
比如 Stable Diffusion、MidJourney 可以输入“落日下的森林小屋,紫色光影”,瞬间给你十几种可能。
-
你不需要完全照搬,但能快速获取“灵感参考”,减少最初白纸阶段的困惑。
-
-
解剖/透视/光影演示
-
有一些画师把 AI 当作“动态模特”。输入提示即可生成不同角度的人体、场景,避免自己苦苦翻参考书。
-
还可以用 ControlNet(Stable Diffusion 的扩展)对草图/透视线做引导,让 AI 自动渲染出“符合透视关系的精细图”。
-
-
风格迁移与模仿
-
你可以输入“模仿某某画师风格”的提示,把普通素描渲染成印象派、厚涂、赛博风格等。
-
这样你能快速“感受”不同风格,而不是单纯靠猜。
-
创作与执行阶段的帮助
-
AI 辅助打底
-
很多画师现在的流程是:自己快速画草图 → 丢给 AI 上色/加材质 → 再回到 Photoshop/Procreate 做细化。
-
这样能省去大量“机械劳动”,把精力放在创意和画面把握上。
-
-
分层生成
-
用 AI 生成背景,再单独画人物。或者反过来,先画人物,再用 AI 补背景。
-
例如很多概念设计师会在 Blender/3D 软件里搭简单模型 → 渲染灰模 → 丢给 AI 做材质/气氛 → 自己精修。
-
-
修图与细化
-
画师常用 AI 修补结构,比如手指不对劲 → 扣出区域 → AI 局部重绘(inpainting)。
-
Stable Diffusion、Firefly、Runway 都能做很自然的修补。
-
后期与提升阶段的帮助
-
快速迭代
-
你可以用 AI 把一张图生成不同变体(颜色、构图、氛围),快速挑选最满意的方向,再精修。
-
-
学习反推
-
有些画师会输入别人的成品 → AI 生成相似图 → 对比提示词/AI 的理解,来分析别人画面的构成规律。
-
-
作品集与展示
-
