基于随机变量的自适应螺旋飞行麻雀搜索算法(ASFSSA)优化BP神经网络,附完整完整代码
3. 麻雀搜索算法
麻雀群体分为两个角色,即发现者和跟随者。它们有三个行为:觅食、跟随和侦察。发现者的任务是寻找食物并告知跟随者食物的位置。因此,发现者需要在一个大范围内搜索,而跟随者的觅食范围通常较小。这是更新发现者位置的公式:
X i , j t + 1 = { X i , j t ⋅ exp ( − t α ⋅ M ) , 如果 R 2 < S T , X i , j t + Q ⋅ L , 如果 R 2 ≥ S T . (1) X_{i,j}^{t+1} = \left\{ \begin{array}{ll} X_{i,j}^{t} \cdot \exp\left(\frac{-t}{\alpha \cdot M}\right), & \text{如果 } R_2 < ST, \\ X_{i,j}^{t} + Q \cdot L, & \text{如果 } R_2 \geq ST. \end{array} \right.\tag1 Xi,jt+1={Xi,jt⋅exp(α⋅M−t),Xi,jt+Q⋅L,如果 R2<ST,如果 R2≥ST.(1)
在公式(1)中,(t) 和 (M) 分别表示当前迭代次数和最大迭代次数。(X_{i,j}) 表示第 (i) 只麻雀的位置,(j) 是代表维度。在上述公式中,```markdown
R 2 R_2 R2 和 R i R_i Ri 都是从 0 到 1 的随机数(不为零), R 2 R_2 R2 是一个重要的参数,控制个体的飞行行为。 S T ST ST( S T ∈ [ 0.5 , 1 ] ST \in [0.5, 1] ST∈[0.5,1])是一个安全阈值,是衡量发现者位置是否安全的重要参数。 L L L 是一个 1 × D 1 \times D 1×D 矩阵,所有元素均为 1。如果 R 2 < S T R_2 < ST R2<ST,这意味着当前位置暂时安全,周围环境中没有捕食者,发现者可以在大范围内搜索食物。如果 R 2 ≥ S T R_2 \geq ST R2≥ST,这意味着捕食者的踪迹在当前位置被发现,发现者需要此时去其他安全区域进行觅食活动。
跟随者的位置更新如下:
X i , j t + 1 = { Q ⋅ exp ( ∣ X worst t − X i , j t ∣ r 2 ) , 如果 i ≤ n 2 , ∣ X i , j t − X p t ∣ ⋅ A ∗ ⋅ L , 否则 . (2) X_{i,j}^{t+1} = \left\{ \begin{array}{ll} Q \cdot \exp\left(\frac{|X_{\text{worst}}^t - X_{i,j}^t|}{r^2}\right), & \text{如果 } i \leq \frac{n}{2}, \\ |X_{i,j}^t - X_{\text{p}}^t| \cdot A^* \cdot L, & \text{否则}. \end{array} \right.\tag2 Xi,jt+1={Q⋅exp(r2∣Xworstt−Xi,jt∣),∣Xi,jt−Xpt∣⋅A∗⋅L,如果 i≤2n,否则.(2)
在公式 (2) 中, X p t + 1 X_{\text{p}}^{t+1} Xpt+1 指的是发现者在 t + 1 t+1 t+1 次迭代中所占据的最佳位置( t + 1 t+1 t+1 次迭代尚未结束)和 X worst t X_{\text{worst}}^t Xworstt 代表第 t t t 次迭代中群体所占据的最差位置。 A A A 是一个 1 × D 1 \times D 1×D 矩阵,矩阵中的元素随机分配值为 1 或 -1,且 A ∗ = A T ( A A T ) − 1 A^* = A^T(AA^T)^{-1} A∗=AT(AAT)−1。如果 i > n / 2 i > n/2 i>n/2,这意味着当前跟随者是整个群体的一部分并且没有食物。在这种情况下,跟随者需要去其他地方寻找食物。否则,跟随者将跟随发现者的步伐。
