应用层:HTTP/HTTPS协议
一.HTTP协议
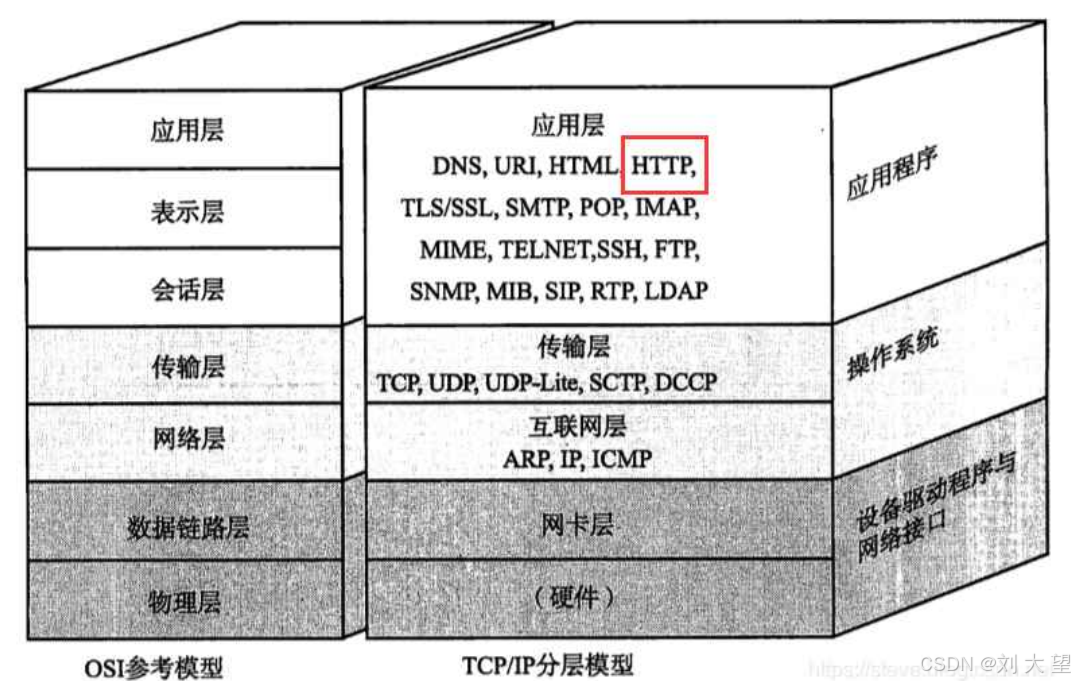
HTTP(全称为"超⽂本传输协议")是一个应用层使用非常广泛的协议HTTP是一个非常广泛的应用层协议
应用层协议,经常是需要进行“自定义协议”的,但是,很多时候也不一定非得从零设定开始,也可以基于一些大佬们设计好的协议,在这个基础上进行定制,HTTP之所以应用非常广,主要是因为HTTP可定制性非常强,以HTTP为蓝本,在这个基础之上捎带着你想要传输的数据,这个时候就很容易完成一个自定义协议了
什么时候会用到http协议呢?
就比如你浏览网页或着微信小程序, 游戏的加载界面等等情况都会用到
HTTP应用的范围非常广,因此说HTTP是应用层最广泛的协议,不管你是前端还是后端,HTTP是一个程序员必须要掌握的协议
HTTP协议的工作过程
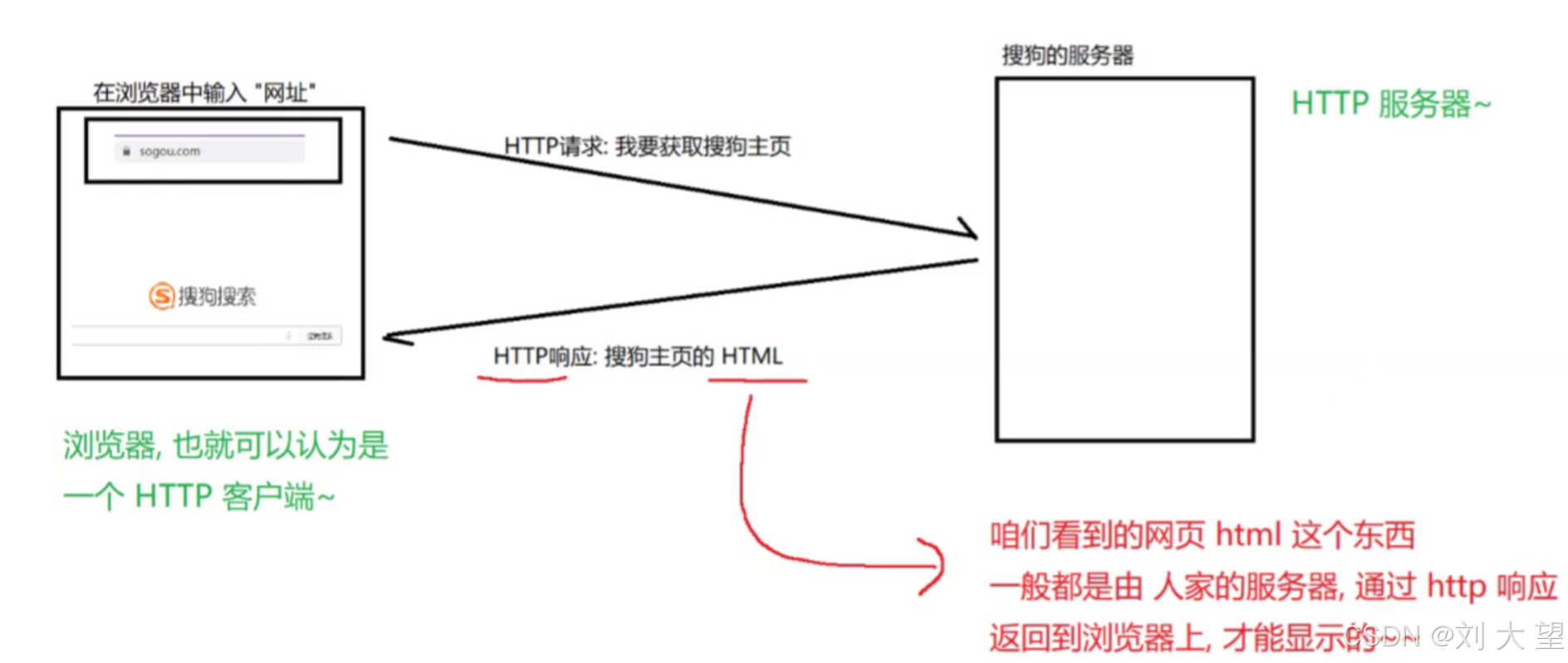
HTTP是一问一答形式的,也就是一个请求对应一个响应
HTTP是一个应用层协议,HTTP请求发送出去之后,就需要从应用层到 传输层再到 网络层再到 数据链路层再到 物理层,层层封装,接收方接收到数据之后,再从物理层到应用层,层层分用,最后才能够完成传输
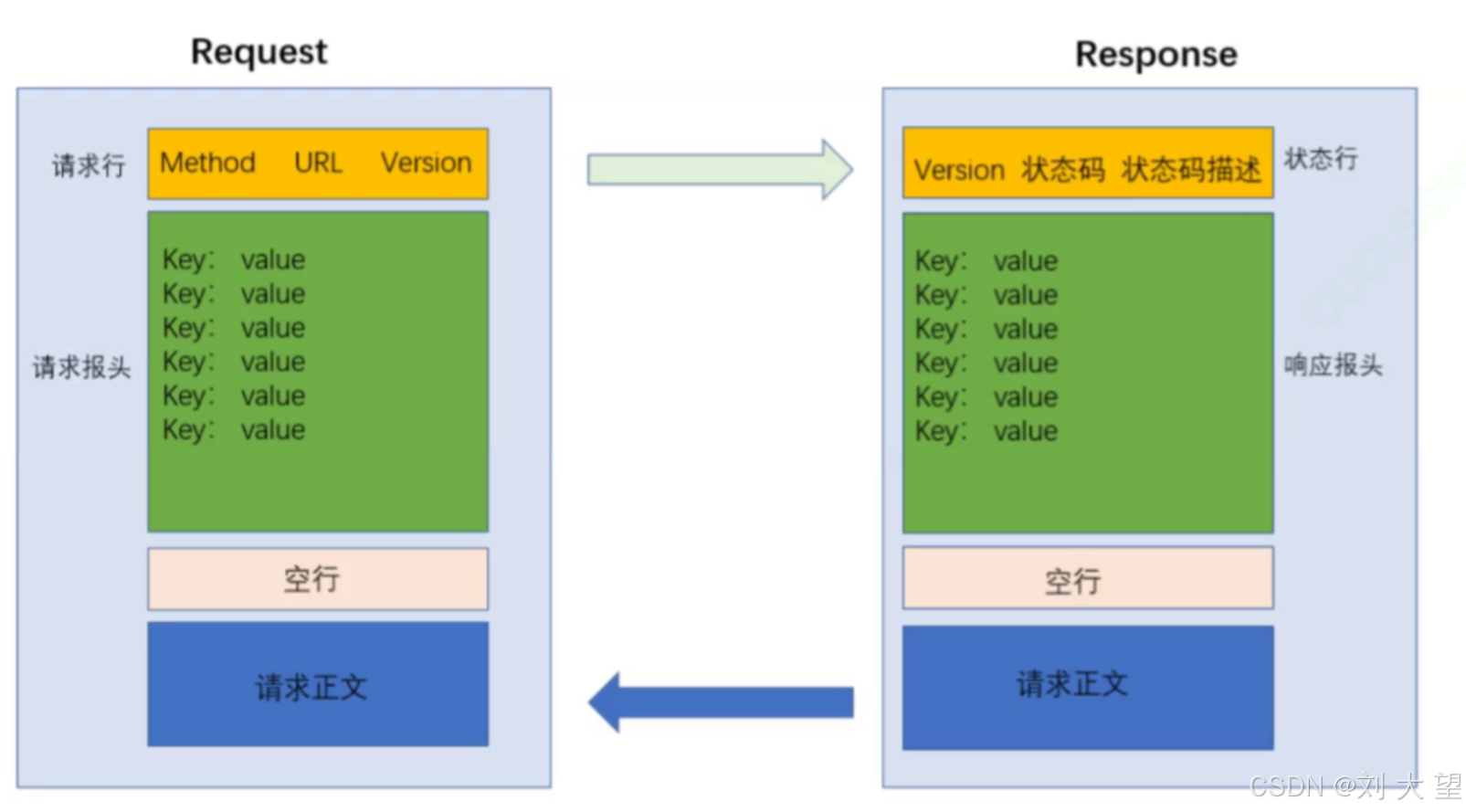
HTTP的报文协议格式
要想知道http的报文格式就要用到抓包工具,这个工具就是抓包工具,就是把数据包给他抓出来,然后显示这个包的报文格式,抓包工具相当于一个代理,借助这样的代理,就可以看到网络上传输的具体数据
