Linux操作系统(6)
二、网络第二部分
1、网络层:长距离传输,路径选择,解决的是主机A为什么到的主机B
在复杂的网络环境中确定一个合适的路径。
(1)、IP协议
①、基本概念

路由器不仅仅工作在网络层,当代路由器,已经是一台小型计算机了,是可以工作在应用层的!
②、IP的核心作用:跨网络
IP协议:提供一种能力,把数据报从A主机,跨网络,送到B主机。
(①)、问题一:能力的意思就是有很大的概率可以完成这件事!
既然是较大概率,也就意味着还是有较小概率是无法完成这件事的,所以就需要帮助!
所以网络层IP提供这种能力,而帮助是由传输层完成的,它负责丢报、超时的时候的重传工作,以及其他可以帮助100%跨网络传输的工作!!
在网络中奔跑的是“IP报文”!
TCP/IP协议的核心作用:把数据报100%可靠的,从主机A跨网络传输到主机B上!
(②)、问题二:既然是跨网络,实现不同主机的数据报交互,就需要标识两端主机的唯一性!
而随着网络的发展,主机的数量逐渐增多,为了区分不同的主机,每台主机都有自己的IP地址(公网IP)!
需要明确的一点是只有公网IP在网络中才是唯一的!
(③)、问题三:IP协议解决的是主机到主机的问题,而TCP对上,解决的是另一个问题:进程到进程的问题,因为有端口号!
③、IP的组成
目标网络+目标主机
为什么这么划分呢?
举个栗子
就比如说我们去北京故宫旅游,不是直接坐飞机直达故宫,下飞机就到门口,而是先到北京,然后在去故宫,所以发送数据报也是一样的道理,主机A发送的数据报先到达主机B的局域网(子网),然后通过内网转发到达主机B,所以IP被分为目标网络和目标主机。
主机号
全0:整个IP就是表示网络号
全1:广播地址
④、IP协议结构体
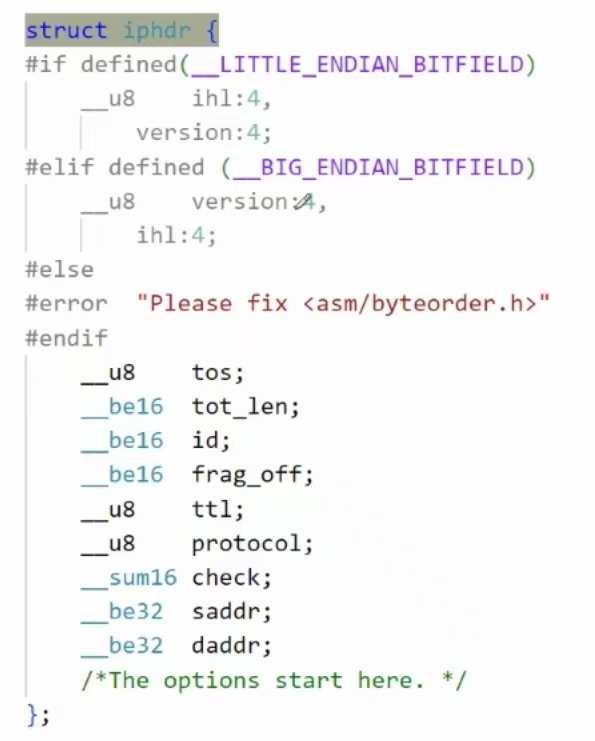
之前我们在传输层说过一个报文就是一个sk_buff,报文从传输层到网络层,head指针就会减小,减小量对应IP协议头大小,然后把指针指向的这段空间强转成ip结构体,把IP协议头中的数据填充进去即可!
⑤、协议头格式
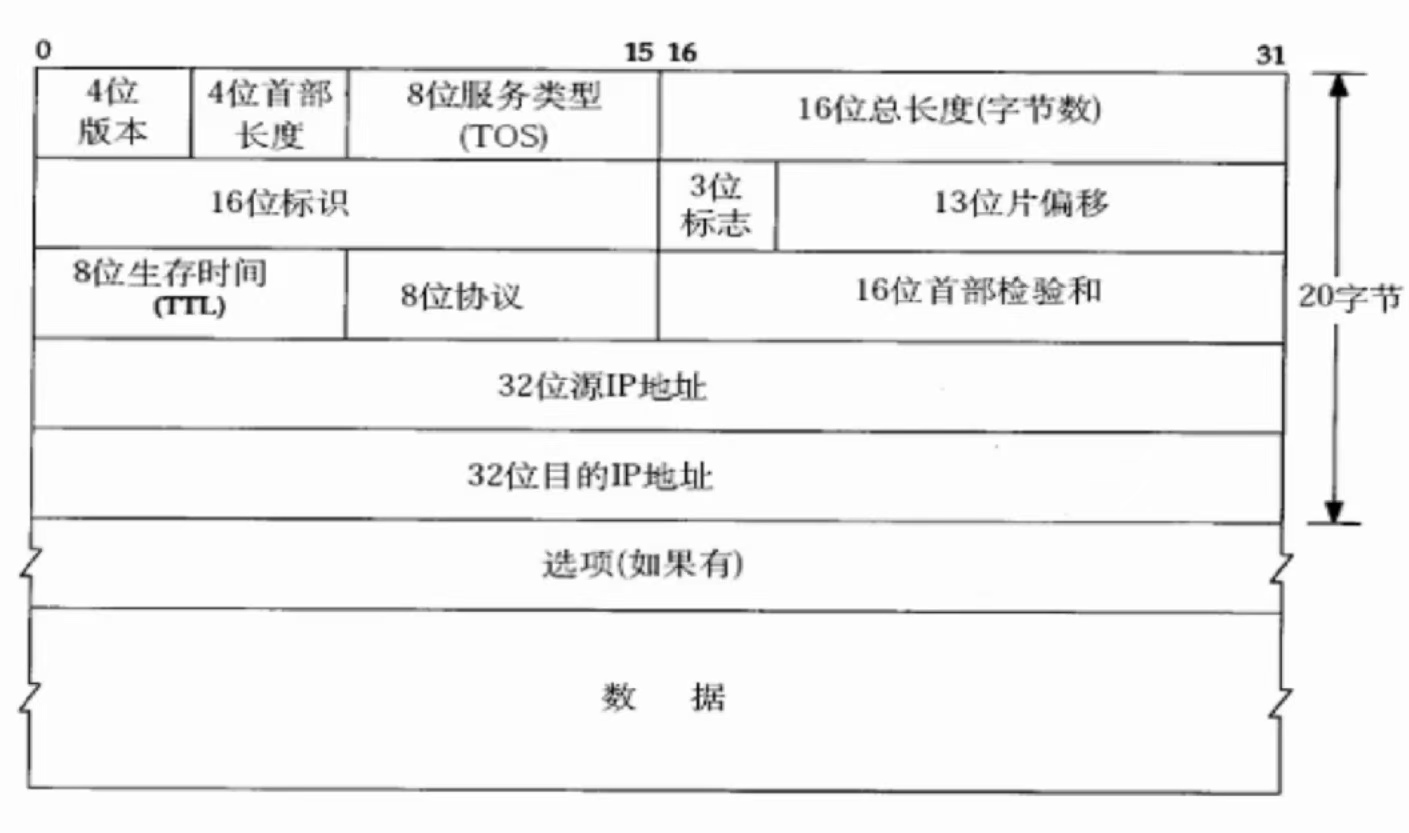

(①)、和TCP协议头一样,也有4位首部长度[0, 15]和选项
(②)、IP协议头固定大小为20字节
(③)、老生常谈:IP报文的解包与分用问题
解包
根据4位首部长度,就可以把正文加选项部分去除掉,剩余就是有效载荷部分。
16位总长度:报头加有效载荷的长度
利用16位总长度减去首部长度,可得有效载荷部分长度。
分用
8位协议:标明我们上层使用的是TCP协议还是UDP协议
(④)、4位版本:IPV4
(⑤)、8位服务类型

其实就是进行路径选择的,从主机A到主机B会有很多种不同的路线,会根据不同的需求选择不同的路线。
(⑥)、8位生存时间TTL(Time To Live)
就是因为目前的网络拓扑结构已经非常复杂了,报文在网络中环路转发,一直绕圈的情况也是会出现的,所以就需要对报文进行一段时间的清除
本质是一个计数器,是报文可以在网络中生存的最大时间,每经过一个路由器,TTL就会减减,等到小于等于0时,该报文就会被其所在的路由器清理。
(⑦)、16位标识
不同报文,标识不同;相同报文,标识相同。
(⑧)、3位标志

(⑨)、13位片偏移
就是每个分片在原始报文的位置情况。
(⑩)、16位首部校验和
解决数据报比特位传输过程中因为磁场而发生比特位翻转,进行校验操作。
(2)、子网划分
①、建立共识:网络本身是几十年发展的产物,网络建设,也是被运营商经过几十年规划进行建设的,也就是说,网络是被设计过的!— 所以我们最应该关心的是报文路由的时候,网络是如何被设计的!
举个栗子
(①)、学号 = 院号 + 学号
我们就把自己的学号看作是一个IP地址,而IP地址由目标网络和目标主机构成。我们自己所在的专业就是网络,我们在本专业中的编号就是主机号。
(②)、圈表示的是我们的群。
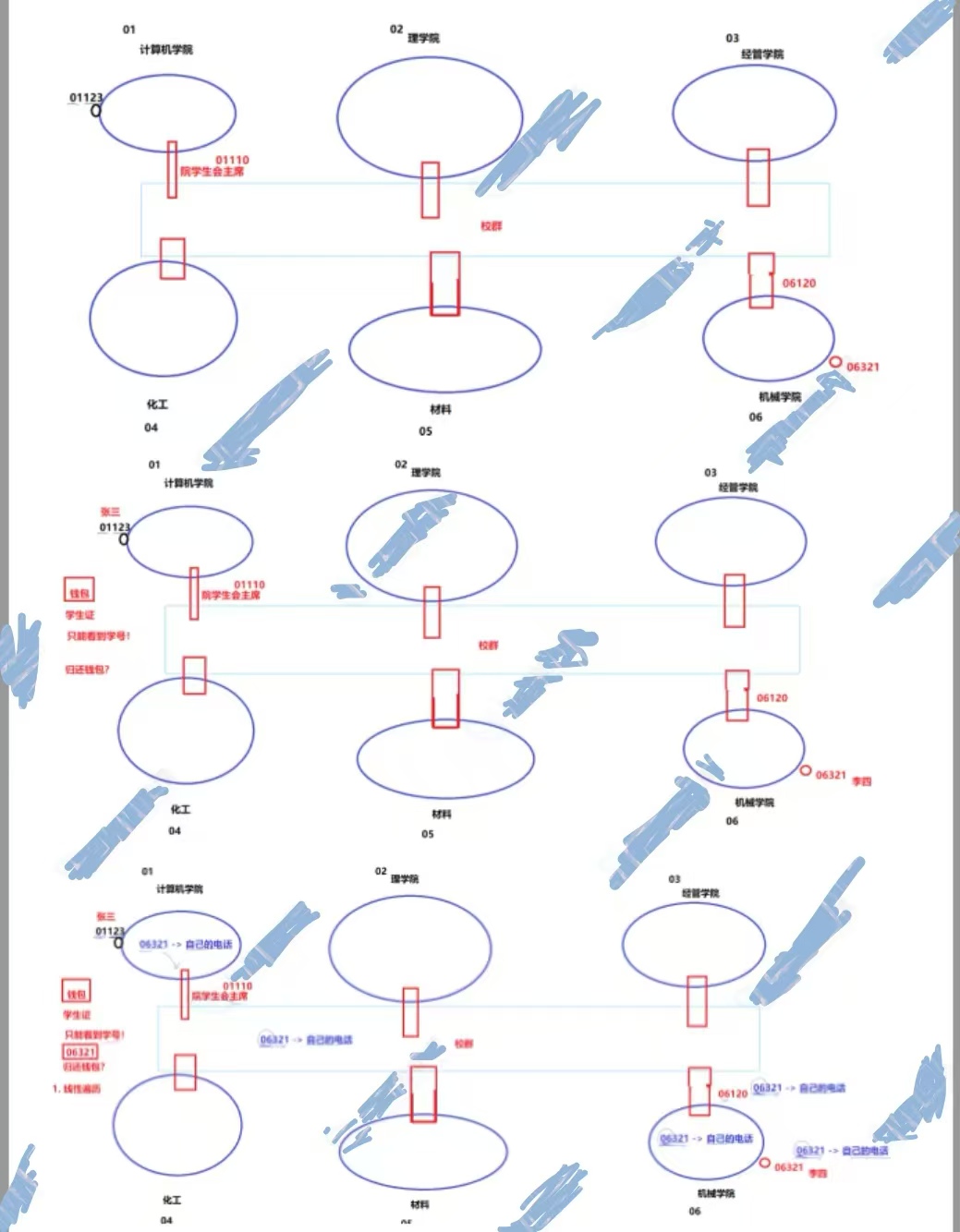

我们自己所在的学院就是一个内网,别的学院就是不同的外网,我们自己学院的管理者就是与其他学院沟通的出入路由器,假设每个学院的管理者熟知不同院系的编号,以及自己院系所有学员的编号。
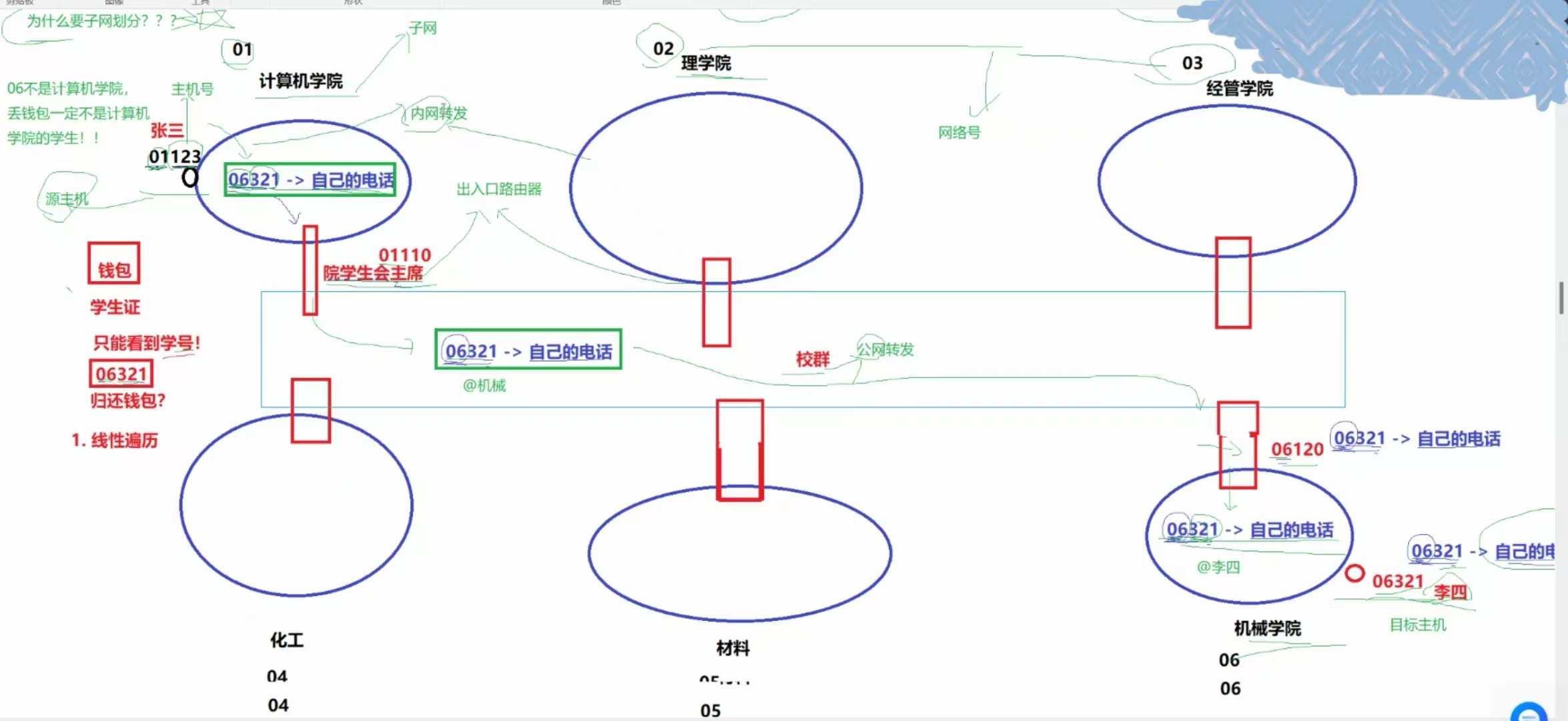
(③)、院学生会主席是出入口路由器
(④)、张三将消息@给院学生会主席是内网转发
(⑤)、校群是一个公网
(⑥)、01、02等这些是网络号,后三位是主机号
(⑦)、在我们没有上大学的时候,上面的学院、院号等概念,已经被学校精心设计过了!
学校就是运营商
划分学院并且带上唯一的编号的过程叫做:子网划分!
问题:为什么要子网划分?(为什么学校要划分不同的学院?)
路由报文,本身其实是查找主机的问题!
而查找的本质其实是淘汰的过程!!–> 换句话说,只要淘汰的效率高,那么查找的效率就高!
原因是:查找目标主机,先必须查找目标网络,而查找目标网络的本质就是可以淘汰其他网络,可以在全网中提高查找目标主机的效率!
②、子网划分的本质:

把32位比特位进行划分,确定网络号有多少位!
子网划分是一种方案,子网会配置在连接在网络的设备当中!
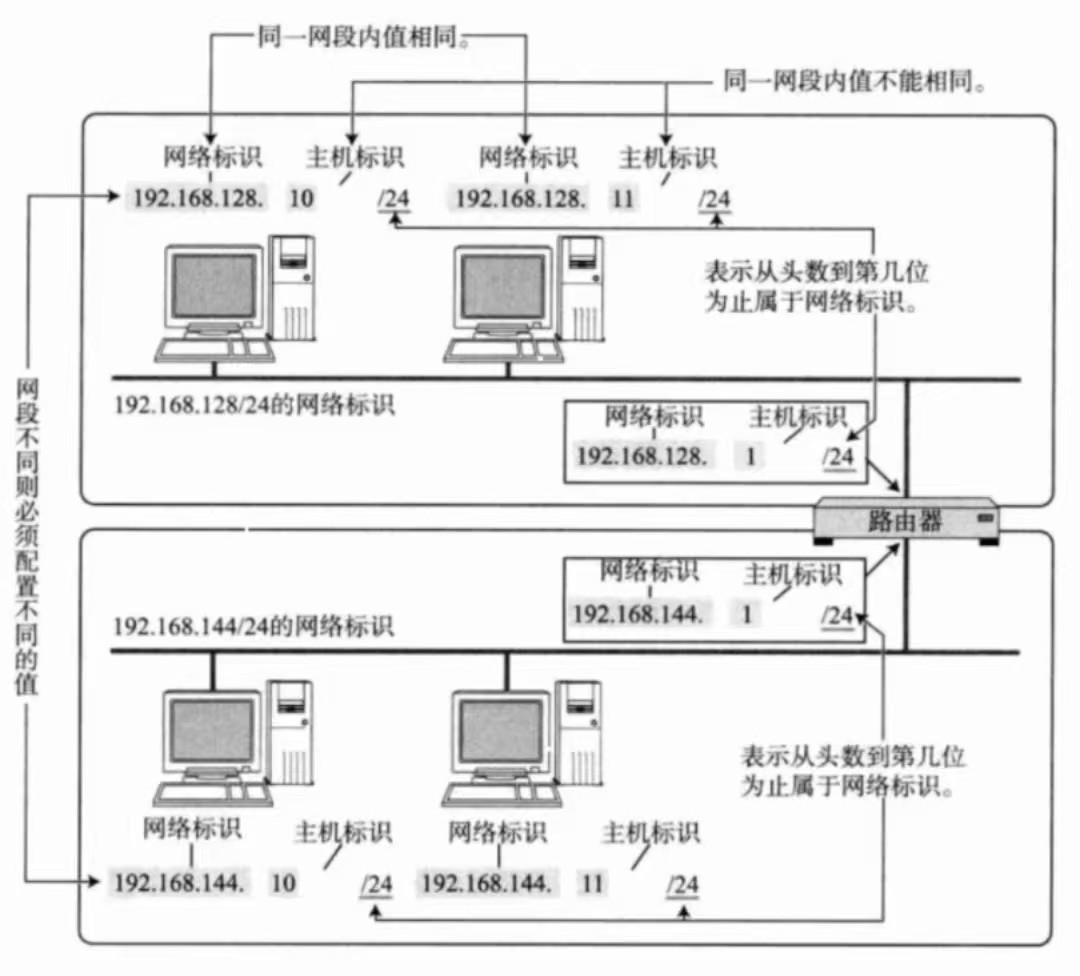
路由器至少要有两个IP地址!

(①)、分类划分法
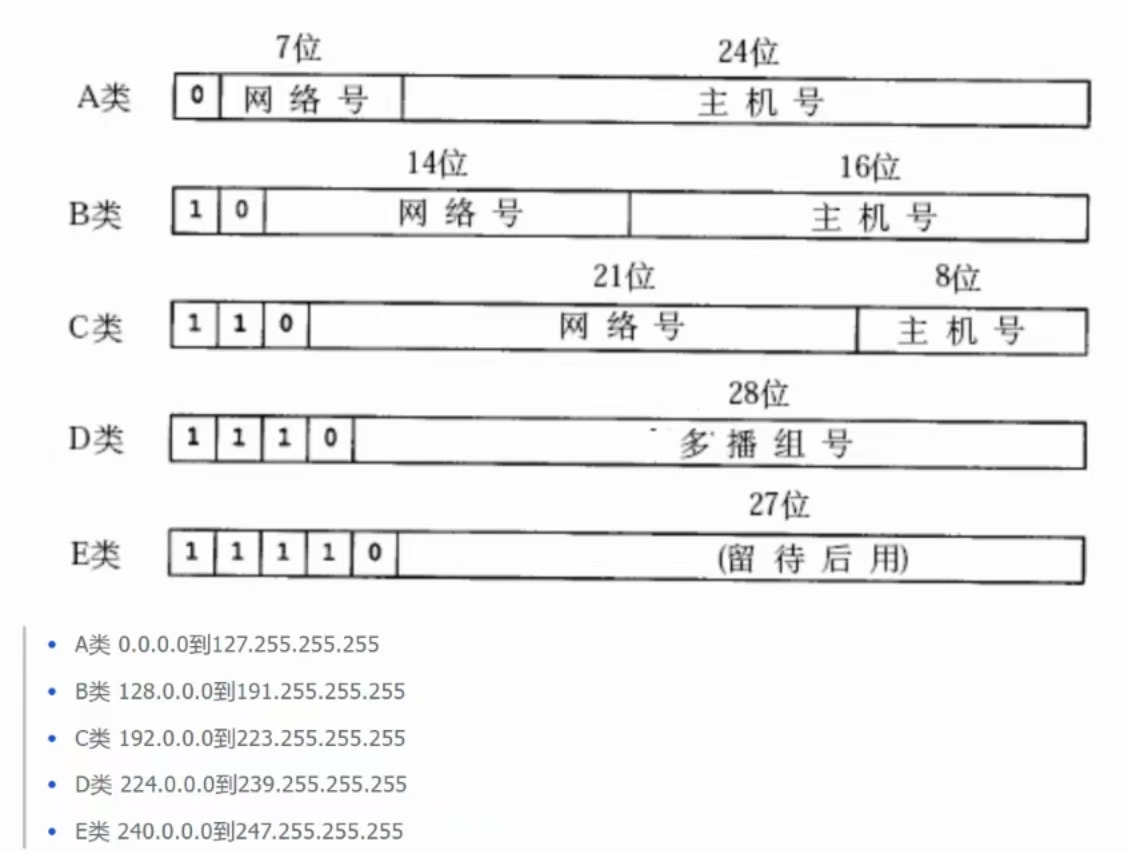
举个栗子
就比如说A类网络,全世界就有2的7次方个;B类网络,全世界就有2的14次方个,以此类推。
结论一:IP地址是有用的,是有限的,是资源 — 是资源,就会被各个国家的运营商争抢
为什么要争抢呢?
因为可以搭建自己国家的子网,发展自己国家的互联网经济!
(②)、CIDR划分法

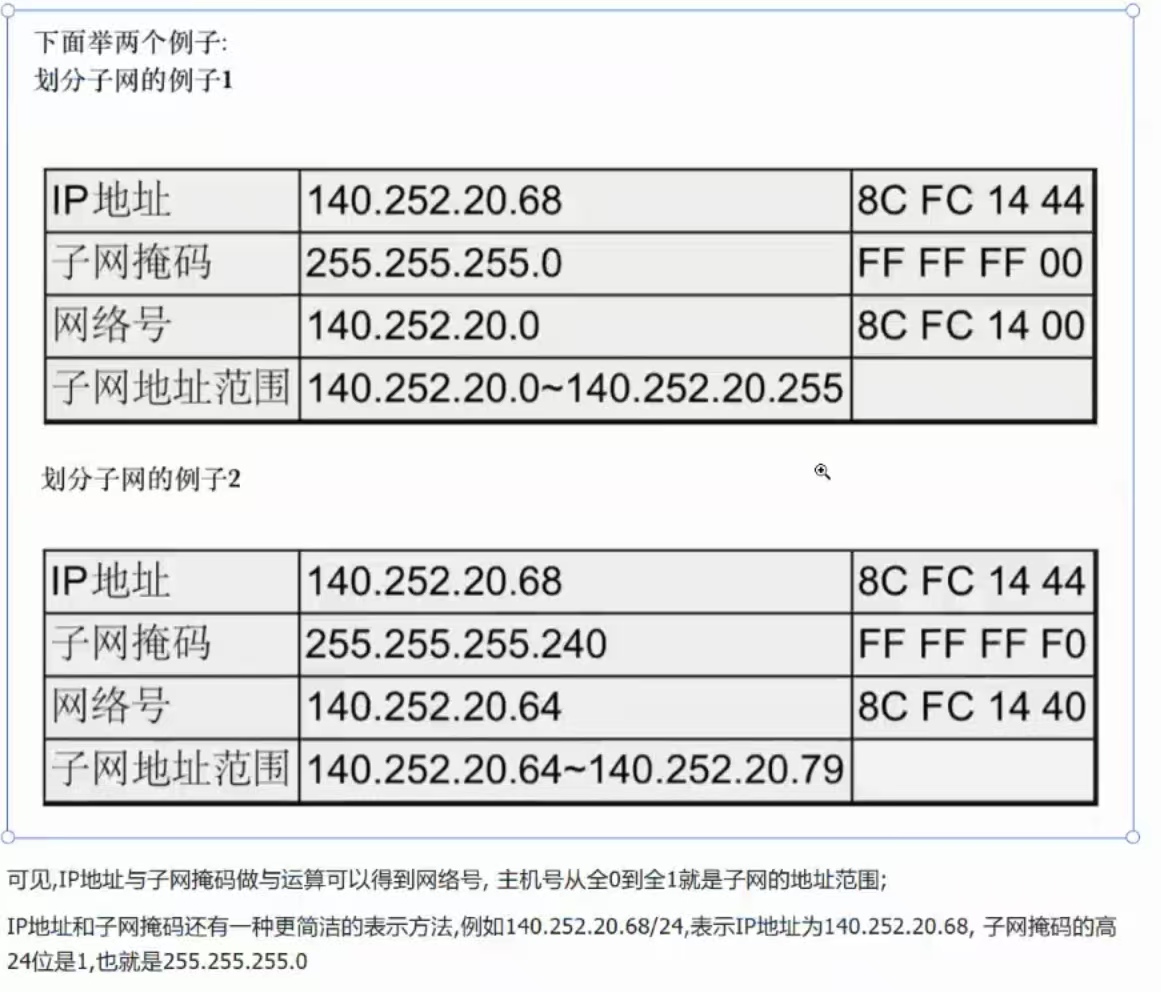
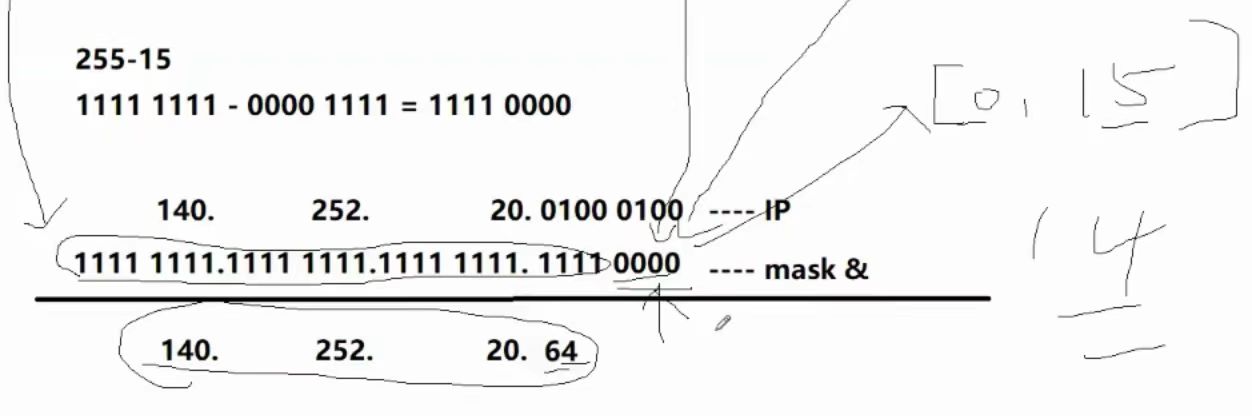
IP地址与子网掩码会被配置到路由器中,按照网络号范围给主机配置具体的IP地址
子网掩码存在的意义?
可以把分类划分的网络的IP地址资源得到充分的利用!9
③、电脑中的IP地址从何而来?
电脑在没有联网的情况下,是默认没有IP地址的,这个IP地址是用于上网的,而主机自带的IP地址不能用于上网,用于本地通信。
而我们的电脑想上网,就需要联网,而连接路由器之后,路由器就会给主机分配IP地址!!这种方式被叫做DUCP!
DHCP(应用层协议)
我们的电脑手机,在没有联网的情况下是没有对外联系的IP地址的,有一个自带的管理地址,是实现本地通信用的,而我们在连接路由器的时候,其实就是在给自己申请IP地址的过程,这个过程被叫做DHCP!
为什么说DHCP是应用层协议
因为路由器具有构建子网的能力(自动的),并且它是工作在应用层的设备(在浏览器输入路由器背后的地址,就可以完成一系列操作,就可以证明它是工作在应用层的)!
④、特殊的IP地址

⑤、问题出现:不够用了
三种解决方式

PS:CIDR方法只是提高了IP地址的利用率,IP地址的数量上限还是没变的
(3)、私有IP地址和公网IP地址

①、网络宏观上被分为:公网 : 内网(子网,局域网) = 1 : n
②、10.*、172.16.*到172.31.*、192.168.*这些才能被用作内网(子网、局域网)IP,不在这个范围内的都是公网IP!
③、注意:在网络通信的过程中,私有IP不能出现在公网上!
为什么不能出现,因为内网IP可能会重复!
A家的内网是192.168.,B家的内网也可能的192.168.,就可能会导致连接的主机的内网IP重复,所以假设A家给公网发送请求报文,公网返回应答的时候,返回给谁啊,有太多种可能了!
但是,因为有NAT技术,不影响内网向外网通信!
所以NAT技术解决的是IP地址不足的问题!!
④、我们普通人直接接触的根本就不是公网,我们直接接触的都是内网(局域网、子网)!
(4)、内网(子网、局域网)(运营商构建的)
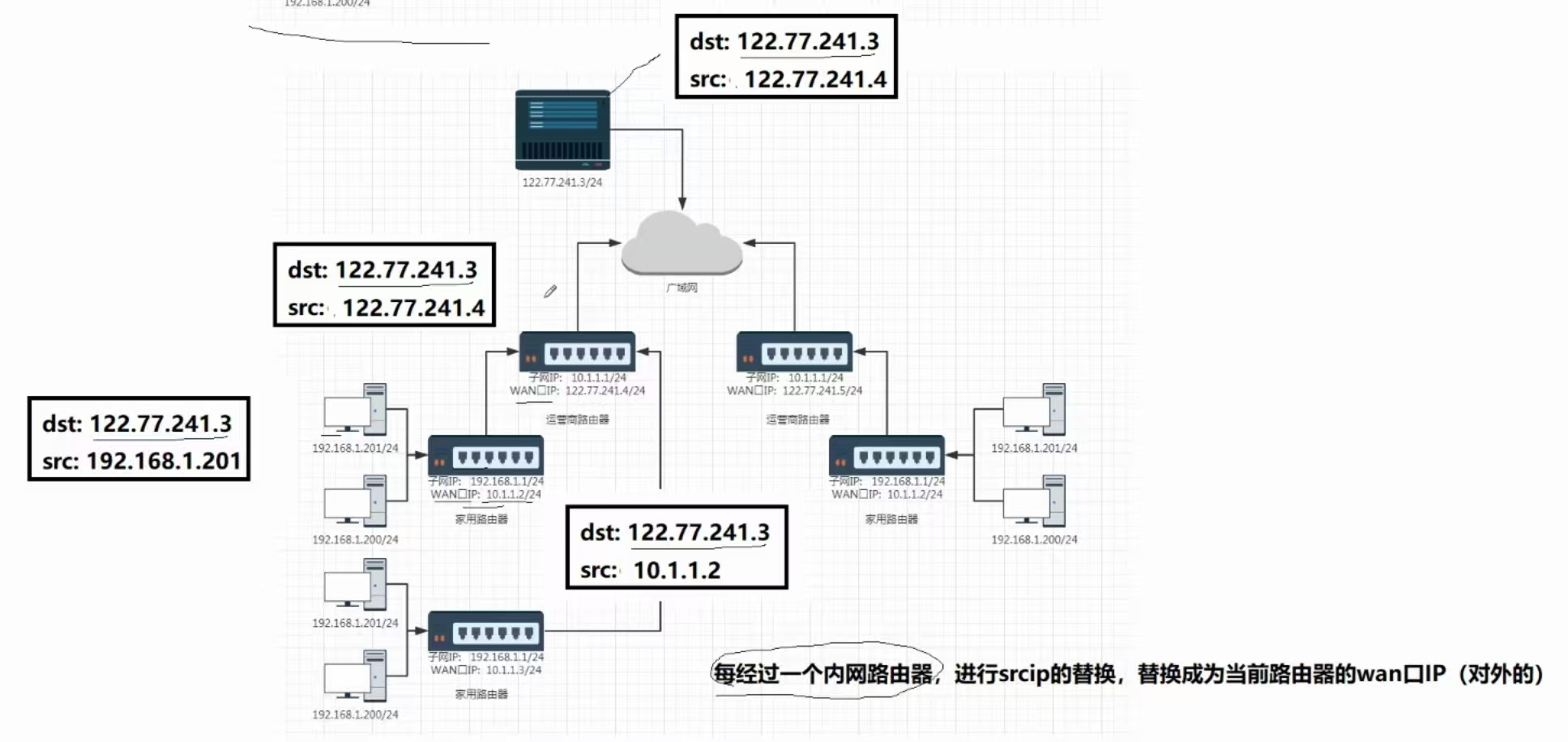