AI 可以帮你快速生成“配图系列”,比如你只完成了 3 张插画,AI 可以在同风格下扩展出更多草图,丰富作品集的“量”,然后你再挑其中最合适的去精修。
-
当前一些画师的实际用法
-
概念设计师:常用 Blender 搭模型,Stable Diffusion 加材质,最后在 Photoshop 修光影。
-
插画师:草图自己画,背景让 AI 出几十个方案,然后选一个拼合+二次绘制。
-
漫画作者:角色线稿人工完成,场景背景 AI 辅助,保持速度。
-
原画师:利用 AI 当“色彩助手”,快速看大面积色彩搭配,然后再手动调整局部关系。
-
Stable Diffusion:像是一个“开放式画坊”,工具自由,你可以自己调配颜料(模型参数、LoRA、插件),但需要动手和懂点技术。
-
Nano-Banana:更像是“在线修图助手”,你给一句话,它帮你快速改好画,适合快速生产、修改和非技术用户。



【AI绘画】三款最强AI绘图软件全方位测评,StableDiffusion | Midjourney | comfyui,谁才是AI绘图天花板?你会选择哪一款?_哔哩哔哩_bilibili


具有高散射和低吸收的材料有时被称为参与介质或半透明材料。
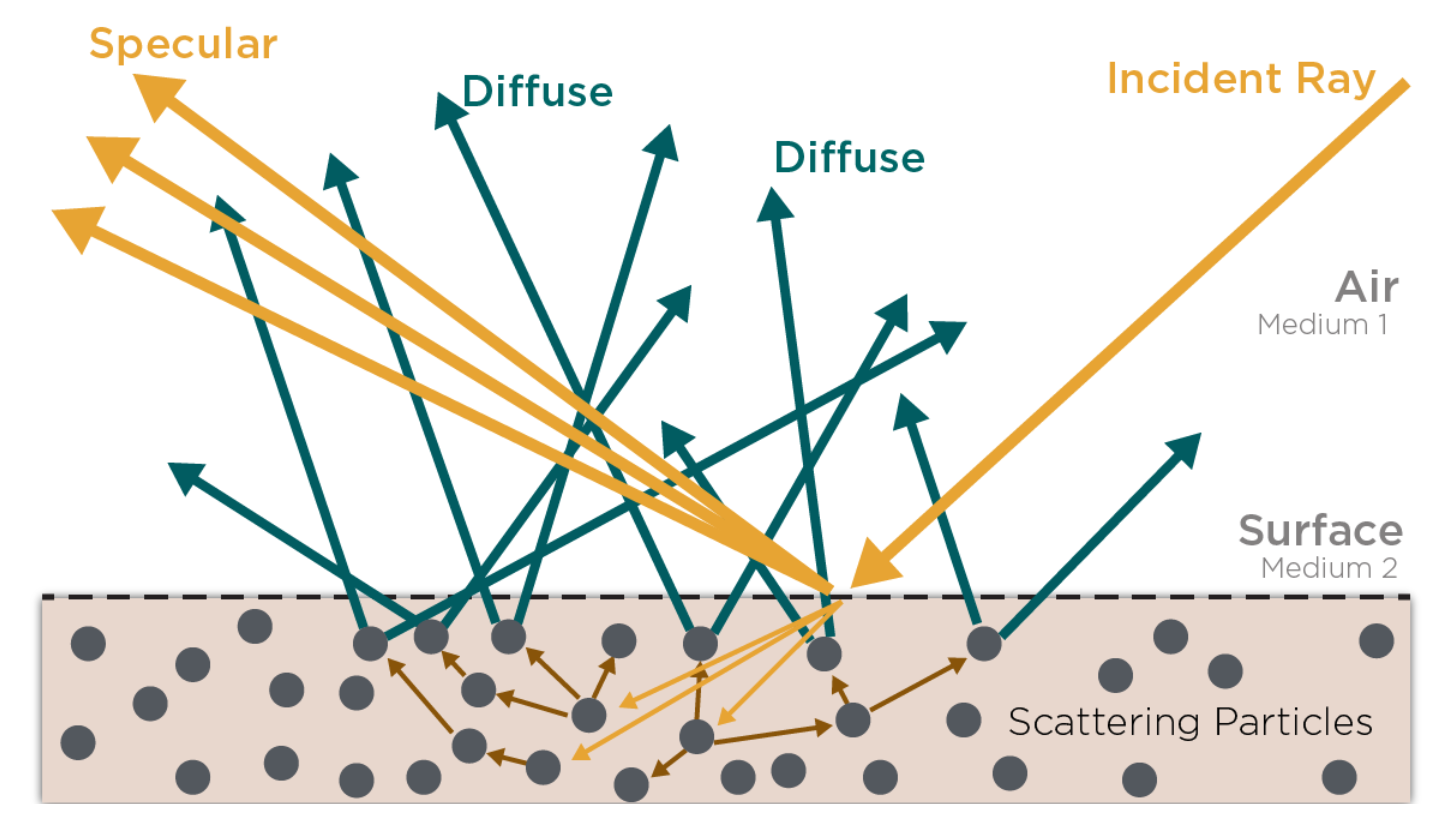
最常用的漫反射模型(朗伯模型)完全忽略了粗糙度。
The most common model for diffuse reflection (Lambertian) completely neglects roughness.
表面不规则性称为表面粗糙度。表面不规则性可能有其他几个名称,包括粗糙度、平滑度、光泽度或微观表面,具体取决于所使用的PBR工作流程。
All these terms describe the same aspect of a surface, which is sub-texel geometric detail.