推荐的抓包工具Fiddler和wireshark, 小白建议使用使用fiddler, fiddler专注于抓取http请求
fiddler下载之后一定要勾选https, 否则无法解析https请求
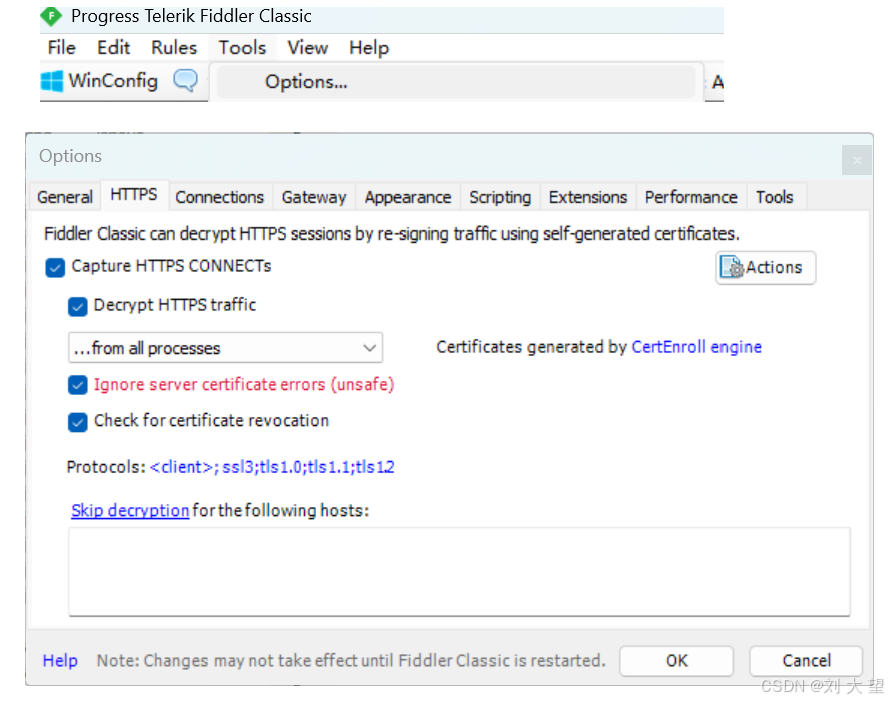
开启抓包工具后, 请求响应的流程就编程以下这个样不再是直接发给服务器了
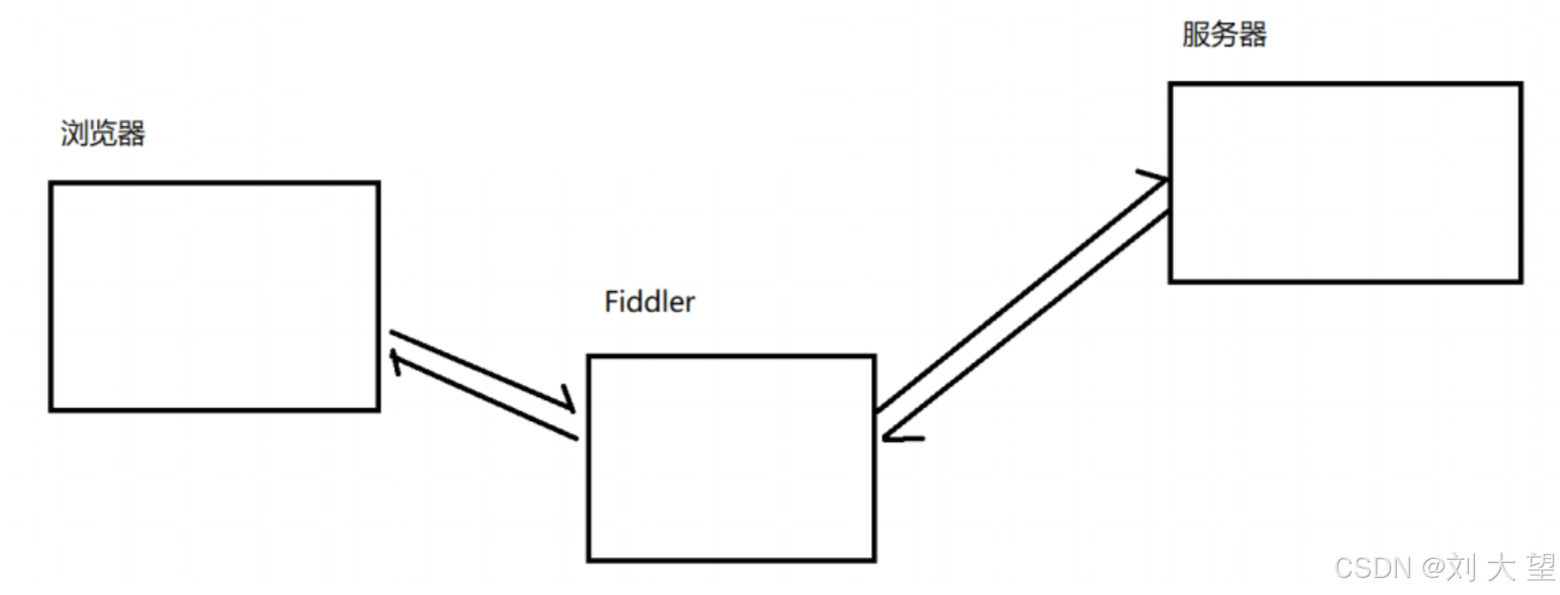
浏览器访问 sogou.com 时, 就会把 HTTP 请求先发给Fiddler,Fiddler 再把请求转发给 sogou 的服务器. 当 sogou 服务器返回数据时,Fiddler 拿到返回数据, 再把数据交给浏览器. 因此 Fiddler 对于浏览器和 sogou 服务器之间交互的数据细节, 都是非常清楚的.
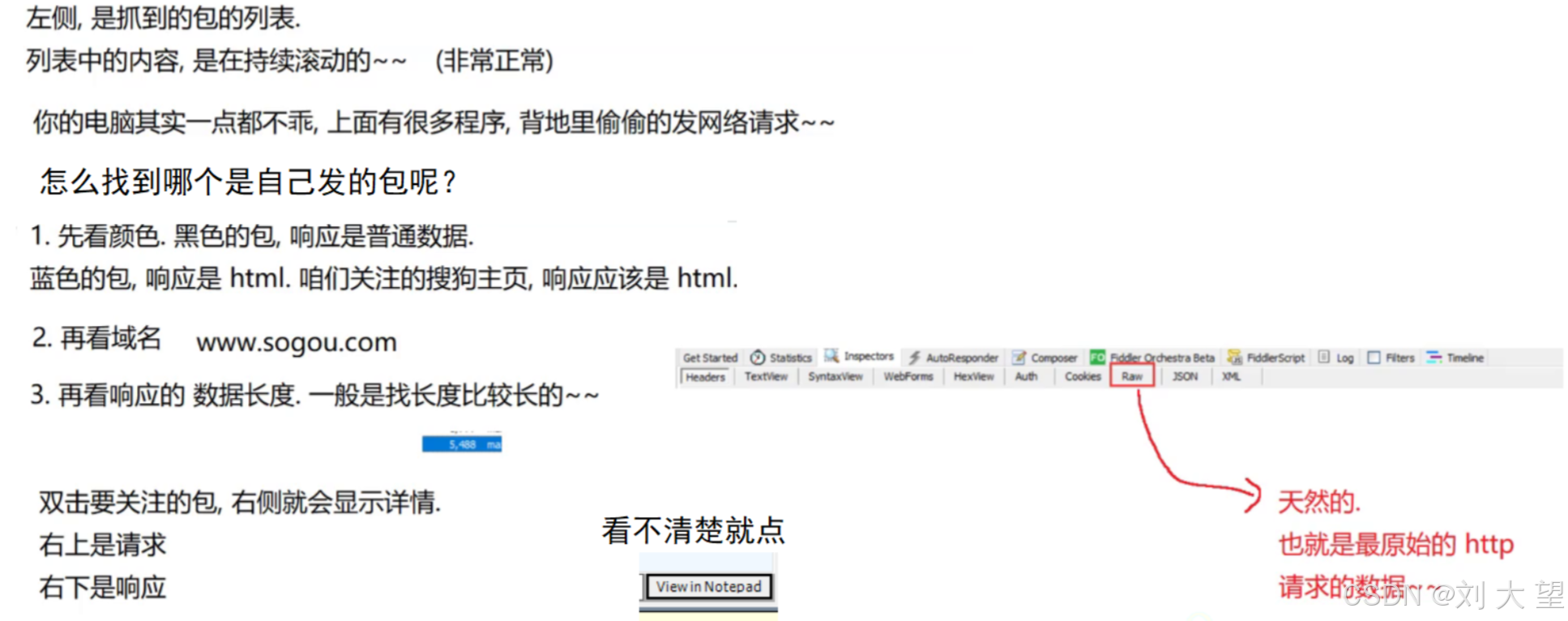
请求
get请求一般没有请求正文, 正文中的数据一般是放到url中的查询字符串中后面会介绍到
响应
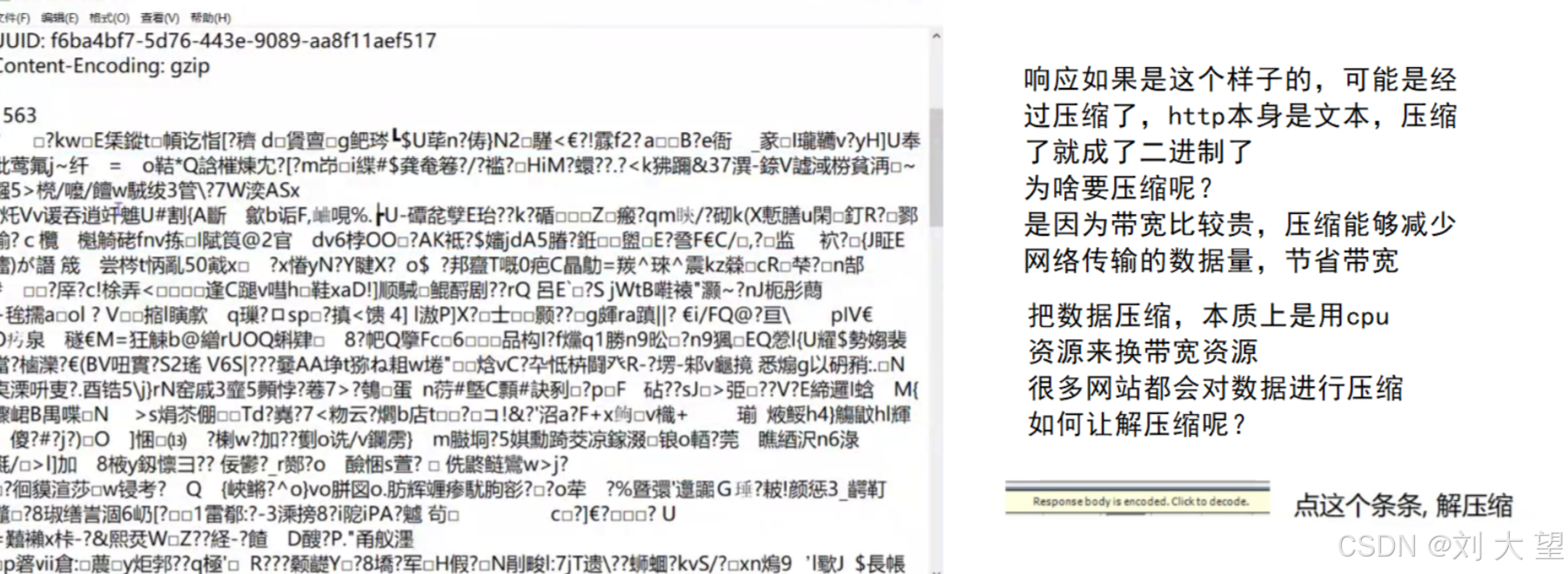
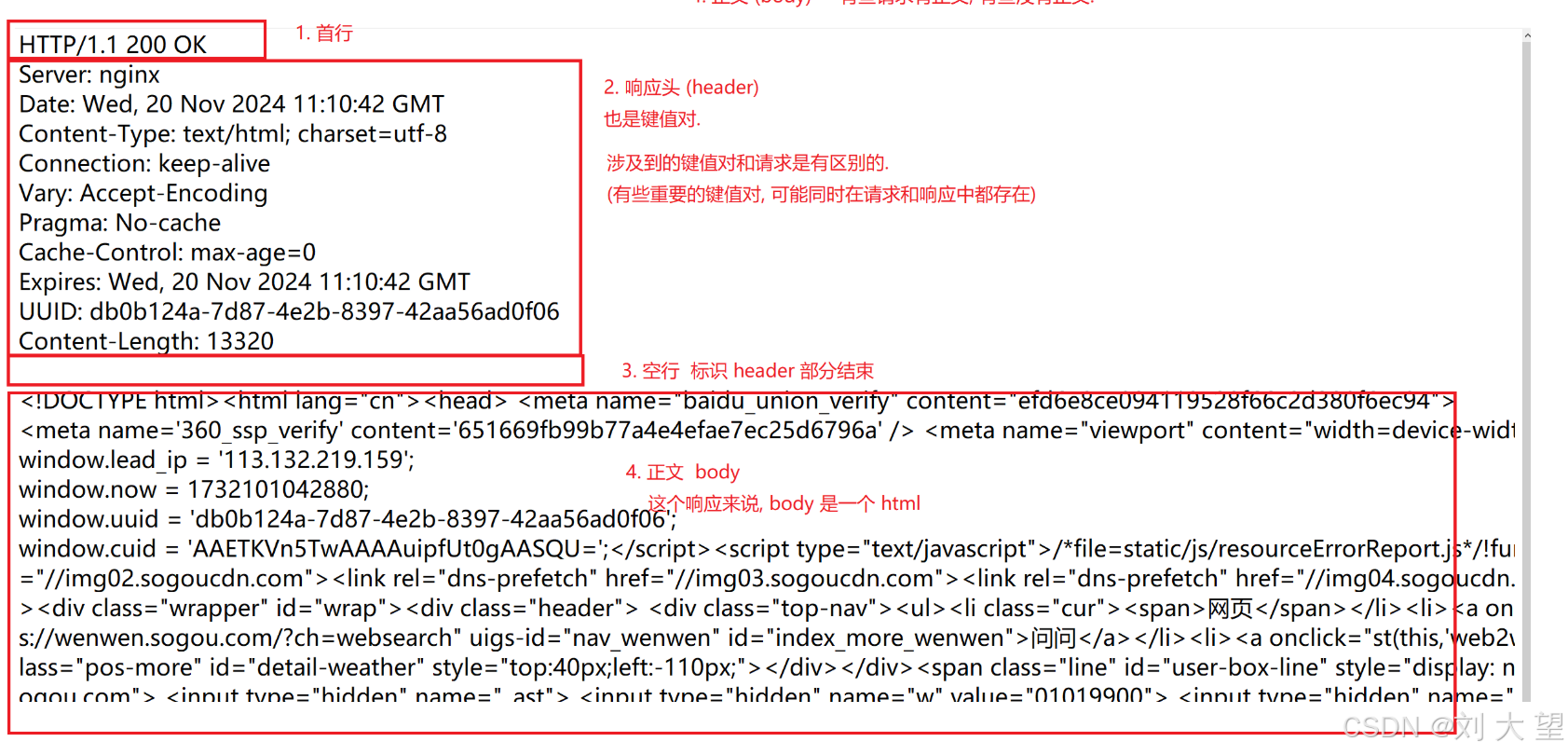
响应的首行包含版本号 状态码 状态码的解释
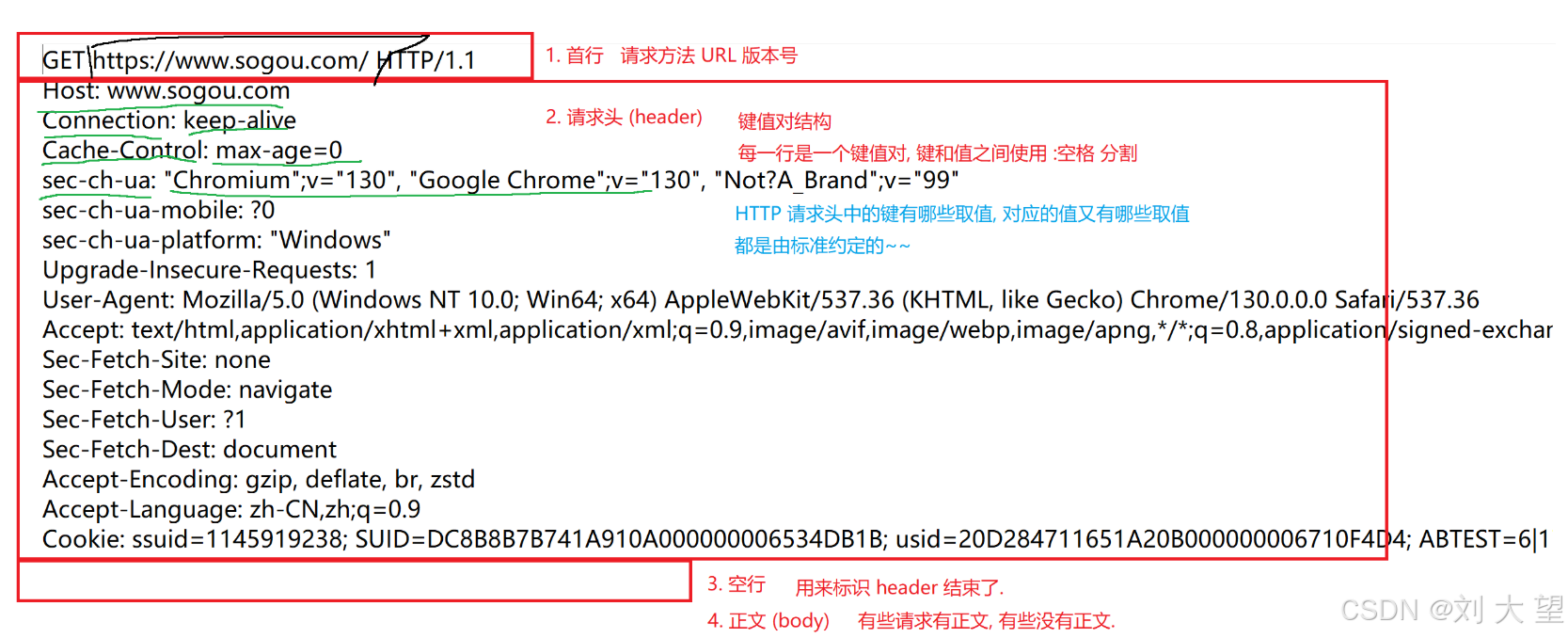
请求首行
方法
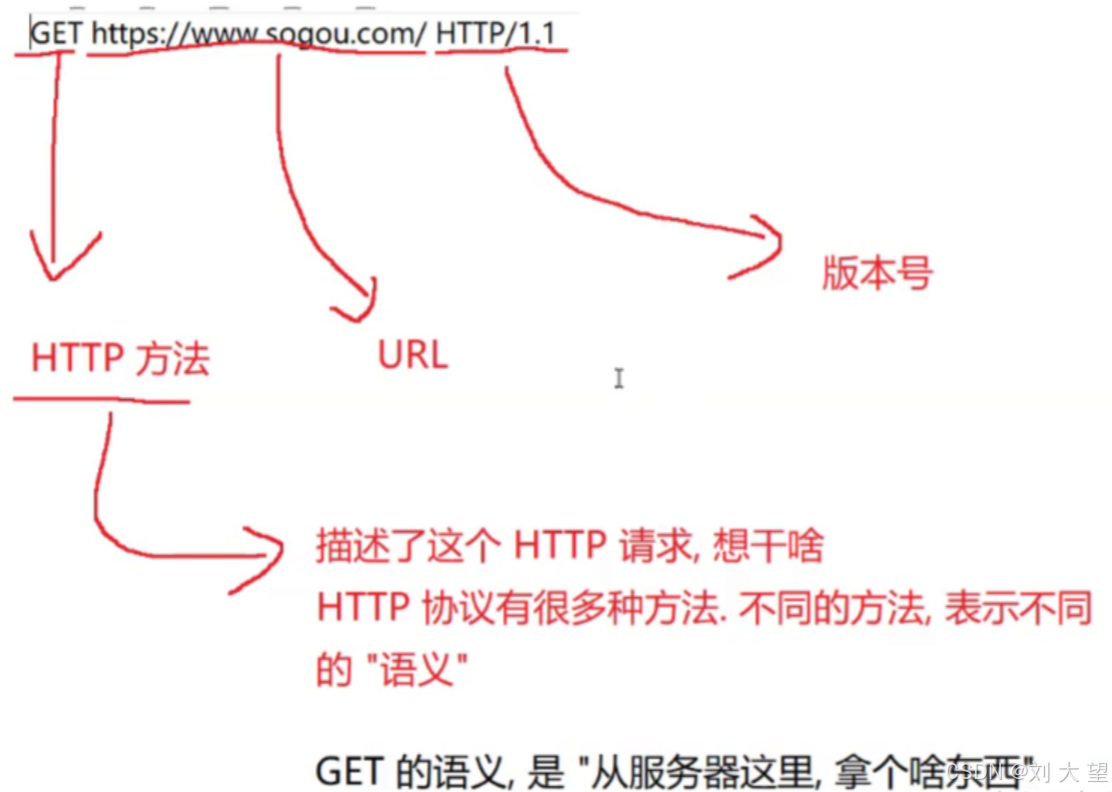
