【论文阅读】-《THE JPEG STILL PICTURE COMPRESSION STANDARD》
JPEG 静止图像压缩标准

原文链接:https://ieeexplore.ieee.org/document/125072
摘要
过去几年中,一个名为 JPEG(联合图像专家组)的 ISO/CCITT 联合委员会一直致力于为连续色调静止图像(灰度和彩色)建立第一个国际压缩标准。JPEG 提出的标准旨在具有通用性,以支持各种连续色调图像的应用。为了满足许多应用的不同需求,JPEG 标准包含两种基本压缩方法,每种方法都有多种操作模式。基于 DCT 的方法用于“有损”压缩,而预测方法用于“无损”压缩。JPEG 的特点包括一种称为基线(Baseline)方法的简单有损技术,它是其他基于 DCT 的操作模式的子集。迄今为止,基线方法是实施最广泛的 JPEG 方法,并且其本身足以满足大量应用的需求。本文概述了 JPEG 标准,并详细介绍了基线方法。
1 引言
过去十年中,数字技术在许多方面取得的进步——特别是图像采集、数据存储、位图打印和显示设备——带来了许多数字成像应用。然而,由于成本相对较高,这些应用往往比较 specialized。除了传真可能例外,数字图像在通用计算系统中并不像文本和几何图形那样普遍。现代商业和消费者对照片和其他类型图像的大部分使用仍然通过更传统的模拟方式进行。
许多应用的关键障碍在于直接表示数字图像所需的海量数据。一张电视分辨率的彩色图片的数字化版本包含大约一百万字节;35mm 分辨率则需要十倍于此的数据量。即使图像捕获和显示设备相当便宜,由于高昂的存储或传输成本,使用数字图像常常不可行。
现代图像压缩技术提供了一个可能的解决方案。最先进的技术可以将典型图像压缩到其未压缩大小的 1/10 到 1/50,而不会明显影响图像质量。但仅靠压缩技术是不够的。要使涉及存储或传输的数字图像应用在当今市场广泛普及,需要标准的图像压缩方法来实现不同制造商设备的互操作性。CCITT 针对当今无处不在的 Group 3 传真机的建议 [17] 就是一个生动的例子,说明了标准压缩方法如何能够促成重要的图像应用。然而,Group 3 方法仅处理二值图像,并未解决照片图像压缩问题。
过去几年中,一项名为 JPEG(联合图像专家组)的标准化工作一直致力于为连续色调(多级)静止图像(灰度和彩色)建立第一个国际数字图像压缩标准。JPEG 中的“联合”指的是 CCITT 和 ISO 之间的合作。JPEG 正式作为指定的 ISO 委员会 JTC1/SC2/WG10 召开会议,但与 CCITT SGVIII 保持着密切的非正式合作。JPEG 将既是 ISO 标准,也是 CCITT 建议。两者的文本将完全相同。
摄影视频图文(Photovidootex)、桌面出版、图形艺术、彩色传真、报纸有线照片传输、医学成像以及许多其他连续色调图像应用都需要一个压缩标准,才能显著超越其现状发展。JPEG 承担了开发一个
通用压缩标准的雄心勃勃的任务,以满足几乎所有连续色调静止图像应用的需求。
如果这个目标得以实现,不仅 individual 应用将蓬勃发展,而且跨应用边界的图像交换也将得到促进。后一个特性将变得越来越重要,因为更多的图像应用将在通用计算系统上实现,而这些系统本身正变得越来越互操作和互联网络化。对于那些需要专用 VLSI 来满足其压缩和解压缩速度要求的应用,一个通用方法将提供单个应用内无法实现的规模经济。
本文概述了 JPEG 提出的图像压缩标准。鼓励没有 JPEG 或基于离散余弦变换(DCT)压缩先验知识的读者首先研究基线顺序编解码器的详细描述,它是所有基于 DCT 的解码器的基础。虽然本文提供了许多细节,但必然省略了更多细节。读者在尝试实现之前应参考 ISO 标准草案 [2]。
业界对 JPEG 提案的一些最早关注集中在将基线顺序编解码器作为一种运动图像压缩方法——属于“帧内”类,其中每一帧都被编码为单独的图像。这类运动图像编码虽然提供的压缩比不如 MPEG 等“帧间”方法,但具有更大的视频编辑灵活性。虽然本文仅关注 JPEG 作为静止图像标准(如 ISO 所愿),但有趣的是,JPEG 也很可能成为一个“事实上的”帧内运动标准。
2 背景:需求与选择过程
JPEG 的目标是开发一种满足以下要求的连续色调图像压缩方法:
-
在压缩率和相应的图像保真度方面达到或接近 state of the art,覆盖广泛的图像质量评级范围,尤其是在视觉保真度被描述为“非常好”到“极佳”的范围内;同时,编码器应该是可参数化的,以便应用(或用户)可以设置所需的压缩/质量权衡;
-
适用于几乎任何类型的连续色调数字源图像(即,对于大多数实际目的,不限制于特定尺寸、颜色空间、像素纵横比等的图像),并且不限制于对场景内容(如复杂性、颜色范围或统计特性)有限制的图像类别;
-
具有易处理的计算复杂度,使得在一系列 CPU 上实现具有可行性能的软件实现成为可能,并且对于需要高性能的应用,硬件实现具有可行的成本;
-
具有以下操作模式:
- 顺序编码:每个图像分量在单一从左到右、从上到下的扫描中编码;
- 渐进编码:图像在多次扫描中编码,适用于传输时间较长,并且观看者更喜欢看到图像以多次从粗糙到清晰的传递方式构建的应用;
- 无损编码:对图像进行编码以保证精确恢复每个源图像样本值(即使与有损模式相比,结果是低压缩);
- 分层编码:以多种分辨率对图像进行编码,以便可以访问较低分辨率的版本,而无需首先以其全分辨率解压缩图像。
1987 年 6 月,JPEG 进行了一个基于主观图像质量盲评的选择过程,并将 12 种提议方法缩小到三种。成立了三个非正式工作组来改进它们,并在 1988 年 1 月,第二次更严格的选择过程 [19] 显示,基于 8x8 DCT 的“ADCT”提案 [11] 产生了最好的图像质量。