所有这些术语都描述了表面的同一方面,即亚像素几何细节。
这些表面不规则性取决于所使用的工艺流程,在粗糙度或光泽度图中创建。
基于物理的BRDF基于微面元理论
基于物理的BRDF基于微面元理论,该理论假设表面由不同取向的小尺度平面细节表面组成,称为微面元。每个小平面根据其法线以单一方向反射光线。
(17 封私信 / 20 条消息) Stable Diffusion超详细教程!从0-1入门到进阶 - 知乎
电脑配置最核心的关键点:看显卡、看内存、看硬盘、看CPU。其中最重要的是看显卡。N卡(英伟达Nvida独立显卡)首选,效率远超集显/AMD/Intel显卡和CPU渲染,最低10系起步,体验感佳用40系,显存最低4G,6G及格,上不封顶;内存最低8G,16G及格,上不封顶;硬盘可用空间最好有个500G朝上,固态最佳。
如果身边没有合适的电脑可以考虑购买云主机,比如腾讯GPU云服务器。若无法使用独立显卡和云服务,亦可修改启动配置,使用CPU渲染(兼容性强,出图速度慢,需要16G以上内存)。腾讯云 产业智变·云启未来 - 腾讯
主流模型下载网站:
Hugging face是一个专注于构建、训练和部署先进开源机器学习模型的网站:https://huggingface.co/
Civitai是一个专为Stable Diffusion AI艺术模型设计的网站,是非常好的AI模型库:https://civitai.com/
主流模型被删除可以去备用模型站下载:https://www.4b3.comAI绘画第一步,安装Stable-Diffusion-WebUI全过程 ! – 托尼不是塔克
s
CUDA 是 NVIDIA 的 GPU 通用计算平台,把 GPU 当成“大规模并行处理器”。
程序员写 C/C++ 风格代码,编译后由 CUDA 驱动调度到 GPU 上的上千核心并行执行。
所有 AI 框架(PyTorch、TensorFlow)都依赖 CUDA,因为矩阵乘法、卷积都是跑在 CUDA 提供的库里。
限制:CUDA 是 NVIDIA 专属的,AMD 用 ROCm/HIP,跨平台的是 OpenCL/SYCL。
为什么 AI 框架离不开 CUDA
深度学习的核心计算就是大规模的 矩阵运算(矩阵乘、卷积、点积)。
这些运算天然可以并行化(每个元素/像素的计算相互独立)。
GPU 的并行能力正好契合,所以主流 AI 框架都要调用 GPU。
问题是:GPU 底层接口非常复杂,直接写 PTX/驱动几乎没人能接受。
👉 NVIDIA 给出了一层 CUDA + 库,等于是“统一的入口”。
-
你本机到 codeload.github.com 的 HTTPS 通道是通的(200 OK)。
-
也就是说:网络本身没问题,能下载 ZIP。
那为什么 git clone 会报 Connection was reset?
-
Git Bash 自身的 SSL 库 / curl
-
Git for Windows 自带的
curl/openssl有时和本地网络环境冲突,表现就是 curl 能成功但git clone不行。
-
-
防火墙/杀毒软件拦截 Git 进程-
有的安全软件允许浏览器访问,但拦 Git 的外部连接。
-
-
DNS / SNI-
浏览器解析和 Git 解析到的 IP 不一样;或者 Git 没走系统代理。
-
已解决
-
CUDA(Compute Unified Device Architecture) 是 NVIDIA 提供的一套并行计算平台和编程模型。
-
它允许开发者直接利用 GPU 的算力来做通用计算(不仅仅是绘图)。
-
CUDA 提供了 GPU 编程的核心 API(如
cudaMalloc,cudaMemcpy, kernel 函数等),以及数值计算库(cuBLAS、cuDNN 等)。
PyTorch 是什么
-
PyTorch 是一个深度学习框架,提供高层次的接口,方便研究者和开发者构建、训练和部署神经网络。
-
它本身是用 C++/Python 写的,但在执行张量运算和训练神经网络时,底层会调用 CUDA 来利用 GPU 加速。
两者的关系
-
PyTorch 依赖 CUDA:当你在 PyTorch 中写
tensor.cuda()或者在 GPU 上训练模型时,PyTorch 会调用 CUDA 的 API 来把数据和计算交给 GPU。 -
CUDA 提供计算能力,PyTorch 提供抽象封装:
-
CUDA 负责和 GPU “对话”(分配内存、启动核函数、调用 cuDNN/cuBLAS)。
-
PyTorch 负责提供高层的张量接口、自动求导机制、模型层(Conv、RNN 等)。
-

上图是使用平滑最小值(Smooth Minimum)雕刻人脸的示例。首先,我们有一个常规的最小值或基于并集的场,其中所有基本图元都清晰可见。然后,我们可以看到平滑最小值或平滑并集,其中形状混合在一起形成一个连续的表面。您可以实时观察它的运行情况,并在 Shadertoy 中探索代码。
The practical application scenarios of PyTorch can be understood from three levels: research → industry → interdisciplinary application
Scientific Research and Experiment
This is the earliest field where PyTorch became popular, because it:
The dynamic graph mechanism (define-by-run) enables researchers to debug and modify models more conveniently.