①、路由器本身就有构建子网的能力,还有给子网中所有主机分配IP地址的能力
路由器分为企业级和家用级
路由器自己有两个IP地址,一个是WAN口IP,一个是子网IP
②、从内网到公网,根本就没有多复杂,因为内网IP是固定的,就那么几种!
所以路由器一识别IP的开头部分,就知道是公网IP还是私有IP,就能快速做出转发响应。
③、为什么内网IP不能出现在公网中?
因为内网IP会重复,不同局域网中的内网IP地址是会重复的!
所以一旦将应答报文返回,相同的内网IP数不胜数,所以给谁呢?
④、所以如何解决内网IP不能出现在公网,同时又能准确的收到公网发送回来的报文?
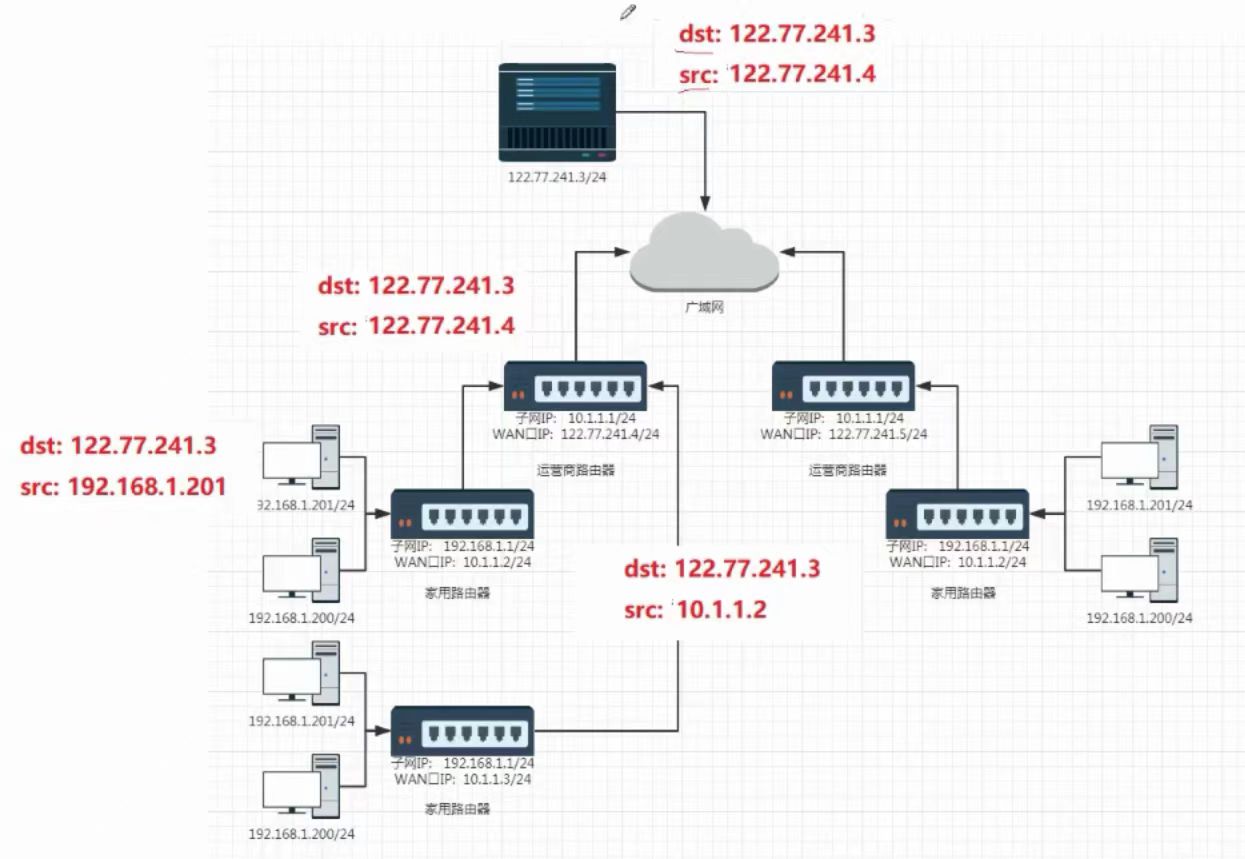
每经过一个内网路由器,进程srcip的替换,替换成当前路由器的wan口IP(都是对外的)
这种技术被叫做NAT(网络地址转换)
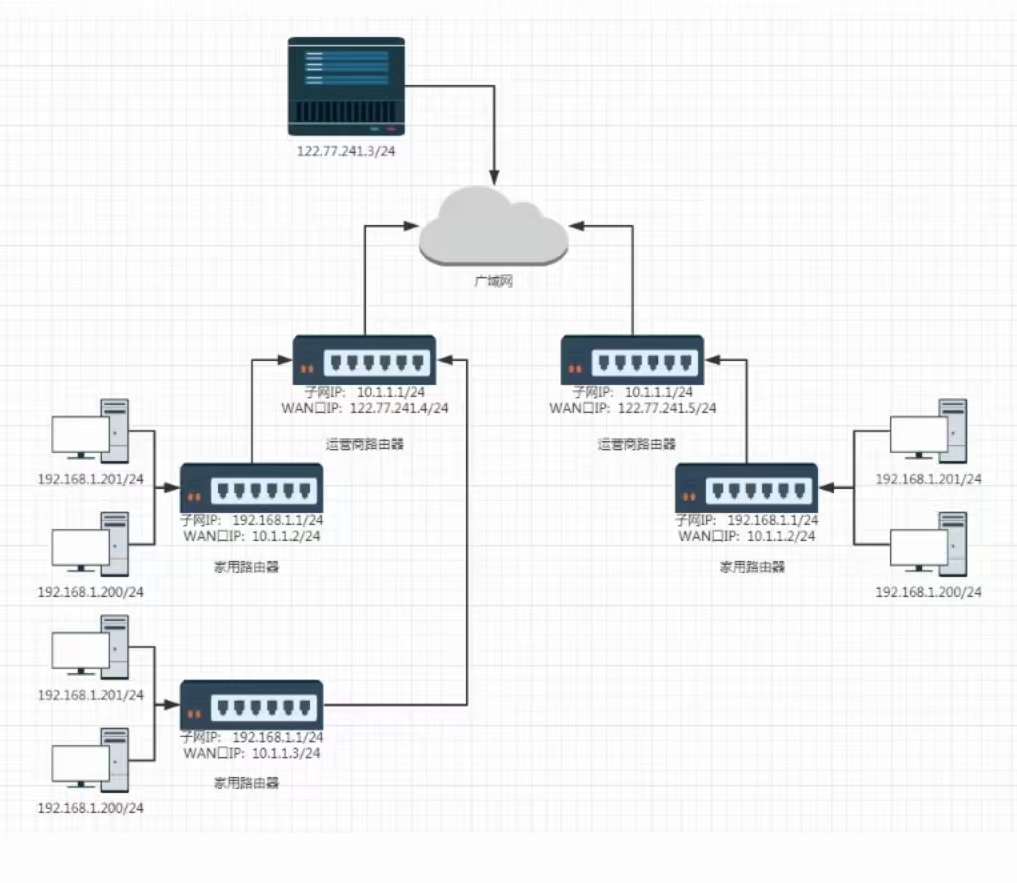
⑤、回来的报文,一定可以把报文先交给子网出入口路由器,剩下的工作,就是内网转发了!
这部分后面会说!
⑥、运营商可以控制我们的报文是否转发到公网
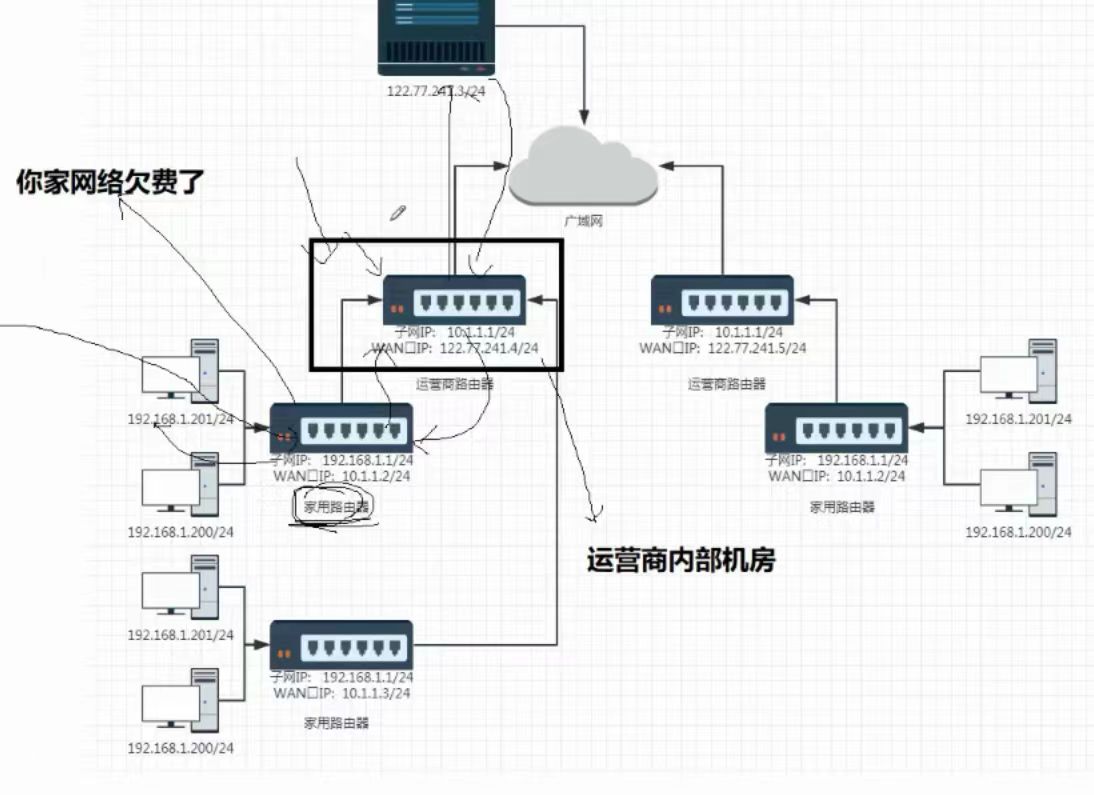
(5)、公网

①、公网IP是由各个国家的运营商自主申请的
分配公网IP的事情,不是简单的按照国家为单位进行划分的,要结合网民数量,按照地区进行划分的!
②、运营商不仅仅要组建内网,也要组建自己国家的公网环境
③、一个区域,究竟有多大的网络,取决于自己有多少个公网IP
④、公网只有一套,而内网可以有很多,这就大大的缓解了IP地址不够用的情况,妙啊!
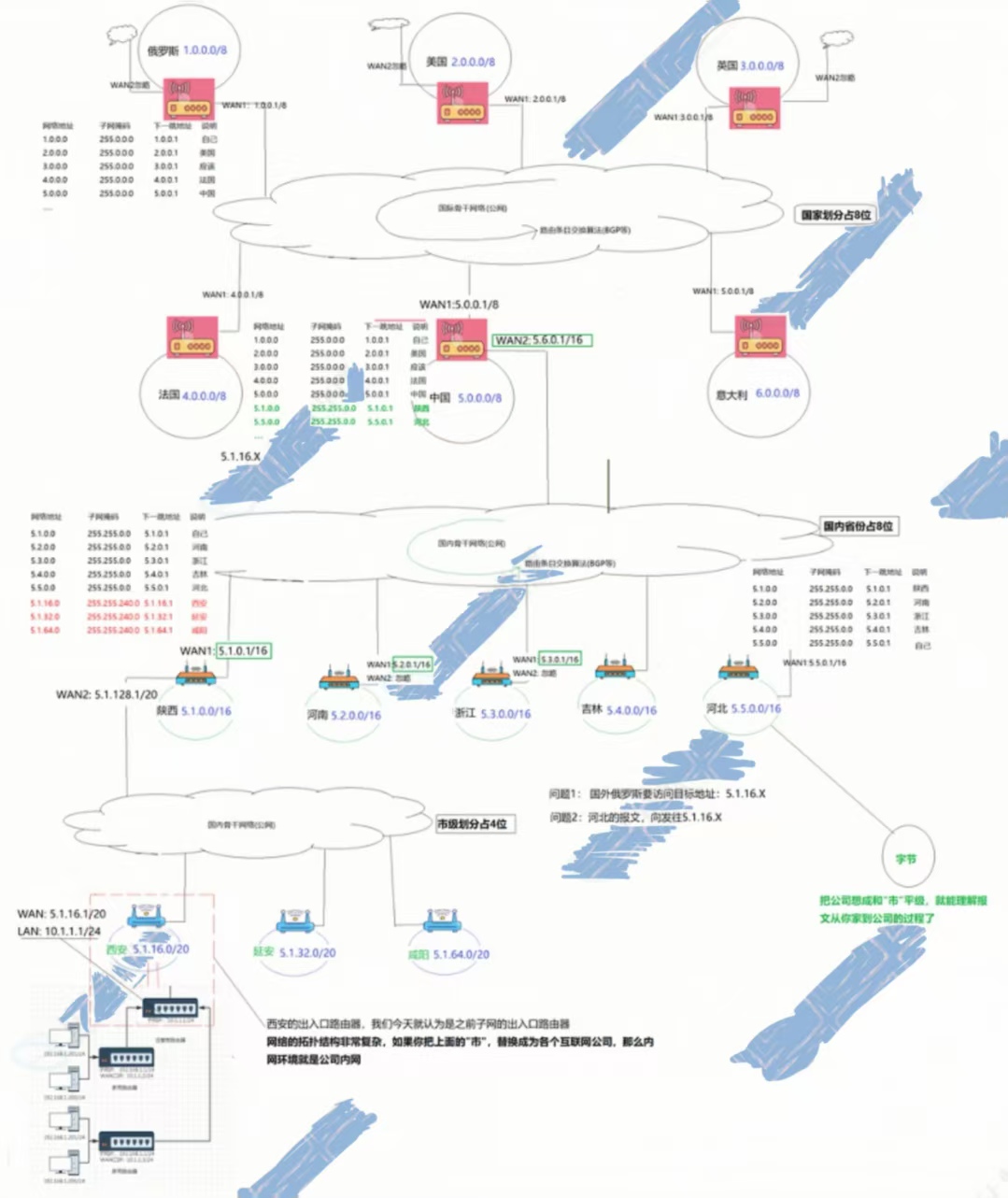
⑤、结论:公网路由器的路由表算法和内网的路由表算法复杂度是不同的!
路由条目交换算法(BGP等),每个国家都会知道其余国家的IP地址、每个省份都会知道不同省份的IP地址、每个城市都会知道不同城市的IP地址!
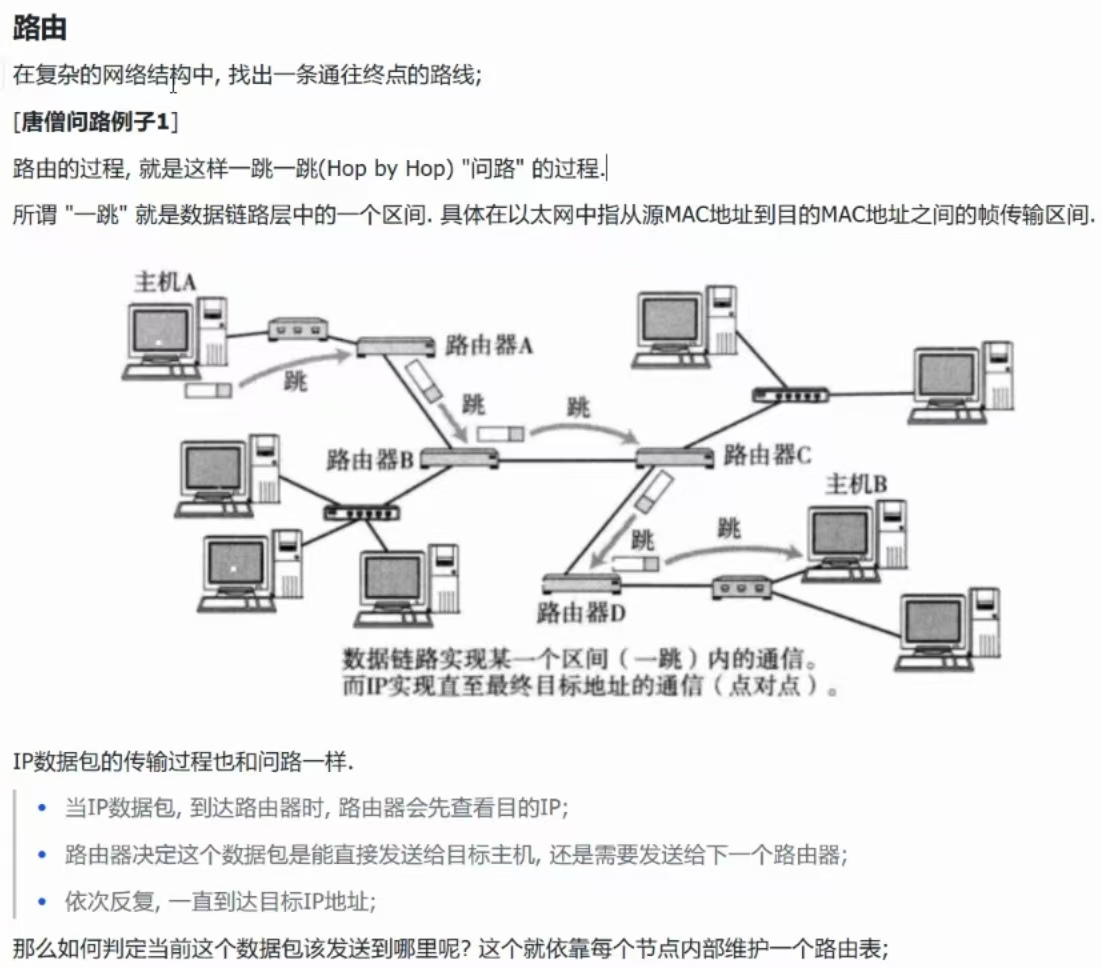
(6)、路由
本质:从一个子网,进入到另一个子网。
查找路由表本质是按照目的地址进行查找的。
路由报文,本质就是查找主机的问题!
查找的本质是淘汰的过程!!
路由的三种情况
第一种:知道去哪里
第二种:查路由表没有查到,直接default缺省路由
第三种:已经到达目标网络的输入口路由器,准备进行内网转发
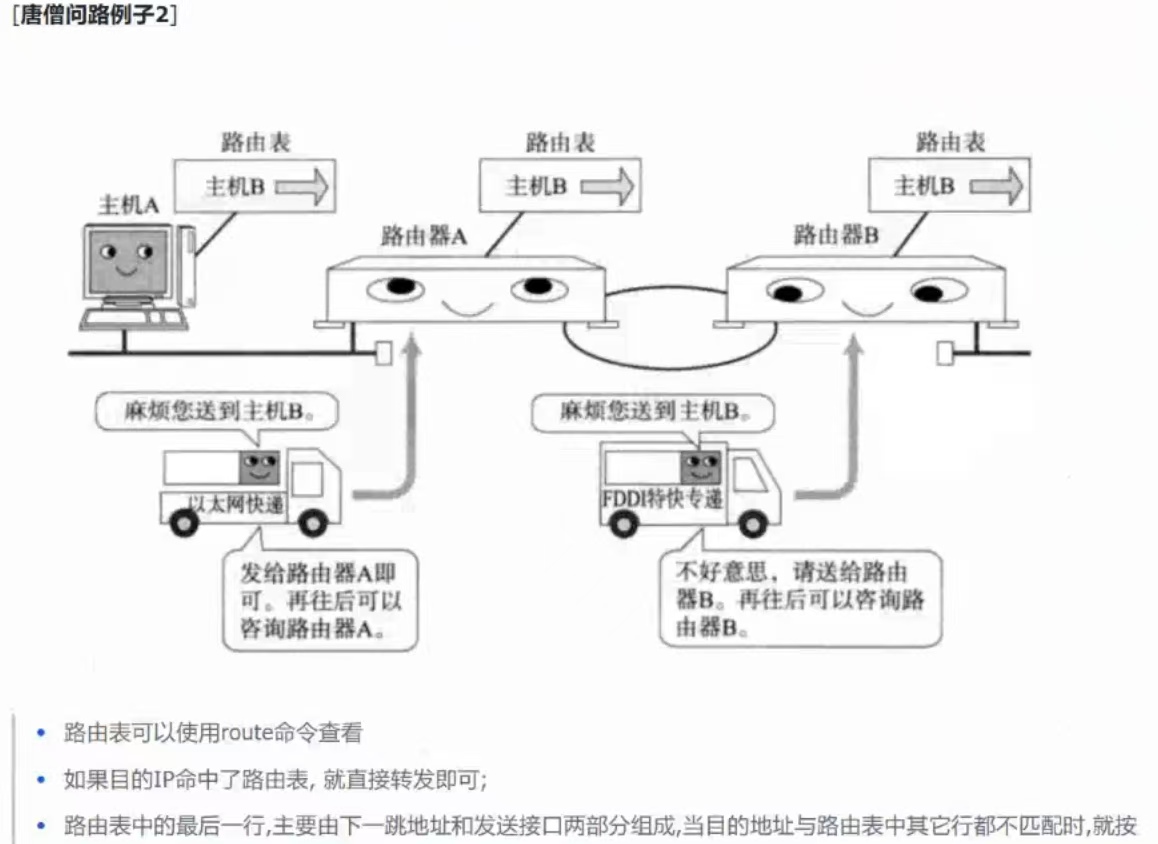
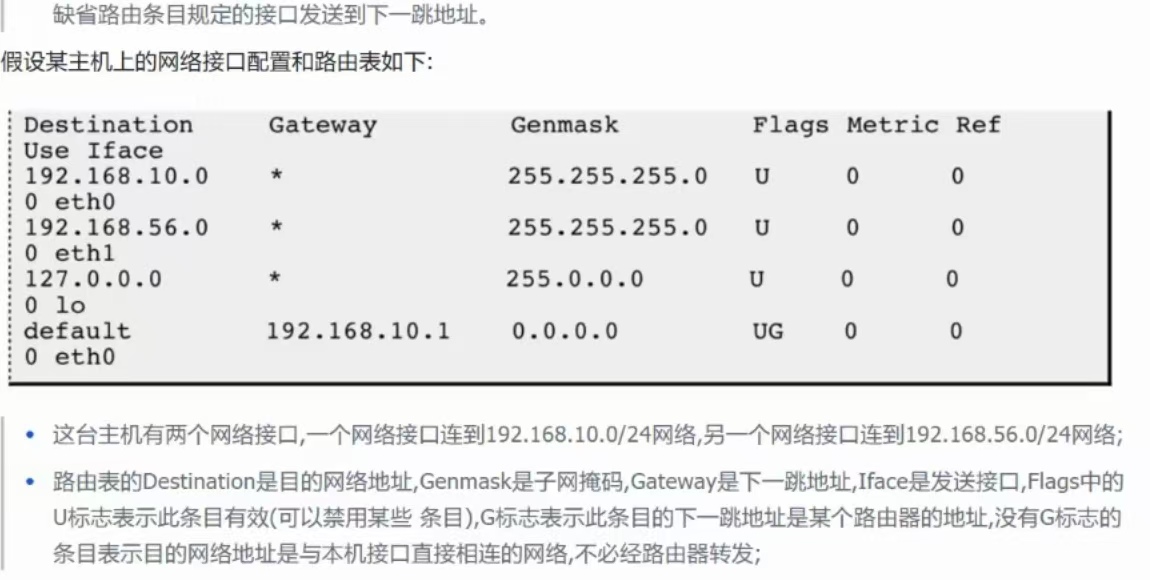
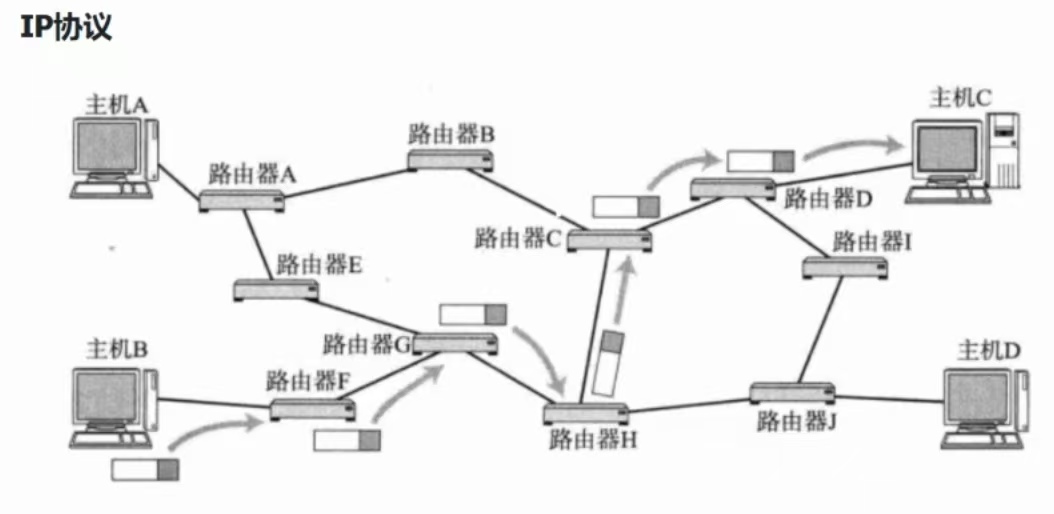
路由转发实例:


2、数据链路层:子网(局域网)通信,解决的是主机A怎么到的主机B
(1)、数据链路层需要注意的点:
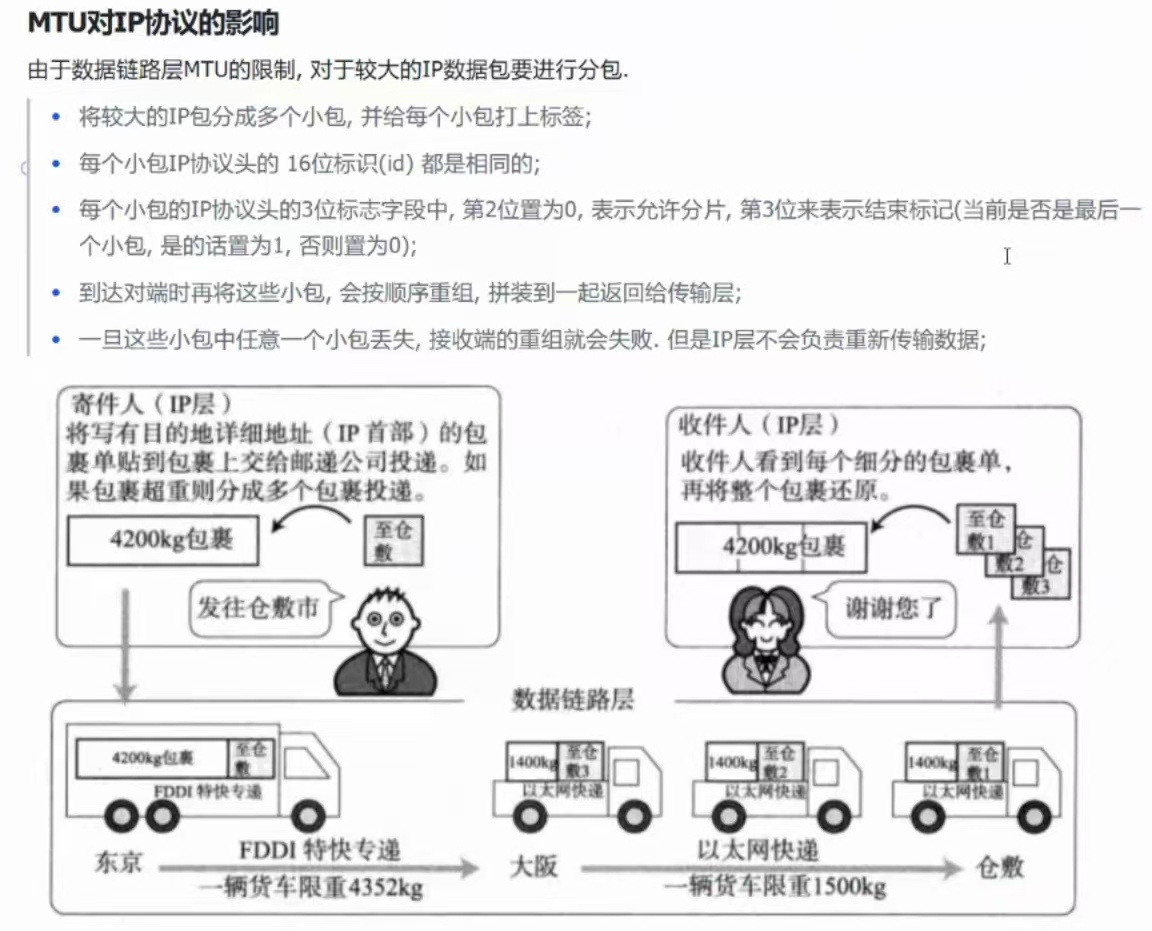
数据链路层,从上层接收下来的完整报文,大小不能超过MTU(最大传送单元,一般是1500字节),但是如果超过了,就需要在网络层中进行分片,到达对方主机的时候,在对方的网络层再进行组装。
①、在网络层就拆分,而不是交给数据链路层进行拆分的原因是
因为数据链路层对网络层要传输的报文不熟悉,而网络层自己对自己要传的报文肯定是熟悉的,所以网络层进行拆分比较保险。
②、但是需要注意的是,如果一个报文的任意一个分片丢失,就会导致该报文失效!
结论一:IP报文可能要进行分片与组装!!
结论二:网络通信中,如果过多进行分片,就会导致丢包概率!!!
结论三:分片与组装不是主流,而是被迫为之!!!!
IP分不分片,不是由IP自己说了算的!
所以就要减少分片,那么在哪一层开始呢?在传输层开始!
结合最大分片的大小1500字节,以及TCP报头大小20字节,IP报头大小20字节可知,传输层发送的最大数据大小是1460字节!
这1460字节被叫做MSS(最大段尺寸)
所以我们之前学习滑动窗口的时候,它里面的数据是一段一段传输的,而不是一次性发完的,就是因为不能超过最大值!
注意:分片不仅仅是在源主机和目的主机之间进行,有可能因为传输经过的路由器流量过小,导致报文分片传输。
即使在路上被路由器分片了,也没关系,16位标识、3位标志、13位片偏移就可以非常有效的解决分片问题!
③、如何进行分片与组装?
(①)、甄别特定报文是否被分片了
3位标志中,更多分片标志位是否为1,1就是分片
更多分片可能是0,但是如果13位片偏移如果不是0,就证明肯定是分片了
所以只有3位标志中的更多分片为0 && 13位片偏移为0,才说明不是分片
(②)、保证自己把分片都收全了
相同标识的分片,聚合在一起
但是怎么保证收全了?
如果第一片丢失
片偏移为0的分片没有了!
如果中间片丢失
把收到的所有分片,按照片偏移进行升序排序
片偏移+自身报文的长度=下一个分片的片偏移的数字!
如果最后一片丢失
更多分片为0的分片没有了!
(③)、组装
只要按照片偏移进行升序与降序的组装,就完成了组装!
(2)、数据链路层的概念

①、网络转发,本质是在子网与子网之间进行转发的
②、同一个子网中,数据链路层就是解决局域网通信的问题,就是解决一个主机怎么把数据交给另一个主机的!
③、传输数据不是目的,是手段,交换应用层报文,完成应用才是目的!
(3)、以太网
①、认识以太网

②、以太网帧格式
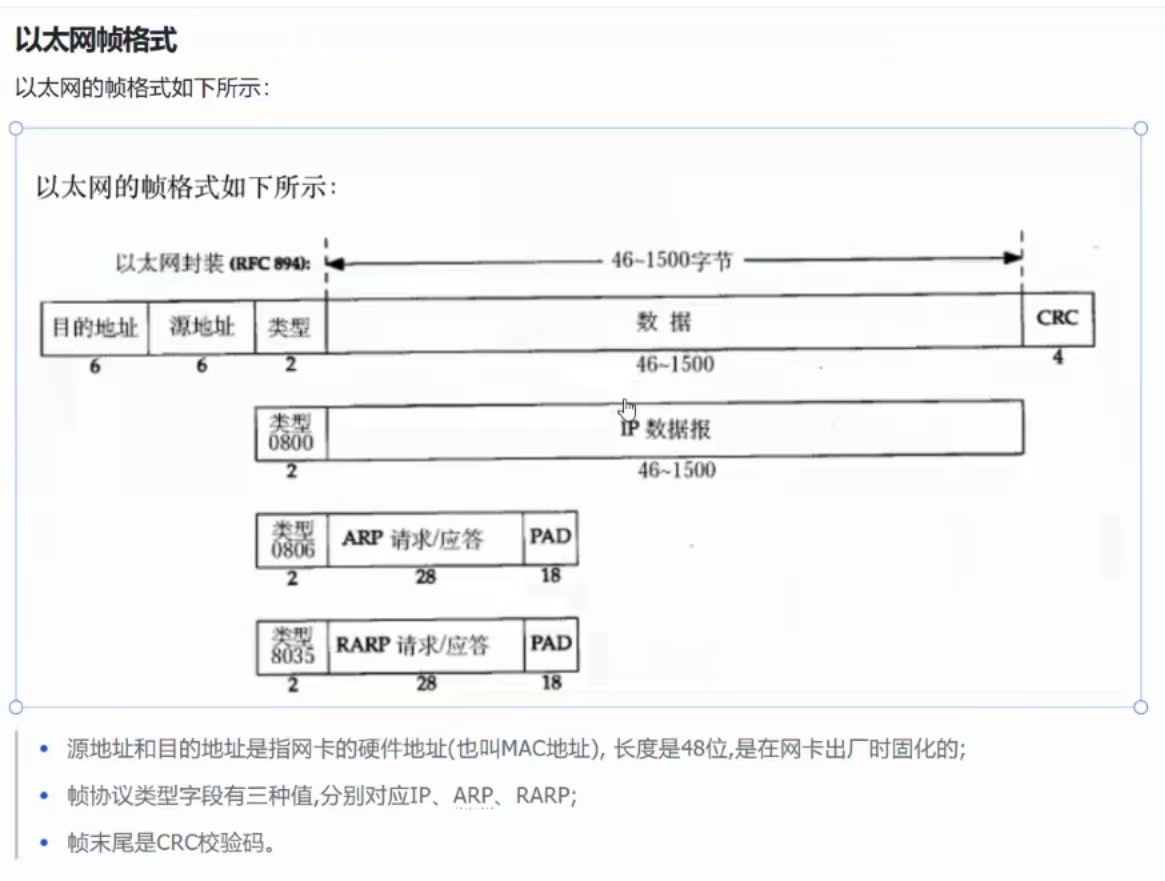
每台主机还配备MAC地址,其只在局域网通信中有效!
数据
数据部分大多数都是IP报文,还会包括ARP,以及RARP。
如何分离?
固定长度的协议,去除固定长度的目的地址、源地址、类型以及CRC,最后剩下的就是数据部分。
如何分用?
利用帧类型
帧类型为0800,数据部分放的就是IP报文、
帧类型为0806,数据部分放的就是ARP报文、
帧类型为8035,数据部分放的就是RARP报文。
③、认识MAC地址
MAC地址主要用于局域网内标识主机的唯一性!

