第 2 讲:Kafka Topic 与 Partition 基础
课程概述
在第一篇课程中,我们了解了 Kafka 的基本概念和简单的 Producer/Consumer 实现。
本篇课程将深入探讨 Kafka 的核心机制:Topic 和 Partition。
学习目标
通过本课程,您将掌握:
- Topic 和 Partition 的设计原理:理解为什么需要分区,以及分区如何提升性能
- Leader/Follower 机制:掌握 Kafka 如何保证高可用性和数据一致性
- 分区策略:学会如何控制消息在分区间的分布
- 数据存储模型:了解 Kafka 如何在磁盘上组织和存储数据
- 实际操作技能:通过代码示例掌握多分区场景下的生产和消费
为什么学习 Topic 和 Partition?
- 性能优化:理解分区机制有助于设计高吞吐量的应用
- 数据有序性:掌握如何在分布式环境中保证消息顺序
- 故障恢复:了解 Kafka 如何通过副本机制保证数据安全
- 扩展性设计:学会如何设计可水平扩展的消息系统
一、核心概念
1. Topic 与 Partition
Topic(主题)
Topic 是 Kafka 中消息分类的逻辑概念,类似于数据库中的表名或文件系统中的目录。每个 Topic 代表一类消息的集合。
特点:
- 逻辑概念,不直接对应物理存储
- 可以有多个生产者和消费者
- 按业务领域划分(如:用户行为、订单事件、日志数据)
Partition(分区)
Partition 是 Topic 的物理分片,每个分区是一个不可变的有序日志序列。
设计目的:
- 并行处理:多个分区可以并行读写,提升吞吐量
- 水平扩展:分区可以分布在不同的 Broker 上
- 有序保证:单个分区内消息严格有序
Replica(副本)
Replica 是分区的副本,用于数据备份和容错。
副本机制:
- 每个分区可以有多个副本(通常 3 个)
- 副本分布在不同的 Broker 上,避免单点故障
- 一个 Leader 副本 + N 个 Follower 副本
关系总结:
Topic = 多个 Partition,Partition = 多个 Replica
实际案例
假设我们有一个电商系统的 “user-events” Topic:
Topic: user-events
├── Partition 0: [用户登录事件]
├── Partition 1: [用户浏览事件]
└── Partition 2: [用户购买事件]每个 Partition 在 3 个 Broker 上都有副本:
Partition 0: Broker-1(Leader), Broker-2(Follower), Broker-3(Follower)
2. Leader 与 Follower 机制
Leader(领导者)
Leader 是每个分区的主副本,负责处理所有的读写请求。
职责:
- 接收 Producer 的写入请求
- 响应 Consumer 的读取请求
- 维护分区的 Offset 状态
- 向 Follower 发送数据同步
Follower(跟随者)
Follower 是分区的备份副本,主要用于数据冗余和故障恢复。
职责:
- 定期从 Leader 拉取数据进行同步
- 不直接处理客户端请求
- 保持与 Leader 的数据一致性
- 在 Leader 故障时参与新 Leader 选举
ISR(In-Sync Replicas)
ISR 是同步副本集合,包含与 Leader 保持同步的所有副本。
同步条件:
- Follower 必须在规定时间内(
replica.lag.time.max.ms)与 Leader 同步 - 落后太多的 Follower 会被移出 ISR
- 只有 ISR 中的副本才能被选举为新的 Leader
故障切换(Failover)
当 Leader 发生故障时,Kafka 会自动进行故障切换:
选举规则:
- 只考虑 ISR 中的副本
- 优先选择 Offset 最高的副本
- 如果 Offset 相同,选择 Broker ID 最小的
数据一致性保证
时间线: T1 -> T2 -> T3 -> T4T1: Leader 收到消息 A
T2: Leader 写入本地日志
T3: Follower 同步消息 A
T4: Leader 向 Producer 发送 ACK只有当 ISR 中所有副本都确认后,消息才被认为"已提交"
3. 分区策略
Producer 发送消息时,Kafka 需要决定将消息写入哪个分区。这个决策过程称为分区策略。
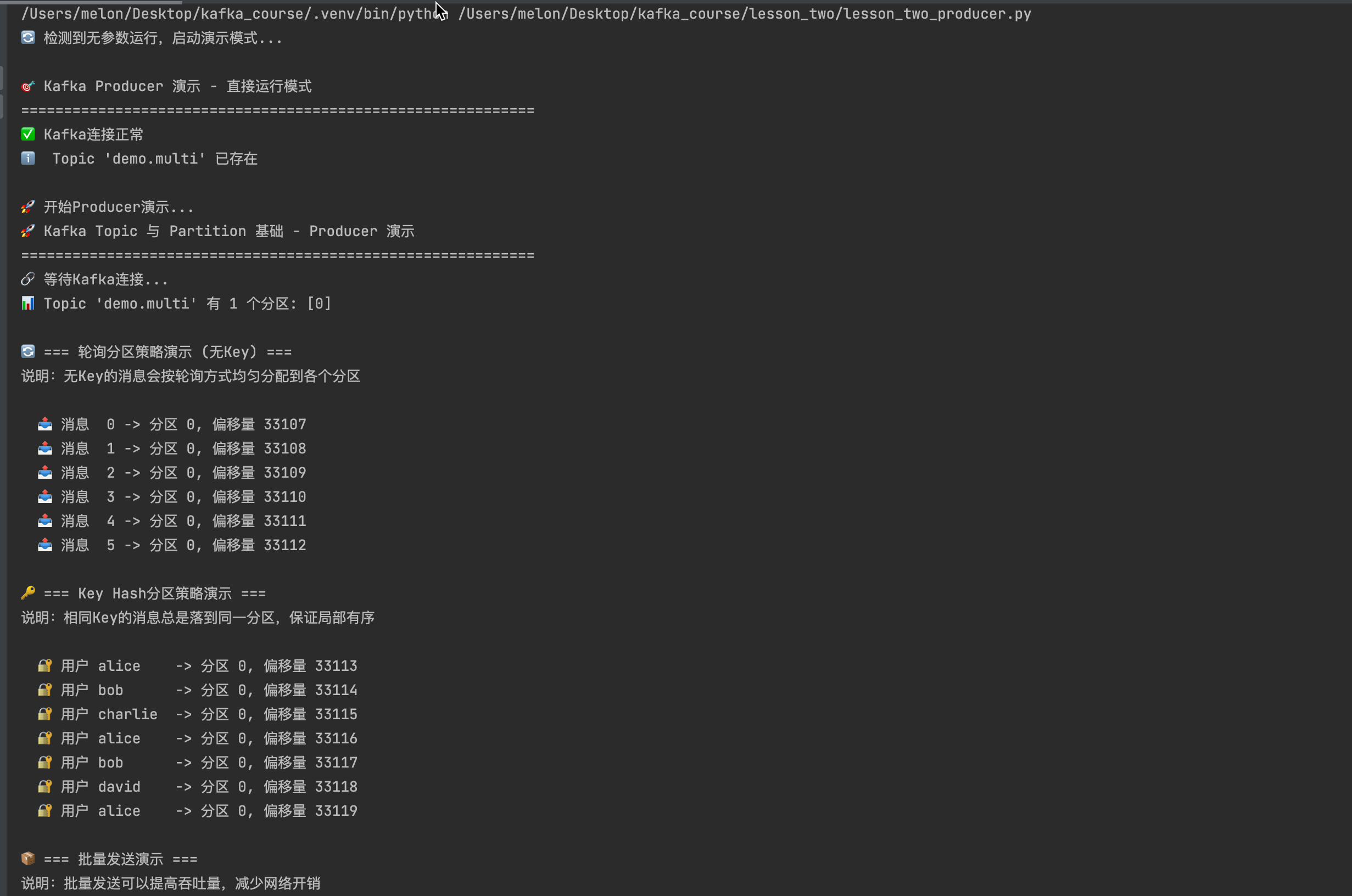
轮询分区(Round-Robin)
适用场景: 消息没有 Key,需要均匀分布负载
# 无 Key 的消息会轮询分配
producer.send("my-topic", value={"data": "message1"}) # -> Partition 0
producer.send("my-topic", value={"data": "message2"}) # -> Partition 1
producer.send("my-topic", value={"data": "message3"}) # -> Partition 2
producer.send("my-topic", value={"data": "message4"}) # -> Partition 0
优点: 负载均衡,充分利用所有分区
缺点: 无法保证消息顺序
Key Hash 分区
适用场景: 需要保证相同业务对象的消息有序
# 相同 Key 的消息总是落到同一分区
producer.send("user-events", key="user_123", value={"action": "login"}) # -> Partition 1
producer.send("user-events", key="user_123", value={"action": "browse"}) # -> Partition 1
producer.send("user-events", key="user_456", value={"action": "login"}) # -> Partition 2
producer.send("user-events", key="user_123", value={"action": "purchase"}) # -> Partition 1
Hash 算法: partition = hash(key) % partition_count
优点: 保证相同 Key 的消息顺序
缺点: 可能导致分区负载不均
自定义分区器
适用场景: 复杂的业务分区逻辑
class RegionPartitioner:def partition(self, key, all_partitions, available_partitions):"""按地区分区"""if key.startswith("beijing"):return 0elif key.startswith("shanghai"): return 1elif key.startswith("guangzhou"):return 2else:return hash(key) % len(all_partitions)# 使用自定义分区器
producer = KafkaProducer(partitioner=RegionPartitioner())
分区策略对比
| 策略 | 负载均衡 | 消息顺序 | 实现复杂度 | 适用场景 |
|---|---|---|---|---|
| 轮询 | ✅ 优秀 | ❌ 无保证 | 🟢 简单 | 日志收集、指标上报 |
| Key Hash | ⚠️ 取决于Key分布 | ✅ 局部有序 | 🟢 简单 | 用户事件、订单处理 |
| 自定义 | ⚠️ 取决于实现 | ⚠️ 取决于实现 | 🔴 复杂 | 地域分片、业务隔离 |
选择建议
- 无序要求 + 高吞吐:选择轮询分区
- 业务对象有序:选择 Key Hash 分区
- 复杂业务逻辑:实现自定义分区器
- 热点数据:考虑 Key 的分布均匀性
4. 数据持久化
Kafka 将消息持久化存储在磁盘上,采用顺序写入的方式保证高性能。理解存储结构对于优化性能和故障排查非常重要。
Segment 文件结构
每个分区的日志由多个 Segment 文件组成,每个 Segment 包含三个文件:
/kafka-logs/demo.multi-0/
├── 00000000000000000000.log # 消息数据文件
├── 00000000000000000000.index # 偏移量索引文件
├── 00000000000000000000.timeindex # 时间戳索引文件
├── 00000000000000000010.log # 下一个 Segment
├── 00000000000000000010.index
└── 00000000000000000010.timeindex
消息存储格式
Kafka 消息在磁盘上的存储格式:
消息1: [长度4字节][CRC32 4字节][魔数1字节][属性1字节][时间戳8字节][Key长度4字节][Key内容][Value长度4字节][Value内容]
消息2: [长度4字节][CRC32 4字节][魔数1字节][属性1字节][时间戳8字节][Key长度4字节][Key内容][Value长度4字节][Value内容]
...
字段说明:
- 长度:整个消息的字节数
- CRC32:消息内容的校验和
- 魔数:版本标识(当前为2)
- 属性:压缩类型、时间戳类型等
- 时间戳:消息创建时间
- Key/Value长度:Key和Value的字节数
文件类型详解
1. .log 文件(消息数据)
- 存储实际的消息内容
- 采用二进制格式,包含消息头和消息体
- 顺序追加写入,不支持修改
2. .index 文件(偏移量索引)
- 建立 Offset 到物理位置的映射
- 稀疏索引,不是每条消息都有索引项
- 加速消息查找,避免全文件扫描
3. .timeindex 文件(时间戳索引)
- 建立时间戳到 Offset 的映射
- 支持按时间查找消息
- 用于日志清理和消息过期
Segment 切分策略
当满足以下任一条件时,Kafka 会创建新的 Segment:
# 服务端配置
log.segment.bytes: 1073741824 # Segment 大小达到 1GB
log.segment.ms: 604800000 # Segment 时间达到 7 天