在选择时,基于 DCT 的方法仅针对某些操作模式部分定义。从 1988 年到 1990 年,JPEG 承担了定义、记录、模拟、测试、验证以及 simply agreeing on 真正互操作性和通用性所必需的大量细节的艰巨任务。JPEG 工作的进一步历史包含在 [6, 7, 9, 18] 中。
3 拟议标准的体系结构
拟议的标准包含前面确定的四种“操作模式”。对于每种模式,指定了一个或多个不同的编解码器。一个模式内的编解码器根据它们可以处理的源图像样本的精度或它们使用的熵编码方法而有所不同。尽管本文中经常使用编解码器(编码器/解码器)一词,但并没有要求实现必须同时包含编码器和解码器。许多应用将拥有只需要其中之一的系统或设备。
这四种操作模式及其各种编解码器是 JPEG 追求通用性以及跨应用图像格式多样性的结果。多个部分可能会给人带来不必要的复杂性的印象,但它们实际上应该被视为一个全面的“工具包”,可以跨越广泛的连续色调图像应用。许多实现不太可能使用每一个工具——事实上,目前市场上大多数早期实现(甚至在最终 ISO 批准之前)只实现了基线顺序编解码器。
基线顺序编解码器本身是一种丰富而复杂的压缩方法,足以满足许多应用的需求。正确且可互操作地实现这种最低限度的 JPEG 能力将为行业提供跨供应商和应用交换图像的重要初始能力。
4 基于 DCT 编码的处理步骤
图 1 和图 2 显示了作为基于 DCT 操作模式核心的关键处理步骤。这些图说明了单分量(灰度)图像压缩的特殊情况。读者可以通过将其本质上视为灰度图像样本的 8x8 块流的压缩来掌握基于 DCT 压缩的要点。彩色图像压缩随后可以近似地视为多个灰度图像的压缩,这些图像要么完全一次压缩一个,要么通过交替交错来自每个图像的 8x8 样本块来压缩。
对于包括基线顺序编解码器在内的 DCT 顺序模式编解码器,简化图相当完整地说明了单分量压缩的工作原理。每个 8x8 块被输入,经过每个处理步骤,并以压缩形式产生输出到数据流中。对于 DCT 渐进模式编解码器,在熵编码步骤之前存在一个图像缓冲区,以便可以存储图像,然后在多次扫描中分批输出,质量逐渐提高。对于分层操作模式,所示的步骤被用作更大框架内的构建块。
4.1 8x8 FDCT 和 IDCT
在编码器的输入端,源图像样本被分组为 8x8 块,从范围 [0,2m−1][0, 2^m - 1][0,2m−1] 的无符号整数移位到范围 [−2p,2p−1][-2^p, 2^{p-1}][−2p,2p−1] 的有符号整数,并输入到前向 DCT(FDCT)。在解码器的输出端,逆 DCT(IDCT)输出 8x8 样本块以形成重建图像。以下方程是 8x8 FDCT 和 8x8 IDCT 的理想化数学定义:
F(u,v)=14C(u)C(v)[∑x=07∑y=07f(x,y)∗cos(2x+1)uπ16cos(2x+1)vπ16]F(u,v) = \frac{1}{4} C(u)C(v) \left[ \sum_{x=0}^{7} \sum_{y=0}^{7} f(x,y) * \cos \frac{(2x+1)u\pi}{16} \cos \frac{(2x+1)v\pi}{16} \right]F(u,v)=41C(u)C(v)[x=0∑7y=0∑7f(x,y)∗cos16(2x+1)uπcos16(2x+1)vπ]
f(x,y)=14[∑u=07∑v=07C(u)C(v)F(u,v)cos(2x+1)uπ16cos(2x+1)vπ16]f(x,y) = \frac{1}{4} \left[ \sum_{u=0}^{7} \sum_{v=0}^{7} C(u)C(v)F(u,v) \cos \frac{(2x+1)u\pi}{16} \cos \frac{(2x+1)v\pi}{16} \right]f(x,y)=41[u=0∑7v=0∑7C(u)C(v)F(u,v)cos16(2x+1)uπcos16(2x+1)vπ]
其中:C(u),C(v)=1/2C(u), C(v) = 1/\sqrt{2}C(u),C(v)=1/2 当 u,v=0u,v = 0u,v=0;
C(u),C(v)=1C(u), C(v) = 1C(u),C(v)=1 其他情况。
DCT 与离散傅里叶变换(DFT)相关。通过将 FDCT 视为谐波分析器,将 IDCT 视为谐波合成器,可以获得一些关于基于 DCT 压缩的简单直觉。每个 8x8 的源图像样本块实际上是一个 64 点离散信号,它是两个空间维度 xxx 和 yyy 的函数。FDCT 将这样的信号作为其输入,并将其分解为 64 个正交基信号。每个基信号包含 64 个独特的二维(2D)“空间频率”之一,这些频率构成了输入信号的“频谱”。FDCT 的输出是 64 个基信号幅度或“DCT 系数”的集合,其值由特定的 64 点输入信号唯一确定。
因此,DCT 系数值可以看作是 64 点输入信号中包含的 2D 空间频率的相对量。在两个维度上频率为零的系数称为“DC 系数”,其余 63 个系数称为“AC 系数”。因为样本值
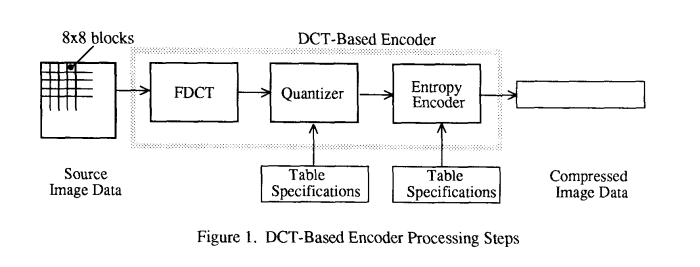
图 1. 基于 DCT 的编码器处理步骤
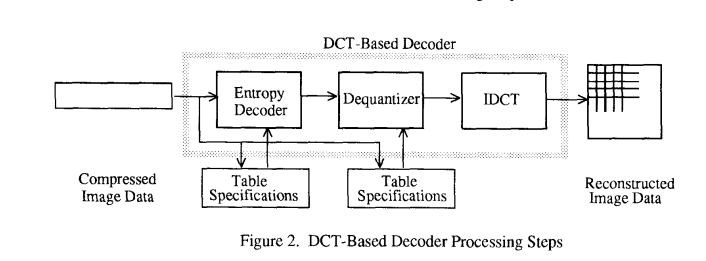
图 2. 基于 DCT 的解码器处理步骤
通常在整个图像中点与点之间缓慢变化,FDCT 处理步骤通过将大部分信号集中在较低空间频率上,为实现数据压缩奠定了基础。对于一个来自典型源图像的典型 8x8 样本块,大多数空间频率的幅度为零或接近零,不需要编码。