对比MAC地址与IP地址
IP地址决定了MAC地址的选择。

④、认识MTU

(①)、MTU对IP协议的影响
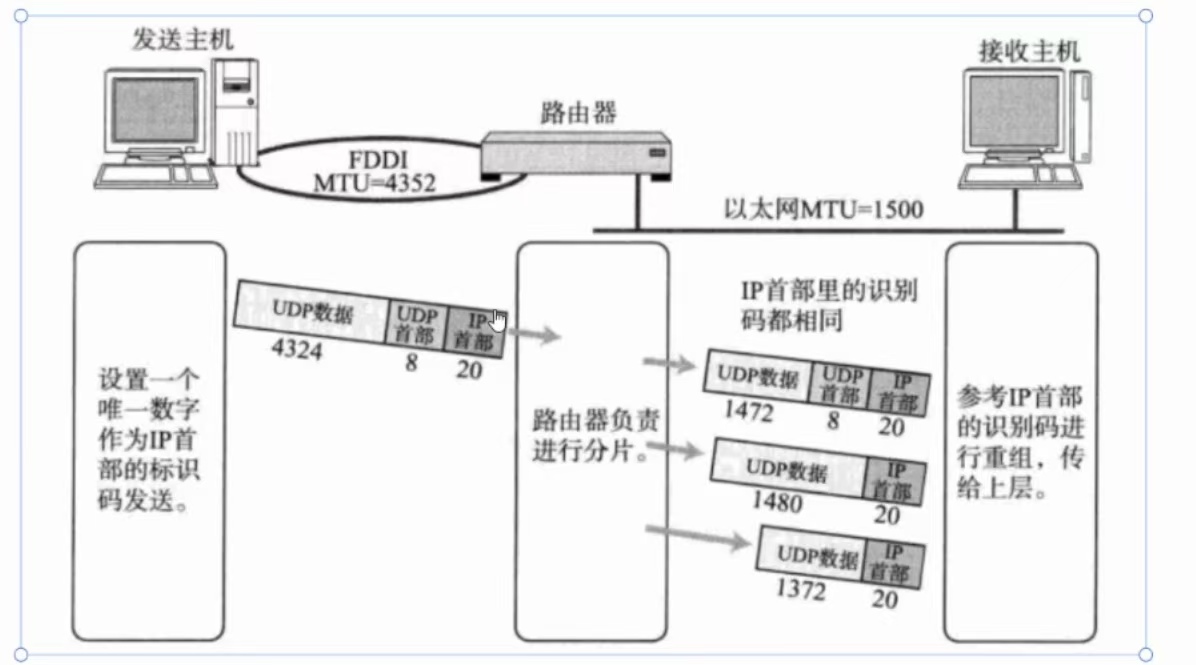
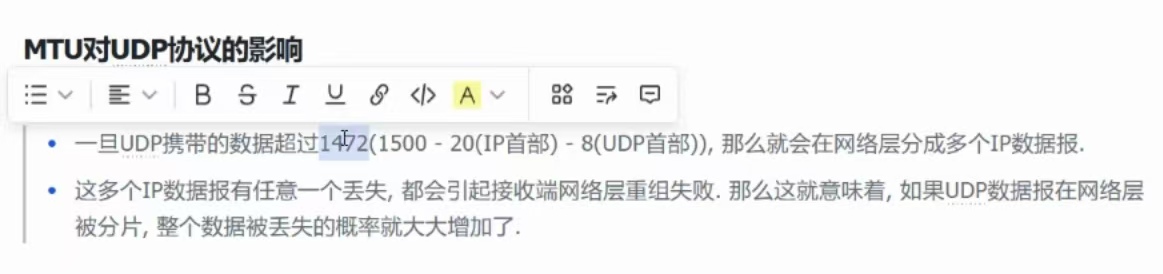
(②)、MTU对UDP协议的影响
(③)、MTU对TCP协议的影响
MSS:1460(通常情况下)
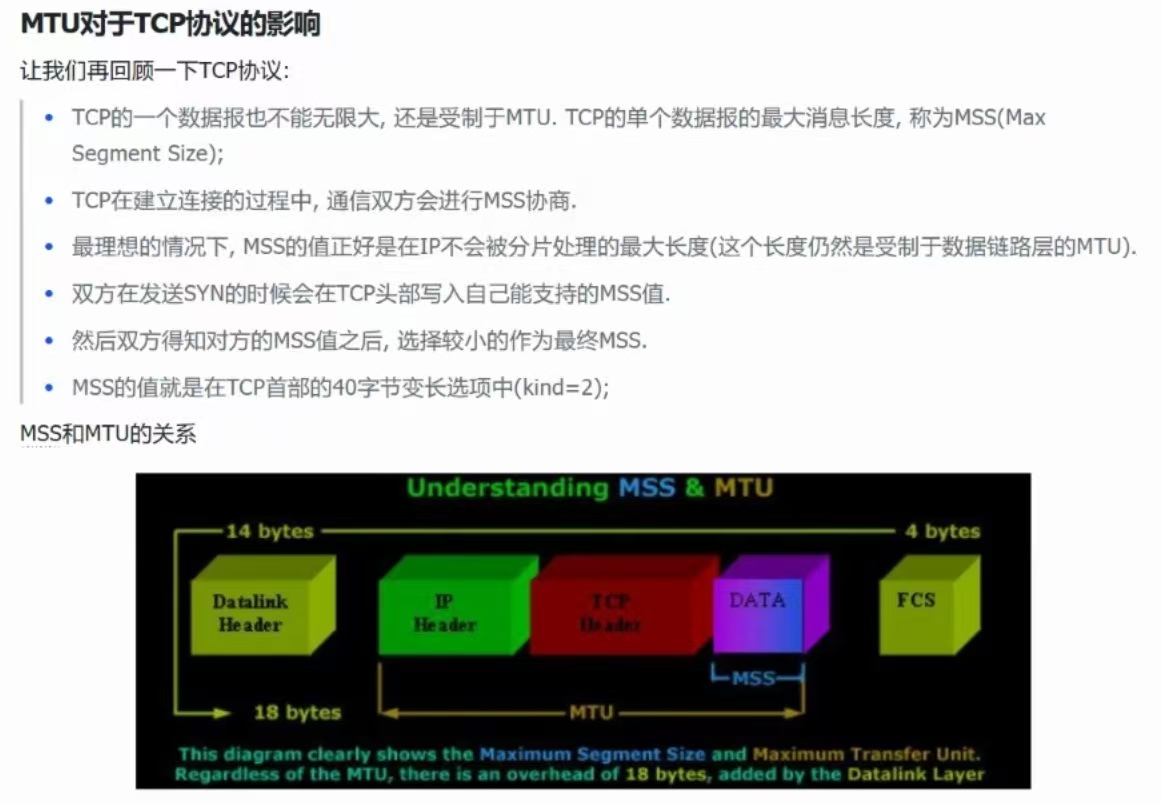
MSS在MTU当中
MSS与MTU的存在就是为了尽可能避免分片。
收发的报文最大长度最好都不要超过1500字节,就是为了方便
所以双方就需要进行MSS协商,并取最小的MSS值
但是MTU的值不是一成不变的,但是不怕,有MSS协商,就可以解决这个问题
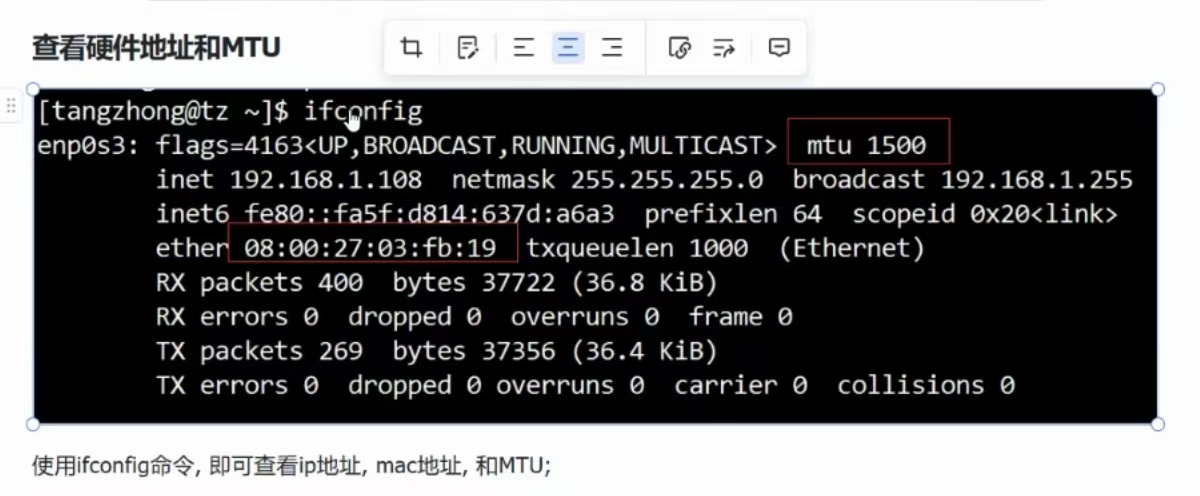
查看硬件地址与MTU
由于UDP不需建立连接,所以它没有MSS这样的可以提前进行协商的方法,所以UDP报文一旦超过临界值,就只能被分片了。
(4)、重谈局域网通信原理
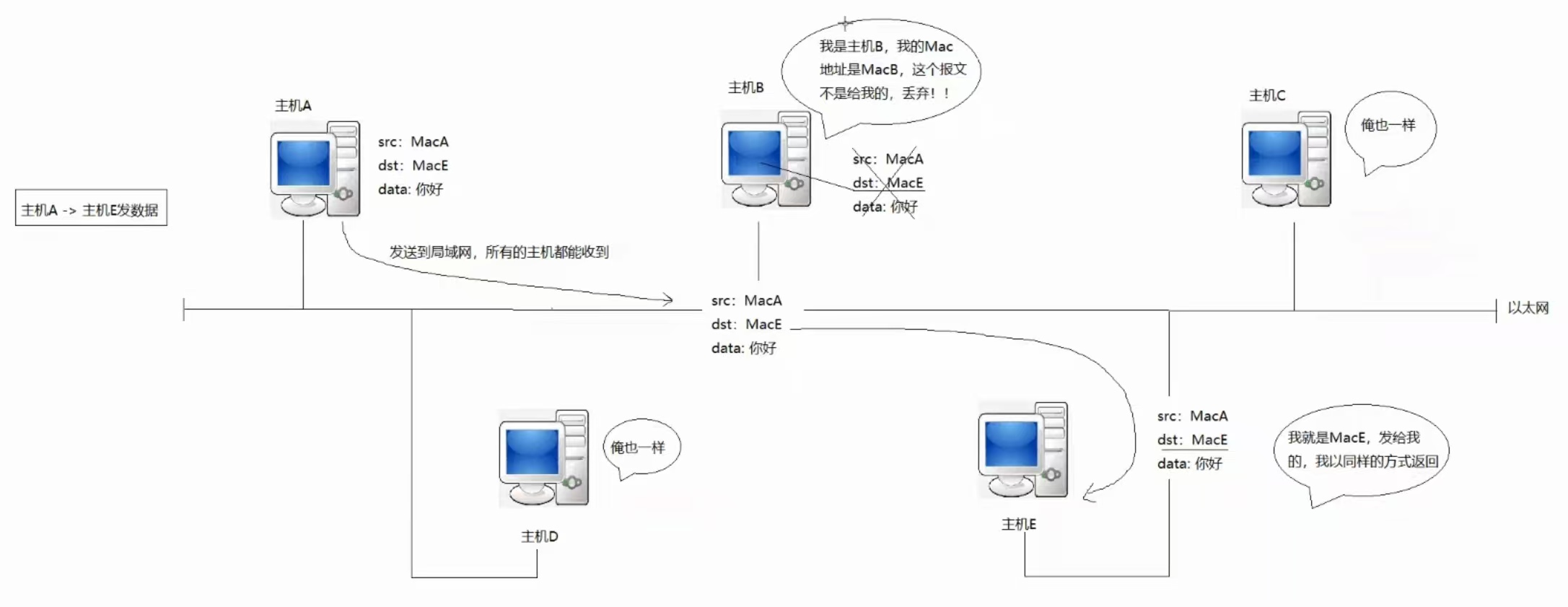
①、回顾一下
之前说过,在一个局域网内,主机A给主机E发的消息是可以被所有在本局域网内的主机接收到的,但是由于目的MAC地址的存在,只有主机E在接收到主机A发送的报文之后,确认是发给自己的,才会进行向上交付,而其余主机在对比完目的MAC地址之后,发现不是给自己的,就会把该报文丢弃。
问题1:为什么主机A要把数据交给主机E?
路由决定
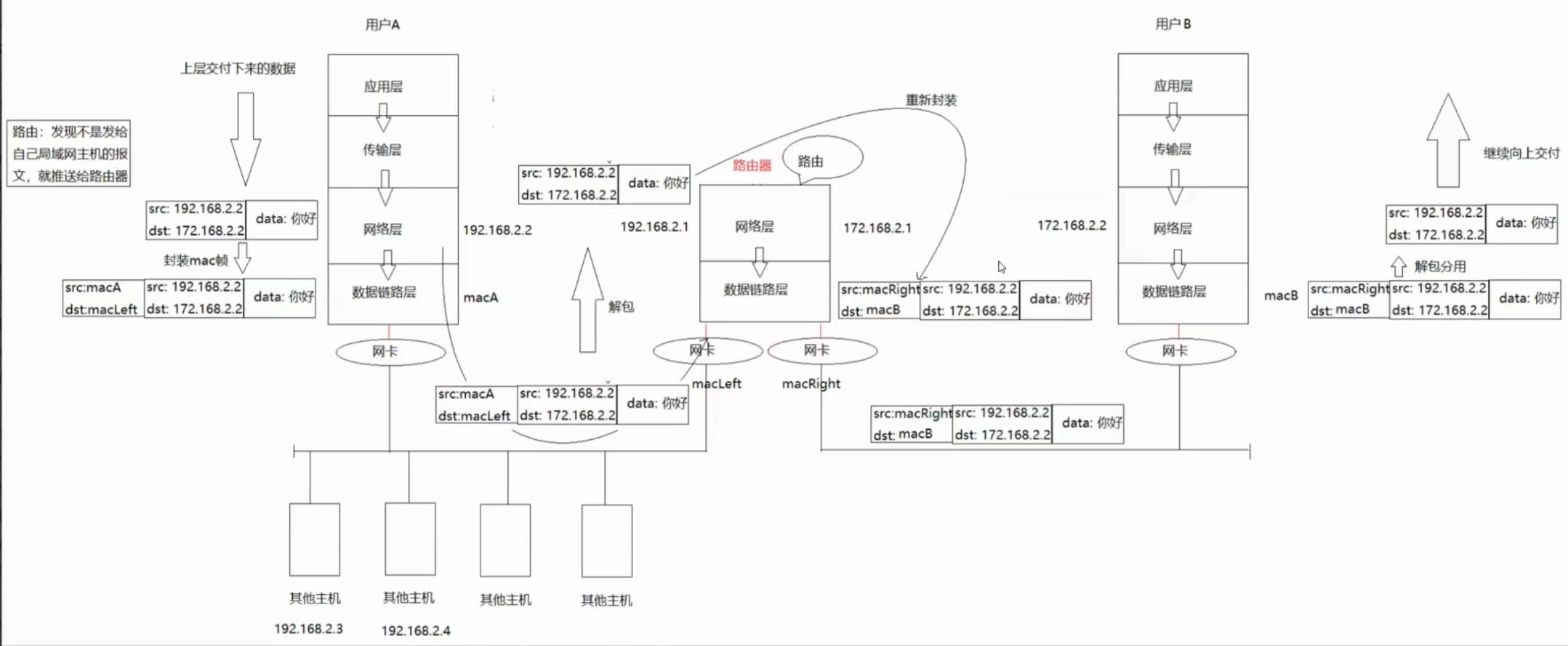
因为网络层有路由表,会对目的IP地址进行比对,从而确定走哪个路由器
问题2:局域网就是一个碰撞域,所以在一个时刻,只能发送一个数据帧
以太网不仅仅是一个共享资源!
结合之前回顾的时候,主机A给主机E发送报文的时候,其余主机也都收到了,这就属于是共享了
还是一个“临界资源”!
一个时刻内,只允许一个报文存在在局域网中,就是“互斥”!
问题3:所以使用以太网的时候,使用时间越长,还是越短好呢?主机A发送数据帧,越长越好,还是越短越好呢??发送的数据帧越多越好,还是越少越好呢???
使用时间不宜过长、数据帧不能太长、数据帧也不能太多
导致单个数据帧不能太短、也不能太长
所以,数据帧既有上限大小,又有下限大小
上限就是1500字节,下限就是45字节!!!
到此,知识形成闭环!
问题4:如果我们只知道目标主机的IP地址,不知道对方的MAC地址,就无法给对方发送数据帧,所以我们需要一种局域网协议,把IP地址转换成为对应的MAC地址—ARP协议(地址解析协议)!
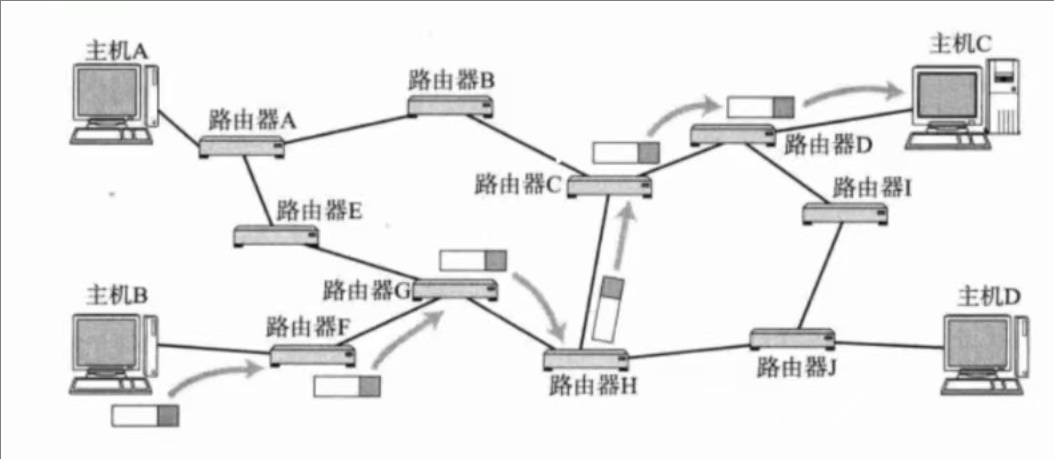
路由器D收到的是一个IP地址,它只知道IPc,不知道MACc,所以就无法封装成MAC帧,无法完成内网转发!
(5)、ARP协议:地址解析协议