log.index.size.max.bytes: 10485760 # 索引文件达到 10MB
消息查找过程
当 Consumer 要读取 Offset=100 的消息时:
日志清理策略
Kafka 提供两种日志清理策略:
1. 删除策略(Delete)
log.cleanup.policy: delete
log.retention.hours: 168 # 保留 7 天
log.retention.bytes: -1 # 无大小限制
2. 压缩策略(Compact)
log.cleanup.policy: compact
log.cleaner.enable: true
- 保留每个 Key 的最新值
- 适用于配置数据、用户状态等场景
性能优化原理
Kafka 存储设计的性能优势:
- 顺序 I/O:避免随机磁盘访问,充分利用磁盘带宽
- 页缓存:利用操作系统的页缓存减少磁盘读取
- 零拷贝:使用 sendfile() 系统调用,避免用户空间拷贝
- 批量操作:批量写入和批量读取提升效率
传统方式: 磁盘 -> 内核缓冲区 -> 用户缓冲区 -> Socket缓冲区 -> 网卡
零拷贝: 磁盘 -> 内核缓冲区 -> 网卡 (减少 2 次拷贝)
存储性能调优
# 服务端存储配置优化
log.segment.bytes: 1073741824 # 1GB Segment大小
log.segment.ms: 604800000 # 7天Segment切分
log.index.size.max.bytes: 10485760 # 10MB索引文件大小
log.flush.interval.messages: 10000 # 每10000条消息刷盘
log.flush.interval.ms: 1000 # 每秒刷盘一次
log.retention.bytes: -1 # 无大小限制
log.retention.hours: 168 # 保留7天
磁盘选择建议
- SSD:高吞吐、低延迟场景,如实时数据处理
- HDD:大容量、成本敏感场景,如日志归档
- RAID:避免单点故障,推荐RAID 1或RAID 10
- 分区:将Kafka数据目录放在独立分区,避免其他进程影响
二、系统架构与数据流
1. 整体架构图
2. 消息分区流程图
3. 消费者分区分配图
📌 架构说明:
- 分布式部署:3个Broker节点,每个分区的Leader和Follower分布在不同节点
- 负载均衡:生产者可以向任意Broker发送消息,Kafka自动路由到正确的Leader分区
- 容错设计:每个分区有2个副本,任意1个Broker故障不影响服务
- 消费隔离:不同Consumer Group独立消费,互不影响
- 水平扩展:可以增加Broker节点和Consumer实例来提升性能
三、实战演练
1. 环境准备与Topic创建
环境检查
在开始之前,确保Kafka环境正常运行:
# 检查Kafka服务状态
ps aux | grep kafka# 检查端口监听
netstat -an | grep 9092# 检查Zookeeper状态
echo stat | nc localhost 2181
创建多分区Topic
# 创建一个3分区、2副本的Topic
bin/kafka-topics.sh --create \--bootstrap-server localhost:9092 \--topic demo.multi \--partitions 3 \--replication-factor 2# 查看Topic详情
bin/kafka-topics.sh --describe \--bootstrap-server localhost:9092 \--topic demo.multi
Topic配置优化
# 设置Topic配置
bin/kafka-configs.sh --bootstrap-server localhost:9092 \--entity-type topics \--entity-name demo.multi \--alter \--add-config retention.ms=604800000,cleanup.policy=delete# 查看Topic配置
bin/kafka-configs.sh --bootstrap-server localhost:9092 \--entity-type topics \--entity-name demo.multi \--describe
分区扩展(生产环境谨慎使用)
# 增加分区数量(只能增加,不能减少)
bin/kafka-topics.sh --bootstrap-server localhost:9092 \--topic demo.multi \--alter \--partitions 6# 注意:增加分区会影响消息顺序,需要重启Consumer
预期输出:
Topic: demo.multi PartitionCount: 3 ReplicationFactor: 2Topic: demo.multi Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2Topic: demo.multi Partition: 1 Leader: 2 Replicas: 2,3 Isr: 2,3 Topic: demo.multi Partition: 2 Leader: 3 Replicas: 3,1 Isr: 3,1
2. 高级Producer实现
基于课程提供的 common.py,我们创建一个功能完整的生产者。现在所有代码都支持直接运行,无需复杂配置:
直接运行演示
# 最简单的运行方式(推荐新手)
python lesson_two_producer.py# 或者使用一键演示脚本
python quick_start.py
python run_demo.py
完整代码实现
# lesson_two_producer.py
import sys
import time
import random
from datetime import datetime
from lesson_two.common import make_producer, wait_kafka, partitions_of, close_safelydef demo_partition_strategies():"""演示不同的分区策略"""print("🚀 等待Kafka连接...")wait_kafka()# 创建生产者producer = make_producer(acks="all", # 等待所有副本确认linger_ms=50, # 批量发送延迟compression_type="gzip" # 启用压缩)topic = "demo.multi"try:# 检查分区数量partitions = partitions_of(producer, topic)print(f"📊 Topic '{topic}' 有 {len(partitions)} 个分区: {sorted(partitions)}")# 1. 轮询分区策略演示print("\n🔄 轮询分区策略 (无Key):")for i in range(6):message = {"id": i,"type": "round_robin","timestamp": datetime.now().isoformat(),"data": f"轮询消息 #{i}"}future = producer.send(topic, value=message)record = future.get(timeout=10)print(f" 消息 {i} -> 分区 {record.partition}, 偏移量 {record.offset}")time.sleep(0.1)# 2. Key Hash分区策略演示 print("\n🔑 Key Hash分区策略:")users = ["alice", "bob", "charlie", "alice", "bob", "david"]for i, user in enumerate(users):message = {"user_id": user,"type": "key_hash", "action": f"action_{i}","timestamp": datetime.now().isoformat()}future = producer.send(topic, key=user, value=message)record = future.get(timeout=10)print(f" 用户 {user} -> 分区 {record.partition}, 偏移量 {record.offset}")time.sleep(0.1)# 3. 批量发送演示print("\n📦 批量发送演示:")futures = []batch_size = 10for i in range(batch_size):message = {"batch_id": 1,"item_id": i,"type": "batch","value": random.randint(1, 100)}future = producer.send(topic, value=message)futures.append(future)# 等待所有消息发送完成producer.flush(timeout=30)# 检查结果for i, future in enumerate(futures):record = future.get()print(f" 批量消息 {i} -> 分区 {record.partition}")except Exception as e:print(f"❌ 发送失败: {e}")return Falsefinally:close_safely(producer)print("✅ 生产者演示完成!")return Trueif __name__ == "__main__":demo_partition_strategies()
Producer配置调优
# 高性能Producer配置
producer = make_producer(acks="1", # 只等待Leader确认,提升性能linger_ms=5, # 减少批量等待时间batch_size=64*1024, # 64KB批量大小compression_type="lz4", # 使用LZ4压缩(更快)max_in_flight_requests_per_connection=5, # 并发请求数retries=3, # 重试次数retry_backoff_ms=100 # 重试间隔