在解码器端,IDCT 反转这一处理步骤。它获取 64 个 DCT 系数(此时已被量化),并通过求和基信号来重建一个 64 点的输出图像信号。在数学上,DCT 是图像域和频率域之间 64 点向量的一对一映射。如果 FDCT 和 IDCT 能够以完美的精度计算,并且如果 DCT 系数不像下文描述的那样被量化,则可以精确恢复原始的 64 点信号。原则上,DCT 不会给源图像样本带来损失;它只是将它们转换到一个可以更有效编码的域。
实际 FDCT 和 IDCT 实现的某些特性提出了 JPEG 标准应该精确要求什么的问题。一个基本特性是 FDCT 和 IDCT 方程包含超越函数。因此,任何物理实现都无法以完美精度计算它们。由于 DCT 的应用重要性及其与 DFT 的关系,人们设计了许多不同的算法来近似计算 FDCT 和 IDCT [16]。事实上,快速 DCT 算法的研究仍在进行中,并且没有一种算法对所有实现都是最优的。在通用 CPU 的软件中是最优的,在可编程 DSP 的固件中不太可能是最优的,并且对于专用 VLSI 来说肯定是次优的。
即使考虑到 DCT 输入和输出的有限精度,独立设计的、即使在其表示余弦项或中间结果的精度上,或者在其求和和舍入小数值的方式上仅有微小差异的相同 FDCT 或 IDCT 算法,最终也会从相同的输入产生 slightly different 输出。
为了在实现中保持创新和定制的自由,JPEG 选择在其提议的标准中既不指定唯一的 FDCT 算法,也不指定唯一的 IDCT 算法。这使得符合性稍微难以确认,因为两个兼容的编码器(或解码器)在给定相同输入的情况下通常不会产生相同的输出。JPEG 标准将通过指定精度测试作为其对所有基于 DCT 的编码器和解码器的符合性测试的一部分来解决这个问题;这是为了防止粗略不准确的余弦基函数降低图像质量。
对于每种基于 DCT 的操作模式,JPEG 提案为具有 8 位和 12 位(每分量)源图像样本的图像指定了单独的编解码器。需要 12 位编解码器来适应某些类型的医学和其他图像,它们需要更多的计算资源来实现所需的 FDCT 或 IDCT 精度。具有其他样本精度的图像通常可以通过 8 位或 12 位编解码器来适应,但这必须在 JPEG 标准之外完成。例如,应用将负责决定如何将 6 位样本拟合或填充到 8 位编码器的输入接口,如何在解码器的输出端解包它,以及如何编码任何必要的相关信息。
4.2 量化
从 FDCT 输出后,64 个 DCT 系数中的每一个都与一个 64 元素量化表一起进行均匀量化,该量化表必须由应用(或用户)指定作为编码器的输入。每个元素可以是 1 到 255 之间的任何整数值,它指定了其相应 DCT 系数量化器的步长。量化的目的是通过以不超过实现所需图像质量所必需的精度来表示 DCT 系数,从而实现进一步压缩。换句话说,此处理步骤的目标是丢弃视觉上不显著的信息。量化是多对一映射,因此本质上是有损的。它是基于 DCT 的编码器中损失的主要来源。
量化定义为每个 DCT 系数除以其相应的量化器步长,然后四舍五入到最接近的整数:
FQ(u,v)=IntegerRound(F(u,v)Q(u,v))F^Q(u,v) = Integer \ Round \ (\frac{F(u,v)}{Q(u,v)})FQ(u,v)=Integer Round (Q(u,v)F(u,v))
(3)
该输出值通过量化器步长进行归一化。反量化是逆函数,在这种情况下,它仅仅意味着通过乘以步长来移除归一化,将结果返回到适合输入到 IDCT 的表示形式:
FQ′(u,v)=FQ(u,v)⋅Q(u,v)F^{Q'}(u,v) = F^Q(u,v) \cdot Q(u,v) FQ′(u,v)=FQ(u,v)⋅Q(u,v)
(4)
当目标是在没有可见伪影的情况下尽可能压缩图像时,理想情况下,每个步长应选择为其相应余弦基函数的视觉贡献的感知阈值或“刚好可察觉差异”。这些阈值也是源图像特性、显示特性和观看距离的函数。对于这些变量可以合理定义的应用,可以进行心理视觉实验来确定最佳阈值。[12] 中描述的实验导致了一组用于 CCIR-601 [4] 图像和显示的量化表。这些已被 JPEG 成员实验性使用,并将作为信息性内容出现在 ISO 标准中,但不是强制性要求。
4.3 DC 系数编码和 Zig-Zag 序列
量化后,DC 系数与 63 个 AC 系数分开处理。DC 系数是 64 个图像样本平均值的度量。由于相邻 8x8 块的 DC 系数之间通常存在强相关性,量化后的 DC 系数被编码为与编码顺序(下文定义)中前一个块的 DC 项的差值,如图 3 所示。这种特殊处理是值得的,因为 DC 系数经常包含总图像能量的很大一部分。
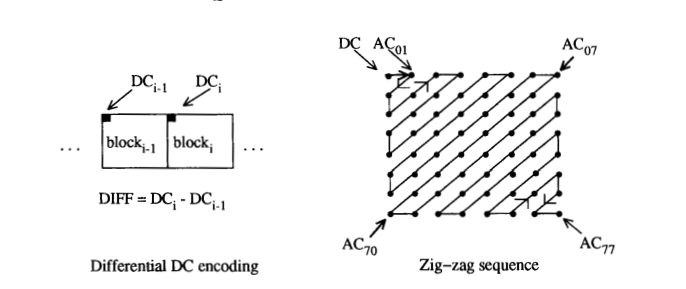
图 3. 为熵编码准备量化系数
最后,所有量化系数被排序成“zig-zag”序列,如图 3 所示。这种排序通过将低频系数(更可能非零)放在高频系数之前,有助于促进熵编码。
熵编码
基于 DCT 的编码器最后的处理步骤是熵编码。此步骤通过基于量化 DCT 系数的统计特性更紧凑地编码它们,从而无损地实现额外压缩。JPEG 提案指定了两种熵编码方法——哈夫曼编码 [8] 和算术编码 [15]。基线顺序编解码器使用哈夫曼编码,但所有操作模式的编解码器都指定了两种方法。
将熵编码视为一个两步过程是有用的。第一步将量化系数的 zig-zag 序列转换为符号的中间序列。第二步将符号转换为数据流,其中符号不再具有外部可识别的边界。中间符号的形式和定义取决于基于 DCT 的操作模式和熵编码方法。