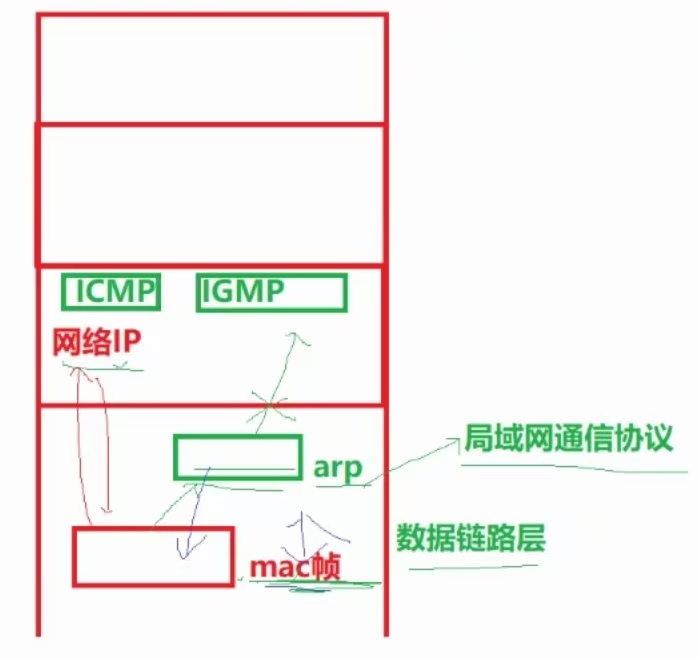
真正在网络物理层上流动的数据—其实是数据帧
①、ARP简要流程
路由器拿着主机E的IP地址,在群里广播,目标主机收到之后,就会对其进行应答,其余主机自动忽略,目标主机会把自己的MAC地址送回到路由器!
请求是广播的,应答是一对一应答的。
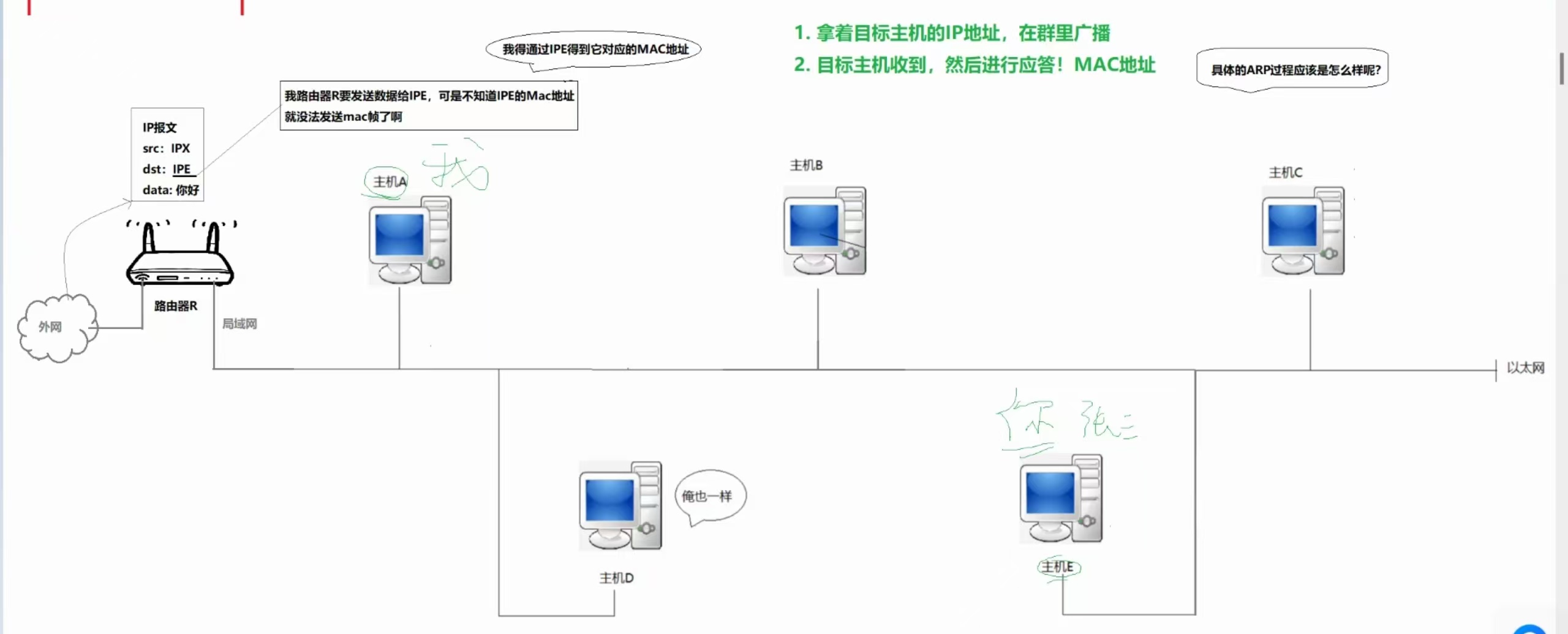
结论:局域网中,任何主机,可能收到ARP请求,也可能收到ARP应答!
②、ARP协议的形式
ARP只有报头!
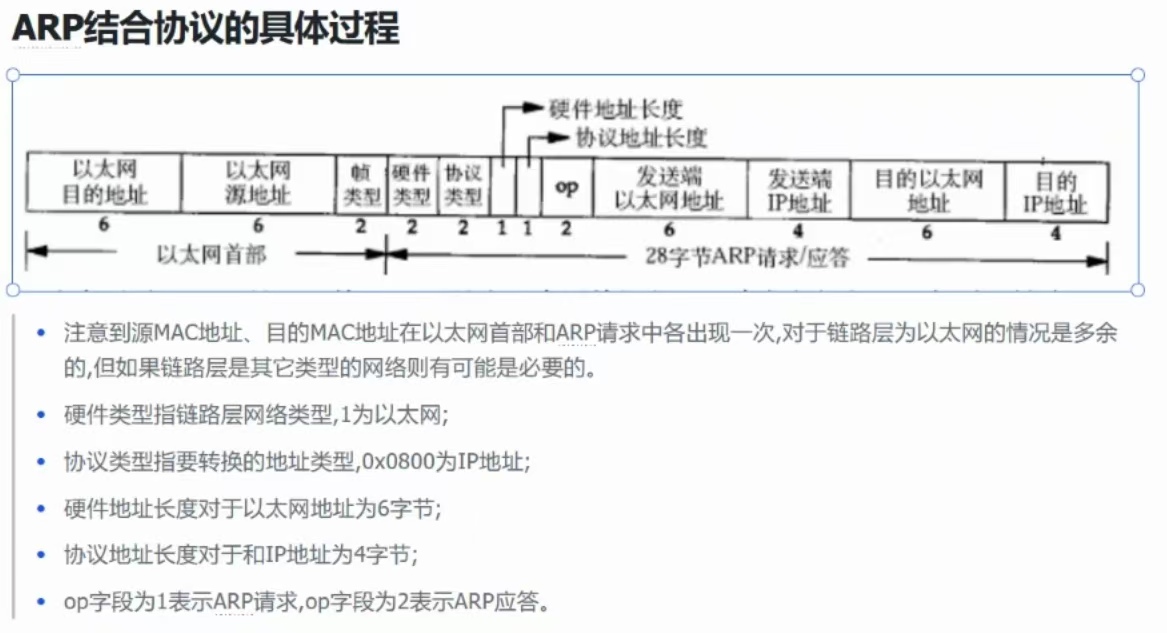
ARP协议定长28字节
但是我们之前在以太网中看到的是MTU最小是46字节啊,这才28字节,所以就会在最后放置一些垃圾数据,凑足46字节!
不能把ARP直接发送给对方,必须包装成MAC帧
硬件类型(1为以太网)、协议类型(0800为IP协议)、硬件地址长度(6)、协议地址长度(4)都是固定的值
OP
一个ARP可能是请求(OP为1),有可能是应答(OP为2)!
请求的时候:目的以太网地址和以太网目的地址不清楚的时候,就写全F,广播地址
③、ARP协议的具体工作流程
只有数据帧才能在局域网中流动
(①)、ARP请求:
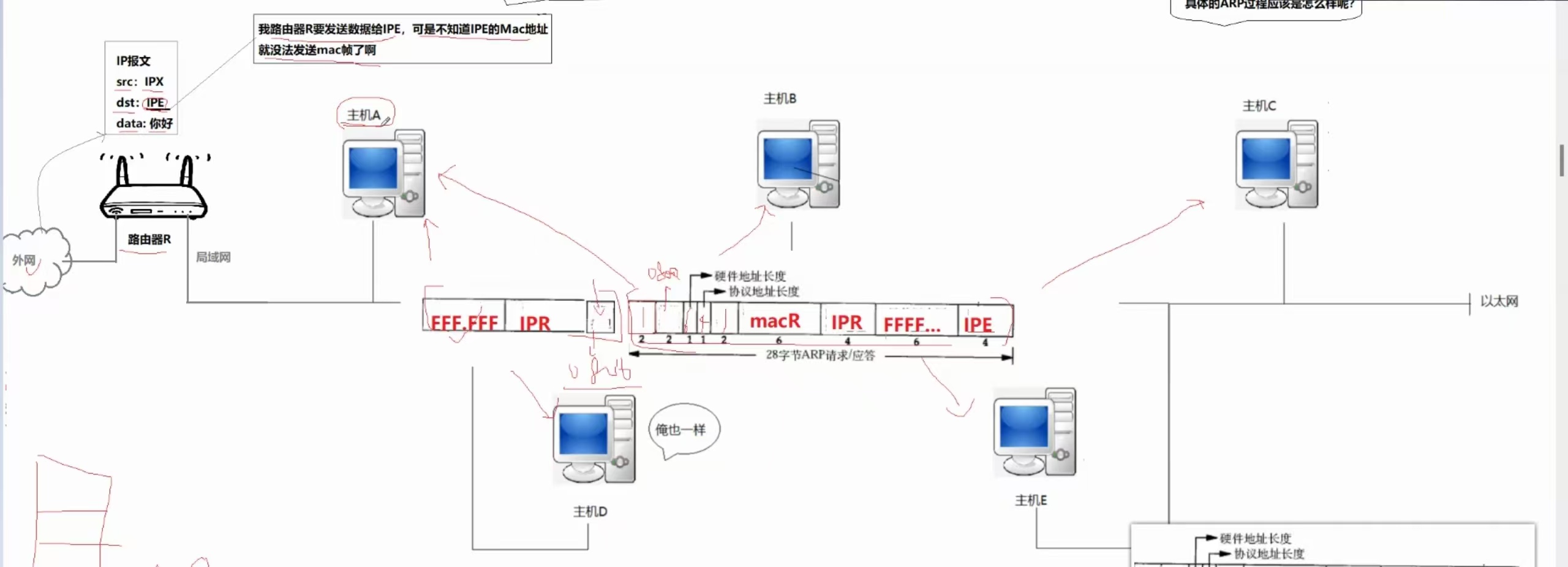
路由器首先完成对ARP请求报头的填写
由于只有MAC帧才能在数据链路层中行走,所以要把ARP报头向下交付,封装成MAC帧,然后广播
因为是广播,所以所有主机都会收到这条报文,就比如说主机A收到这条报文之后,是要进行受理的,去除MAC报头之后,把剩余部分给到自己的ARP协议处,分析内容,先看OP,是请求还是应答,然后看IP,发现IP地址不是主机A自己,就会在ARP部分对该报文进行丢弃!
细节:ARP请求是在ARP层丢弃的!
之所以在ARPC层丢弃是因为MAC报头中的目的以太网地址是全F,为广播地址,所以非想要的目的主机都可以处理这条MAC帧,然后去掉报头,向上交付,具体分析。
(②)、ARP应答
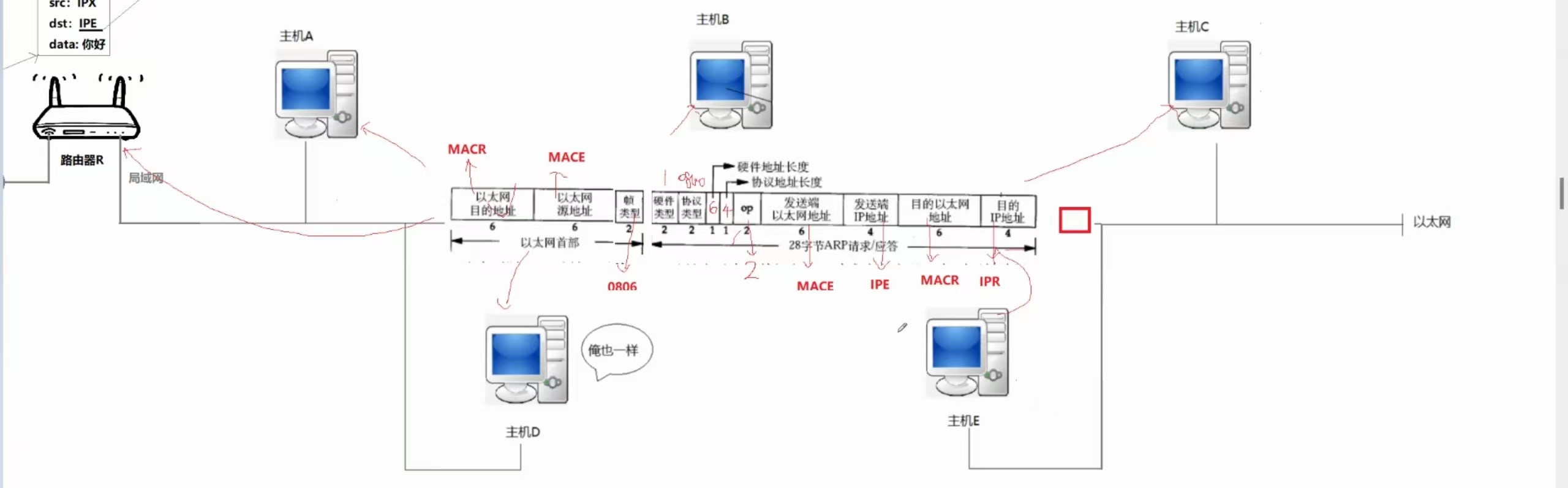
先在ARP部分完成除报头以外的数据填充,然后在MAC部分完成报头的数据填充(主机E把自己的MAC地址填入其中)。
路由器R收到应答之后,先看OP,发现是应答,路由器就会知道目标的IP地址和MAC地址,然后路由器就会把要发送的数据,发送给主机E。
细节:ARP应答是在MAC层丢弃的!
之所以在MAC层就丢弃是因为看到了MAC报头中的目的以太网地址是具体的MACR,所以不是路由器R的其他主机就在MAC层自动丢弃了。
细节一:主机会在一段时间内,记录下来局域网中,各个IP地址对应的MAC地址的映射关系!
但是不会永久记住,这样不好,也没必要,目前的IP地址是会发生动态变化的,所以,即使记录了,也不一定对!
细节二:虽然ARP协议是一个局域网协议,但是它在整个传递过程中是一直存在的!!
只要知道IP地址,就可以进行通过ARP,对MAC地址进行转换,同时路由器会不定期的进行路由算法,把IP地址通告给其他路由器!
举一个栗子
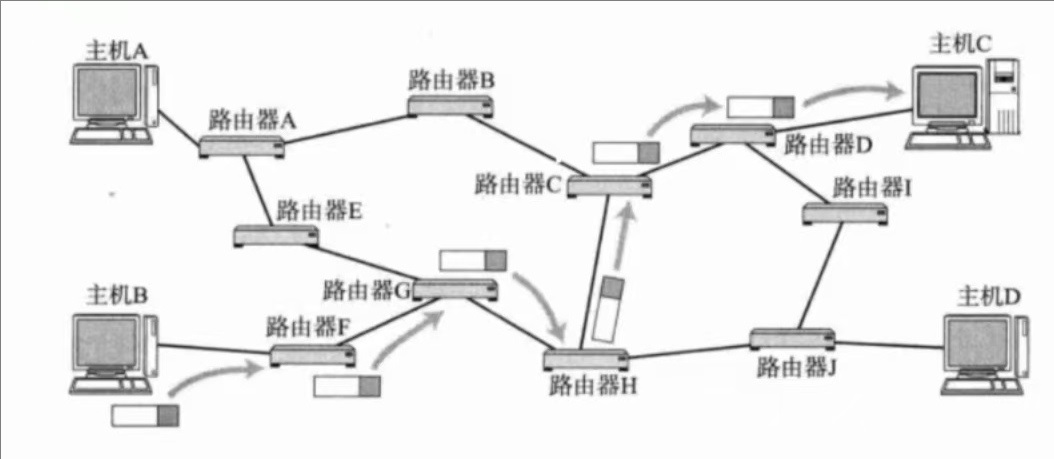
这个前面说过,主机B发信息给主机C,是会一直存在ARP的,主机B不知道路由器F的MACf,就会对路由器F进行ARP请求,路由器F进行ARP应答,以此类推,一路向下,就可以顺利到达主机C。
举两个栗子
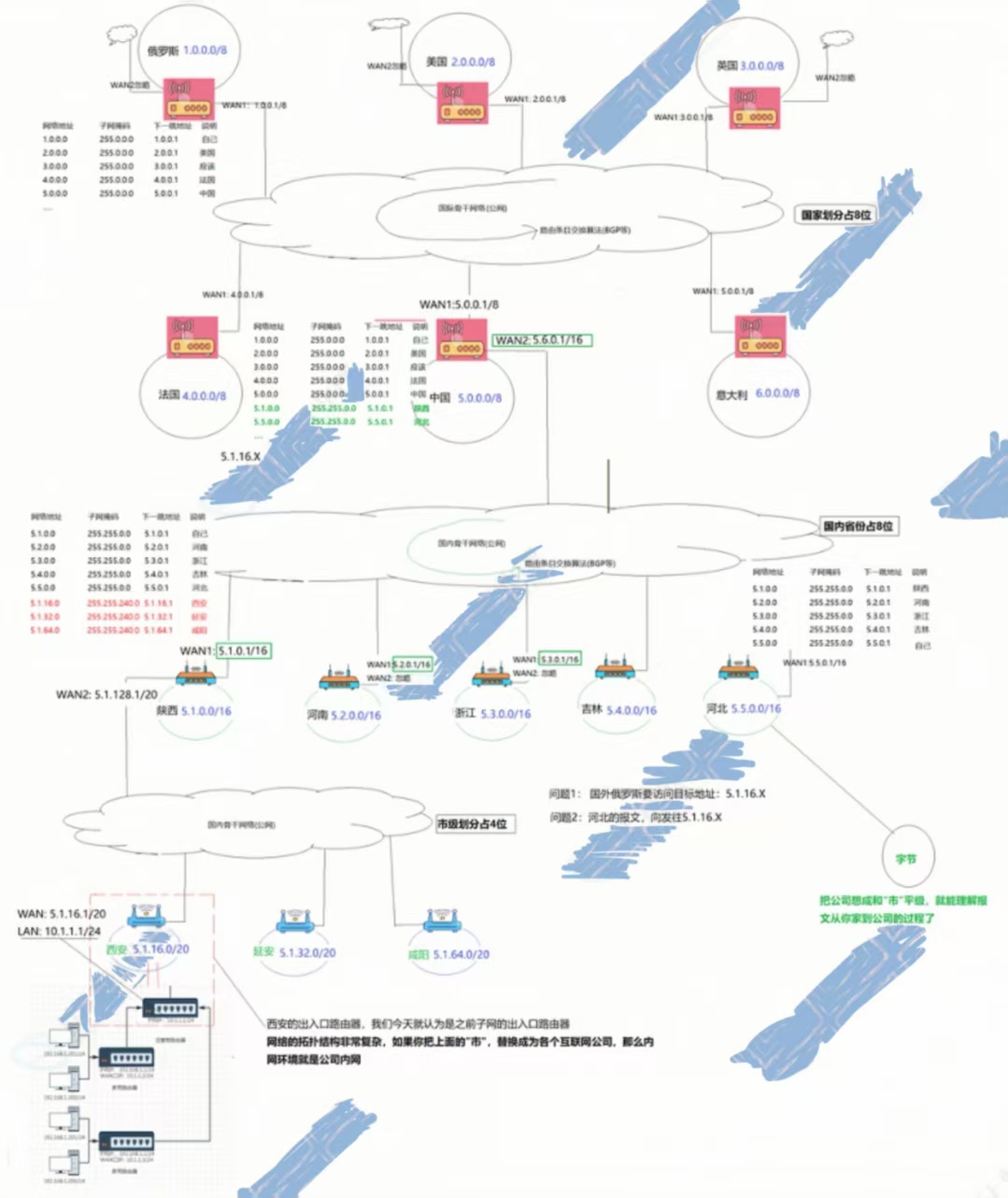
这个前面也提到过,俄罗斯的消息要发送给中国陕西省西安市,俄罗斯对外路由器知道5.0.0.1是中国的IP,但是忘记了中国的MAC地址,也会进行ARP请求,同样,中国路由器忘记了陕西省路由器的MAC地址,也会进行ARP请求,所以说,ARP虽然是局域网协议,但是只要有IP的地方,就会有ARP的身影,当然,前提是,需要MAC地址的。
(6)、NAT
①、NAT技术背景