)# 高可靠性Producer配置
producer = make_producer(acks="all", # 等待所有副本确认enable_idempotence=True, # 启用幂等性max_in_flight_requests_per_connection=1, # 保证顺序retries=10, # 更多重试retry_backoff_ms=1000 # 更长重试间隔
)
3. 高级Consumer实现
现在Consumer也支持直接运行,提供完整的消息消费和统计功能:
直接运行演示
# 最简单的运行方式(推荐新手)
python lesson_two_consumer.py# 自定义参数运行
python lesson_two_consumer.py demo.multi analytics_group --from-beginning
python lesson_two_consumer.py demo.multi analytics_group --max-messages 50
完整代码实现
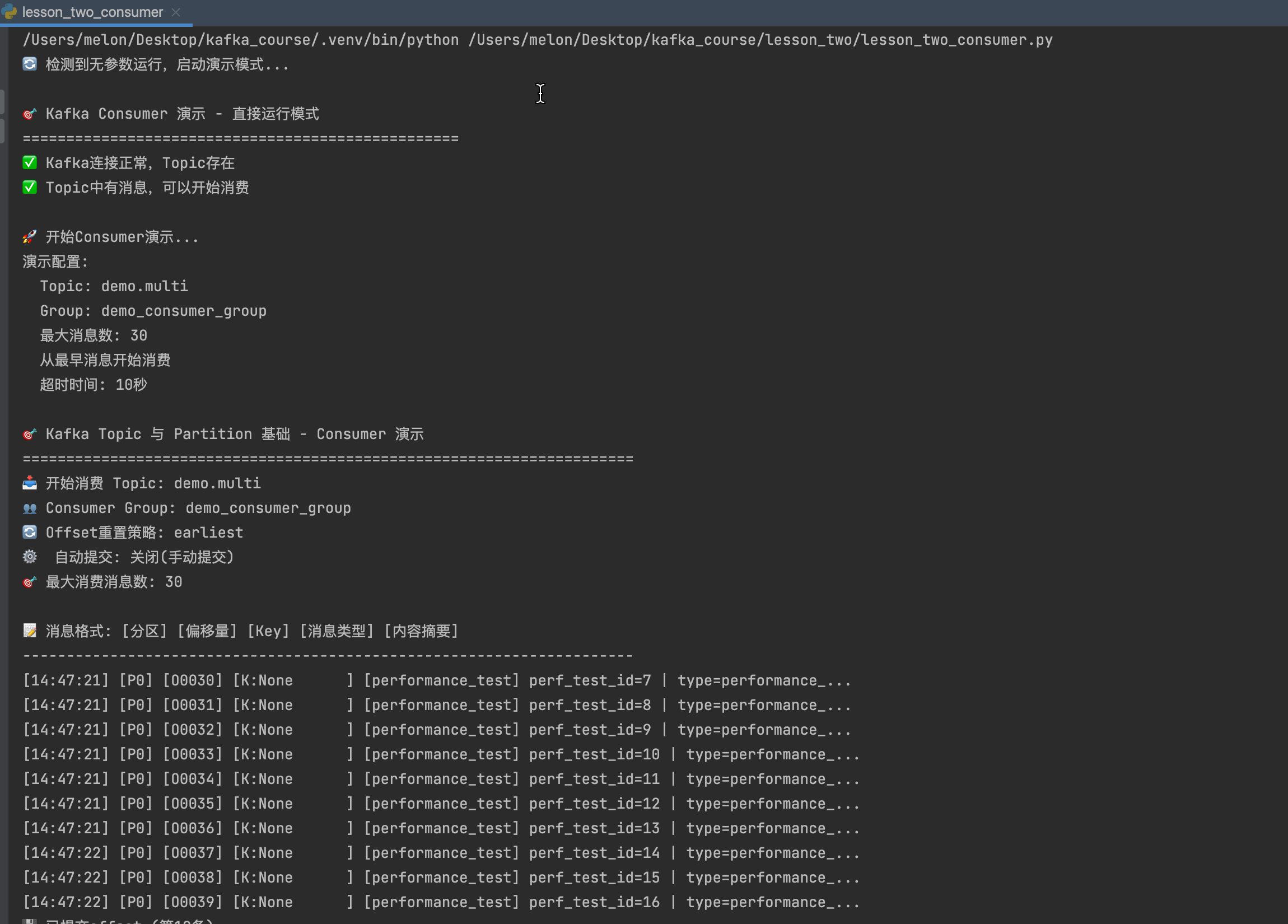
# lesson_two_consumer.py
import signal
import sys
from collections import defaultdict, Counter
from datetime import datetime
from lesson_two.common import make_consumer, close_safelyclass PartitionStatsConsumer:"""统计各分区消息的高级消费者"""def __init__(self, topic, group_id, max_messages=100, auto_commit=False, from_beginning=False):self.topic = topicself.group_id = group_idself.max_messages = max_messagesself.auto_commit = auto_commitself.from_beginning = from_beginningself.consumer = Noneself.running = True# 统计数据self.partition_stats = defaultdict(int)self.message_types = Counter()self.user_stats = Counter()self.start_time = Noneself.total_messages = 0# 注册信号处理signal.signal(signal.SIGINT, self._signal_handler)signal.signal(signal.SIGTERM, self._signal_handler)def _signal_handler(self, signum, frame):"""优雅停止处理"""print(f"\n📊 收到停止信号 {signum}, 准备优雅停止...")self.running = Falsedef start_consuming(self):"""开始消费消息"""try:# 创建消费者offset_reset = "earliest" if self.from_beginning else "latest"self.consumer = make_consumer(topic=self.topic,group_id=self.group_id,auto_offset_reset=offset_reset,enable_auto_commit=self.auto_commit,max_poll_records=50, # 每次最多拉取50条fetch_min_bytes=1024, # 最少1KB才返回fetch_max_wait_ms=1000 # 最多等待1秒)print(f"🎯 开始消费 Topic: {self.topic}, Group: {self.group_id}")print("📝 消息格式: [分区] [偏移量] [Key] [消息类型] [内容摘要]")print("-" * 80)self.start_time = time.time()# 主消费循环for message in self.consumer:if not self.running:break# 处理消息self._process_message(message)# 定期手动提交if not self.auto_commit and self.total_messages % 10 == 0:self.consumer.commit()print(f"💾 已提交offset (第{self.total_messages}条)")# 定期显示统计if self.total_messages % 20 == 0 and self.total_messages > 0:self._print_interim_stats()# 检查是否达到最大消息数if self.total_messages >= self.max_messages:print(f"\n🏁 已处理 {self.total_messages} 条消息,达到设定上限")breakexcept Exception as e:print(f"❌ 消费失败: {e}")finally:self._cleanup()def _process_message(self, message):"""处理单条消息"""# 更新统计partition = message.partitionself.partition_stats[partition] += 1self.total_messages += 1# 解析消息内容key = message.key or "None"value = message.value# 统计消息类型if isinstance(value, dict):msg_type = value.get("type", "unknown")self.message_types[msg_type] += 1# 统计用户if "user_id" in value:self.user_stats[value["user_id"]] += 1else:msg_type = "raw"self.message_types["raw"] += 1# 生成内容摘要content_summary = self._summarize_content(value)# 显示消息详情timestamp = datetime.now().strftime("%H:%M:%S")print(f"[{timestamp}] [P{partition:01d}] [O{message.offset:04d}] "f"[K:{key[:10]:10s}] [{msg_type:12s}] {content_summary}")def _summarize_content(self, value):"""生成消息内容摘要"""if not isinstance(value, dict):return str(value)[:50] + "..." if len(str(value)) > 50 else str(value)# 提取关键字段summary_parts = []priority_fields = ["id", "user_id", "batch_id", "action", "data", "category"]for field in priority_fields:if field in value:val = str(value[field])if len(val) > 15:val = val[:12] + "..."summary_parts.append(f"{field}={val}")if len(summary_parts) >= 3:breakreturn " | ".join(summary_parts) if summary_parts else "空消息"def _print_interim_stats(self):"""打印中期统计信息"""elapsed = time.time() - self.start_time if self.start_time else 0rate = self.total_messages / elapsed if elapsed > 0 else 0print()print(f"📊 实时统计 (已处理 {self.total_messages} 条,速度 {rate:.1f} 条/秒):")# 分区统计total = sum(self.partition_stats.values())if total > 0:stats_str = " | ".join([f"P{p}:{count}({count/total*100:.1f}%)" for p, count in sorted(self.partition_stats.items())])print(f" 分区分布: {stats_str}")else:print(f" 分区分布: 暂无数据")# 消息类型统计if self.message_types:type_str = " | ".join([f"{t}:{c}" for t, c in self.message_types.most_common(3)])print(f" 消息类型: {type_str}")print("-" * 70)def _print_final_stats(self):"""打印最终统计信息"""elapsed = time.time() - self.start_time if self.start_time else 0print("\n" + "="*70)print("📈 最终消费统计报告")print("="*70)# 基本信息print(f"🕒 消费时长: {elapsed:.2f} 秒")print(f"📦 总消息数: {self.total_messages}")if self.total_messages > 0 and elapsed > 0:print(f"⚡ 平均速度: {self.total_messages/elapsed:.2f} 