Wan系列模型解析--详细架构图
文章目录
- Wan T2V
- Wan I2V
Wan T2V
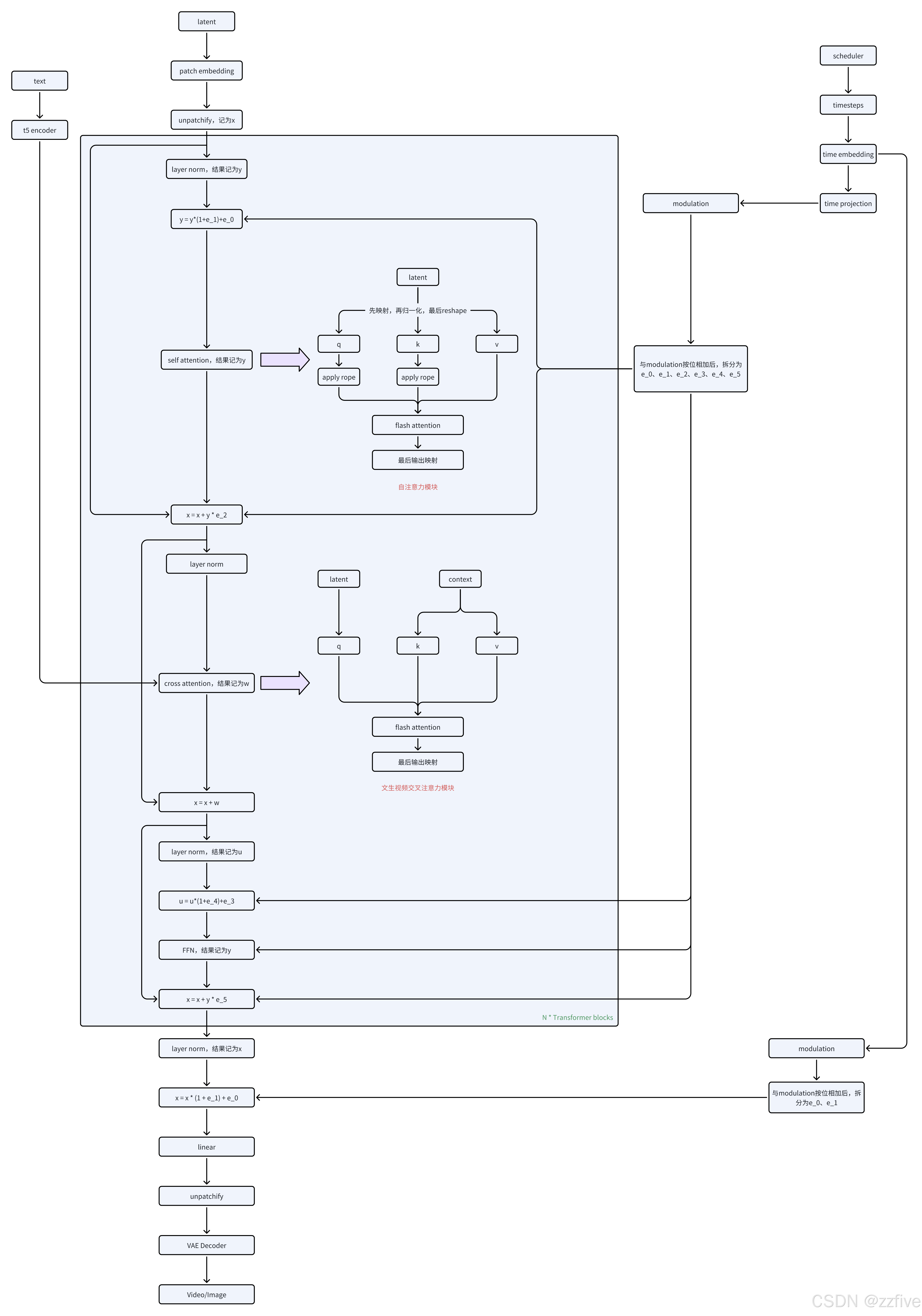
注意点:
- 只有自注意力中引用了rope,交叉注意力中并没有使用
- 时间嵌入的转换和应用很特殊
- 先和注意力模块中的调制块modulation按位相加,再拆分为6个的值,充当类似层归一化中缩放因子和偏移量的作用,因为Wan中的LayerNorm是将elementwise_affine设置为了False,即LayerNorm层内部是没有学习缩放因子和偏移量的
- 最后在head中也与其中的调制块modulation按位相加,然后拆分为2个值,也是起缩放因子和偏移量的作用