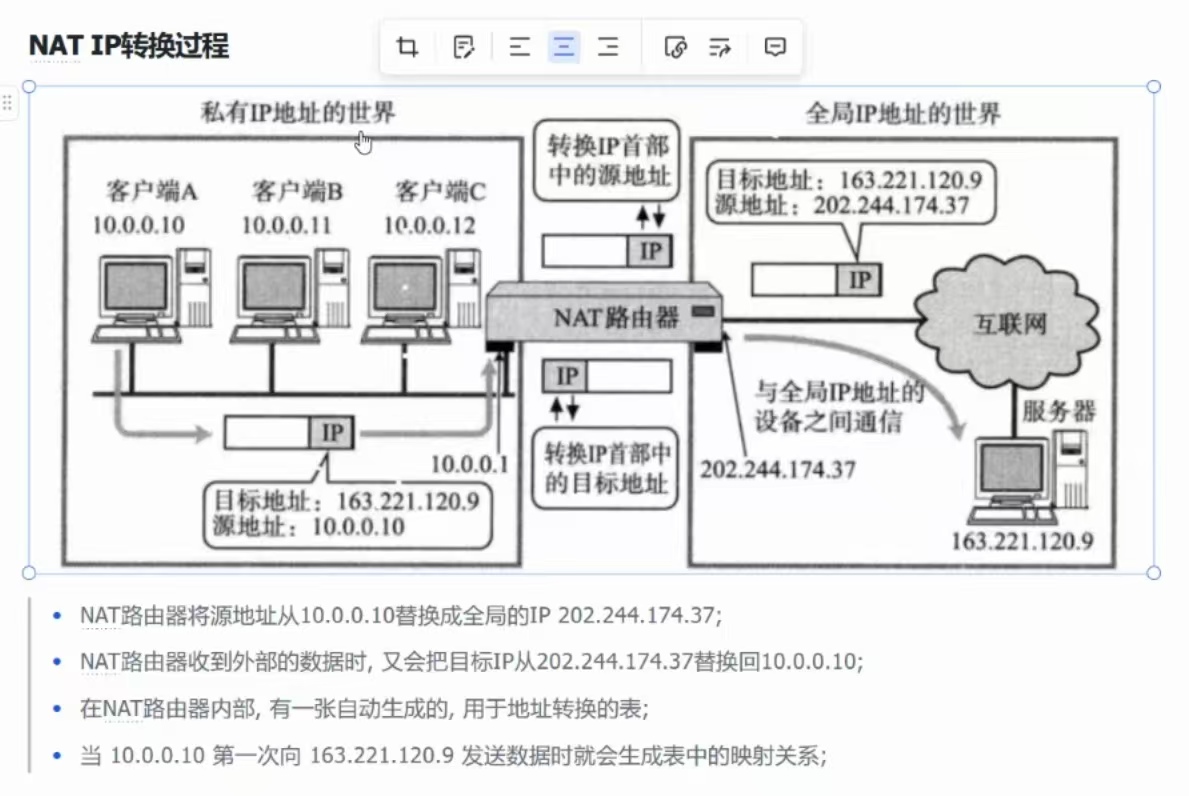
学到这里,对之前说过的结论进行升华,目的IP地址始终是不变的,但是源IP地址可能会变,就是因为有NAT技术的存在,它可以解决IP地址不足的问题!
②、NAT IP转换过程
③、NAT技术的缺陷

从外向内无法传送数据,只能是从内向外,建立完之后,外界才能给内部发送消息
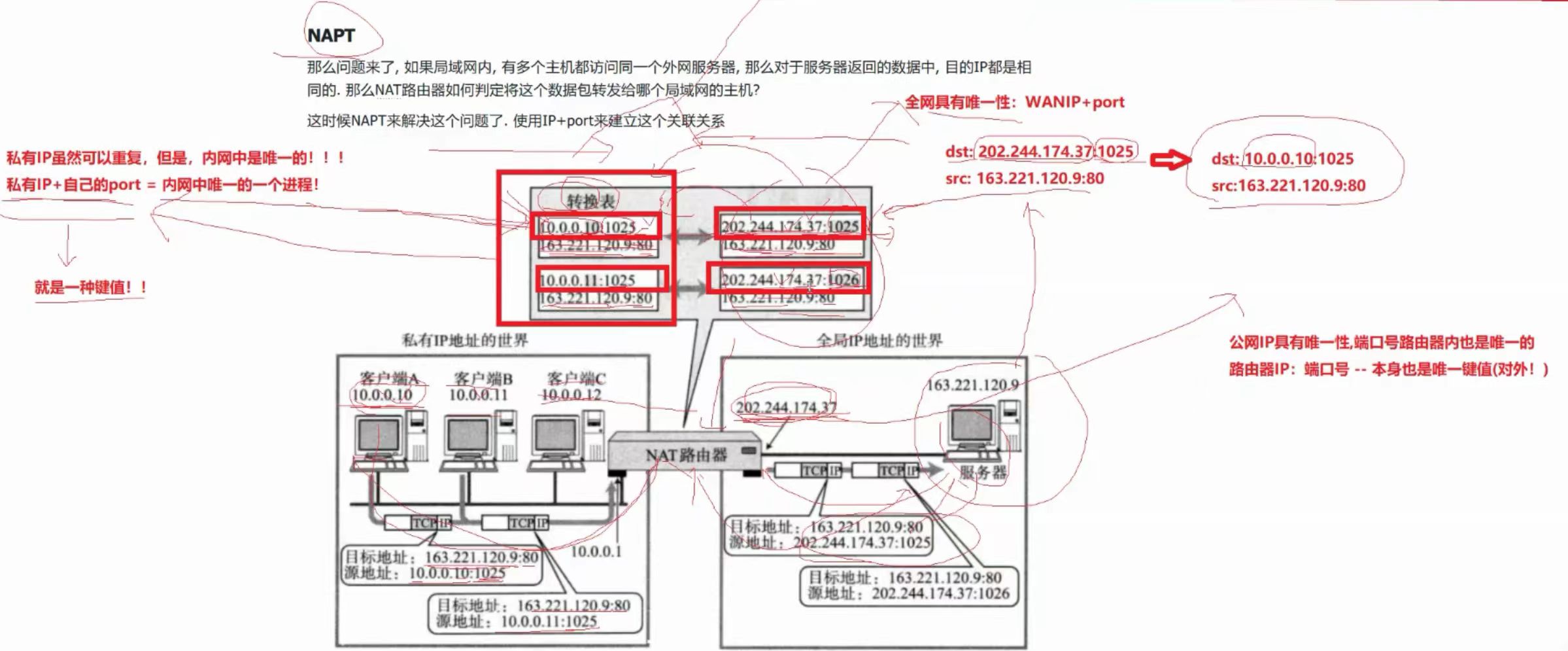
(7)、NAPT
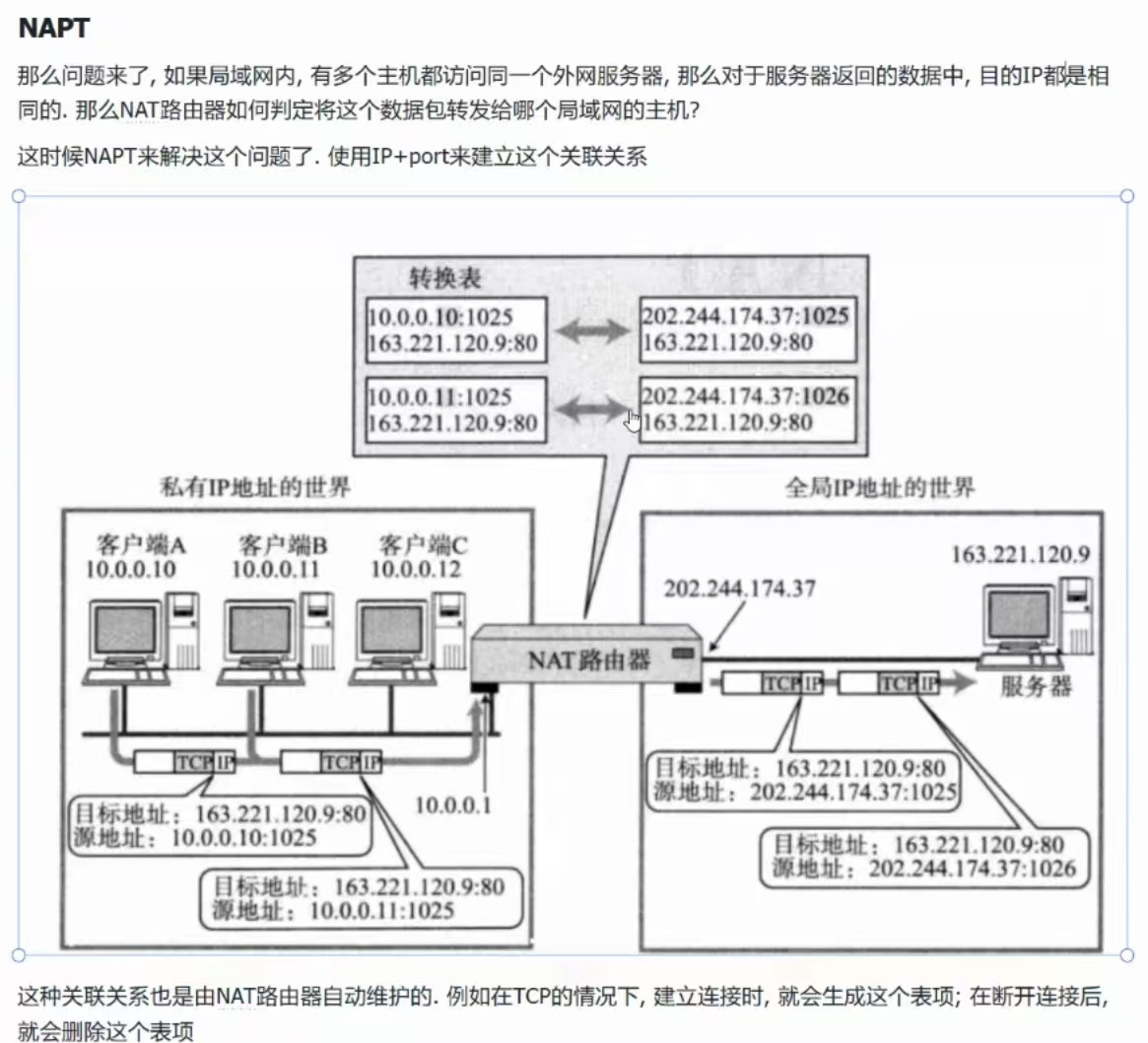
有了这张表之后,从外到内,以及从内到外都可以实现了!
这张表是路由器自己维护的!
①、NAT的过程,不仅仅是源IP(内网IP)的替换,端口号也可以进行替换!
源IP的替换只发生在局域网的部分,等到了省间、国际间,就不会发生了。
②、私有IP虽然可以重复,但是,私有IP在自己的内网中是唯一的
私有IP + 自己的port(就是一种键值) = 内网中唯一的一个进程
③、路由器的公网IP具有唯一性,端口号在路由器上也是唯一的
路由器IP : 端口号 – 本身也是唯一键值(对外),在全网中也是唯一的!
④、所以从左向右就是一个唯一值映射到另一个唯一值,从右向左也是一个唯一值映射到另一个唯一值!
互为键值!!
这时候就不用再担心IP地址不够用的情况了!
(8)、代理服务器(应用层概念)
正向代理
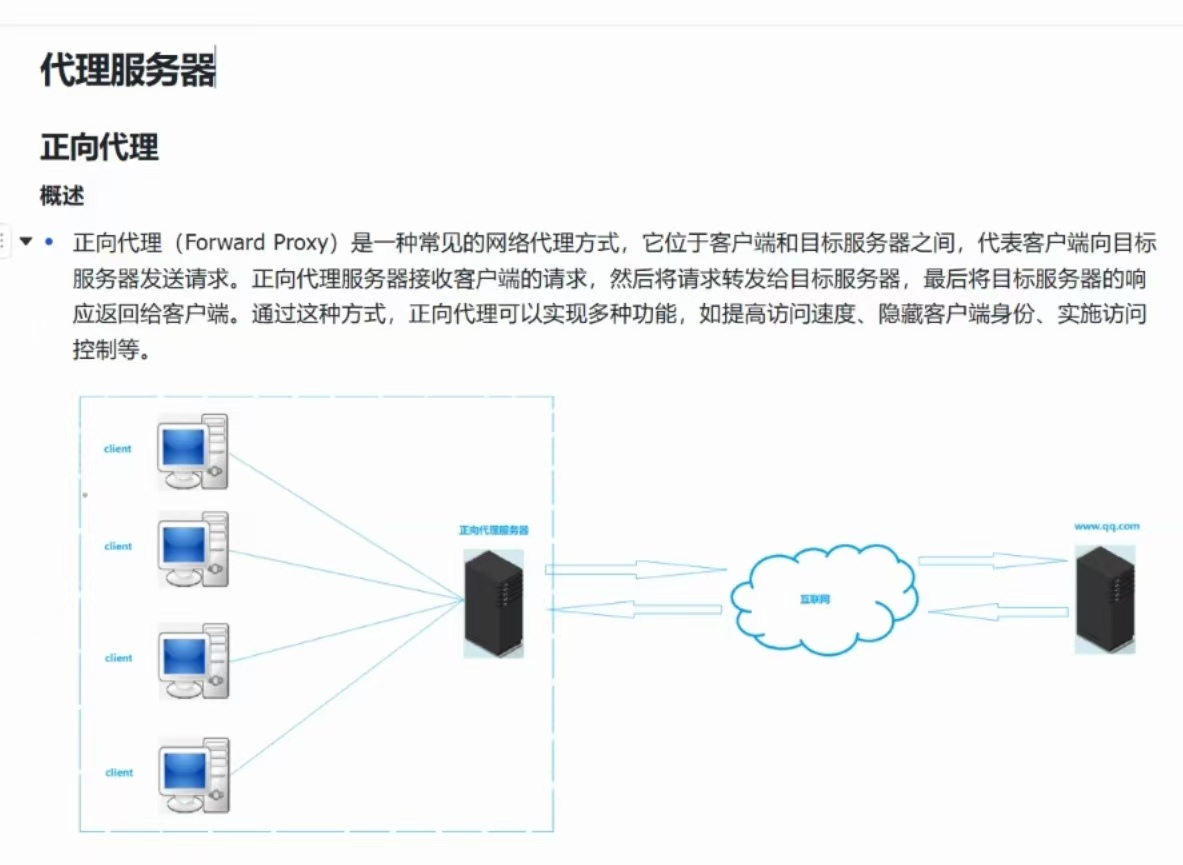
工作原理