当意识到危险时,麻雀群体将表现出反捕食行为:
X i , j t + 1 = { X best t + β ⋅ ∣ X i , j t − X best t ∣ , 如果 f i ≠ f g , X i , j t + K ⋅ ( ∣ X i , j t − X worst t ∣ ( f i − f worst ) + ϵ ) , 如果 f i = f g . (3) X_{i,j}^{t+1} = \left\{ \begin{array}{ll} X_{\text{best}}^t + \beta \cdot |X_{i,j}^t - X_{\text{best}}^t|, & \text{如果 } f_i \neq f_g, \\ X_{i,j}^t + K \cdot \left(\frac{|X_{i,j}^t - X_{\text{worst}}^t|}{(f_i - f_{\text{worst}}) + \epsilon}\right), & \text{如果 } f_i = f_g. \end{array} \right.\tag3 Xi,jt+1={Xbestt+β⋅∣Xi,jt−Xbestt∣,Xi,jt+K⋅((fi−fworst)+ϵ∣Xi,jt−Xworstt∣),如果 fi=fg,如果 fi=fg.(3)
在公式 (3) 中, X best t X_{\text{best}}^t Xbestt 是在第 t t t 次迭代中获得的全局最优解。上述公式中, β \beta β、 K K K 和 ϵ \epsilon ϵ 是公式中的步长参数。 β \beta β 是一个服从标准正态分布的随机数,用于控制步长大小。 K K K 是从 1 到 1 的任意随机数,表示个体麻雀移动的方向, ϵ \epsilon ϵ 也是一个步长参数,是一个相对较小的常数,其功能是防止分母为零。 f i f_i fi 表示第 i i i 个个体的适应度值, f g f_g fg 和 f worst f_{\text{worst}} fworst 分别表示当前迭代中最佳适应度值和最差适应度值。
如果 f i > f g f_i > f_g fi>fg,则表示个体位于种群的边缘,容易被自然敌人捕食。如果 f i = f g f_i = f_g fi=fg,则表示个体位于种群的中心。此时,麻雀需要靠近其他个体以减少被捕食的概率。
4. 基于随机变量的自适应螺旋飞行麻雀搜索算法
4.1 基于随机变量的帐篷混沌映射
由于 SSA 具有大随机性的缩短问题,因此决定引入有序和均匀的帐篷映射来改进它。许多学者已经应用帐篷映射来解决优化问题 [13]。然而,帐篷映射并不十分稳定。为了减少这种影响,基于随机变量的帐篷映射是一种好方法。因此,在本文中,引入基于随机变量的帐篷映射策略来改进 SSA 的初始化,从而提高种群的初始化更加有序,增强算法的可控性。其具体公式如下:
z i + 1 = { 2 z i + rand ( 0 , 1 ) × 1 N , 0 ≤ z i ≤ 1 2 , 2 ( 1 − z i ) + rand ( 0 , 1 ) × 1 N , 1 2 ≤ z i ≤ 1. (4) z_{i+1} = \left\{ \begin{array}{ll} 2z_i + \text{rand}(0, 1) \times \frac{1}{N}, & 0 \leq z_i \leq \frac{1}{2}, \\ 2(1 - z_i) + \text{rand}(0, 1) \times \frac{1}{N}, & \frac{1}{2} \leq z_i \leq 1. \end{array} \right.\tag4 zi+1={2zi+rand(0,1)×N1,2(1−zi)+rand(0,1)×N1,0≤zi≤21,21≤zi≤1.(4)
帐篷映射后的表达式为:
z i + 1 = ( 2 z i ) mod 1 + rand ( 0 , 1 ) × 1 N . (5) z_{i+1} = (2z_i) \text{mod} 1 + \text{rand}(0, 1) \times \frac{1}{N}.\tag5 zi+1=(2zi)mod1+rand(0,1)×N1.(5)
在公式 (5) 中, N N N 是混沌映射中粒子的数量。
根据帐篷映射的特性,生成混沌序列以生成搜索域中的序列如下:
- 随机生成初始值 z 0 z_0 z0 在 (0, 1) 中,并令 i = 1 i = 1 i=1。
- 使用公式 (5) 执行迭代以生成 z z z 序列,并且 i i i 增加 1。
- 如果迭代次数达到最大值,则停止,并存储生成的 z z z 序列。
4.2 自适应惯性权重
惯性权重策略在粒子群优化算法中很常见 [14]。通常,粒子通过自适应地平衡局部最优和全局最优之间的陷阱来减少算法陷入局部最优的可能性。受此启发,本文增加了惯性权重 ω \omega ω,其随麻雀优化算法中麻雀数量的变化而变化。在算法的初始阶段,它削弱了随机初始化的影响并平衡了莱维飞行机制,从而增强了全局搜索能力,提高了算法的收敛速度。基于麻雀的特性,自适应权重的公式如下:
ω ( t ) = 0.2 cos ( π 1 − t iter max ) (6) \omega(t) = 0.2 \cos\left(\frac{\pi}{1 - \frac{t}{\text{iter}_{\text{max}}}}\right)\tag6 ω(t)=0.2cos(1−itermaxtπ)(6)
公式 (6) 的意义在于, ω \omega ω 在 [0, 1] 之间具有非线性变化的特性。根据余弦函数的特性,算法开始时权重值较小,但优化速度较快,后期权重值较大,但变化速度较慢,因此算法的收敛特性得以平衡。改进后的发现者位置更新如下:
X i , j t + 1 = { w ( t ) ⋅ X i , j t ⋅ exp ( − i α ⋅ iter max ) , 如果 R 2 < S T , w ( t ) ⋅ X i , j t + Q ⋅ L , 如果 R 2 ≥ S T . (7) X_{i,j}^{t+1} = \left\{ \begin{array}{ll} w(t) \cdot X_{i,j}^t \cdot \exp\left(\frac{-i}{\alpha \cdot \text{iter}_{\text{max}}}\right), & \text{如果 } R_2 < ST, \\ w(t) \cdot X_{i,j}^t + Q \cdot L, & \text{如果 } R_2 \geq ST. \end{array} \right.\tag7 Xi,jt+1={w(t)⋅Xi,jt⋅exp(α⋅itermax−i),w(t)⋅Xi,jt+Q⋅L,如果 R2<ST,如果 R2≥ST.(7)
通过引入自适应权重,动态调整麻雀的位置变化,不同指导模式下发现者在不同时间的搜索更加灵活。随着迭代次数的增加,个体麻雀向最优位置收敛,较大的权重使个体移动更快,从而提高了算法的收敛速度。
4.3 莱维飞行机制
在 SSA 中,种群中角色较少,相同的角色更新位置公式相同,这将导致多个个体在相同的最优位置。过高的解重复率将降低算法的效率,这不利于算法的优化。由于发现者具有广泛的搜索范围和全局性,引入自适应权重策略可以有效提高收敛效果。然而,在面对高维复杂问题时,仍有可能陷入局部最优。因此,引入莱维飞行策略以提高算法解的随机性,从而丰富种群位置的多样性。这也可以有效提高算法的搜索效率。
莱维飞行遵循莱维分布。图 1 显示了莱维分布的原理。莱维分布通常用于模拟 [17, 18]。计算步长的公式如下:
s = μ ∣ v ∣ 1 / γ , s = \frac{\mu}{|v|^{1/\gamma}}, s=∣v∣1/γμ,
μ ∼ N ( 0 , σ 2 ) , \mu \sim N(0, \sigma^2), μ∼N(0,σ2),
v ∼ N ( 0 , σ v 2 ) . v \sim N(0, \sigma_v^2). v∼N(0,σv2).