哈夫曼编码要求应用指定一个或多个哈夫曼码表集。用于压缩图像的相同表需要用于解压缩它。哈夫曼表可以在应用中预定义并用作默认值,或者在压缩前的初始统计收集过程中专门为给定图像计算。这些选择是使用 JPEG 的应用的事情;JPEG 提案没有指定必需的哈夫曼表。第 7 节详细描述了基线顺序编码器的哈夫曼编码。
相比之下,JPEG 提案 [2] 中指定的特定算术编码方法不需要外部输入表,因为它能够在编码图像时适应图像统计。(如果需要,可以使用统计调节表作为输入以获得稍好的效率,但这不是必需的。)对于 JPEG 成员测试过的许多图像,算术编码比哈夫曼编码产生了 5-10% 更好的压缩率。然而,一些人认为对于某些实现,例如最高速的硬件实现,它比哈夫曼编码更复杂。(在 JPEG 的整个历史中,“复杂性”已被证明是作为比较压缩方法的实用度量中最难以捉摸的。)
如果两个 JPEG 编解码器之间的唯一区别是熵编码方法,则可以通过简单地用一种方法进行熵解码并用另一种方法进行熵重新编码来实现两者之间的转码。
压缩与图像质量
对于具有中等复杂度场景的彩色图像,所有基于 DCT 的操作模式通常为指定的压缩范围产生以下级别的图像质量。这些级别仅供参考——质量和压缩率会根据源图像特征和场景内容而有显著差异。(这里的单位“比特/像素”是指压缩图像中的总比特数——包括色度分量——除以亮度分量中的样本数。)
- 0.25-0.5 比特/像素:中等至良好质量,足以满足某些应用;
- 0.5-0.75 比特/像素:良好至非常好质量,足以满足许多应用;
- 0.75-1.5 比特/像素:优秀质量,足以满足大多数应用;
- 1.5-2.0 比特/像素:通常与原始无法区分,足以满足要求最苛刻的应用。
5 预测无损编码的处理步骤
在 1988 年选择了基于 DCT 的方法之后,JPEG 发现基于 DCT 的无损模式很难定义为一个实用的标准,使得编码器和解码器可以独立实现,而不会对编码器和解码器的实现施加严格的限制。
JPEG 为了满足其对无损操作模式的要求,选择了一种简单的预测方法,该方法完全独立于前面描述的 DCT 处理。选择这种方法并非像基于 DCT 的方法那样是严格竞争评估的结果。然而,JPEG 无损方法产生的结果,鉴于其简单性,令人惊讶地接近无损连续色调压缩的 state of the art,如最近的技术报告 [5] 所示。
图 4 显示了单分量图像的主要处理步骤。预测器组合最多三个相邻样本(A、B 和 C)的值,以形成对图 5 中 X 指示的样本的预测。然后将该预测从样本 X 的实际值中减去,并对差值进行编码
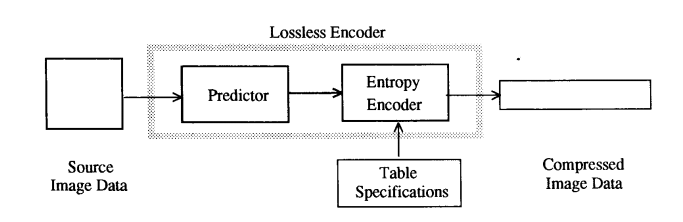
图 4. 无损模式编码器处理步骤
使用两种熵编码方法中的任何一种——哈夫曼或算术——进行无损编码。可以使用表 1(“选择值”下)中列出的八种预测器中的任何一种。
选择 1、2 和 3 是一维预测器,选择 4、5、6 和 7 是二维预测器。选择值 0 只能用于分层操作模式中的差分编码。熵编码与第 7.1 节(哈夫曼编码)中描述的用于 DC 系数的熵编码几乎相同。
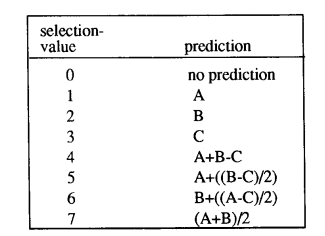
表 1. 无损编码的预测器
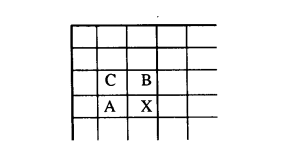
图 5. 3 样本预测邻域
对于无损操作模式,指定了两种不同的编解码器——每种熵编码方法一种。编码器可以使用从 2 到 16 位/样本的任何源图像精度,并且可以使用除选择值 0 之外的任何预测器。解码器必须处理任何样本精度和任何预测器。无损编解码器通常为具有中等复杂度场景的彩色图像产生大约 2:1 的压缩。
6 多分量图像
前面几节讨论了基于 DCT 和预测无损编解码器在单分量源图像情况下的关键处理步骤。这些步骤完成了图像数据压缩。但 JPEG 提案的很大一部分也涉及处理和控制具有多个分量的彩色(或其他)图像。JPEG 对通用压缩标准的目标要求其提案能适应各种源图像格式。
6.1 源图像格式
JPEG 提案中使用的源图像模型是从各种图像类型和应用中抽象出来的,仅包含压缩和重建数字图像数据所必需的内容。读者应认识到,JPEG 压缩数据格式编码的信息不足以作为完整的图像表示。例如,JPEG 不指定或编码任何关于像素纵横比、颜色空间或图像采集特性的信息。
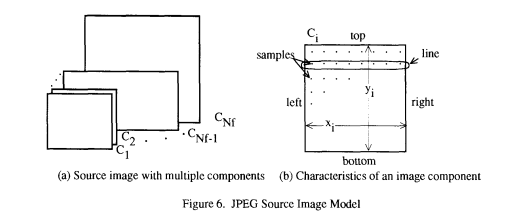
图 6 说明了 JPEG 源图像模型。源图像包含 1 到 255 个图像分量,有时称为颜色或光谱波段或通道。每个分量由一个样本矩形数组组成。样本定义为精度为 P 位的无符号整数,其值在范围 [0,2P−1][0, 2^P - 1][0,2P−1] 内。同一源图像中所有分量的所有样本必须具有相同的精度 P。对于基于 DCT 的编解码器,P 可以是 8 或 12;对于预测编解码器,P 可以是 2 到 16。
第 i 个分量具有样本尺寸 xix_ixi 乘 yiy_iyi。为了适应某些图像分量以不同于其他分量的速率采样的格式,分量可以具有不同的尺寸。尺寸必须具有由 HiH_iHi 和 ViV_iVi(相对水平和垂直采样因子)定义的互整关系,这些因子必须为每个分量指定。整体图像尺寸 X 和 Y 定义为图像中所有分量的最大 xix_ixi 和 yiy_iyi,并且可以是最大 2162^{16}216 的任何数字。H 和 V 只允许整数值 1 到 4。编码的参数是 X、Y 以及每个分量的 HiH_iHi 和 ViV_iVi。解码器根据公式 5 所示的以下关系重建每个分量的尺寸 xix_ixi 和 yiy_iyi:
xi=⌈X×HiHmax⌉andyi=⌈Y×ViVmax⌉(5)x_i = \left\lceil X \times \frac{H_i}{H_{max}} \right\rceil \quad \text{and} \quad y_i = \left\lceil Y \times \frac{V_i}{V_{max}} \right\rceil \tag{5}xi=⌈X×HmaxHi⌉andyi=⌈Y×VmaxVi⌉(5)
其中 ⌈⋅⌉\left\lceil \cdot \right\rceil⌈⋅⌉ 是向上取整函数。
6.2 编码顺序与交错
一个实用的图像压缩标准必须解决系统在解压缩过程中需要如何处理数据的问题。许多应用需要在并行显示或打印多分量图像的过程中与解压缩过程进行流水线操作。对于许多系统,这只有在分量在压缩数据流内交错在一起时才可行。
为了使相同的交错机制适用于基于 DCT 和预测的编解码器,JPEG 提案定义了“数据单元”的概念。数据单元在预测编解码器中是一个样本,在基于 DCT 的编解码器中是一个 8x8 样本块。
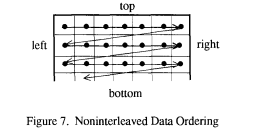
压缩数据单元放置在压缩数据流中的顺序是光栅扫描顺序的推广。通常,数据单元根据图 6 所示的方向从左到右、从上到下排序。(应用负责定义源图像的哪些边缘是上、下、左、右。)如果图像分量是非交错的(即,压缩时未与其他分量交错),则压缩数据单元按纯光栅扫描顺序排序,如图 7 所示。
当两个或多个分量交错时,每个分量 CiC_iCi 被划分为 HiH_iHi 乘 ViV_iVi 数据单元的矩形区域,如图 8 的通用示例所示。区域在一个分量内从左到右、从上到下排序,并且在一个区域内,数据单元从左到右、从上到下排序。JPEG 提案定义了术语最小编码单元(MCU)作为最小的
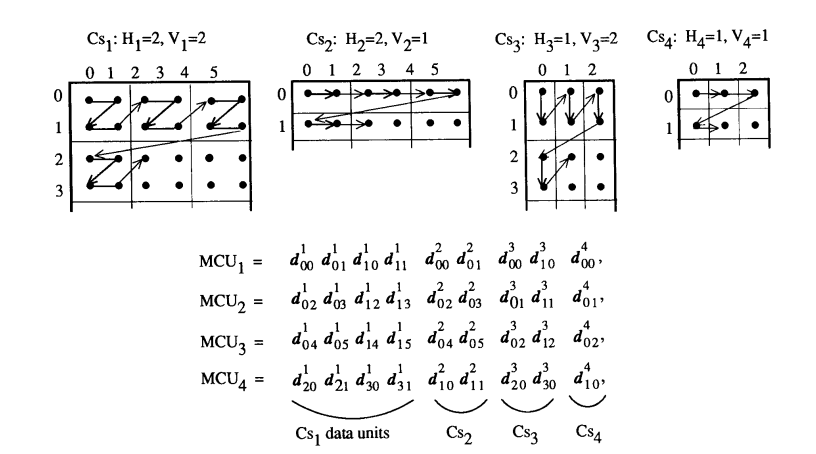
图 8. 通用交错数据排序示例
交错数据单元组。对于所示的示例,MCU_1 包含首先取自 C1C_1C1 最左上区域的数据单元,接着是取自 C2C_2C2 同一区域的数据单元,同样对于 C3C_3C3 和 C4C_4C4 也是如此。MCU_2 继续该模式,如图所示。
因此,交错数据是有序的 MCU 序列,一个 MCU 中包含的数据单元数量由交错的分量数量及其相对采样因子决定。可以交错的最大分量数为 4,一个 MCU 中数据单元的最大数量为 10。后一个限制如公式 6 所示,其中求和是针对所有交错分量进行的:
∑all interleaved componentsHi×Vi≤10(6)\sum_{\text{all interleaved components}} H_i \times V_i \leq 10 \tag{6}all interleaved components∑Hi×Vi≤10(6)
由于此限制,并非每一个可以在 JPEG 压缩图像中以非交错顺序表示的 4 分量组合都允许被交错。另外,请注意 JPEG 提案允许在同一压缩图像中,某些分量是交错的,而某些是非交错的。
6.3 多表
除了前面讨论的交错控制之外,JPEG 编解码器还必须控制将正确的表数据应用于正确的分量。必须使用相同的量化表和相同的熵编码表(或表集)来编码一个分量内的所有样本。
JPEG 解码器可以同时存储最多 4 个不同的量化表和最多 4 个不同的(组)熵编码表。(基线顺序解码器是例外;它只能存储最多 2 组熵编码表。)这对于在包含多个(交错)分量的扫描的解压缩过程中在不同表之间切换是必要的,以便将正确的表应用于正确的分量。(不能在扫描的解压缩过程中加载表。)图 9 说明了编码器端必须与多分量交错结合管理的表切换控制。(此简化视图未区分量化和熵编码表。)
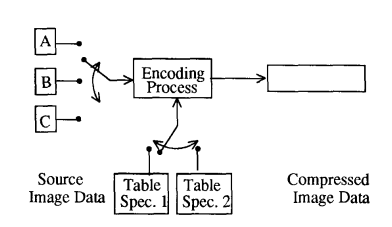
图 9. 分量交错和表切换控制
7 基线和其他 DCT 顺序编解码器
DCT 顺序操作模式包括第 4 节中的 FDCT 和量化步骤,以及第 6.3 节中的多分量控制。除了基线顺序编解码器之外,还定义了其他 DCT 顺序编解码器以适应两种不同的样本精度(8 位和 12 位)和两种不同类型的熵编码方法(哈夫曼和算术)。
基线顺序编码用于具有 8 位样本的图像,并且仅使用哈夫曼编码。它与其他顺序 DCT 编解码器的不同之处还在于其解码器只能存储两组哈夫曼表(每组一个 AC 表和一个 DC 表)。此限制意味着,对于具有三个或四个交错分量的图像,至少有一组哈夫曼表必须由两个分量共享。对于非交错分量,此限制根本不构成任何限制;在非交错分量的解压缩开始之前,可以将一组新表加载到解码器中。
对于许多确实需要交错三个颜色分量的应用,此限制几乎根本不是限制。表示色度(“颜色”)信息用两个分量,表示消色差(“灰度”)信息用第三个分量的颜色空间(YUV、CIELUV、CIELAB 等)比像 RGB 这样的空间更有利于压缩。一组哈夫曼表可用于消色差分量,一组用于色度分量。对于大多数图像的色度分量,DCT 系数统计是相似的,并且一组哈夫曼表可以几乎像两组一样最优地对两者进行编码。
委员会还认为,以商品价格早期提供单芯片实现将鼓励 JPEG 提案在各种应用中的早期接受。在 1988 年定义基线顺序时,委员会的 VLSI 专家认为,当前技术使得将四组可加载哈夫曼表——除了四组量化表之外——塞进一个商品价格的编解码器芯片的可行性是一个有风险的提议。
基线顺序编解码器的 FDCT、量化、DC 差分和 zig-zag 排序处理步骤完全按照第 4 节的描述进行。在熵编码之前,通常只有很少的非零系数和许多零值系数。熵编码的任务是有效地编码这些少量系数。基线顺序熵编码的描述分为两个步骤:将量化 DCT 系数转换为符号的中间序列,以及为符号分配变长码。