功能特点 && 应用场景

反向代理
负载均衡
域名解析之后的IP,就是反向代理服务器的IP!
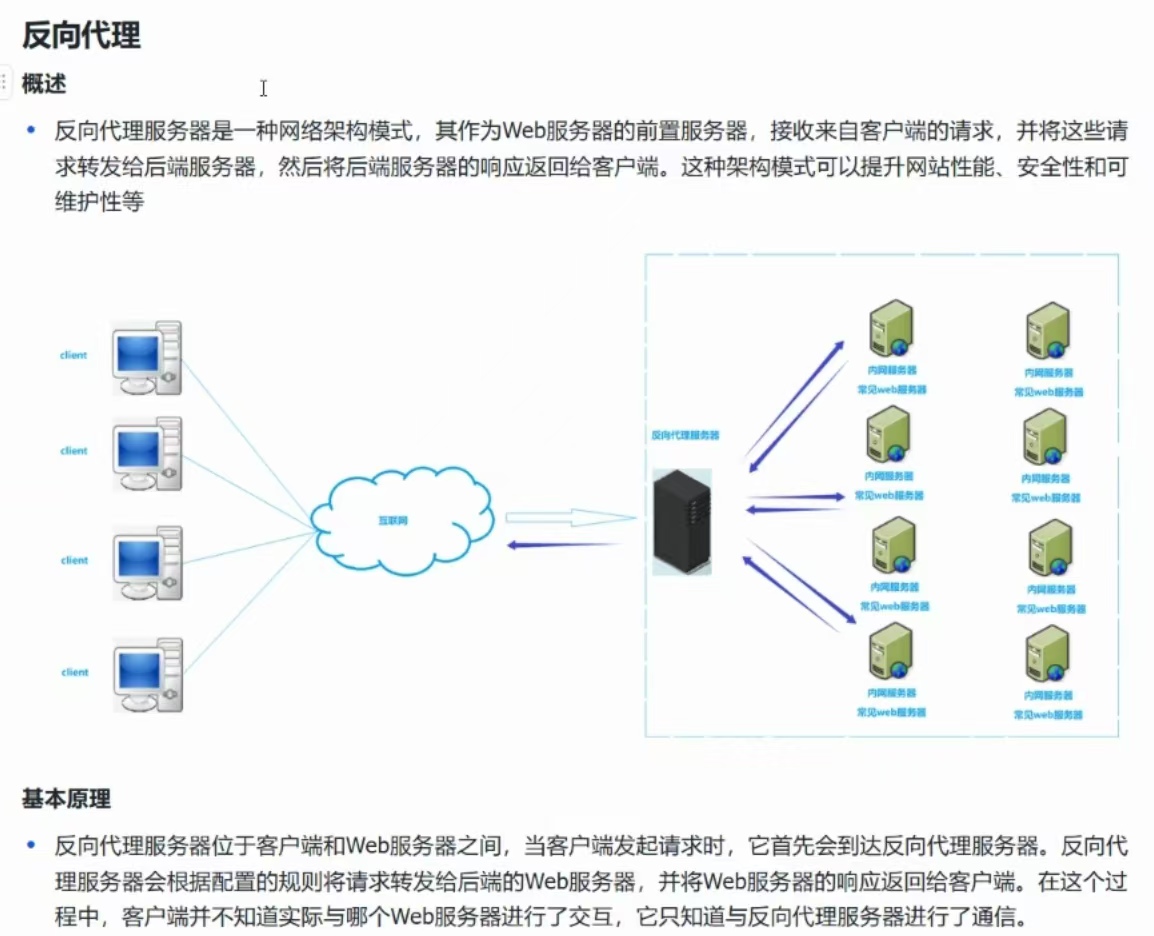
同时,域名解析之后的IP地址会有很多,会对应不同地区的反向代理服务器,确保负载均衡!
应用场景

CDN
做CDN的运营商开创了很多的云资源,许多公司会把一些静态资源,如图片等,就会放到这些云资源中,客户想访问的时候,就直接从云资源里拿,大大减少了公司反向代理服务器的压力,同时也加快了用户的访问速度!
(9)、NAT和代理服务器

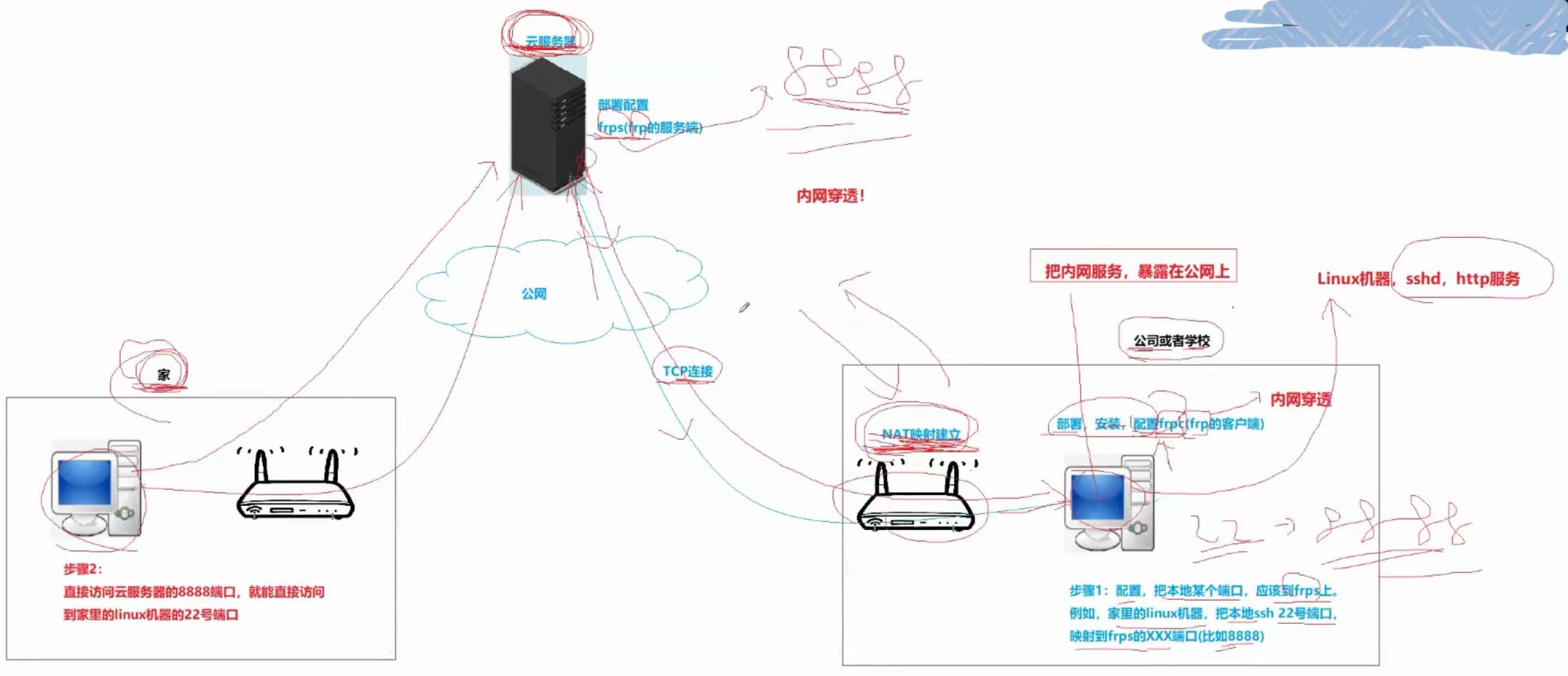
(10)、内网穿透
本质:建立从内向外的NAT映射
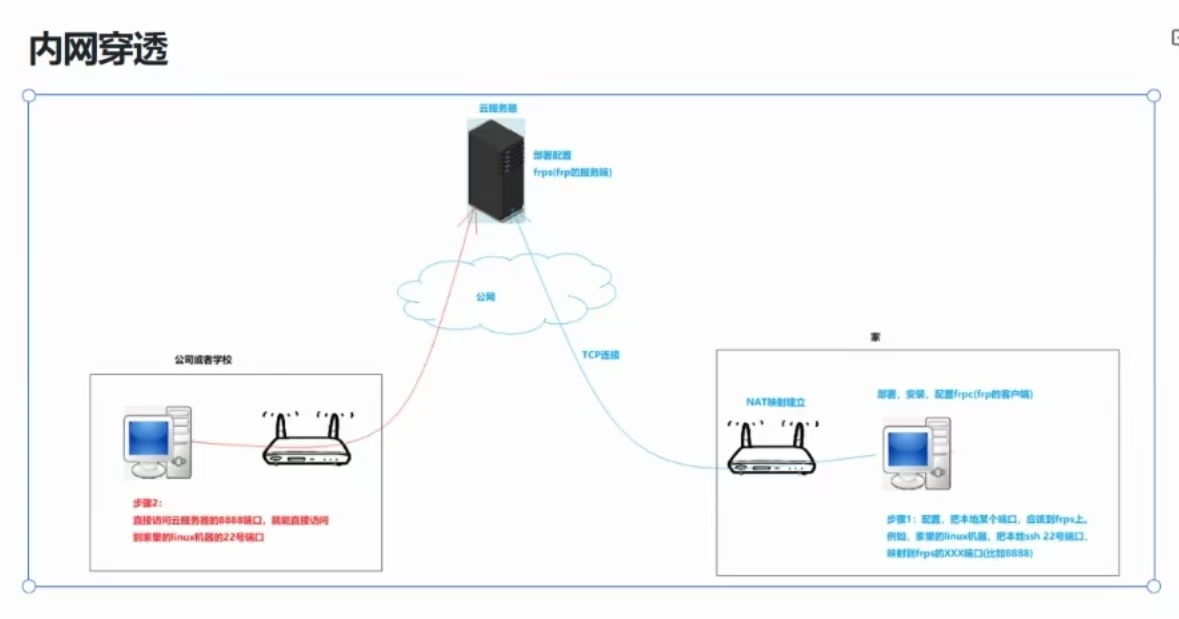
frp是专门做内网穿透的软件
(11)、内网打洞
p2p技术
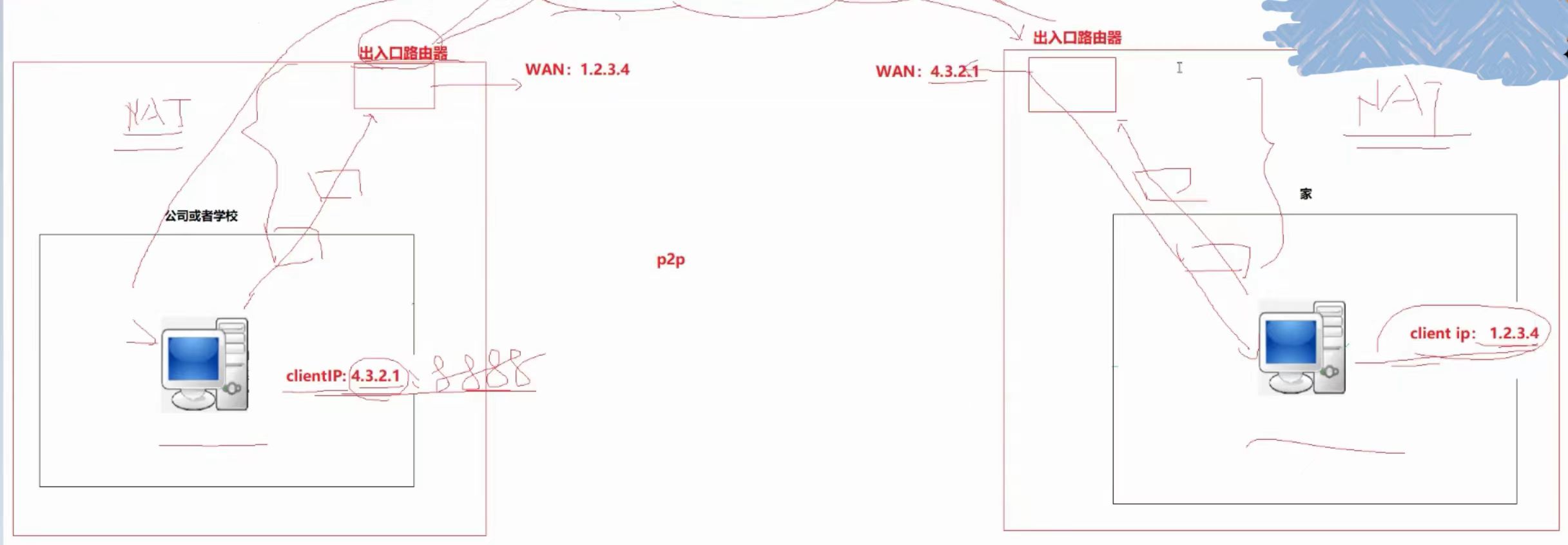
大致流程
当两台主机同时访问外网的时候,且都访问一个云服务器时,这时候两台路由器就会建立对彼此的NAT映射关系,通过云服务器把对方的输入口路由器的WAN口发给对方,然后路由器再把对方的信息发送给用户自己,这时候用户就可以对方用户的WAN口信息了,之后就可以只用一点点公网,不需要使用云服务器,就可以实现采用内网转发来进行双方的通信了!
应用场景
基于内网穿透的直播方案
就比如说某音平台的大主播,一场直播在线人数就有10几万,这时候如果这些用户都登陆某音的服务器观看直播,那么服务器的压力就太大了,为了缓解服务器的压力,就会采用内网打洞的方式
主播A所在的地方WAN口路由器为1.2.3.4,用户A所在地区的WAN口路由器是4.3.2.1,这时候,和上面说的一样,就不会经过服务器,主播和用户A的本地网络直接连接,同样,其他用户也是如此。
PS:由于此种方案相当于在薅运营商的羊毛,所以运营商可能会对此方案进行拦截!(内网穿透与内网打洞可能会被拦截)
(12)、交换机:工作在数据链路层的设备
把一个大的碰撞域划分成小的碰撞域,极大的解决了数据帧冲突的概率
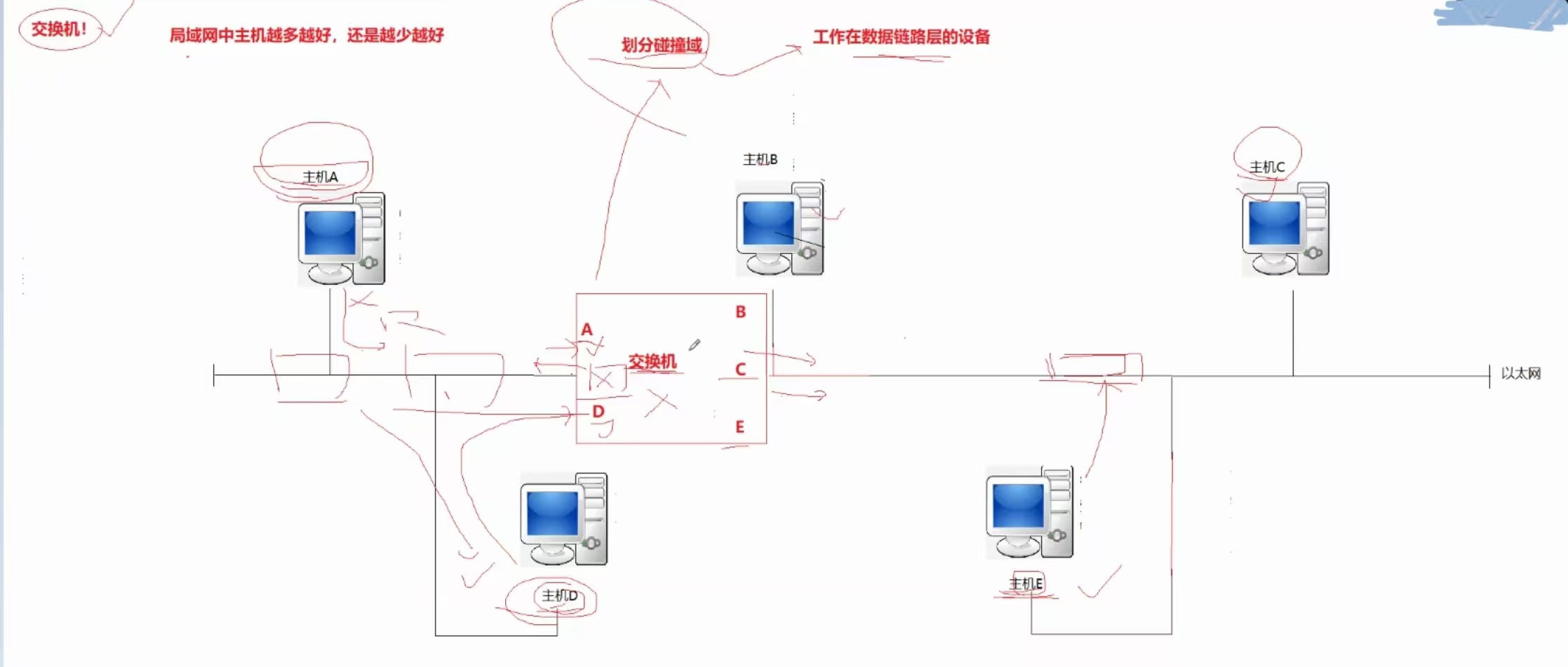
举一个栗子
主机A给主机D发送信息,经过交换机,不出预料,会广播给局域网内所有主机,但是交换机会默默记录有一台主机,它在交换机的左边,就这样,所有主机发送完消息之后,交换机对他们的位置就有了了解,就知道主机A和主机D属于一个碰撞域,而主机B、主机C、主机E又属于另一个碰撞域。
这时候主机A给主机D发信息,交换机就不会给右侧广播该消息了。
三、总结
数据链路层

网络层

传输层

应用层