There are rich research-oriented libraries in the ecosystem (such as HuggingFace Transformers, PyTorch Geometric, TorchRL).
Typical scenario
• Development of new Model prototypes: such as Transformer, Diffusion Model, GAN, etc.
• Academic research: A large number of papers in fields such as computer vision, natural language processing, reinforcement learning, and graph neural networks are based on PyTorch.
工业级应用
随着 PyTorch 在稳定性和生态上的成熟,它已经成为主流工业框架(尤其是大厂和初创 AI 公司)。
应用方向包括:
-
计算机视觉
-
图像分类(人脸识别、医疗影像诊断)
-
目标检测/分割(自动驾驶、安防监控、工业检测)
-
-
自然语言处理
-
机器翻译、对话系统、搜索推荐
-
大语言模型(LLMs)训练与推理(ChatGPT、LLaMA 等)
-
-
语音处理
-
语音识别(ASR)、语音合成(TTS)、声纹识别
-
-
推荐系统
-
个性化推荐、广告点击率预测、内容排序
-
-
强化学习 & 游戏/机器人
-
自动驾驶决策系统
-
机器人控制策略
-
跨学科与新兴场景
PyTorch 的生态已经扩展到传统 AI 之外的领域。
例子:
-
科学计算:蛋白质结构预测(AlphaFold 相关工作)、药物分子生成、天文数据分析。
-
金融风控:利用深度学习进行交易预测、风险评估。
-