7.1 中间熵编码表示
在中间符号序列中,每个非零 AC 系数与 zig-zag 序列中在其前面的“游程长度”(连续数量)的零值 AC 系数组合表示。每个这样的游程长度/非零系数组合(通常)由一对符号表示:
符号-1符号-2\text{符号-1} \quad \text{符号-2}符号-1符号-2
(RUNLENGTH, SIZE)(AMPLITUDE)(\text{RUNLENGTH, SIZE}) \quad (\text{AMPLITUDE})(RUNLENGTH, SIZE)(AMPLITUDE)
符号-1 表示两条信息,RUNLENGTH 和 SIZE。符号-2 表示指定的单条信息 AMPLITUDE,它 simply 是非零 AC 系数的幅度。RUNLENGTH 是 zig-zag 序列中在所表示的非零 AC 系数之前的连续零值 AC 系数的数量。SIZE 是用于编码 AMPLITUDE 的位数——也就是说,通过 JPEG 特定哈夫曼编码方法使用的有符号整数编码来编码符号-2。
RUNLENGTH 表示长度为 0 到 15 的零游程。zig-zag 序列中的实际零游程可能大于 15,因此符号-1 值 (15, 0) 被解释为 runlength=16 的扩展符号。在终止符号-1(其 RUNLENGTH 值完成实际游程长度)之前,最多可以有三个连续的 (15, 0) 扩展。终止符号-1 后面总是跟着一个符号-2,除非最后的零游程包括最后一个(第 63 个)AC 系数。在这种常见情况下,特殊的符号-1 值 (0,0) 表示 EOB(块结束),并且可以被视为终止 8x8 样本块的“转义”符号。
因此,对于每个 8x8 样本块,63 个量化 AC 系数的 zig-zag 序列被表示为一个符号-1、符号-2 符号对的序列,尽管每个“对”在长游程长度的情况下可以有符号-1 的重复,或者在 EOB 的情况下只有一个符号-1。
量化 AC 系数的可能范围决定了 AMPLITUDE 和 SIZE 信息都必须表示的值的范围。对 8x8 FDCT 方程的数值分析表明,如果 64 点(8x8 块)输入信号包含 N 位整数,则输出数字(DCT 系数)的非小数部分最多可以增长 3 位。当量化器步长整数值为 1 时,这也是量化 DCT 系数的最大可能大小。
基线顺序具有范围 [−27,27−1][-2^7, 2^7-1][−27,27−1] 的 8 位整数源样本,因此量化 AC 系数幅度覆盖范围 [−210,210−1][-2^{10}, 2^{10}-1][−210,210−1] 的整数。有符号整数编码使用长度为 1 到 10 位的符号-2 AMPLITUDE 码(因此 SIZE 也表示 1 到 10 的值),并且 RUNLENGTH 表示如前所述的 0 到 15 的值。对于 AC 系数,符号-1 和符号-2 中间表示的结构分别在表 2 和表 3 中说明。
8x8 样本块的差分 DC 系数的中间表示结构类似。然而,符号-1 仅表示 SIZE 信息;符号-2 像以前一样表示 AMPLITUDE 信息:
符号-1符号-2(SIZE)(AMPLITUDE)\begin{array}{|c|c|} \hline \text{符号-1} & \text{符号-2} \\ \text{(SIZE)} & \text{(AMPLITUDE)} \\ \hline \end{array}符号-1(SIZE)符号-2(AMPLITUDE)
由于 DC 系数是差分编码的,它覆盖的整数值是 AC 系数的两倍,[−211,211−1][-2^{11}, 2^{11}-1][−211,211−1],因此必须为 DC 系数在表 3 的底部添加一个额外的级别。因此,DC 系数的符号-1 表示 1 到 11 的值。

表 2. 基线哈夫曼编码符号-1 结构
7.2 变长熵编码
一旦一个 8x8 块的量化系数数据以上述中间符号序列表示,就会分配变长码。对于每个 8x8 块,首先编码并输出 DC 系数的符号-1 和符号-2 表示。
对于 DC 和 AC 系数,每个符号-1 使用分配给 8x8 块的图像分量的哈夫曼表集中的变长码(VLC)进行编码。每个符号-2 使用一个“变长整数”(VLI)码进行编码,其长度(以位为单位)在表 3 中给出。VLC 和 VLI 都是变长码,但 VLI 不是哈夫曼码。一个重要的区别是,VLC(哈夫曼码)的长度在解码之前是未知的,但 VLI 的长度存储在其前面的 VLC 中。
哈夫曼码(VLC)必须作为输入外部指定给 JPEG 编码器。(请注意,哈夫曼表在数据流中的表示形式是一种间接规范,解码器必须在解压缩之前根据它构建表本身。)JPEG 提案在其信息附录中包含了一组示例哈夫曼表,但由于它们是应用特定的,因此没有指定任何必需使用的表。相比之下,VLI 码是“硬连线”到提案中的。这是合适的,因为 VLI 码数量要多得多,可以计算而不是存储,并且尚未证明实现为哈夫曼码时会显著提高效率。
7.3 基线编码示例
本节给出了单个 8x8 样本块的基线压缩和编码示例。请注意,此处省略了完整 JPEG 基线编码器的大量操作,包括创建交换格式信息(参数、头、量化和哈夫曼表)、字节填充、在标记码之前填充到字节边界以及其他关键操作。尽管如此,此示例应有助于具体化前面的许多解释。
图 10(a) 是一个 8x8 的 8 位样本块,任意从一个真实图像中提取。样本间的小变化表明低频空间频率占主导地位。从每个样本中减去 128 以进行所需的电平移位后,将 8x8 块输入到 FDCT 方程 (1)。图 10(b) 显示了(保留一位小数)得到的 DCT 系数。除了少数最低频率系数外,幅度都非常小。