HTTP有很多方法
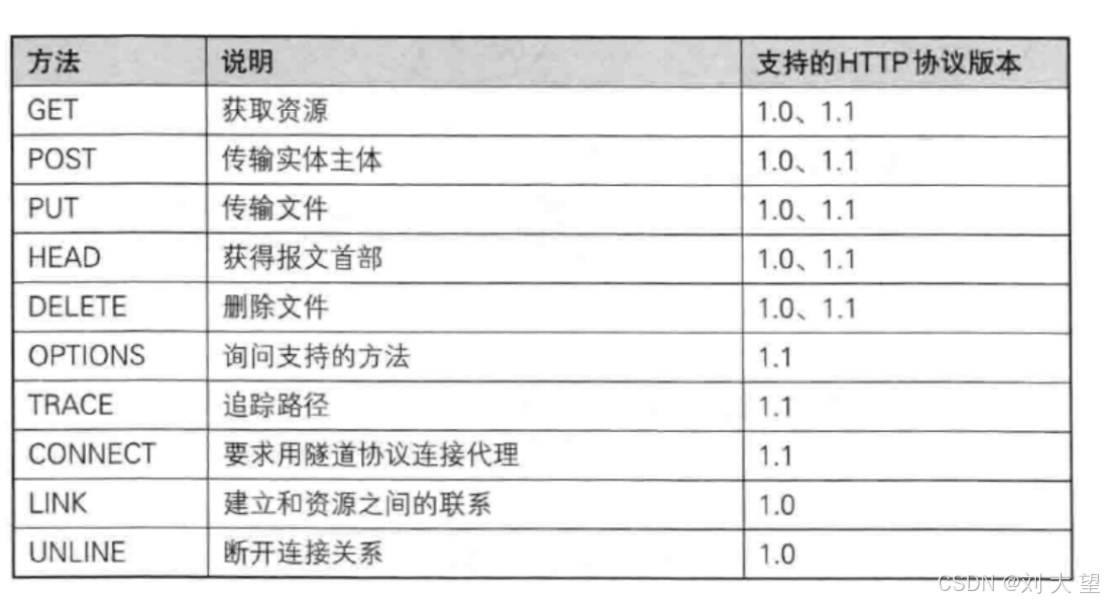
但是最常用的是GET和POST
POST:往服务器提交个啥东西
日常开发中绝大部分用的都是GET
而且在日常开发中get和post都是混着用的
那么啥时候能看到POST呢?
1.登陆的时候
2.上传文件的时候
POST请求的正文(body)一般不为空
GET请求的正文(body)一般为空
下面看一个登录的http请求
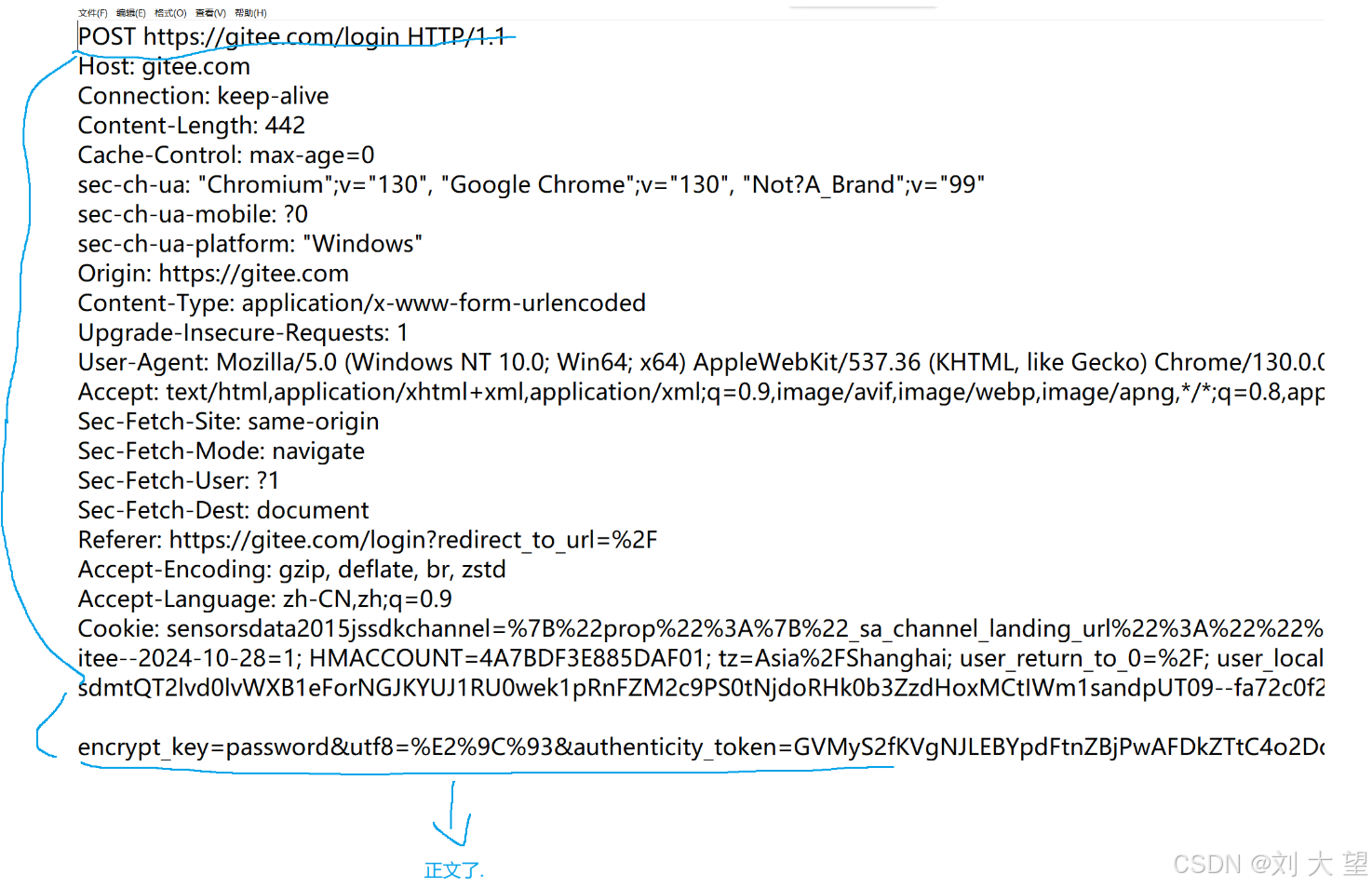
现在密码一般都不会是明文传输了经过加密后会变成一串无规律的字符串
GET和POST虽然表示的是不同语义,但是实际上,也并非需要严格遵守,http方法的语义只是一种建议,程序员实际使用的时候,也不一定必须要遵守,毕竟你自己写的代码你自己负责来定义
对于body有没有的情况,也不是绝对的,GET可能也有body,只不过很少见,POST也可以没有body,也比较少见
如果谈到GET和POST有什么区别?(面试题)
没有本质区别!使用GET的场景,替换成POST一般也可以,反过来也行
但是,没有本质区别,不代表没区别!
两者在使用习惯上有区别:
1.GET习惯上用来表示“获取一个数据”,POST则用来表示“提交一个数据”
2.GET一般没有body,需要携带数据就放到URL中,POST一般有body
3.GET请求通常会设计成幂等的,POST则无要求
4.GET是可缓存的(前提是幂等),而POST则不能
5.GET请求可以被浏览器收藏,而POST不能