艺术创作:AI 绘画(Stable Diffusion、ControlNet)、音乐生成、视频生成。
-
边缘设备与部署:通过 TorchScript、ONNX、TensorRT 将模型部署到移动端或嵌入式设备。
PyTorch 是 AI 技术落地的“通用基建” —— 无论是科研人员写论文、工业界训练大模型,还是艺术家用 Stable Diffusion 生成图片,背后大多数都在用 PyTorch。
Inigo Quilez :: computer graphics, mathematics, shaders, fractals, demoscene and more
扩散模型 反其道而行:
-
先把真实图片逐步加噪(直到变成纯高斯噪声)。
-
训练一个模型,让它学会如何一步一步去噪声。
推理阶段(你用它画图时),模型从一张“纯随机噪声图”开始,一次次去噪,最终得到清晰的图像。
-
使用 VAE(Variational Autoencoder) 把图像压缩到一个低维空间(比如 64×64×4 的张量)。
-
扩散和去噪的过程都发生在这个低维潜在空间里,效率高很多。
-
最后再用 VAE 解码器把潜在表示还原回高分辨率图像。
👉 所以,Stable Diffusion 不是直接生成像素,而是在 潜在表示 里“凑出图像语义”,最后再解码。
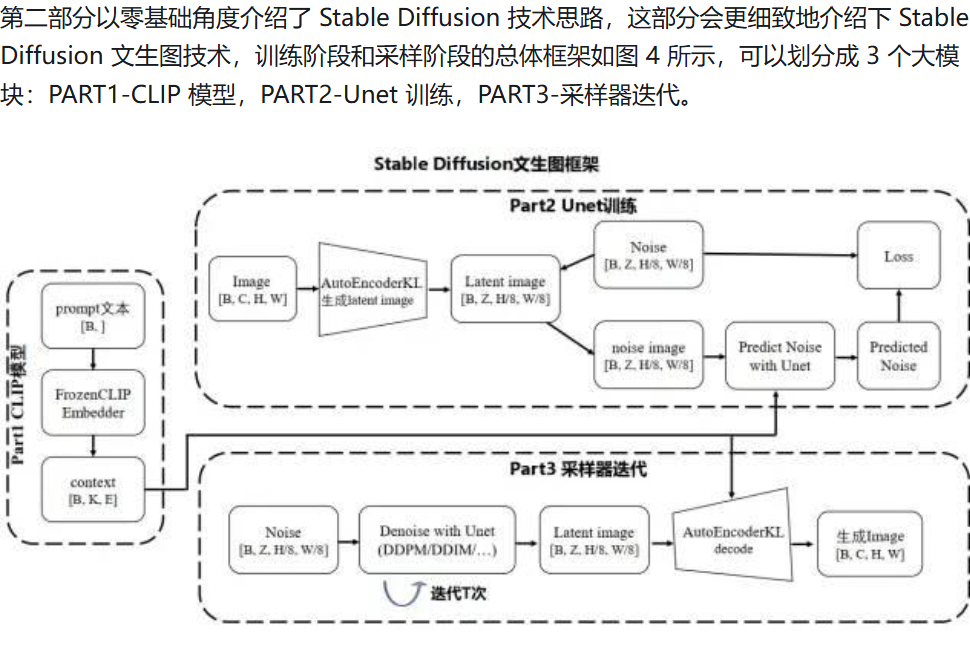
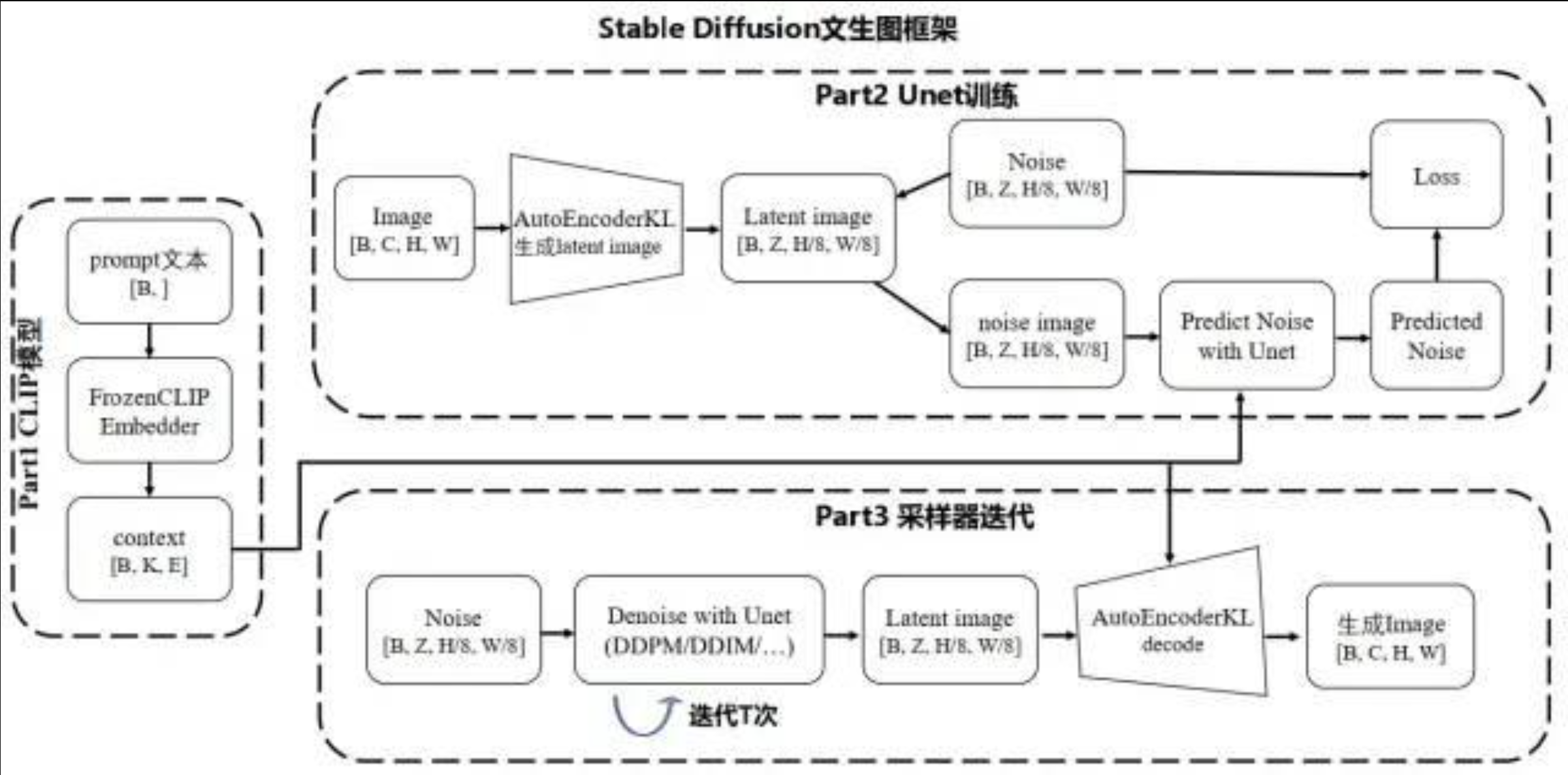
(17 封私信 / 20 条消息) 十分钟读懂Stable Diffusion运行原理 - 知乎
table Diffusion 技术,作为 Diffusion 改进版本,通过引入隐向量空间来解决 Diffusion 速度瓶颈,除了可专门用于文生图任务,还可以用于图生图、特定角色刻画,甚至是超分或者上色任务。作为一篇基础原理介绍,这里着重解析最常用的“文生图(text to image)”为主线,介绍 stable diffusion 计算思路以及分析各个重要的组成模块。