Wan I2V
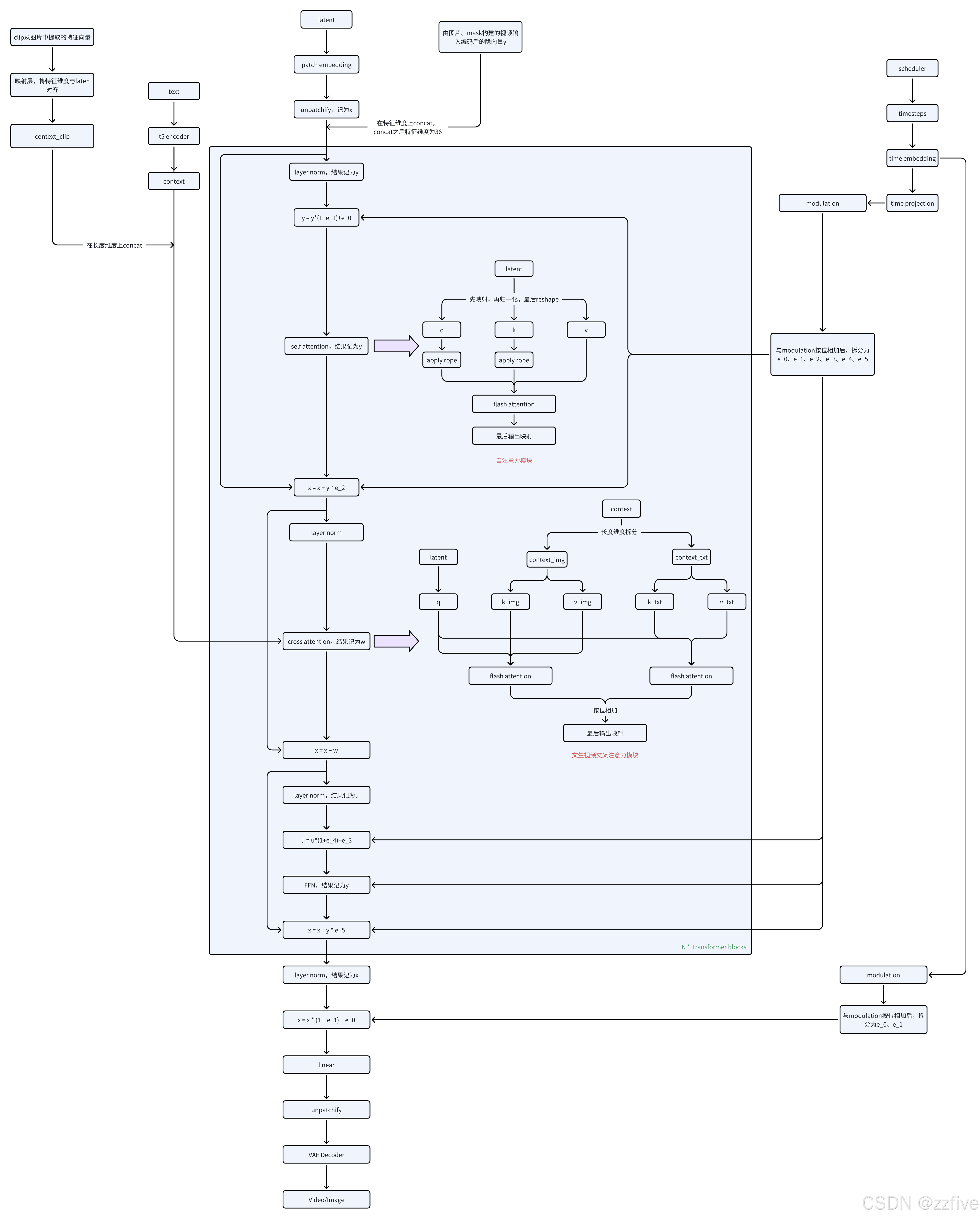
注意点:
- 相较于T2V,I2V的输入多了两项,分别是clip从图片中提取的图片特征和图片、mask组成的视频输入y
- clip提取的图片特征和t5提取的文本特征在长度上concat
- 视频输入y是经过VAE编码的隐向量,会直接与初始化的时空尺寸相同的noise在特征维度concat,故是的I2V任务的Wan模型的输入维度为36,而T2V任务的Wan模型的输入维度为16
- 包含图片信息和文本信息的context会在交叉注意力模块中会先拆开,然后隐向量单独与context_img、context_txt分别进行注意力计算,然后按位相加