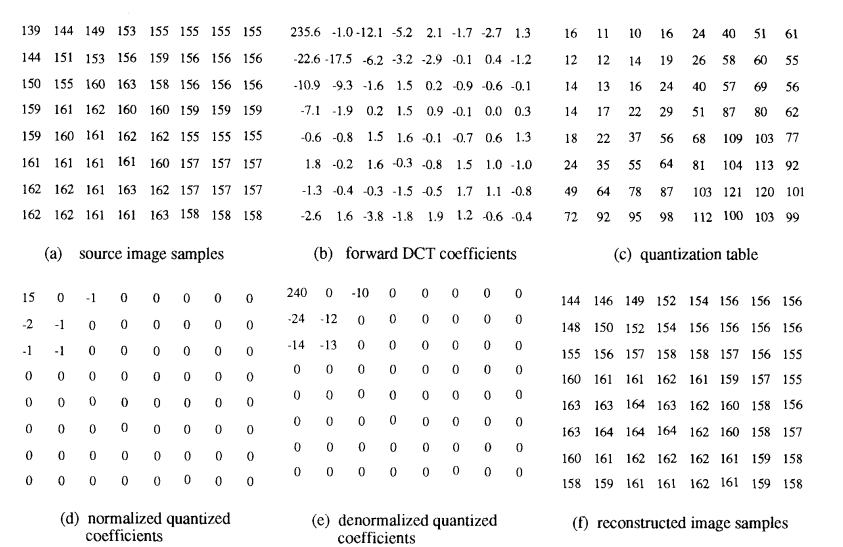
图 10. DCT 和量化示例
图 10© 是 JPEG 标准草案第 1 部分 [2] 信息附录中包含的亮度(灰度)分量的示例量化表。图 10(d) 显示了量化后的 DCT 系数,按其量化表项归一化,如公式 (3) 所指定。在解码器端,这些数字根据公式 (4) 进行“反归一化”,并输入到 IDCT,公式 (2)。最后,图 10(f) 显示了重建的样本值,与 10(a) 中的原始值 remarkably similar。
当然,图 10(d) 中的数字必须经过哈夫曼编码才能传输到解码器。块中要编码的第一个数字是 DC 项,它必须进行差分编码。如果前一个块的量化 DC 项是,例如,12,那么差值是 +3。因此,中间表示是 (2)(3),SIZE=2 且 AMPLITUDE=3。
接下来,编码量化后的 AC 系数。按照 zig-zag 顺序,第一个非零系数是 -2,前面有一个零游程 1。这产生了一个中间表示 (1,2)(-2)。接下来在 zig-zag 顺序中遇到三个连续的非零幅度 -1。这意味着每个前面都有一个长度为零的零游程,中间符号为 (0,1)(-1)。最后一个非零系数是 -1,前面有两个零,表示为 (2,1)(-1)。因为这是最后一个非零系数,所以代表这个 8x8 块的最终符号是 EOB,或 (0,0)。
因此,这个示例 8x8 块的中间符号序列是:
(2)(3), (1,2)(-2), (0,1)(-1), (0,1)(-1), (0,1)(-1), (2,1)(-1), (0,0)
接下来必须分配码本身。对于此示例,将使用 [2] 信息附录中的 VLC(哈夫曼码)。此示例的差分-DC VLC 是:
(2) 011
此示例的 AC 亮度 VLC 是:
(0,0) 1010
(0,1) 00
(1,2) 11011
(2,1) 11100
[2] 中指定的 VLI 与二进制补码表示有关。它们是:
(3)11(3) \quad 11(3)11
(2)01(2) \quad 01(2)01
(−1)0(-1) \quad 0(−1)0
因此,这个 8x8 示例块的比特流如下所示。请注意,表示 64 个系数需要 31 位,实现了略低于 0.5 比特/样本的压缩:
011 11 11011 10 00 0 00 0 00 0 11100 0 1010
(根据上面的码和 VLI 拼接而成:DC: (2)VLC011 + (3)VLI11; AC: (1,2)VLC11011 + (-2)VLI10; (0,1)VLC00 + (-1)VLI0 (三次); (2,1)VLC11100 + (-1)VLI0; EOB: (0,0)VLC1010)
7.4 其他 DCT 顺序编解码器
具有哈夫曼编码的 12 位 DCT 顺序编解码器的结构是前面描述的熵编码方法的直接扩展。量化 DCT 系数可以大 4 位,因此 SIZE 和 AMPLITUDE 信息相应扩展。具有算术编码的 DCT 顺序在 [2] 中有详细描述。
8 DCT 渐进模式
DCT 渐进操作模式由与 DCT 顺序模式相同的 FDCT 和量化步骤(来自第 4 节)组成。关键区别在于每个图像分量在多次扫描中编码,而不是在单次扫描中编码。第一次扫描编码一个粗糙但可识别的图像版本,与总传输时间相比可以快速传输,并通过后续扫描进行细化,直到达到由量化表建立的图像质量水平。
为了实现这一点,需要在量化器输出端、熵编码器输入端之前添加一个图像大小的缓冲存储器。缓冲存储器必须足够大以存储作为量化 DCT 系数的图像,每个系数(如果直接存储)比源图像样本大 3 位。每个 DCT 系数块被量化后,存储在系数缓冲存储器中。然后缓冲的系数在多次扫描中部分编码。
有两种互补的方法可以部分编码一个量化 DCT 系数块。首先,在给定扫描中,只需要编码 zig-zag 序列中指定的系数“频带”。此过程称为“频谱选择”,因为每个频带通常包含占据该 8x8 块空间频率频谱较低或较高部分的系数。其次,当前频带内的系数不需要在给定扫描中编码到其全(量化)精度。在系数首次编码时,可以先编码 N 个最高有效位,其中 N 是可指定的。在后续扫描中,可以 then 编码较低有效位。此过程称为“逐次逼近”。两种过程可以单独使用,或以灵活的组合混合使用。
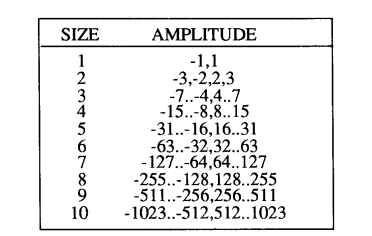
表 3. 基线熵编码符号-2 结构
关于频谱选择和逐次逼近的一些直觉可以从图 11 中获得。量化 DCT 系数信息可以被视为一个矩形,其轴是 DCT 系数(按 zig-zag 顺序)和它们的幅度。频谱选择在一个维度上切片信息,逐次逼近在另一个维度上切片。
9 分层操作模式
分层模式提供图像的多分辨率“金字塔式”编码,每个编码与其相邻编码在水平或垂直维度或两者上的分辨率相差两倍。编码过程可以总结如下:
-
将原始图像按每个维度所需的 2 的倍数进行滤波和降采样。
-
使用前面描述的顺序 DCT、渐进 DCT 或无损编码器之一对这个缩小尺寸的图像进行编码。
-
解码这个缩小尺寸的图像,然后使用接收器必须使用的相同插值滤波器,在水平和/或垂直方向上进行插值和上采样 2 倍。
-
使用这个上采样图像作为此分辨率下原始图像的预测,并使用前面描述的顺序 DCT、渐进 DCT 或无损编码器之一对差分图像进行编码。
-
重复步骤 3) 和 4),直到图像的全分辨率已被编码。