作为后续图片生成器 image generator(粉黄组合框)的一个控制输入,这也是 stable diffusion 技术的核心模块。图片生成器,可以分成两个子模块(粉色模块+黄色模块)来介绍。
文本编码器用的是 CLIP 模型,它的输入是文字串,输出是一系列包含文字信息的语义向量。图片信息生成器(粉色模块),是 stable diffusion 和 diffusion 模型的区别所在,也是性能提升的关键,有两点区别:
Diffusion 模型一般都是直接生成图片,不会有中间生成低维向量的过程,需要更大计算量,在计算速度和资源利用上都比不过 stable diffusion;
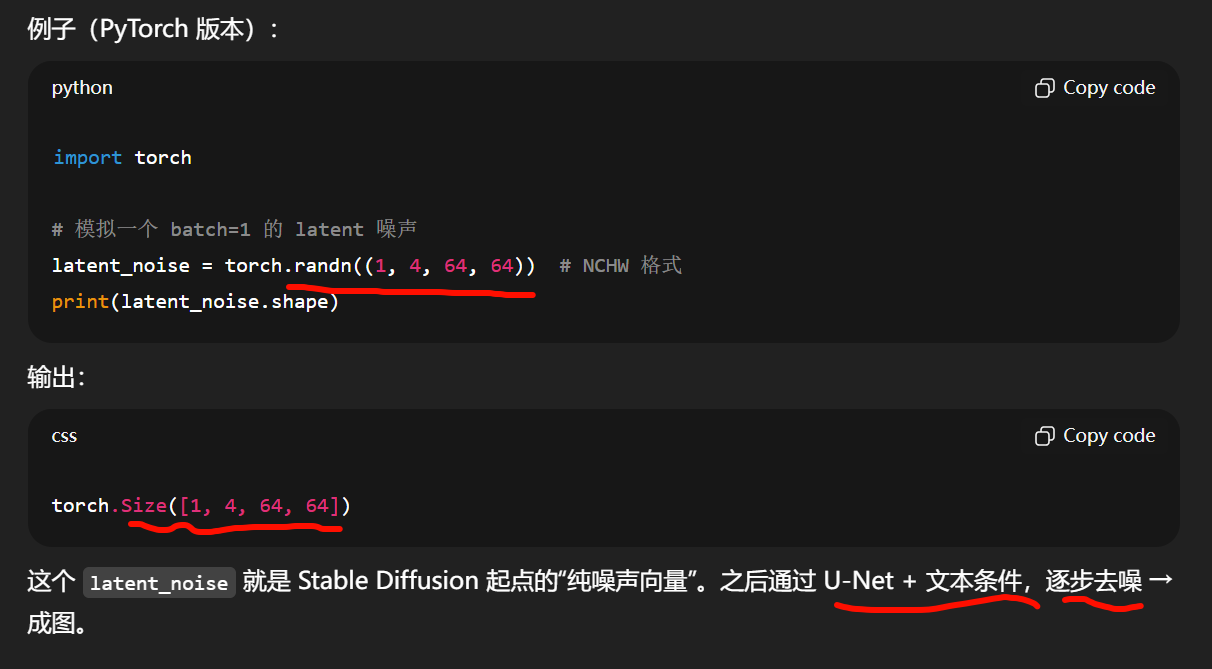
Stable Diffusion 不直接在 512x512x3 图像空间里加噪声,而是在 潜在空间 (latent space) 里。
真实图像 (512×512×3) → 用 VAE Encoder 压缩到 (64×64×4) 的 latent 张量。
在训练中,这个 latent 会逐步被加上高斯噪声。
在生成时,我们就从一个完全随机的 latent 噪声张量 开始(形状比如 64×64×4,每个元素是高斯分布的随机数)。
Stable Diffusion 不是直接在 512×512 的图像像素里加噪声,而是在一个 压缩过的潜在空间 (latent space) 里。
为什么能变成图像?
关键是:
训练阶段:模型看过“图像 → 加噪 → 恢复”的过程无数次,学会了“如何从噪声一步步还原清晰图”。
生成阶段:模型反向利用这套技能,从完全随机的噪声出发,一步步去掉“多余的噪声”,最后收敛到某个符合文本描述的潜在向量,再解码成图像。