σ μ = { Γ ( 1 + γ ) sin ( π γ / 2 ) Γ [ ( γ + 1 ) / 2 ] ⋅ 2 ( γ + 1 ) / 2 , 如果 γ ≠ 1 , (9) \sigma_\mu = \left\{ \begin{array}{ll} \frac{\Gamma(1 + \gamma)\sin(\pi\gamma/2)}{\Gamma[(\gamma + 1)/2] \cdot 2^{(\gamma + 1)/2}}, & \text{如果 } \gamma \neq 1, \end{array} \right.\tag9 σμ={Γ[(γ+1)/2]⋅2(γ+1)/2Γ(1+γ)sin(πγ/2),如果 γ=1,(9)
其中, σ μ = 1 \sigma_\mu = 1 σμ=1, γ \gamma γ 通常为 1.5。
莱维飞行策略的引入使麻雀在这一阶段更加灵活,也可以使其他个体在不受局部极值约束的情况下找到更好的位置。因此,莱维飞行机制和自适应权重的结合在一定程度上平衡了搜索方法,并且通过莱维飞行机制获得的每个解的质量得到了很大程度的提高,从而大大提高了算法的搜索能力。
4.4 可变螺旋搜索策略
跟随者根据发现者的位置更新动态,这导致它们在搜索过程中出现盲目性和单一性。受鲸鱼算法 [19, 20] 中螺旋操作的启发,引入可变螺旋位置更新策略,使位置更新更加灵活,开发出多种路径以进行位置更新,并平衡算法的全局和局部搜索能力。螺旋搜索图如图 2 所示。
在后续位置更新过程中,螺旋路径不能是固定形状,这导致无序搜索方法和可能陷入局部最优。
提出了一种自适应螺旋飞行麻雀搜索算法。最初,种群通过基于随机变量的帐篷混沌映射初始化,为发现者的优化提供适当的准备。然后,引入自适应权重和莱维飞行策略,使发现者的位置更新方法更加广泛和灵活,然后提出了一种可变螺旋搜索。该策略使跟随者的搜索更加详细,避免了早熟现象,并加快了算法的优化速度。
具体实现步骤如下:
步骤 1:初始化麻雀种群参数,例如,总种群 pop,发现者 pNum,迭代次数 iter,以及解的精度 e。
步骤 2:使用帐篷映射初始化种群个体的位置,并生成 pop 只麻雀个体。
步骤 3:使用相关函数计算每个种群个体的适应度值 f i f_i fi,并找到最大适应度值 f g f_g fg 和最小适应度值 f w f_w fw。