什么是幂等性?
核心就是重复执行同一操作,返回的结果保持一致
比如牛吃进去的是草,挤出来的是奶
如果每次吃进去的都是草,并且每次挤出来的都是奶,就可以说是幂等
如果每次吃进去的是草,挤出来的不都是奶,就不是幂等
幂等性,在开发中也是很关键的,设计成幂等之后,请求就可以缓存了
怎么理解缓存呢?
比如1×10 我可以一秒就说出来是等于10,不是因为我脑子快,而是我记住了,因为只计算了一次,我就记住了,后续我再被问1×10,我可以张口就来
缓存可以提高响应速度,节省运算资源
缓存无处不在,既可以在客户端,也可以在服务器
浏览器可以通过ctrl+f5强制刷新来刷新掉缓存
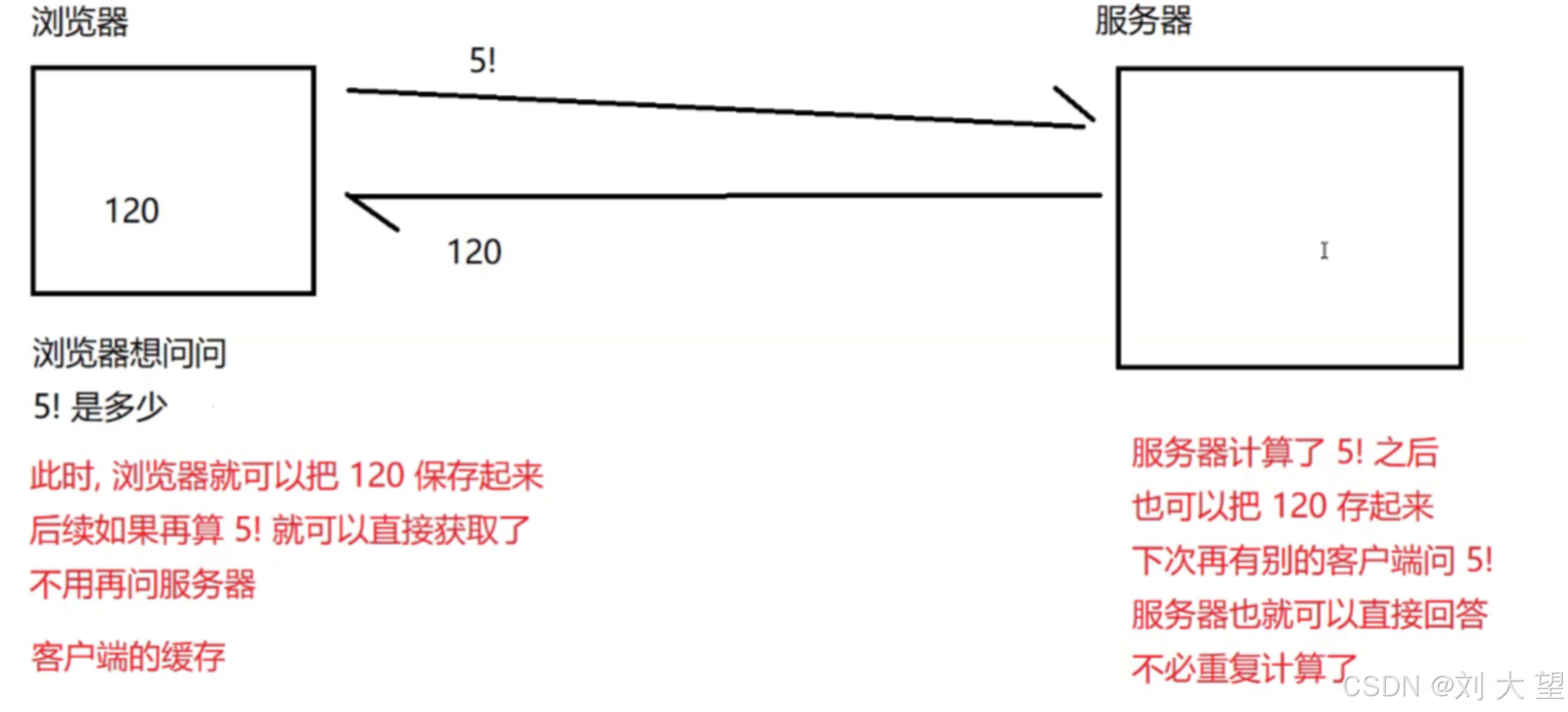
浏览器本质上也是一个程序,在cpu上运行的一系列指令,很有可能cpu也把120给记录下来,后续如果再需要计算5的阶乘,都不许要访问其他设备,自己就知道了,这也是一种缓存