步骤 2) 和 4) 中的编码必须仅使用基于 DCT 的过程、仅使用无损过程,或者使用基于 DCT 的过程并对每个分量进行最终的无损过程。
分层编码在必须通过较低分辨率显示器访问非常高分辨率图像的应用中非常有用。一个例子是以高分辨率扫描和压缩的图像,用于非常高质量的打印机,而该图像也必须在低分辨率 PC 视频屏幕上显示。
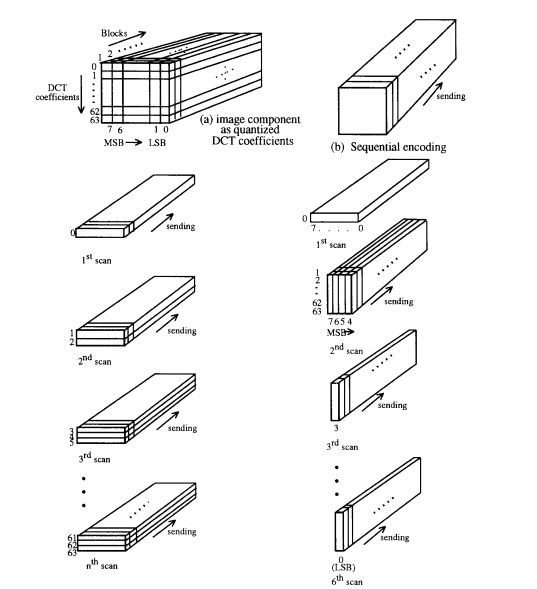
图 11: 渐进编码的频谱选择和逐次逼近方法
10 JPEG 提案的其他方面
拟议标准的一些关键方面只能简要提及。其中最重要的是关于除编码和解码程序之外指定的压缩图像数据的编码表示的点。
最重要的是,指定了一种交换格式语法,确保 JPEG 压缩图像可以在不同的应用环境之间成功交换。该格式以一致的方式为所有操作模式构建。交换格式始终包括用于压缩图像的所有量化和熵编码表。
应用(和应用特定标准)是 JPEG 标准的“用户”。JPEG 标准不要求在一个应用的环境内,在存储或传输过程中,所有甚至任何表都必须与压缩图像数据一起编码。这使应用可以自由地指定默认或引用的表,如果它们被认为是合适的。这也使它们有责任确保在其环境内使用的符合 JPEG 的解码器在适当的时间加载了适当的表,并且当压缩图像被“导出”到应用之外时,适当的表包含在交换格式中。
一些已经采用或已表示有兴趣采用 JPEG 压缩的重要应用包括 Adobe 的打印系统 PostScript 语言 [1]、ISO 办公文档体系结构和交换格式的光栅内容部分 [13]、未来的 CCITT 彩色传真标准以及欧洲 ETSI 图文电视标准 [10]。
11 标准化时间表
JPEG 的 ISO 标准将分为两个部分。第 1 部分 [2] 将指定四种操作模式、为这些模式指定的不同编解码器以及交换格式。它还将包含关于实现指南的大量信息部分。第 2 部分 [3] 将指定符合性测试,以确定编码器实现、解码器实现或交换格式中的 JPEG 压缩图像是否符合第 1 部分的规范。除了引用的 ISO 文档外,JPEG 标准还将作为 CCITT 建议 T.81 发布。
ISO 标准化过程有两个关键的投票阶段:委员会草案(CD)进行投票以决定是否提升为国际标准草案(DIS),而 DIS 进行投票以决定是否提升为国际标准(IS)。CD 投票需要四到六个月的 processing,DIS 投票需要六到九个月的 processing。JPEG 的第 1 部分于 1991 年 11 月开始 DIS 投票,第 2 部分于 1991 年 12 月开始 CD 投票。
尽管不能保证每个阶段的第一次投票都会导致提升到下一个阶段,但 JPEG 在第一次投票中就成功地将 CD 第 1 部分提升为 DIS 第 1 部分。此外,JPEG 的 DIS 第 1 部分自 JPEG 最终工作草案(WD)[14] 以来没有经过任何技术更改(除了一些小的更正)。因此,第 1 部分从最终 WD 到 CD,再到 DIS 保持不变。如果一切顺利,第 1 部分应在 1992 年年中获得作为 IS 的最终批准,第 2 部分大约九个月后获得最终 IS 批准。
12 结论
新兴的 JPEG 连续色调图像压缩标准并非万能药,不能解决在数字图像完全集成到所有最终将受益于它们的应用之前必须解决的无数问题。例如,如果两个应用因为使用不兼容的颜色空间、纵横比、尺寸等而无法交换未压缩图像,那么通用的压缩方法也无济于事。
然而,许多应用因为存储或传输成本、因为争论使用哪种(非标准)压缩方法、或者因为 VLSI 编解码器由于产量低而太昂贵而“停滞不前”。对于这些应用,JPEG 委员会成员所进行的 thorough 技术评估、测试、选择、验证和文档工作预计将很快产生一个经得起质量和时间考验的 approved 国际标准。随着 diverse 成像应用越来越多地在开放网络计算系统上实现,委员会成功的最终衡量标准将是当 JPEG 压缩的数字图像开始被视为甚至被视为“只是另一种数据类型”时,就像今天的文本和图形一样。
致谢
以下长期 JPEG 核心成员花费了无数时间(通常是在他们的“本职工作”之外)使这项国际合作努力取得成功。每个人都对 JPEG 提案做出了 specific substantive 贡献:Aharon Gill (Zoran, Israel), Eric Hamilton (C-Cube, USA), Alain Leger (CCETT, France), Adriana Leitenberg (Storm, USA), Herbert Lohscheller (ANT, Germany), Joan Mitchell (IBM, USA), Michael Nier (Kodak, USA), Takao Omachi (NEC, Japan), William Pennebaker (IBM, USA), Henning Poulsen (KTAS, Denmark), and Jorgen Vaaben (AutoGraph, Denmark)。感谢 Hiroshi Yasuda (NTT, Japan)(JPEG 诞生的 JTC1/SC2/WG8 的召集人)、Istvan Sebestyen (Siemens, Germany)(CCITT SGVIII 的特派报告员)和 Graham Hudson (British Telecom U.K.)(前 JPEG 主席和后来成为 JPEG 的努力的创始人)的领导 efforts。作者遗憾的是篇幅不允许表彰许多其他为 JPEG 工作做出贡献的个人。
感谢 Eastman Kodak 的 Majid Rabbani 提供了第 7.3 节中的示例。
作者在 JPEG 中的角色得到了数字设备公司的大力支持。