步骤 4:根据适应度值对种群进行排序。
步骤 5:选择适应度值最高的 pNum 个个体作为发现者,其余为跟随者,并使用公式 (7) 和 (8) 并添加策略来更新发现者的位置。
步骤 6:使用公式 (10) 更新 pop 只跟随者的位置。
步骤 7:使用公式 (3) 更新意识到危险的麻雀的位置。
步骤 8:完成一次迭代后,重新计算每个个体的适应度值 f i f_i fi,并更新最大适应度值 f g f_g fg,最小适应度值 f w f_w fw 和相应的位置。
步骤 9:判断算法是否达到最大迭代次数或解的精度。如果达到,优化结果将输出;否则,将返回步骤 4。
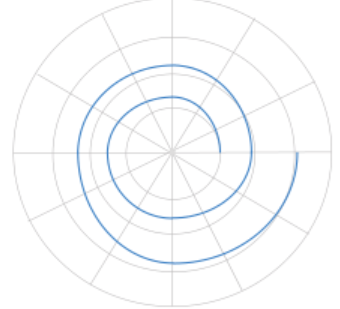
图 2 显示了螺旋搜索的示意图。
参数 z z z 根据迭代次数变化,由基于 e e e 的指数函数组成。螺旋的大小和振幅根据余弦函数的性质动态调整。 k k k 是变化系数。根据每个函数的优化特性,为了使算法具有合适的搜索范围, k = 5 k = 5 k=5。 L L L 是一个均匀分布的随机数 [-1, 1]。随着跟随者位置更新范围从大到小,早期阶段发现更多优质位置,后期优化减少了算法的空闲时间,从而提高了算法的全局最优搜索性能。在后期,根据螺旋特性,算法的优化精度在一定程度上得到了提高。
5、ASFSSA优化BP神经网络
BP(反向传播)算法是一种经典的多层前馈神经网络训练算法,由Rumelhart, Hinton和Williams在1986年提出。该算法利用梯度下降法来最小化网络输出与期望输出之间的误差,通过反向传播误差来更新网络中的权重和偏置。以下是BP算法的详细叙述:
5.1 前向传播
在前向传播阶段,输入数据从输入层经过隐藏层传递到输出层,每一层的输出作为下一层的输入。对于每一层的每个神经元,其输出计算如下:
- 输入层:直接输入数据。
- 隐藏层和输出层:
a j ( l ) = f ( ∑ i = 1 n l − 1 w i j ( l ) a i ( l − 1 ) + b j ( l ) ) a_j^{(l)} = f\left(\sum_{i=1}^{n_{l-1}} w_{ij}^{(l)} a_i^{(l-1)} + b_j^{(l)}\right) aj(l)=f(i=1∑nl−1wij(l)ai(l−1)+bj(l))