条/秒")else:print("⚡ 平均速度: N/A")print()# 分区统计print("📊 分区消息分布:")if self.partition_stats:total = sum(self.partition_stats.values())for partition in sorted(self.partition_stats.keys()):count = self.partition_stats[partition]percentage = count / total * 100bar = "█" * int(percentage / 5)print(f" 分区 {partition}: {count:4d} 条 ({percentage:5.1f}%) {bar}")else:print(" 📭 无消息消费")print(" 💡 可能原因:")print(" - Topic中没有消息")print(" - 消费超时(Consumer等待消息时间过短)")print(" - offset重置策略导致跳过了历史消息")print()# 消息类型统计print("🏷️ 消息类型分布:")if self.message_types:for msg_type, count in self.message_types.most_common():percentage = count / self.total_messages * 100 if self.total_messages > 0 else 0print(f" {msg_type:15s}: {count:4d} 条 ({percentage:5.1f}%)")else:print(" 无消息类型统计")print()# 用户统计(如果有)if self.user_stats:print("👤 用户消息统计 (Top 5):")for user, count in self.user_stats.most_common(5):percentage = count / self.total_messages * 100 if self.total_messages > 0 else 0print(f" {user:15s}: {count:4d} 条 ({percentage:5.1f}%)")print()# 性能分析print("⚡ 性能分析:")if self.total_messages > 0 and elapsed > 0:print(f" 吞吐量: {self.total_messages/elapsed:.2f} 条/秒")print(f" 平均处理延迟: {elapsed/self.total_messages*1000:.2f} 毫秒/条")elif self.total_messages == 0:print(" 📭 无消息处理,无法计算性能指标")print(" 💡 建议:")print(" 1. 先运行 Producer 发送一些消息:")print(" python lesson_two_producer.py")print(" 2. 或使用 --from-beginning 参数从头消费:")print(" python lesson_two_consumer.py demo.multi test_group --from-beginning")else:print(" 数据不足,无法计算准确的性能指标")print()if self.total_messages > 0:print("✅ 消费完成!")else:print("📭 本次未消费到任何消息")print("="*70)def _cleanup(self):"""清理资源"""try:if self.consumer and not self.auto_commit:print("💾 最终提交offset...")self.consumer.commit()except Exception as e:print(f"⚠️ 提交offset失败: {e}")if self.consumer:print("🔄 关闭消费者连接...")close_safely(self.consumer)self._print_final_stats()def main():"""主函数:解析命令行参数"""parser = argparse.ArgumentParser(description="Kafka Topic 与 Partition 基础 - Consumer 演示")parser.add_argument("topic", help="要消费的Topic名称")parser.add_argument("group_id", help="Consumer Group ID")parser.add_argument("--max-messages", type=int, default=100, help="最大消费消息数量 (默认: 100)")parser.add_argument("--auto-commit", action="store_true", help="启用自动提交offset (默认: 手动提交)")parser.add_argument("--from-beginning", action="store_true", help="从最早的消息开始消费 (默认: 从最新开始)")args = parser.parse_args()try:# 创建并启动消费者consumer = PartitionStatsConsumer(topic=args.topic,group_id=args.group_id,max_messages=args.max_messages,auto_commit=args.auto_commit,from_beginning=args.from_beginning)consumer.start_consuming()except KeyboardInterrupt:print("\n👋 用户手动停止程序")except Exception as e:print(f"\n❌ 程序异常: {e}")import tracebacktraceback.print_exc()sys.exit(1)if __name__ == "__main__":if len(sys.argv) == 1:# 没有参数,直接运行演示print("🔄 检测到无参数运行,启动演示模式...")print()run_demo()elif len(sys.argv) < 3:print("Kafka Topic 与 Partition 基础 - Consumer 演示程序")print()print("🎯 快速开始(推荐):")print(" python lesson_two_consumer.py")print(" (直接运行演示,无需参数)")print()print("🔧 自定义用法: python lesson_two_consumer.py <topic> <group_id> [选项]")print()print("示例:")print(" python lesson_two_consumer.py demo.multi analytics_group")print(" python lesson_two_consumer.py demo.multi analytics_group --max-messages 50")print(" python lesson_two_consumer.py demo.multi analytics_group --from-beginning")print()print("参数说明:")print(" topic Topic名称")print(" group_id Consumer Group ID")print(" --max-messages N 最大消费消息数量 (默认: 100)")print(" --auto-commit 启用自动提交offset")print(" --from-beginning 从最早的消息开始消费")print()print("💡 提示: 如果还没有消息,请先运行 lesson_two_producer.py")sys.exit(1)else:main()
Consumer配置调优
# 高性能Consumer配置
consumer = make_consumer(max_poll_records=500, # 增加批量大小fetch_min_bytes=50*1024, # 50KB最小拉取fetch_max_wait_ms=100, # 减少等待时间enable_auto_commit=True, # 自动提交,减少代码复杂度auto_commit_interval_ms=1000 # 每秒自动提交
)# 高可靠性Consumer配置
consumer = make_consumer(enable_auto_commit=False, # 手动提交,确保处理成功isolation_level="read_committed", # 只读取已提交的消息max_poll_records=100, # 减少批量大小,提高可靠性session_timeout_ms=30000 # 增加会话超时时间
)
4. 一键演示脚本
为了简化学习过程,我们提供了多个演示脚本:
🚀 快速开始(推荐新手)
# 一键体验所有功能
python quick_start.py# 这个脚本会:
# 1. 检查Kafka环境
# 2. 创建demo.multi Topic
# 3. 发送示例消息
# 4. 消费并显示统计
# 5. 提供学习指导
🔄 完整演示
# 完整的课程演示
python run_demo.py# 这个脚本会依次运行:
# 1. Producer演示(分区策略)
# 2. Consumer演示(多分区消费)
# 3. Admin工具演示(集群管理)
# 4. Benchmark演示(性能测试)
📊 独立运行
# 单独运行Producer演示
python lesson_two_producer.py# 单独运行Consumer演示
python lesson_two_consumer.py# 单独运行Admin工具
python lesson_two_admin.py# 单独运行性能测试
python lesson_two_benchmark.py
5. 实际运行演示
步骤1:启动消费者
# 在第一个终端启动消费者(推荐方式)
python lesson_two_consumer.py# 或者自定义参数