put 和delete方法(一般不用)

URL
平时我们俗称的"⽹址"其实就是说的URL(UniformResourceLocator统⼀资源定位符).
URL–唯一资源定位符,描述了网络上的唯一的一个资源
这个概念严格的说,并非是HTTP里的概念,很多协议都会用到URL
URL的结构如下图


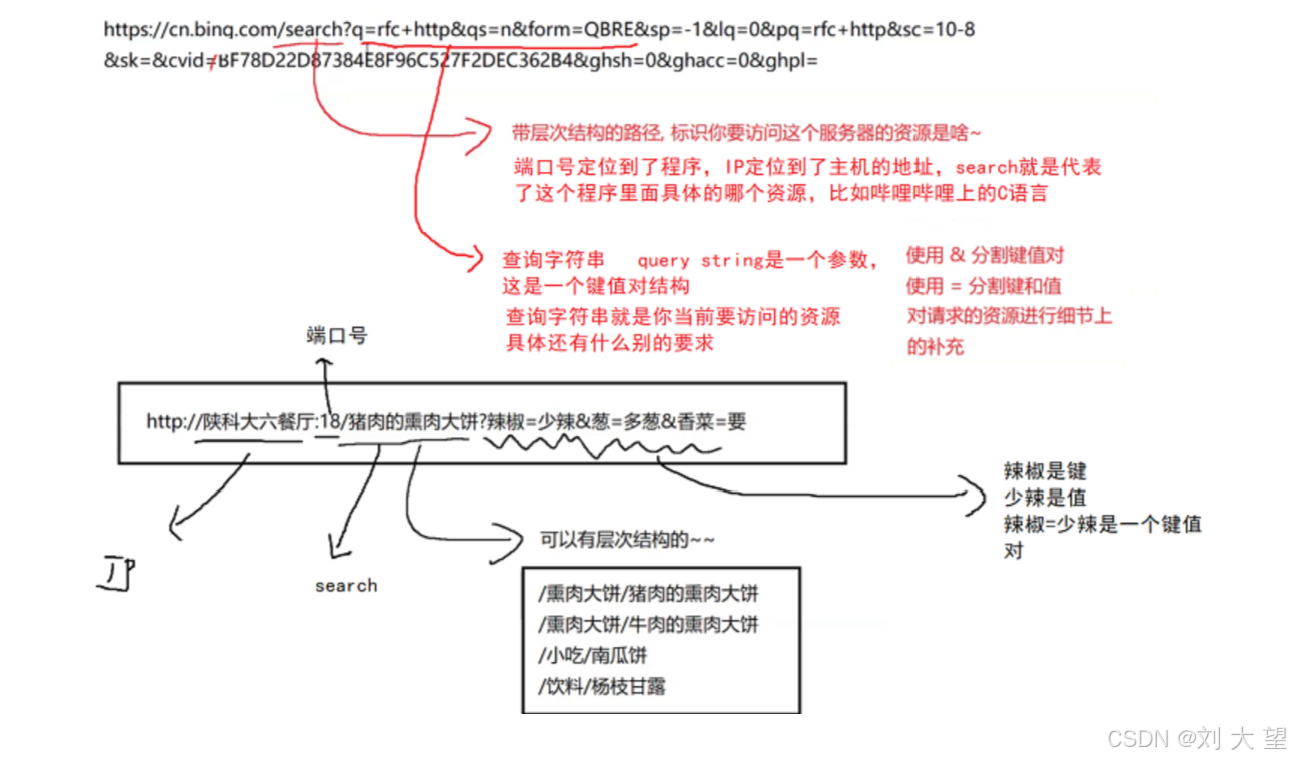
?号后面就是查询字符串的内容, 一般get请求方法给服务器发送数据就是通过这个传过去的
urlencode

为什么要encode?
1.字符集限制
URL最初仅支持ASCII字符集中的部分字符(如字母、数字、部分符号 -._~ 等)。如果包含非ASCII字符(如中文、日文、特殊符号 @#$% 等),直接传输会导致解析错误,因为不同系统对这些字符的处理方式可能不一致。
2.避免歧义(主要)
一些字符在URL中有特殊含义(如 ?分隔路径和参数, & 分隔多个参数, = 表示键值对)。如果这些字符作为普通内容出现在URL中(比如参数值里包含 &),会被误认为是分隔符,导致解析混乱。编码后可将其转换为特殊格式(如 & 编码为 %26),避免歧义。
3.保证传输兼容性
早期网络协议对传输的字符有严格要求,非
标准字符可能在传输中被截断或修改。编码后所有字符都转换为ASCII范围内的百分号加十六进制形式(如中文"中"编码
为 %E4%B8%AD),确保在各种网络环境中稳定传输
版本号
最常见的是HTTP/1.1,这也是最主流的版本,绝大部分的互联网上的网站用的都是1.1
还有HTTP/1.0 HTTP/2 HTTP/3
后两个版本对HTTP的功能做了很多扩充, 但是也有很多未知的bug,企业不愿承担这样的风险所以大多数企业还是用的1.1版本
请求头(header)

Host属性

Content-type和Content-Length
Content-Length 描述了body的长度 单位是:字节

Content-type 描述了body的数据格式
提示了接收方如何来解析body中的数据,http能携带的数据种类有很多

请求和响应中都会用到这两个header属性
如果有body没有这俩属性都是会错误的, 同样没有body也就会没有这俩属性
User-Agent(简称UA)
UA主要描述了系统是啥版本,浏览器是啥版本


Referer
描述了当前这个页面,从哪个页面跳转过来的
如果直接在搜狗主页的地址栏输入url,此时请求中没有referer,如果点收藏夹,效果也一样,如下图,请求的header里就没有referer