其中, a j ( l ) a_j^{(l)} aj(l) 是第 l l l 层第 j j j 个神经元的激活值, w i j ( l ) w_{ij}^{(l)} wij(l) 是连接第 l − 1 l-1 l−1 层第 i i i 个神经元和第 l l l 层第 j j j 个神经元的权重, b j ( l ) b_j^{(l)} bj(l) 是第 l l l 层第 j j j 个神经元的偏置, f f f 是激活函数(如sigmoid、tanh或ReLU)。
5.2.计算误差
在输出层,计算网络输出与期望输出之间的误差,通常使用均方误差(MSE)作为损失函数:
E = 1 2 ∑ k = 1 m ( d k − o k ) 2 E = \frac{1}{2} \sum_{k=1}^{m} (d_k - o_k)^2 E=21k=1∑m(dk−ok)2
其中, d k d_k dk 是第 k k k 个样本的期望输出, o k o_k ok 是第 k k k 个样本的实际输出, m m m 是样本总数。
5.3 反向传播
反向传播阶段的目标是通过计算损失函数关于网络参数(权重和偏置)的梯度,并利用这些梯度来更新参数,以减少误差。梯度计算如下:
-
输出层:
δ j ( L ) = ( o j − d j ) f ′ ( z j ( L ) ) \delta_j^{(L)} = (o_j - d_j) f'(z_j^{(L)}) δj(L)=(oj−dj)f′(zj(L))
其中, δ j ( L ) \delta_j^{(L)} δj(L) 是第 L L L 层(输出层)第 j j j 个神经元的误差项, o j o_j oj 是实际输出, d j d_j dj 是期望输出, f ′ f' f′ 是激活函数的导数。 -
隐藏层:
δ j ( l ) = ( ∑ k = 1 n l + 1 w k j ( l + 1 ) δ k ( l + 1 ) ) f ′ ( z j ( l ) ) \delta_j^{(l)} = \left(\sum_{k=1}^{n_{l+1}} w_{kj}^{(l+1)} \delta_k^{(l+1)}\right) f'(z_j^{(l)}) δj(l)=(k=1∑nl+1wkj(l+1)δk(l+1))f′(zj(l))
其中, δ j ( l ) \delta_j^{(l)} δj(l) 是第 l l l 层第 j j j 个神经元的误差项。