python lesson_two_consumer.py demo.multi analytics_group --from-beginning
步骤2:启动生产者
# 在第二个终端启动生产者(推荐方式)
python lesson_two_producer.py# 或者使用一键演示
python quick_start.py
步骤3:观察输出
消费者将显示类似以下的输出:
🎯 开始消费 Topic: demo.multi, Group: demo_consumer_group
📝 消息格式: [时间] [分区] [偏移量] [Key] [消息类型] [内容摘要]
--------------------------------------------------------------------------------
[14:30:15] [P0] [0000] [K:None ] [round_robin ] id=0 | data=轮询消息 #0
[14:30:15] [P1] [0000] [K:None ] [round_robin ] id=1 | data=轮询消息 #1
[14:30:15] [P2] [0000] [K:None ] [round_robin ] id=2 | data=轮询消息 #2
[14:30:16] [P0] [0001] [K:None ] [round_robin ] id=3 | data=轮询消息 #3
[14:30:16] [P1] [0001] [K:alice ] [key_hash ] user_id=alice | action=action_0
[14:30:16] [P1] [0002] [K:alice ] [key_hash ] user_id=alice | action=action_3
[14:30:17] [P2] [0001] [K:bob ] [key_hash ] user_id=bob | action=action_1
[14:30:17] [P2] [0002] [K:bob ] [key_hash ] user_id=bob | action=action_4📊 实时统计 (已处理 20 条,速度 8.5 条/秒):分区分布: P0:6(30.0%) | P1:8(40.0%) | P2:6(30.0%)消息类型: round_robin:12 | key_hash:8
----------------------------------------------------------------------
步骤4:查看最终统计
运行结束后,会显示详细的统计报告:
📈 最终消费统计报告
======================================================================
🕒 消费时长: 2.35 秒
📦 总消息数: 30
⚡ 平均速度: 12.77 条/秒📊 分区消息分布:分区 0: 10 条 ( 33.3%) ██████分区 1: 12 条 ( 40.0%) ████████分区 2: 8 条 ( 26.7%) █████🏷️ 消息类型分布:round_robin : 18 条 ( 60.0%)key_hash : 12 条 ( 40.0%)⚡ 性能分析:吞吐量: 12.77 条/秒平均处理延迟: 78.43 毫秒/条✅ 消费完成!
======================================================================
四、常见问题与故障排查
1. 分区相关问题
Q1: 如何选择合适的分区数量?
问题现象: 不知道创建多少个分区最合适
解决方案:
# 分区数量选择原则:
# 1. 吞吐量需求:目标吞吐量 ÷ 单分区吞吐量
# 2. Consumer 数量:分区数 >= Consumer 实例数
# 3. 硬件资源:不超过 Broker 的 CPU 核心数# 示例:目标 100MB/s,单分区 10MB/s
分区数 = 100MB/s ÷ 10MB/s = 10 个分区
实际计算示例:
# 分区数量计算工具
def calculate_partitions(target_throughput_mbps, single_partition_mbps, consumer_count):"""计算推荐的分区数量"""# 基于吞吐量throughput_partitions = max(1, int(target_throughput_mbps / single_partition_mbps))# 基于Consumer数量consumer_partitions = max(1, consumer_count)# 基于硬件资源(假设每个Broker有8个CPU核心)broker_count = 3 # 假设3个Brokermax_partitions_per_broker = 8hardware_partitions = broker_count * max_partitions_per_broker# 取最大值,但不超过硬件限制recommended = min(max(throughput_partitions, consumer_partitions), hardware_partitions)print(f"📊 分区数量计算:")print(f" 目标吞吐量: {target_throughput_mbps} MB/s")print(f" 单分区吞吐量: {single_partition_mbps} MB/s")print(f" Consumer数量: {consumer_count}")print(f" 推荐分区数: {recommended}")return recommended# 使用示例
calculate_partitions(100, 10, 5) # 目标100MB/s,单分区10MB/s,5个Consumer
最佳实践:
- 开始时使用较少分区(3-6个)
- 根据实际负载逐步调整
- 预留一定的扩展空间
Q2: 分区数据不均衡怎么办?
问题现象: 某些分区消息量特别大,负载不均
原因分析:
# 热点Key导致的问题
hot_keys = ["popular_user", "trending_topic"]
for key in hot_keys:# 这些Key总是落到同一分区,造成热点producer.send("user-events", key=key, value=data)
解决方案:
# 方案1:给Key添加随机后缀
import randomdef balanced_key(original_key):suffix = random.randint(0, 3) # 4个子分区return f"{original_key}_{suffix}"# 方案2:自定义分区器
class BalancedPartitioner:def partition(self, key, all_partitions, available_partitions):if key in hot_keys:# 热点Key随机分配return random.choice(list(all_partitions))else:# 普通Key使用Hashreturn hash(key) % len(all_partitions)
实际应用示例:
# 电商系统分区策略
class EcommercePartitioner:def __init__(self):# 定义热点商品类别self.hot_categories = {"electronics", "clothing", "books"}# 定义热点用户(VIP用户)self.vip_users = {"user_001", "user_002", "user_003"}def partition(self, key, all_partitions, available_partitions):if not key:# 无Key消息,轮询分配return hash(str(time.time())) % len(all_partitions)key_str = key.decode('utf-8') if isinstance(key, bytes) else str(key)# 检查是否是热点类别if any(cat in key_str.lower() for cat in self.hot_categories):# 热点类别,分散到多个分区return hash(f"{key_str}_{int(time.time() / 3600)}") % len(all_partitions)# 检查是否是VIP用户if key_str in self.vip_users:# VIP用户,使用固定分区保证顺序return hash(key_str) % len(all_partitions)# 普通Key,使用Hash分区return hash(key_str) % len(all_partitions)# 使用自定义分区器
producer = make_producer(partitioner=EcommercePartitioner())
监控分区均衡性:
def check_partition_balance(topic, partitions):"""检查分区均衡性"""partition_counts = {}# 统计每个分区的消息数量for partition in partitions:# 这里需要实际查询分区信息# 简化示例partition_counts[partition] = random.randint(80, 120)# 计算均衡度counts = list(partition_counts.values())max_count = max(counts)min_count = min(counts)balance = (1 - (max_count - min_count) / max_count) * 100print(f"📊 分区均衡性检查:")print(f" 最大分区: {max_count} 条")print(f" 最小分区: {min_count} 条")print(f" 均衡度: {balance:.1f}%")if balance < 80:print(" ⚠️ 分区不均衡,建议优化分区策略")else:print(" ✅ 分区均衡性良好")return balance
2. 性能优化问题
Q3: Producer发送速度慢怎么优化?