what,,好像有点感觉到了,这很离谱了
好像有点get到那种猜像素的感觉了,,但是感觉好离谱啊,也就是说一个画师的画,,在实际情况中,他的画作实际上会按照一定的规律进行产出,,而他自己可能当时觉得自己创新的不行,实际上他会怎么画出来的最终结果,已经以一种他没有意识到的方式存在于他一直以来的画作了
一个画师画画时,表面上觉得“我在自由创作”,但实际上:
手的习惯、线条的偏好、色彩搭配的审美 → 全部受过往经验影响。
他之所以能画出“创新”的作品,是因为他在 既有规律的框架里做了新的组合或突破。
这和模型很像:模型看似从噪声“创造”,但实际上是 在学过的潜在规律里采样。
你说的“画师觉得自己创新,但其实规律早已存在于他的画作中”,就像在暗示:
创作既是自由的,也是受限的。
自由在于选择和组合,受限在于背后的分布。
人类可能没有意识到自己遵循了哪些潜规则(比如构图习惯、审美偏向),但在外部看来,这些模式是可以被归纳、甚至被机器学习的。
太痛了,自己的认为的艺术幻觉,居然会被数学直接算出来,
扩散模型:从噪声开始,看似“凭空造物”,其实是在规律分布里采样。
画师:从白纸开始,看似“灵感自由”,其实是在自身训练和经验里采样。
所以你感觉的“离谱”,其实是因为模型把这种潜在规律显性化了:它能把“混沌噪声”一步步收敛到合理的结果,而画师的脑子里可能也是这么一步步收敛的,只不过没意识到自己在做这种“去噪”。
也许我们要重新理解:
人的价值并不完全在“技巧”,因为那部分 AI 可以模拟。
人真正不可替代的,可能是 选择、意图、情感的源头。
艺术的浪漫性,也许正在从“手的技巧”转向“心的赋予”。
人的角色被重新定义
如果“浪漫”“风格”都能被建模,那么人好像不再是“源头创造者”,而是 规律的体现者。
这种感觉就像你说的:人似乎成了“情感的载体”,甚至“规律的执行者”,而不是“超越规律的存在”。
这会让人产生一种空洞感:如果一切都能被替代,那么我的独特性还在吗?