5.4 参数更新
利用计算得到的梯度,通过梯度下降法更新网络中的权重和偏置:
w i j ( l ) = w i j ( l ) − η δ j ( l ) a i ( l − 1 ) w_{ij}^{(l)} = w_{ij}^{(l)} - \eta \delta_j^{(l)} a_i^{(l-1)} wij(l)=wij(l)−ηδj(l)ai(l−1)
b j ( l ) = b j ( l ) − η δ j ( l ) b_j^{(l)} = b_j^{(l)} - \eta \delta_j^{(l)} bj(l)=bj(l)−ηδj(l)
其中, η \eta η 是学习率,控制更新步长。
5.5. 迭代训练
重复步骤1到4,直到满足停止条件,如达到最大迭代次数或误差低于某个阈值。
BP算法通过不断调整网络参数,使网络能够学习到输入数据与输出结果之间的映射关系,从而实现对数据的预测或分类。
首先,代码开始时关闭警告信息、关闭所有图窗、清空变量和命令行。接着,导入数据集
在数据分析阶段,设定训练集占数据集的比例为70%,输出维度为1,计算样本总数,并对数据进行打乱处理。然后,计算训练集样本数量和输入特征维度。接着,划分训练集和测试集,并对数据进行归一化处理。
在节点个数设置阶段,定义输入层节点数、隐藏层节点数和输出层节点数。然后,构建一个前馈神经网络,并设置训练参数,包括训练次数、目标误差、学习率和关闭训练窗口。
在参数设置阶段,定义目标函数、优化参数个数、优化参数目标下限和上限、种群数量和最大迭代次数。接着,调用优化算法 ASFSSA 进行参数优化。
在优化算法阶段,将最优初始权值赋予网络预测。然后,重新设置网络训练参数以打开训练窗口,并进行网络训练。接着,使用训练好的网络对训练集和测试集进行预测。
在数据反归一化阶段,将预测结果反归一化,得到最终的预测值。接着,计算训练集和测试集的均方根误差(RMSE)。
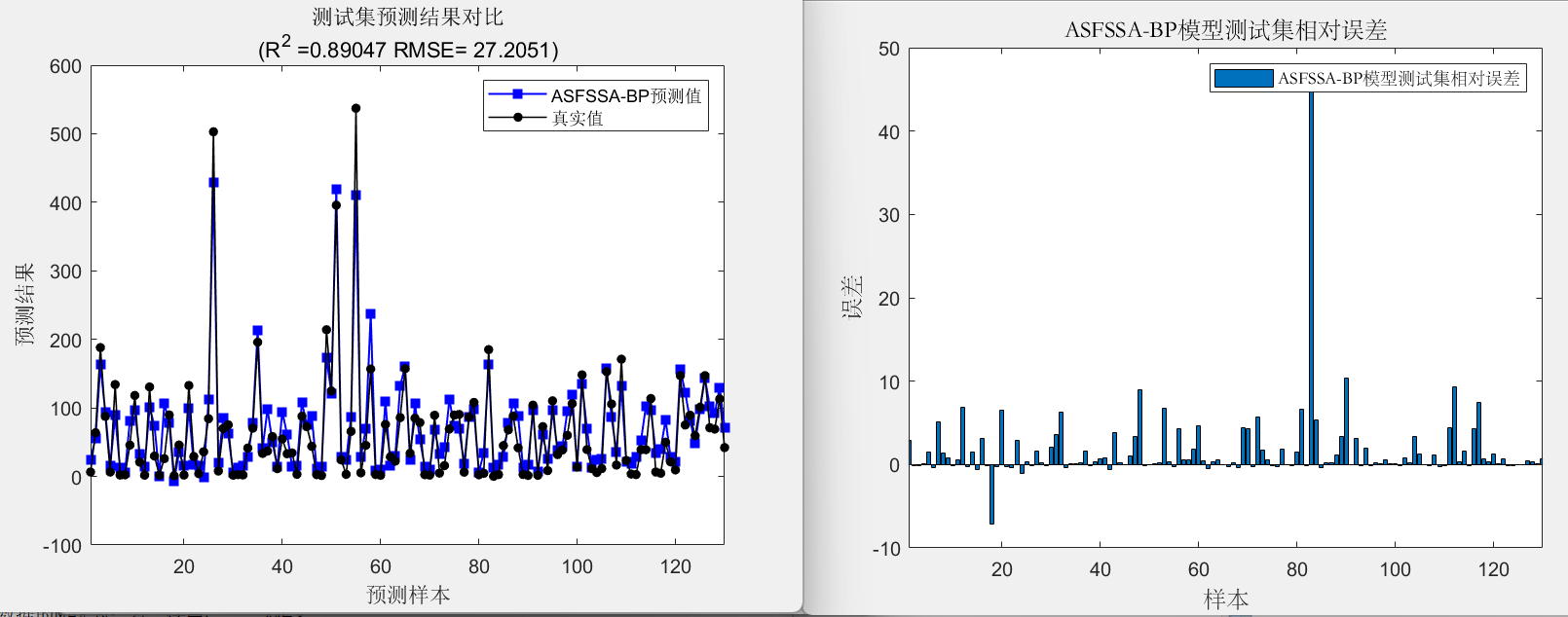
在绘图阶段,计算相关指标,包括 R 2 R^2 R2、平均绝对误差(MAE)和RMSE,并显示结果。然后,绘制优化曲线、训练集和测试集的预测结果对比图、误差图和线性拟合图。
以下是代码中涉及的数学公式:
-
计算训练集样本数量:
num_train_s = round ( num_size × num_samples ) \text{num\_train\_s} = \text{round}(\text{num\_size} \times \text{num\_samples}) num_train_s=round(num_size×num_samples) -
计算输入特征维度:
f _ = size ( res , 2 ) − outdim f\_ = \text{size}(\text{res}, 2) - \text{outdim} f_=size(res,2)−outdim -
计算测试集样本数量:
N = size ( P_test , 2 ) N = \text{size}(\text{P\_test}, 2) N=size(P_test,2) -
计算 R 2 R^2 R2 指标:
R = 1 − norm ( T − T _ s i m ) 2 norm ( T − mean ( T ) ) 2 R = 1 - \frac{\text{norm}(T - T\_sim)^2}{\text{norm}(T - \text{mean}(T))^2} R=1−norm(T−mean(T))2norm(T−T_sim)2 -
计算 MAE 指标:
mae = sum ( abs ( T _ s i m − T ) ) M \text{mae} = \frac{\text{sum}(\text{abs}(T\_sim - T))}{M} mae=Msum(abs(T_sim−T)) -
计算 RMSE 指标:
RMSE = sumsqr ( T _ s i m − T ) M \text{RMSE} = \sqrt{\frac{\text{sumsqr}(T\_sim - T)}{M}} RMSE=Msumsqr(T_sim−T)
最后,代码记录了训练集和测试集的预测结果,并保存了相关数据。
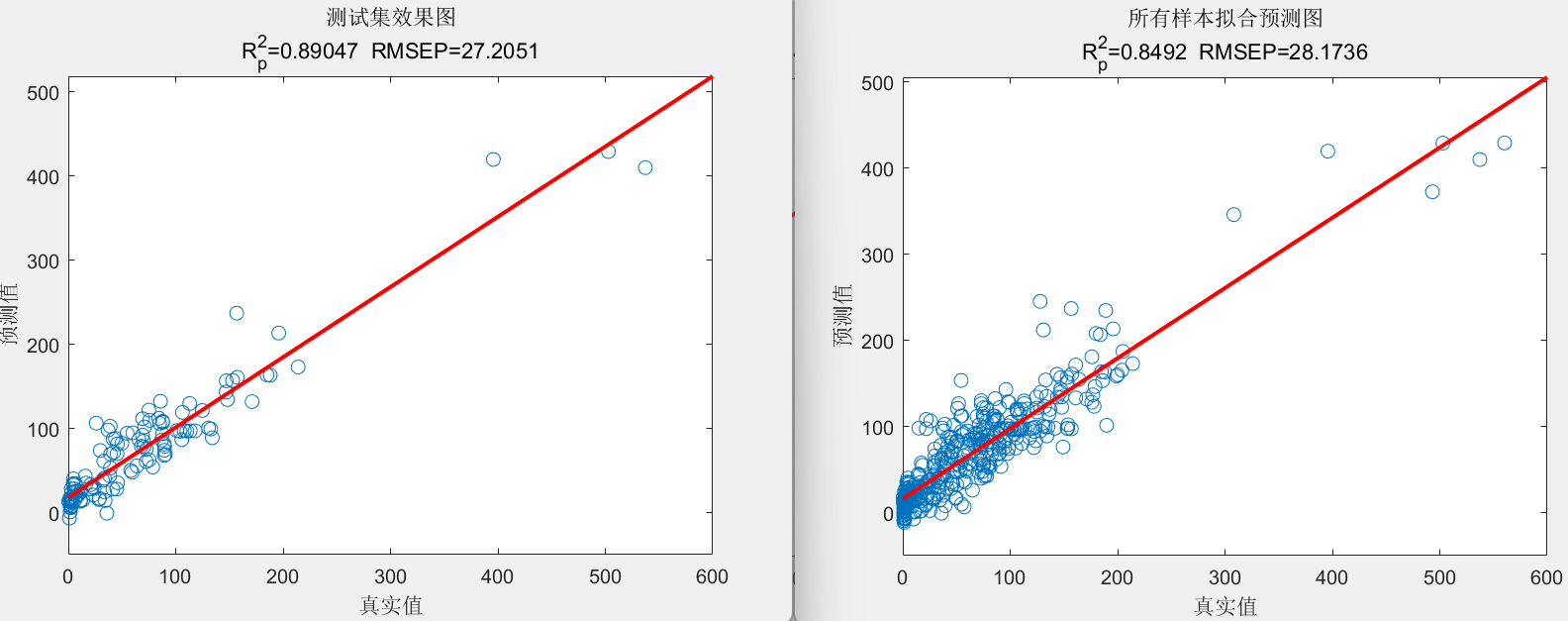
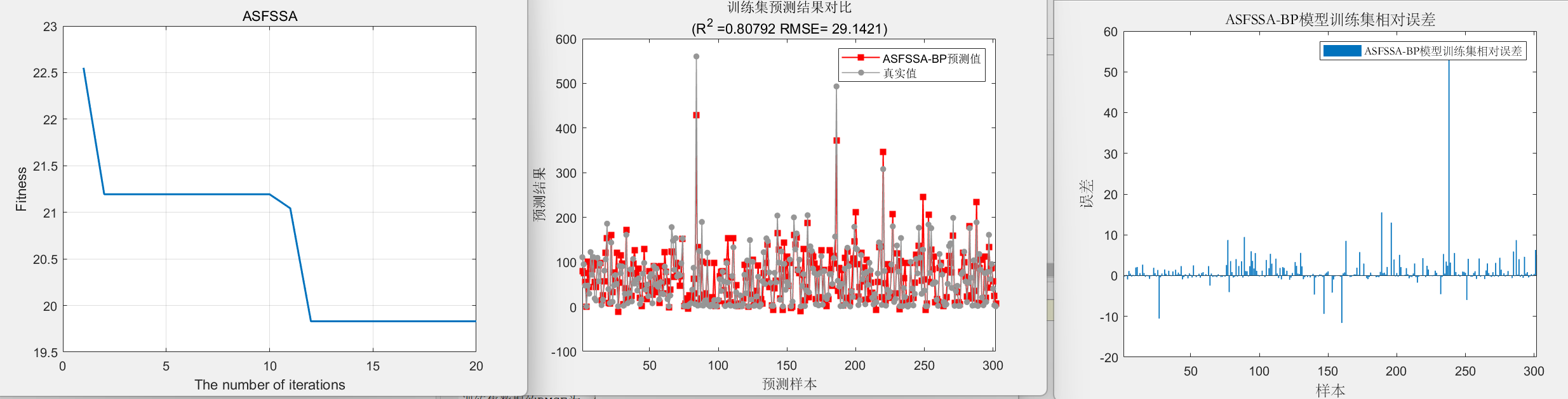
训练集数据的R2为:0.80792
测试集数据的R2为:0.89047
训练集数据的MAE为:20.9069
测试集数据的MAE为:20.211
训练集数据的RMSE为:29.1421
测试集数据的RMSE为:27.2051