问题现象: 消息发送TPS较低,延迟较高
诊断方法:
# 监控Producer关键指标
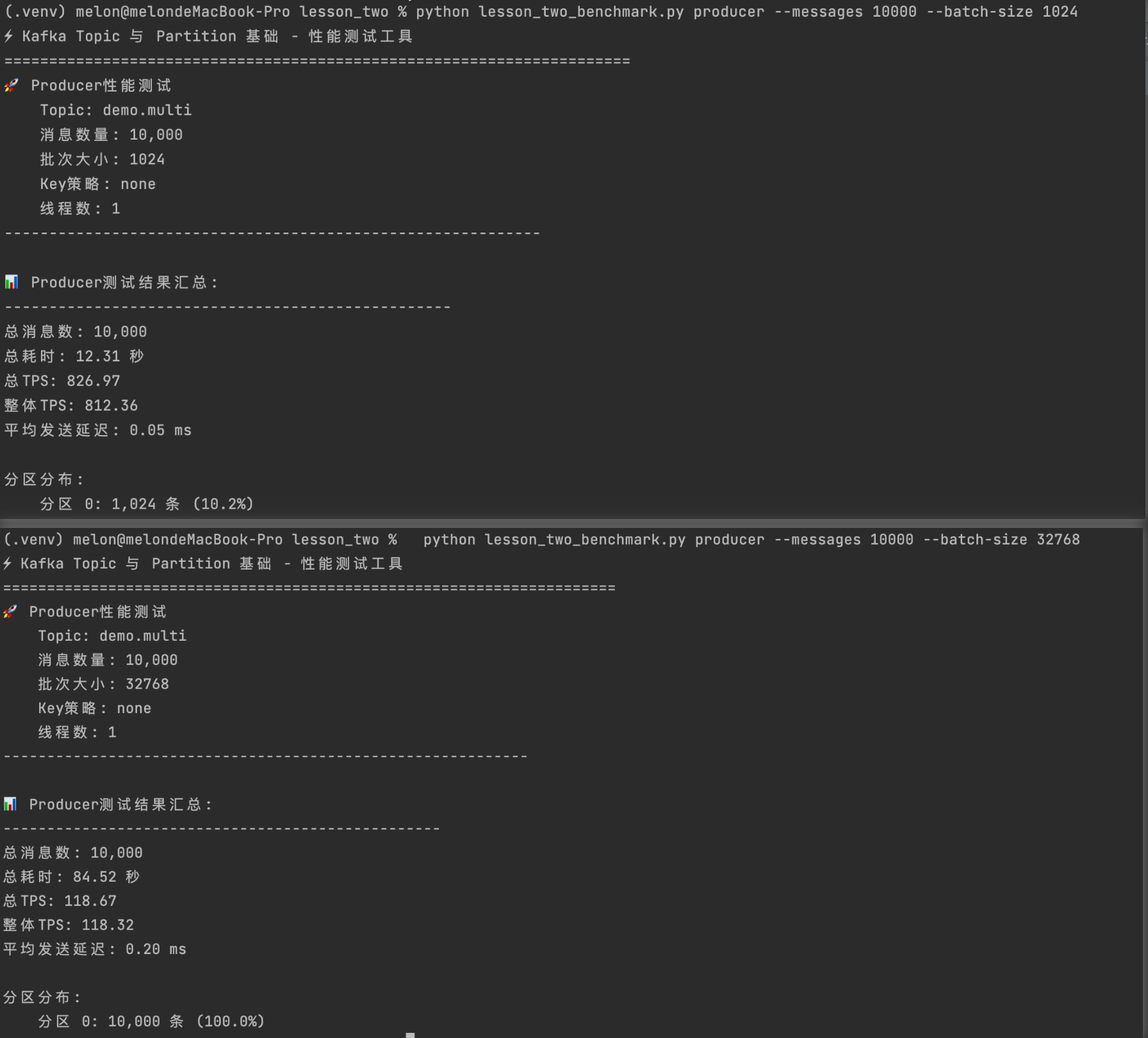
import timedef benchmark_producer():producer = make_producer(linger_ms=5, # 减少批量等待时间batch_size=32*1024, # 32KB批量大小compression_type="lz4" # 使用更快的压缩算法)start_time = time.time()message_count = 1000for i in range(message_count):producer.send("test-topic", value={"id": i})producer.flush()elapsed = time.time() - start_timetps = message_count / elapsedprint(f"TPS: {tps:.2f} messages/sec")
优化建议:
# Producer 配置优化
acks: 1 # 降低到1(而非all)提升性能
linger_ms: 5 # 减少批量等待
batch_size: 64KB # 增大批量大小
compression_type: lz4 # 使用LZ4压缩
max_in_flight_requests_per_connection: 5
Q4: Consumer消费延迟高怎么办?
问题现象: Consumer Lag持续增长,处理跟不上生产
诊断命令:
# 检查Consumer Lag
bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 \--group my-group --describe# 输出示例:
# TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG
# demo.multi 0 1000 1500 500
# demo.multi 1 1200 1300 100
# demo.multi 2 900 1600 700
解决方案:
# 优化Consumer配置
consumer = make_consumer(topic="demo.multi",group_id="my-group",max_poll_records=500, # 增加批量大小fetch_min_bytes=50*1024, # 50KB最小拉取fetch_max_wait_ms=100, # 减少等待时间enable_auto_commit=False # 手动提交,批量处理
)# 批量处理消息
messages = consumer.poll(timeout_ms=1000, max_records=500)
for topic_partition, msgs in messages.items():# 批量处理这个分区的所有消息process_batch(msgs)# 批量提交offset
consumer.commit()
3. 可靠性问题
Q5: 如何确保消息不丢失?
配置生产者:
producer = make_producer(acks="all", # 等待所有副本确认retries=10, # 重试次数retry_backoff_ms=1000, # 重试间隔enable_idempotence=True, # 启用幂等性(需要confluent-kafka)max_in_flight_requests_per_connection=1 # 保证顺序
)
配置消费者:
consumer = make_consumer(topic="important-topic",group_id="reliable-group", enable_auto_commit=False, # 禁用自动提交isolation_level="read_committed" # 只读取已提交的消息
)# 确保处理成功后再提交
for message in consumer:try:process_message(message)consumer.commit() # 处理成功后提交except Exception as e:print(f"处理失败,跳过: {e}")# 不提交,重新消费
Q6: 如何处理重复消息?