假如你从搜狗的页面输入一个信息,然后你到了你想要的信息的页面,就可以看到referer就是sougou主页,因为是从搜狗主页跳转过来的
举个例子


Cookie
 Cookie的本质是浏览器在本地存储用户自定义数据的一种关键机制
Cookie的本质是浏览器在本地存储用户自定义数据的一种关键机制
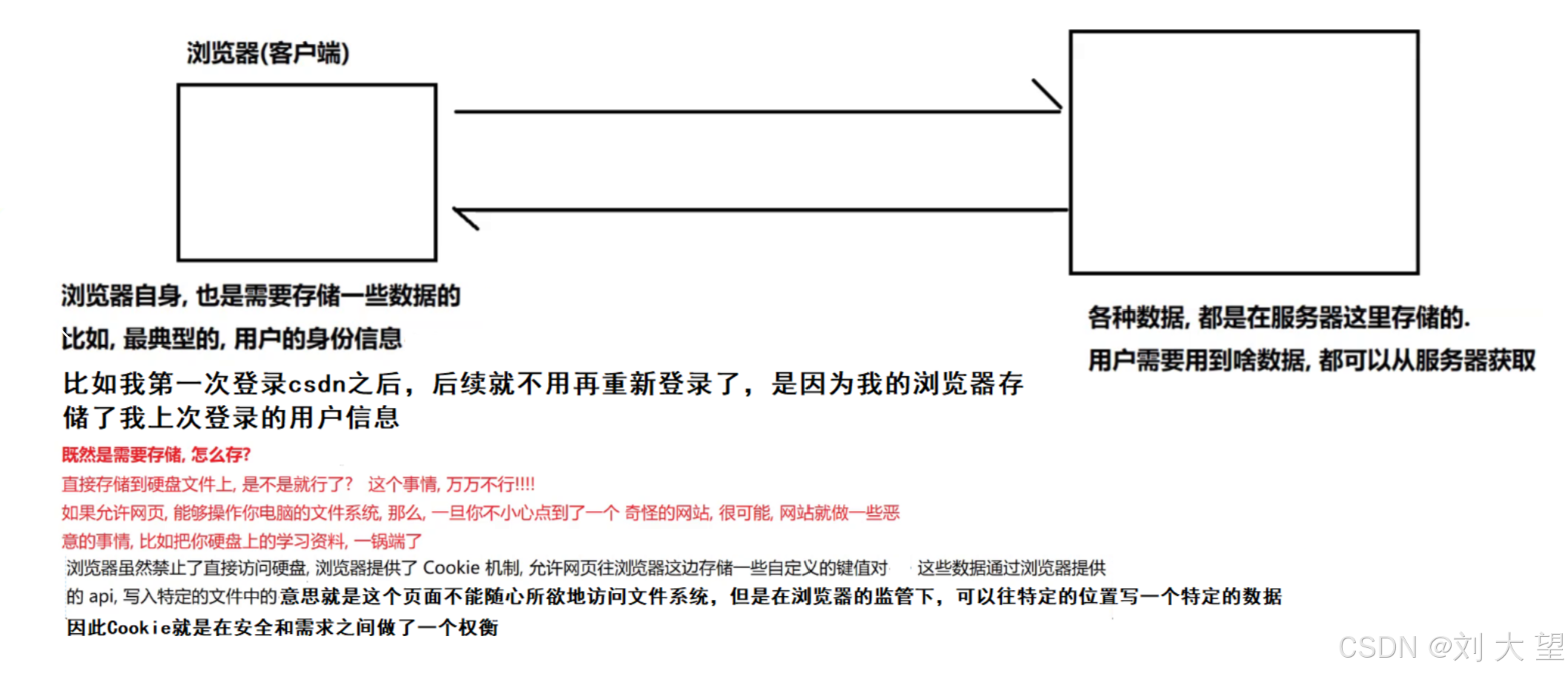
由于网页有很多,我访问搜狗,是需要存一些数据,访问百度也需要存一些数据,针对这种情况,做法是分开,每个网站都存自己的cookie,cookie是按照域名为维度进行存储的
同一个网站(搜狗的主页,搜狗的结果页,搜狗的图片)都共享一份cookie
不同网站(百度,美团,淘宝)则是各自有各自的cookie
那么针对cookie有三个问题
1.cookie从哪里来?
从服务器来的,当我们的浏览器访问服务器的时候,服务器就会在http响应中,通过Set-Cookie字段,把Cookie的键值对,返回给浏览器,浏览器收到这个数据,就会在本地存储
2.cookie到哪里去?
会在下次请求的时候,把cookie带给服务器,cookie在浏览器这边只是暂存,真正要让这个数据发挥作用,还是得由服务器来使用
3.cookie有啥用?
cookie是浏览器本地存储数据的机制,存储的不一定非得是角色,任何想存的数据都行(前提是字符串)由于cookie存储空间有限,一般也不会用cookie存太大的
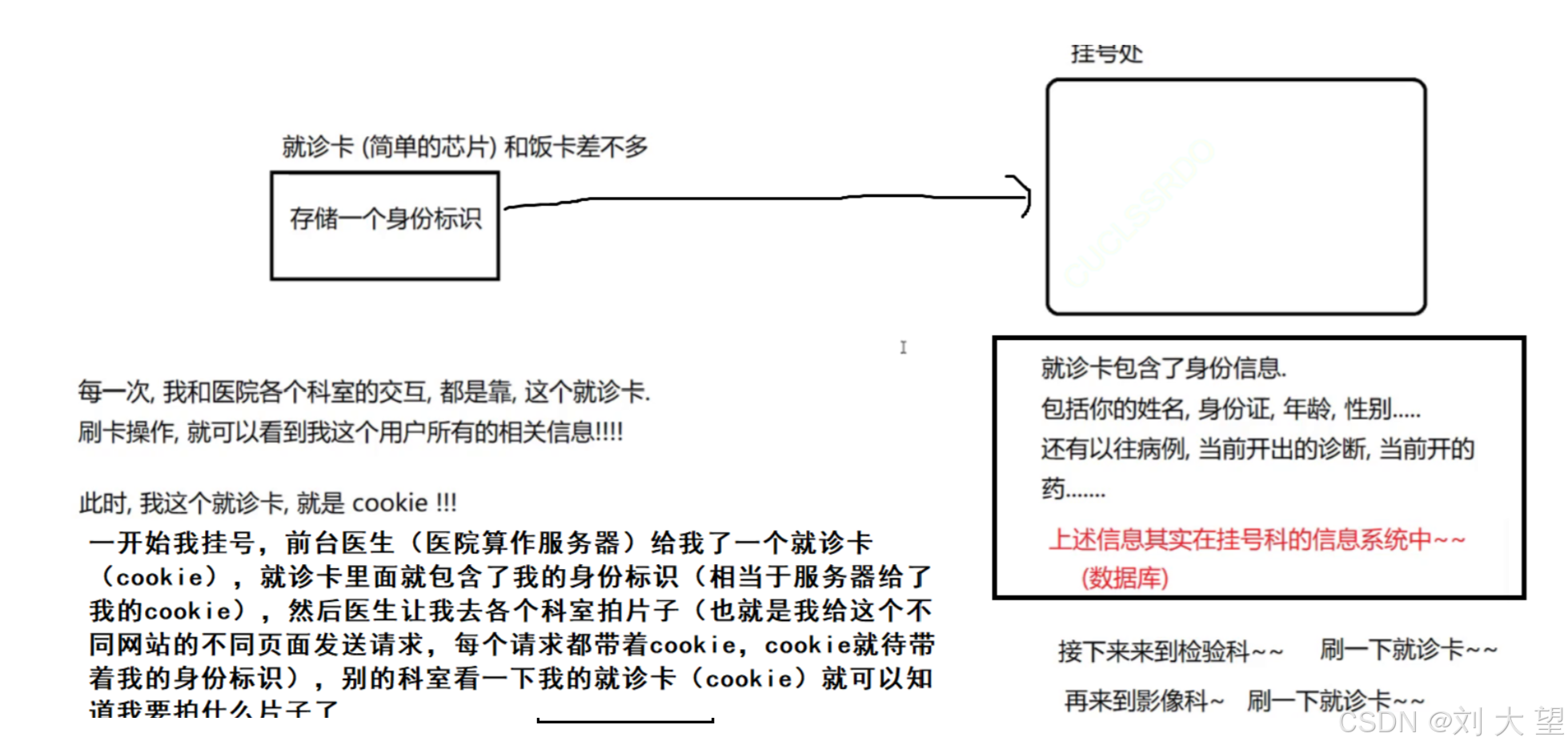
cookie这里最典型的应用就是存储用户的身份信息
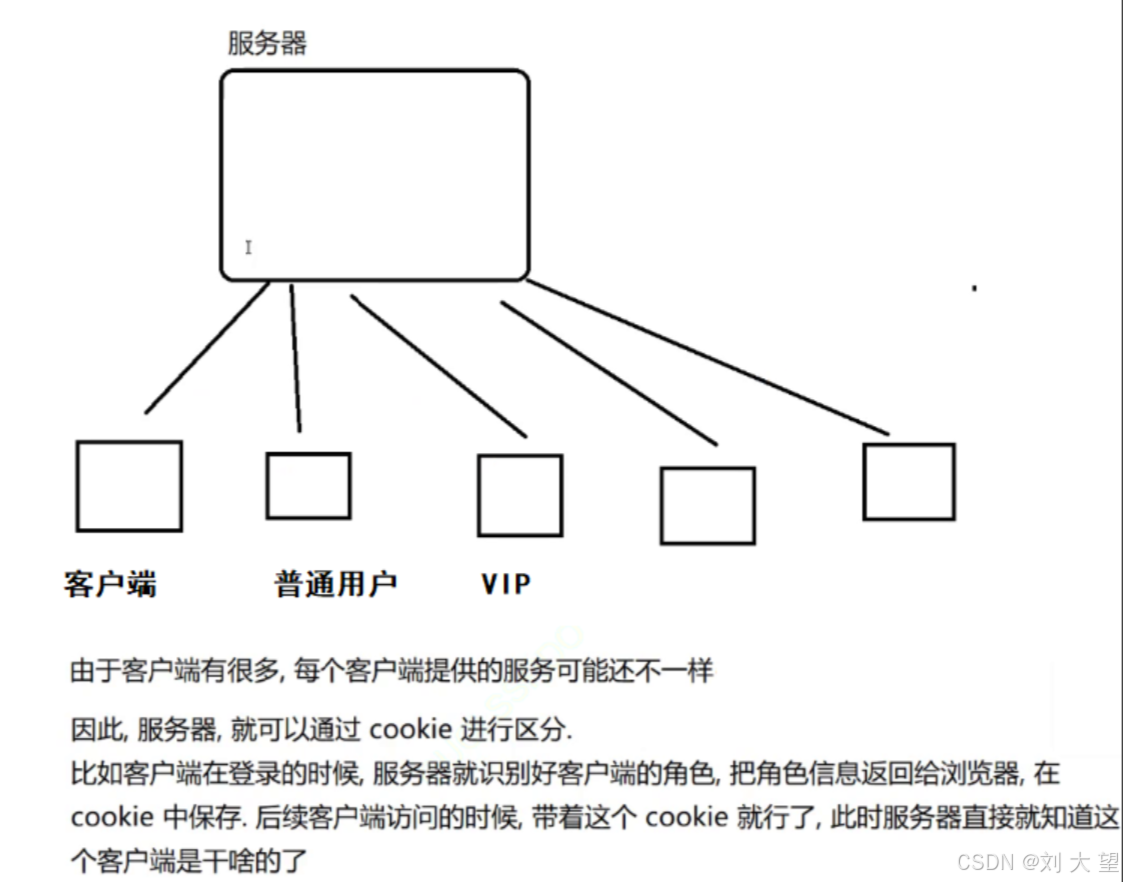
举个例子