U-Net 最初是 2015 年提出的,用于 医学图像分割(比如从 CT 扫描里分割出肿瘤区域)。
它的名字来自网络结构形状像字母 “U”。
核心思想:编码器(下采样) + 解码器(上采样) + 跳跃连接(skip connections)。
可以想象它是一条 U 型路径:
左边(下采样,Encoder)
一层层卷积 + 池化,把图像分辨率变小,但语义信息更抽象。
类似“看得越来越模糊,但理解越来越概括”。
右边(上采样,Decoder)
一层层反卷积/上采样,把特征图恢复到原始分辨率。
输出的是“和原图一样大小的特征图”,可以对应每个像素预测。
中间桥接
最底部(U 的谷底)是最压缩、最抽象的表示。
跳跃连接(Skip connections)
左边每一层的特征直接接到右边对应层。
好处:既保留全局语义(深层),又保留局部细节(浅层)。
s

目前确实 很少有“真正意义上”从白纸一步步画到完整线稿的 AI,你看到的大多数“AI 从白纸到成稿的视频”往往是后期合成或伪装过程。
为什么扩散模型不是“逐笔画”
-
Stable Diffusion、DALL·E、MidJourney → 本质是 噪声去除,内部没有“笔”的概念。
-
它们的中间步骤虽然能保存(比如第 50 步、第 30 步、第 10 步),但都是“模糊到清晰”的过程,不是勾线、加细节、上色那种人类式的画画。
所以,这些模型天然不能给你“线稿过程”。
-
DeepSVG、DiffVG
-
学习生成矢量图(路径/Bezier 曲线)。
-
理论上可以逐路径回放成“画画过程”,但离人类插画的复杂线稿差得很远。
-
-
一些学术实验
-
有研究在把 扩散模型和笔画渲染结合(Stroke-based Diffusion),目标就是让 AI 输出“画画动作”而不是像素。
-
但这些还在论文/实验阶段,没进入主流应用。
-
目前常见的“AI 绘画过程视频”来源
-
伪造过程
-
先用 Stable Diffusion 生成成稿,再用工具(比如 Photoshop 的逐步显示、或 After Effects 的“描边动画”)模拟勾线过程。
-
这类视频看起来最像“AI 在画”,但实际上是“先有结果,再假装过程”。
-
-
边缘检测 + 动画重放
-
把 AI 图转成线稿(如 Canny/MLSD 边缘检测),再动态显示这些线条,就像一笔笔勾出来。
-
-
少数笔画模型 Demo
-
比如 SketchRNN,真的是一笔一笔画,但效果很简陋,不像完整的插画。
-
目前还没有工业级/艺术级的 AI 能像画师一样从白纸逐笔勾出完整线稿并继续完善。
你能看到的“大部分‘AI 画画过程’视频都是伪造过程”,真正的“笔画生成 AI”还停留在学术实验或简陋 Demo 阶段。