问题原因: 网络重传、Consumer重启等导致重复消费
解决方案1:业务层去重
import redisredis_client = redis.Redis(host='localhost', port=6379, db=0)def process_with_dedup(message):msg_id = message.value.get("id")# 检查是否已处理if redis_client.exists(f"processed:{msg_id}"):print(f"消息 {msg_id} 已处理,跳过")return# 处理业务逻辑do_business_logic(message)# 标记为已处理redis_client.setex(f"processed:{msg_id}", 3600, "1")
解决方案2:幂等性设计
def idempotent_update(user_id, balance_change):"""幂等性的余额更新"""# 使用数据库的原子操作query = """UPDATE user_balance SET balance = balance + %s,last_update_id = %sWHERE user_id = %s AND last_update_id != %s"""# 只有当last_update_id不同时才更新return execute_query(query, [balance_change, msg_id, user_id, msg_id])
4. 监控与排查工具
常用诊断命令
# 1. 查看Topic信息
bin/kafka-topics.sh --bootstrap-server localhost:9092 \--list# 2. 查看分区详情
bin/kafka-topics.sh --bootstrap-server localhost:9092 \--topic demo.multi --describe# 3. 查看Consumer Group状态
bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 \--group my-group --describe# 4. 重置Consumer Offset
bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 \--group my-group --topic demo.multi \--reset-offsets --to-earliest --execute# 5. 查看日志目录
ls -la /kafka-logs/demo.multi-0/
Python监控脚本
# monitor.py - 简单的Kafka监控脚本
from kafka.admin import KafkaAdminClient, ConfigResource, ConfigResourceType
from kafka import KafkaConsumerdef check_cluster_health():"""检查集群健康状态"""admin = KafkaAdminClient(bootstrap_servers="localhost:9092")# 检查Topic列表topics = admin.list_topics()print(f"发现 {len(topics)} 个Topics: {list(topics)}")# 检查每个Topic的分区分布for topic in topics:partitions = admin.describe_topics([topic])[topic].partitionsprint(f"\nTopic: {topic}")for partition in partitions:print(f" 分区 {partition.partition_id}: Leader={partition.leader}, Replicas={partition.replicas}")if __name__ == "__main__":check_cluster_health()
五、实际应用场景与最佳实践
1. 电商系统架构
订单处理流程
分区策略设计
# 电商系统分区策略
class EcommercePartitioner:def __init__(self):self.order_partitions = 3 # 订单Topic:3分区self.inventory_partitions = 2 # 库存Topic:2分区self.payment_partitions = 2 # 支付Topic:2分区def partition_order(self, order_id):"""订单分区:保证同一订单的顺序"""return hash(order_id) % self.order_partitionsdef partition_inventory(self, product_id):"""库存分区:按商品ID分区"""return hash(product_id) % self.inventory_partitionsdef partition_payment(self, user_id):"""支付分区:按用户ID分区"""return hash(user_id) % self.payment_partitions# 使用示例
partitioner = EcommercePartitioner()# 发送订单事件
producer.send("order-events", key=order_id, value={"type": "order_created", "amount": 100.0})# 发送库存更新
producer.send("inventory-updates", key=product_id, value={"type": "stock_reduced", "quantity": 1})# 发送支付事件
producer.send("payment-events", key=user_id, value={"type": "payment_success", "amount": 100.0})
2. 日志收集系统
系统架构
日志分区策略
# 日志收集系统分区策略
class LogPartitioner:def __init__(self):self.app_logs_partitions = 20self.error_logs_partitions = 10self.access_logs_partitions = 15def partition_app_logs(self, message):"""应用日志:轮询分区,无Key"""# 使用时间戳确保均匀分布timestamp = int(time.time() * 1000)return timestamp % self.app_logs_partitionsdef partition_error_logs(self, service_name):"""错误日志:按服务名分区"""return hash(service_name) % self.error_logs_partitionsdef partition_access_logs(self, user_id):"""访问日志:按用户ID分区"""return hash(user_id) % self.access_logs_partitions# 使用示例
log_partitioner = LogPartitioner()# 应用日志(无Key,轮询分区)
producer.send("app-logs", value={"level": "INFO","message": "User login successful","timestamp": datetime.now().isoformat()
})# 错误日志(按服务名分区)
producer.send("error-logs", key="web-service", value={"level": "ERROR","message": "Database connection failed","stack_trace": "..."})# 访问日志(按用户ID分区)
producer.send("access-logs", key="user_123", value={"action": "page_view","page": "/dashboard","ip": "192.168.1.100"})
3. 实时数据处理系统
流处理架构
实时处理配置
# 实时数据处理配置
class RealTimeProcessor:def __init__(self):self.sensor_partitions = 8self.user_partitions = 12self.transaction_partitions = 6def create_sensor_producer(self):"""传感器数据生产者:高吞吐量配置"""return make_producer(acks="1", # 快速确认linger_ms=5, # 最小延迟batch_size=64*1024, # 64KB批量compression_type="lz4", # 快速压缩max_in_flight_requests_per_connection=5)def create_user_events_producer(self):"""用户事件生产者:平衡配置"""return make_producer(acks="all", # 高可靠性linger_ms=10, # 平衡延迟和吞吐量batch_size=32*1024, # 32KB批量compression_type="gzip", # 高压缩比enable_idempotence=True # 幂等性)def create_transaction_producer(self):"""交易数据生产者:高可靠性配置"""return make_producer(acks="all", # 最高可靠性linger_ms=50, # 批量优化batch_size=16*1024, # 16KB批量compression_type="snappy", # 快速压缩enable_idempotence=True, # 幂等性retries=10, # 更多重试retry_backoff_ms=1000 # 重试间隔)# 使用示例
rt_processor = RealTimeProcessor()# 发送传感器数据
sensor_producer = rt_processor.create_sensor_producer()
sensor_producer.send("sensor-data", key="device_001", value={"temperature": 25.5, "humidity": 60})# 发送用户事件
user_producer = rt_processor.create_user_events_producer()
user_producer.send("user-events", key="user_456", value={"action": "product_view", "product_id": "prod_123"})# 发送交易数据
tx_producer = rt_processor.create_transaction_producer()
tx_producer.send("transactions", key="merchant_789", value={"amount": 299.99, "currency": "USD"})
4. 最佳实践总结
分区数量规划
# 分区数量规划工具
def plan_partitions(use_case, expected_throughput, consumer_count, reliability_requirement):"""分区数量规划"""base_partitions = {"high_throughput": 20, # 高吞吐量场景"balanced": 12, # 平衡场景"high_reliability": 6 # 高可靠性场景}# 基础分区数base = base_partitions.get(use_case, 12)# 根据吞吐量调整if expected_throughput > 1000: # 1000+ msg/sbase = min(base * 2, 50) # 最多50个分区# 根据Consumer数量调整if consumer_count > base:base = consumer_count# 根据可靠性要求调整if reliability_requirement == "high":base = max(base, 6) # 至少6个分区保证高可用return base# 使用示例
print("📊 分区数量规划:")
print(f" 高吞吐量场景: {plan_partitions('high_throughput', 2000, 8, 'medium')}")
print(f" 平衡场景: {plan_partitions('balanced', 500, 4, 'medium')}")
print(f" 高可靠性场景: {plan_partitions('high_reliability', 200, 3, 'high')}")
分区策略选择
# 分区策略选择指南
def select_partition_strategy(use_case, message_order_requirement, key_distribution):"""选择合适的分区策略"""strategies = {"round_robin": {"description": "轮询分区","pros": ["负载均衡", "实现简单"],"cons": ["无法保证顺序"],"best_for": ["日志收集", "指标上报", "无顺序要求"]},"key_hash": {"description": "Key Hash分区","pros": ["相同Key有序", "负载相对均衡"],"cons": ["可能热点不均"],"best_for": ["用户事件", "订单处理", "需要局部有序"]},"custom": {"description": "自定义分区","pros": ["灵活控制", "业务适配"],"cons": ["实现复杂", "维护成本高"],"best_for": ["复杂业务规则", "地域分片", "负载均衡要求高"]}}# 根据用例选择策略if message_order_requirement == "strict":if key_distribution == "uniform":return "key_hash"else:return "custom"elif use_case in ["logging", "monitoring"]:return "round_robin"else:return "key_hash"return "round_robin" # 默认策略# 使用示例
print("🎯 分区策略选择:")
print(f" 日志收集: {select_partition_strategy('logging', 'none', 'uniform')}")
print(f" 用户事件: {select_partition_strategy('user_events', 'strict', 'skewed')}")
print(f" 订单处理: {select_partition_strategy('order_processing', 'strict', 'uniform')}")
六、总结与展望
核心知识点回顾
通过本课程,我们深入学习了 Kafka 的分区机制:
1. 概念理解
- Topic:消息的逻辑分类,类似数据库表
- Partition:Topic 的物理分片,实现并行处理
- Replica:分区副本,保证数据安全和高可用
- Leader/Follower:主从架构,Leader处理读写,Follower负责备份
2. 分区策略掌握
| 策略 | 适用场景 | 优势 | 劣势 |
|---|---|---|---|
| 轮询分区 | 日志收集、指标上报 | 负载均衡 | 无法保证顺序 |
| Key Hash | 用户事件、业务有序处理 | 相同Key有序 | 可能热点不均 |
| 自定义分区 | 复杂业务规则 | 灵活控制 | 实现复杂 |
3. 存储原理认知
- Segment 文件:
.log(数据)+.index(索引)+.timeindex(时间索引) - 顺序写入:充分利用磁盘性能
- 零拷贝:减少内存拷贝,提升效率
- 页缓存:利用操作系统缓存机制
4. 运维能力提升
- 分区数量规划:基于吞吐量和Consumer数量
- 性能优化:Producer批量、Consumer并发
- 故障排查:监控Lag、检查ISR状态
- 数据可靠性:合理配置acks、retries参数
实际应用场景
高吞吐日志系统:
Topic: application-logs
├── 分区策略: 轮询(无Key)
├── 分区数量: 20个(支持20个Consumer并行处理)
├── 副本数量: 2个(平衡可靠性和成本)
└── 适用场景: 应用日志、系统监控、指标收集
用户行为追踪:
Topic: user-events
├── 分区策略: Key Hash(user_id作为Key)
├── 分区数量: 12个(保证单用户事件有序)
├── 副本数量: 3个(高可靠性要求)
└── 适用场景: 用户画像、行为分析、个性化推荐
订单处理系统:
Topic: order-events
├── 分区策略: 自定义(按地区分区)
├── 分区数量: 8个(对应8个地区)
├── 副本数量: 3个(金融级可靠性)
└── 适用场景: 电商订单、支付处理、库存管理
IoT数据处理:
Topic: sensor-data
├── 分区策略: Key Hash(device_id作为Key)
├── 分区数量: 16个(支持高并发设备)
├── 副本数量: 2个(成本敏感场景)
└── 适用场景: 智能家居、工业监控、环境监测
实时推荐系统:
Topic: recommendation-events
├── 分区策略: 混合策略(用户事件用Key Hash,系统事件用轮询)
├── 分区数量: 24个(高并发用户访问)
├── 副本数量: 3个(业务连续性要求)
└── 适用场景: 电商推荐、内容推荐、广告投放
下一步学习计划
第3篇课程预告:《Consumer Group 深入剖析》
我们将学习:
-
Consumer Group 工作机制
- 分区分配策略(Range、RoundRobin、Sticky)
- Rebalance 过程详解
- Consumer 故障恢复
-
Offset 管理
- 手动 vs 自动提交
- Offset 存储位置
- 重复消费和丢失消费的避免
-
高级消费模式
- 多线程消费
- 批量消费
- 流式处理
-
实战项目
- 构建分布式日志收集系统
- 实现消息重试机制
- 监控和告警系统
推荐深入阅读
- Kafka 官方文档 - Partitions
- 《Kafka: The Definitive Guide》
- Kafka 性能调优最佳实践
练习作业
为巩固本课程内容,建议完成以下练习:
🎯 基础练习(必做)
-
Topic创建与观察
# 创建不同分区数的Topic bin/kafka-topics.sh --create --bootstrap-server localhost:9092 \--topic test-3part --partitions 3 --replication-factor 1bin/kafka-topics.sh --create --bootstrap-server localhost:9092 \--topic test-6part --partitions 6 --replication-factor 1# 观察分区分布 bin/kafka-topics.sh --describe --bootstrap-server localhost:9092 --topic test-3part -