业务场景中cookie和session通常配合出现cookie是在客户端这边session实在服务器那边
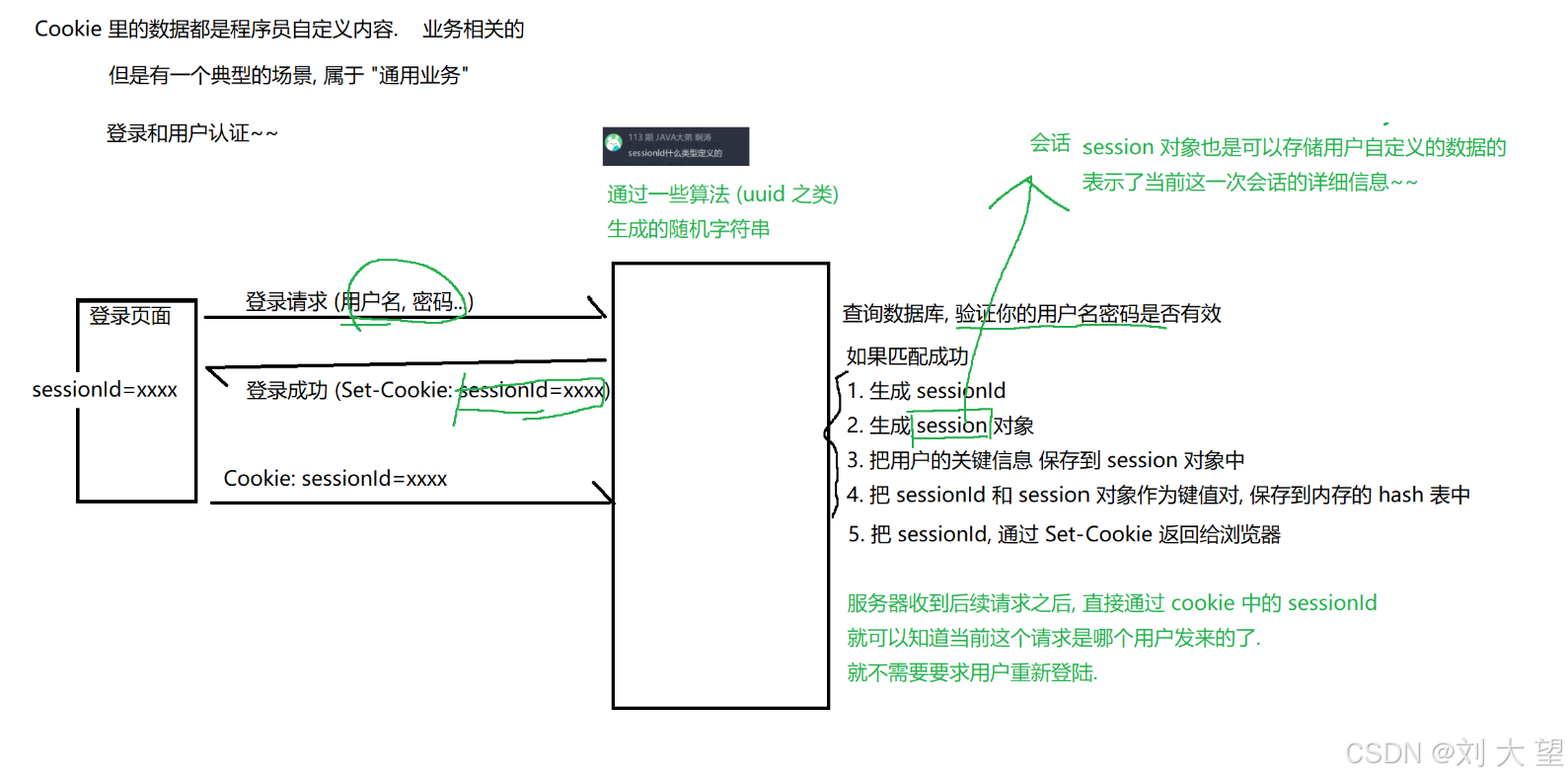
session这里不做过多介绍
当前在http中遇到的键值对
1.url中的query string
2.header部分,每一行都是一个键值对
3.body部分,如果Content-Type为x-www-form-urlencoded或者json,body的内容也是键值对
4.Cookie里面存储的数据还是键值对
这些键值对都是允许用户自定义的
这些自定义键值对,都是http协议留给程序员进行扩展的地方
为什么http能大火,就是因为他强大的扩展性
正文(body)
正文中的内容格式和 header 中的 Content-Type 密切相关.可以理解成就是按照Content-Type的格式类型写的
Http响应首行
首行由版本号,状态码,状态码描述组成
状态码 是个数字,数字来表示这次请求执行成功还是失败,以及失败的原因
(比如我用海尔洗衣机,中涂出错了,洗衣机显示一个E02,我就去查了一下,原来E02是错误的标志,什么出错呢?是甩干的时候洗衣机盖子没盖好的标志)
状态码描述 通过一个或者一组单词,描述这个状态码的含义
Http的状态码非常繁多,是因为HTTP遇到的情况太复杂了
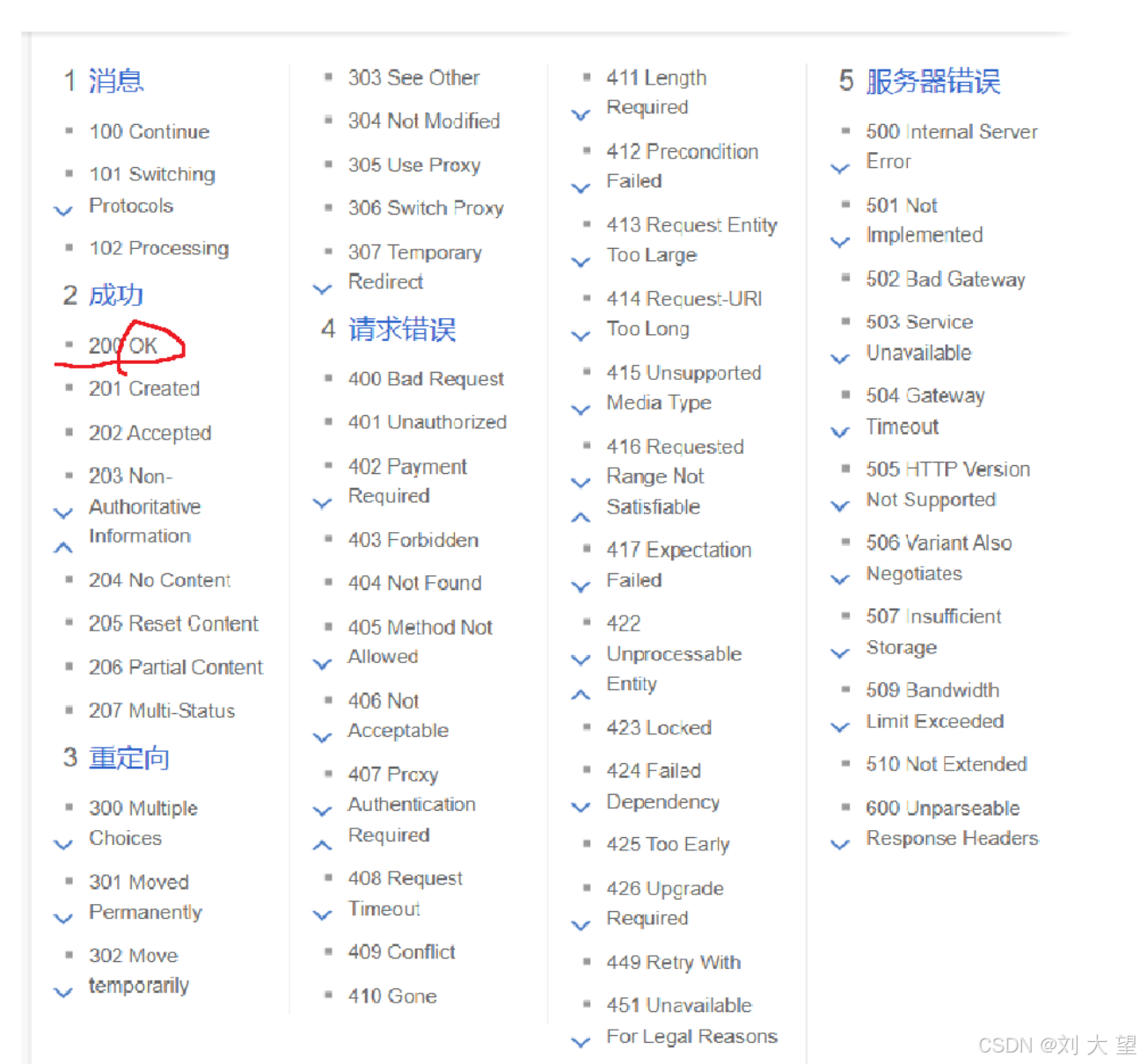
虽然上述的状态码很多,但是常见的就几个
(1).200 OK 表示的是请求成功

(2).404 Not Found 表示要访问的资源不存在
(3).403 Forbidden 访问被拒绝(无权限)
(3).403 Forbidden 访问被拒绝(无权限)
(4).500 Internal Server Error 服务器内部错误
这个状态码你在互联网上不常见,但是在你自己写代码的过程中非常常见,比如你的服务器bug了,抛了异常但是没有catch到,就会500
(5).504 Gateway Timeout 服务器访问超时了
浏览器给服务器发送请求,服务器就要返回响应,结果服务器迟迟没响应
(6)302Move temporarily 临时重定向
Moved Permanently 永久重定向
重定向:访问旧的地址,被自动引导到新的地址上
临时重定向就是我这次重定向了,下次要不要重定向不确定
状态码虽然很多,但是总的可以分成几个大类