消息分布观察
# 运行Producer发送消息 python lesson_two_producer.py# 运行Consumer观察分区分布 python lesson_two_consumer.py# 分析:为什么某些分区消息更多?
🔧 进阶练习(推荐)
-
自定义分区器实现
# 实现一个按时间分区的分区器 class TimeBasedPartitioner:def partition(self, key, all_partitions, available_partitions):# 按小时分区:0-23点对应不同分区hour = datetime.now().hourreturn hour % len(all_partitions)# 测试你的分区器 producer = make_producer(partitioner=TimeBasedPartitioner()) -
分区均衡性分析
# 编写脚本分析分区均衡性 def analyze_partition_balance(topic_name):# 统计每个分区的消息数量# 计算标准差和变异系数# 生成可视化图表pass
⚡ 性能练习(挑战)
-
性能对比测试
# 测试不同配置下的性能 python lesson_two_benchmark.py producer --messages 10000 --batch-size 1024 python lesson_two_benchmark.py producer --messages 10000 --batch-size 32768# 分析:批量大小如何影响性能? -
分区数量影响分析
# 创建不同分区数的Topic # 测试相同消息量下的性能 # 分析:分区数量如何影响吞吐量?
🚨 故障练习(高级)
-
故障转移模拟
# 模拟Broker故障 # 1. 停止一个Broker # 2. 观察分区Leader切换 # 3. 验证数据完整性 # 4. 恢复Broker,观察重新平衡 -
数据一致性验证
# 编写脚本验证故障转移后的数据一致性 def verify_data_consistency(topic_name, partition_id):# 1. 记录故障前的消息# 2. 触发故障转移# 3. 验证故障后的消息完整性pass
📊 综合项目(毕业设计)
- 构建完整的消息系统
# 设计一个电商订单处理系统 class OrderProcessingSystem:def __init__(self):# 创建多个Topic# order-events: 订单事件# inventory-updates: 库存更新# payment-events: 支付事件# notification-events: 通知事件passdef process_order(self, order_data):# 1. 发送订单创建事件# 2. 检查库存# 3. 处理支付# 4. 发送通知passdef monitor_system_health(self):# 监控分区均衡性# 监控Consumer Lag# 监控错误率pass
🎓 提交要求
- 基础练习:截图 + 简单分析
- 进阶练习:代码 + 运行结果
- 性能练习:数据对比 + 分析报告
- 故障练习:故障过程记录 + 恢复验证
- 综合项目:完整代码 + 设计文档 + 演示视频
🏆 评分标准
- 完成度:40%(是否完成所有练习)
- 理解深度:30%(对概念的理解程度)
- 实践能力:20%(代码实现质量)
- 创新性:10%(是否有创新思考)
💡 学习建议
- 循序渐进:从基础练习开始,逐步深入
- 理论结合实践:每学一个概念就动手验证
- 记录过程:记录遇到的问题和解决方案
- 分享交流:与其他学习者分享经验
- 持续改进:根据反馈不断优化代码
课程总结
🎯 学习成果
通过本课程,您已经掌握了:
-
核心概念理解
- Topic、Partition、Replica的关系和设计原理
- Leader/Follower机制和故障转移过程
- ISR机制和数据一致性保证
-
分区策略掌握
- 轮询分区:适用于日志收集、指标上报
- Key Hash分区:适用于用户事件、订单处理
- 自定义分区:适用于复杂业务规则
-
存储原理认知
- Segment文件结构和消息存储格式
- 顺序I/O、页缓存、零拷贝等性能优化原理
- 日志清理策略和配置优化
-
实践技能提升
- 多分区Topic的创建和管理
- Producer/Consumer的高级配置和调优
- 性能测试和故障排查能力
-
实际应用能力
- 电商系统、日志收集、实时数据处理等场景设计
- 分区数量规划和策略选择
- 系统架构设计和最佳实践
🚀 技能等级评估
- 初级:理解基本概念,能运行演示代码
- 中级:掌握分区策略,能优化配置参数
- 高级:深入理解原理,能设计复杂系统
- 专家:能解决生产环境问题,指导团队
📚 推荐学习路径
第1篇:Kafka基础 → 第2篇:Topic与Partition → 第3篇:Consumer Group → 第4篇:高级特性↓ ↓ ↓ ↓
基础概念 分区机制 消费模式 流处理、连接器
简单Demo 分区策略 负载均衡 监控运维
环境搭建 存储原理 故障恢复 性能调优
🔍 知识地图
Kafka Topic & Partition
├── 基础概念
│ ├── Topic(逻辑分类)
│ ├── Partition(物理分片)
│ └── Replica(数据副本)
├── 核心机制
│ ├── Leader/Follower
│ ├── ISR(同步副本)
│ └── 故障转移
├── 分区策略
│ ├── 轮询分区
│ ├── Key Hash分区
│ └── 自定义分区
├── 存储原理
│ ├── Segment文件
│ ├── 索引机制
│ └── 性能优化
└── 实际应用├── 系统设计├── 性能调优└── 故障排查
下一步学习计划
🎯 第3篇课程预告:《Consumer Group 深入剖析》
学习目标:
-
Consumer Group 工作机制
- 分区分配策略(Range、RoundRobin、Sticky)
- Rebalance 过程详解
- Consumer 故障恢复机制
-
Offset 管理
- 手动 vs 自动提交
- Offset 存储位置和机制
- 重复消费和丢失消费的避免
-
高级消费模式
- 多线程消费设计
- 批量消费优化
- 流式处理集成
-
实战项目
- 构建分布式日志收集系统
- 实现消息重试和死信队列
- 监控和告警系统搭建
📖 推荐深入阅读
- Kafka 官方文档 - Partitions
- 《Kafka: The Definitive Guide》
- Kafka 性能调优最佳实践
- Kafka 生产环境部署指南
- Kafka 监控指标详解
🛠️ 实践项目建议
- 个人项目:搭建个人博客的日志收集系统
- 团队项目:设计公司内部的消息通知系统
- 开源贡献:参与Kafka相关开源项目
- 技术分享:在团队内分享Kafka最佳实践
🌟 职业发展
- 初级开发:掌握基本使用,能参与Kafka项目
- 中级开发:能独立设计Kafka架构,解决常见问题
- 高级开发:能优化系统性能,指导团队使用
- 架构师:能设计大规模分布式系统,制定技术标准
🌟 运行演示案例
下次课程见! 🚀 我们将在第3篇中深入探讨 Consumer Group 的高级特性,带您进入Kafka的更深层次!