后面的Header和Body响应就和请求没啥区别了,具体参照 http请求 做参考
如何去构造HTTP请求
1.直接通过地址栏,输入一个url,然后就会构造出一个get请求
2.html中,一些特殊标签,也会触发get请求
例如link,script,img,a
比如有个页面中,有一个img标签,此时当页面被加载好了之后,浏览器就会根据标签的src属性,给服务器发起一个get请求,来获取图片内容(想触发get请求需要是个网络资源,如果是个本地资源,就不会触发get请求)
3.form表单,可以触发get请求和post请求
<form action="https://www.sogou.com/abc/def" method="get"><input type="text" name="aaa"><input type="text" name="bbb"><input type="submit" value="提交">
</form>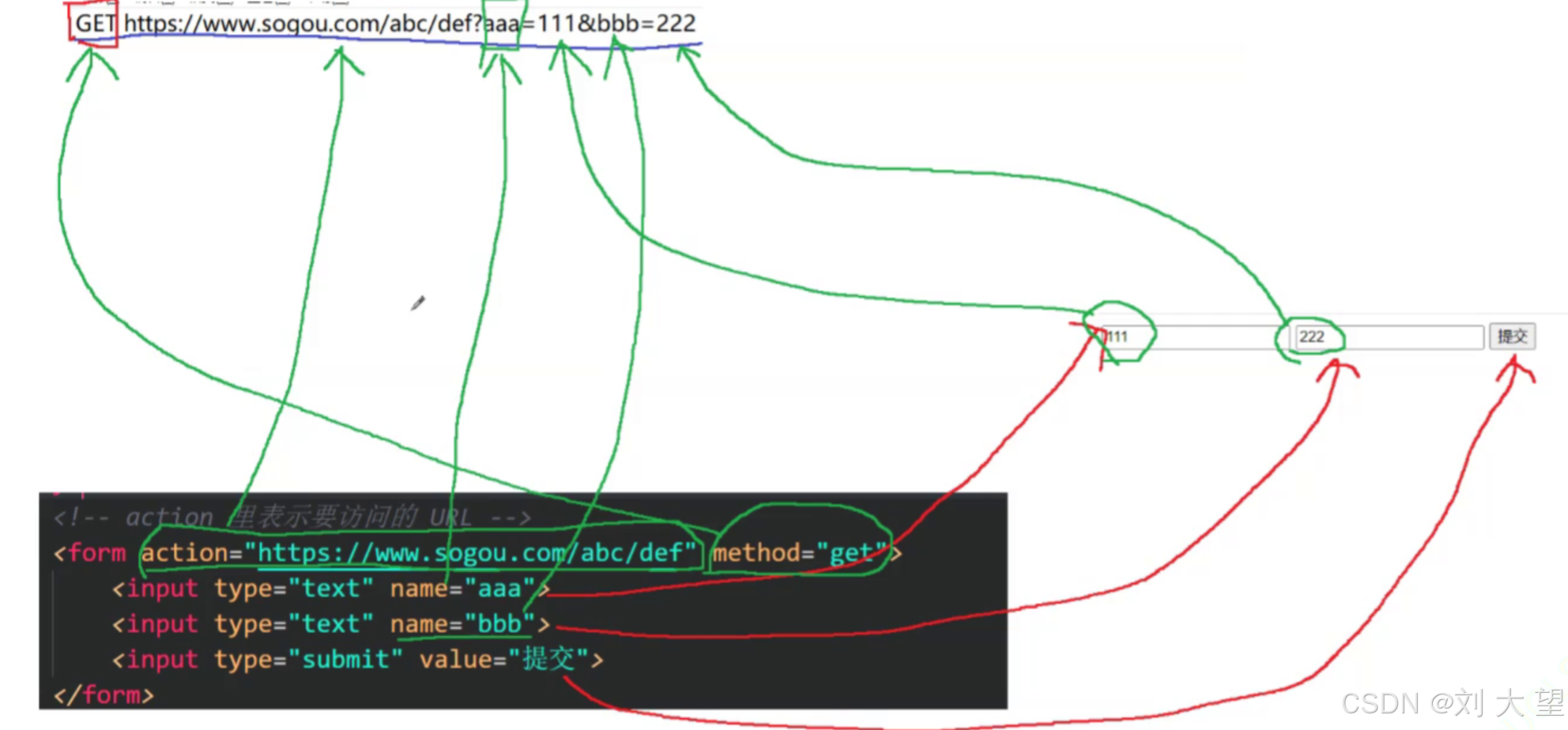
form只支持get和post,其他的http方法就无能为力了
(4).ajax[重要]
ajax 全称 Asynchronous Javascript And XML
ajax是一种前端和后端异步交互的一种方式
什么是异步呢?
异步(Asynchronous)是一种编程或系统设计模式,指任务或操作无需按顺序执行,也无需等待前一个操作完成即可启动后续操作。异步的核心思想是通过非阻塞的方式提高效率
js提供了原生的ajax的api,这个api贼难用,这里用jquery里面提供的ajax的api
<html lang="en">
<head><meta charset="UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>ajax</title><script src="https://code.jquery.com/jquery-3.7.0.min.js"></script>
</head>
<body><script>$.ajax({url: "https://www.sogou.com",type: "post", // 可以写作 post, put, delete 等等。写成大写的也行data: "这是 body",contentType: "text/plain",success: function(body) {// 写处理响应的代码console.log(body);}});</script>
</body>
</html>success表示如果请求成功之后,我们要通过一个回调函数来处理响应
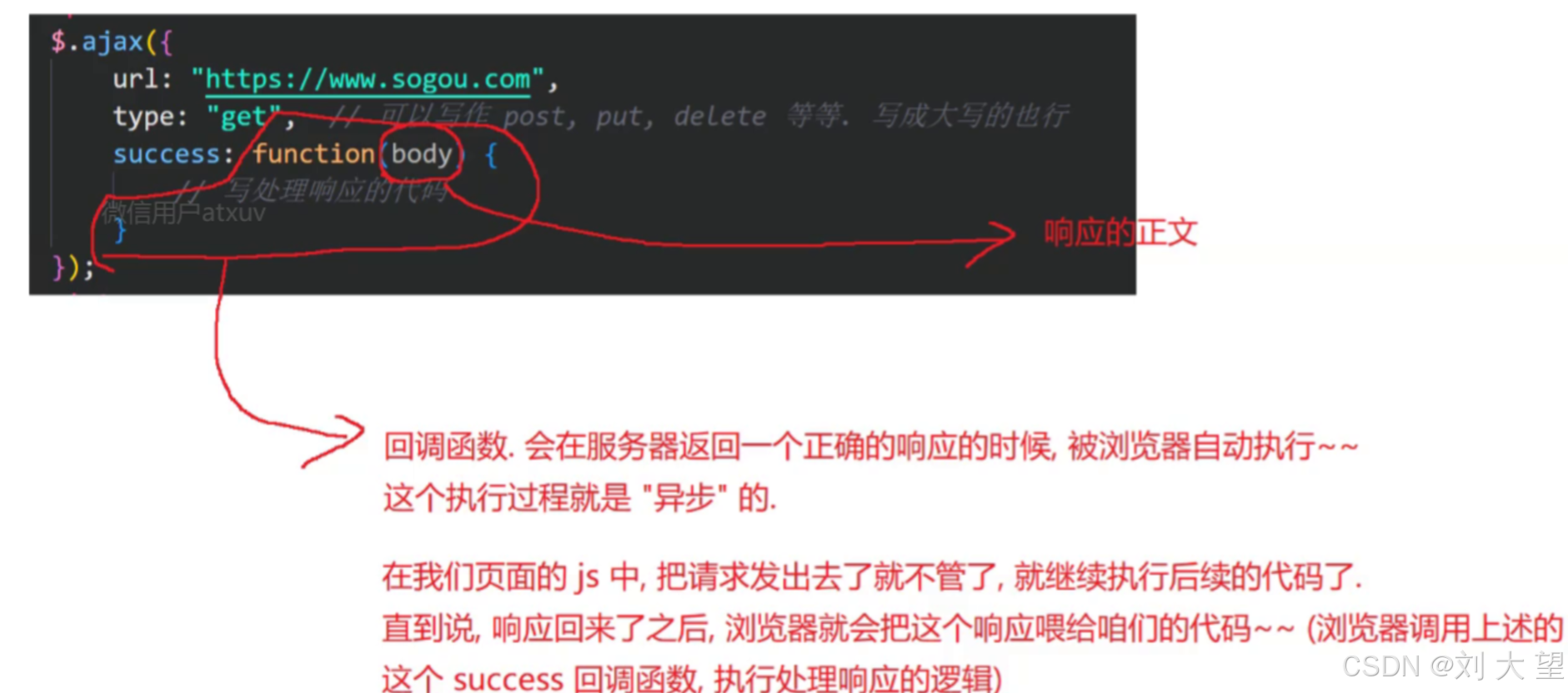
回调函数就是不会立刻去调用,而是取决于后端返回响应的时间
通过postman来构造
以上就是HTTP的基本内容了,用一张图来说就是
二.HTTPS协议
HTTPS(超文本传输安全协议)是基于HTTP的,仅仅比HTTP多了一个“加密层” S就是secure(安全)
为啥要有HTTPS呢?
归根结底还是安全原因
就比如上面提到的运营商劫持问题
下载⼀个天天动听未被劫持的效果,点击下载按钮,就会弹出天天动听的下载链接.
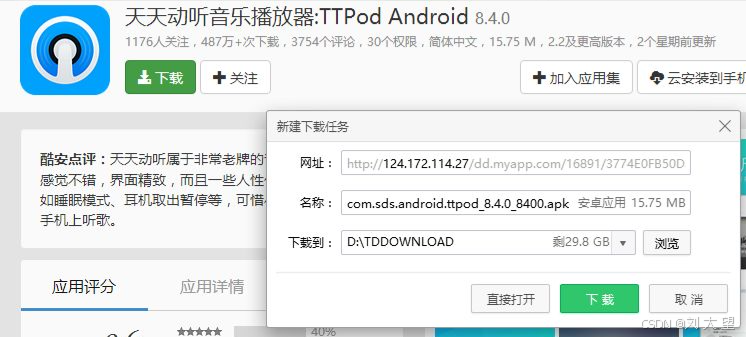
已被劫持的效果,点击下载按钮,就会弹出QQ浏览器的下载链接
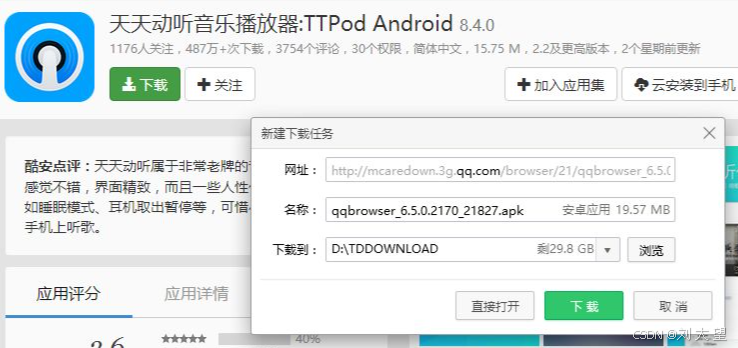
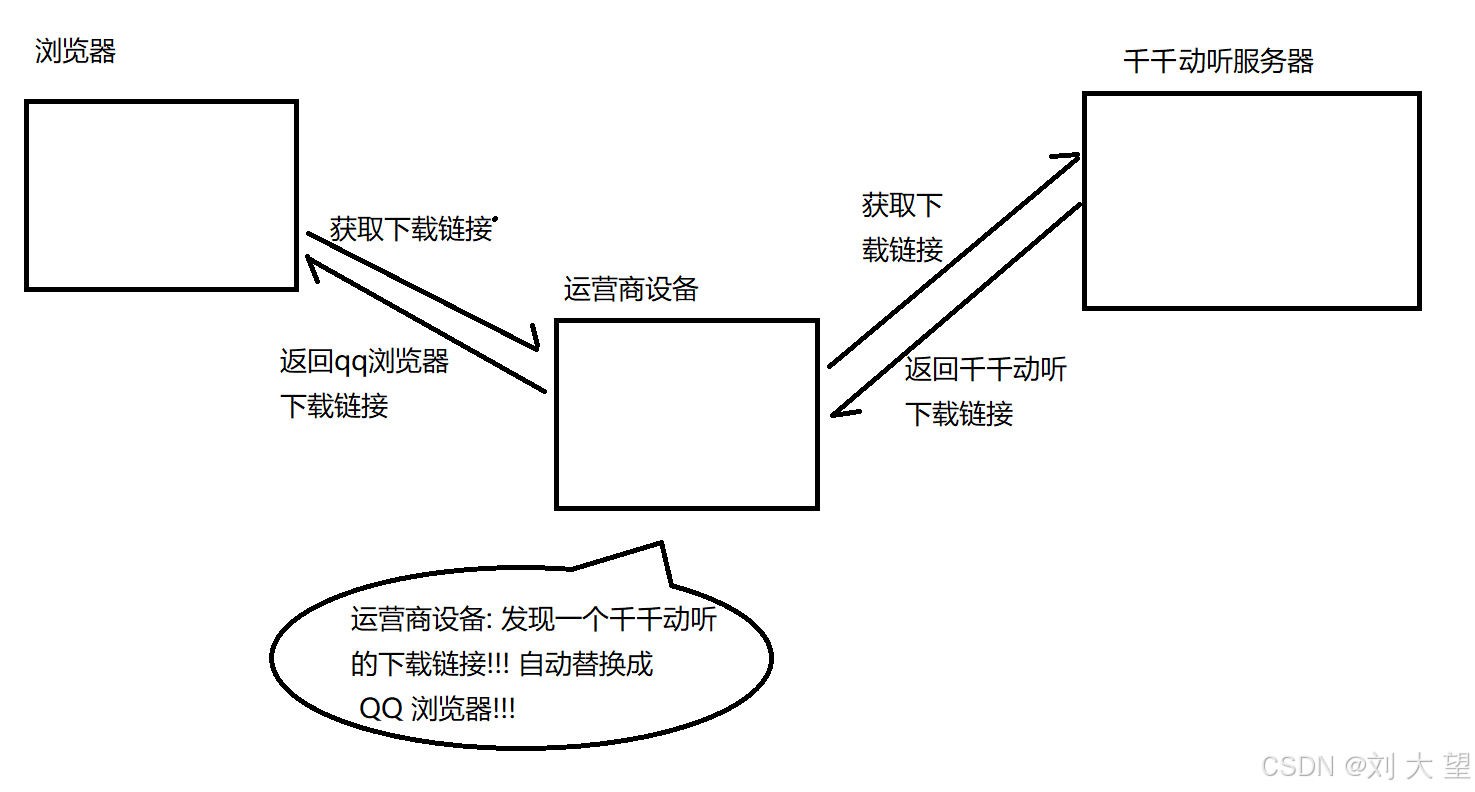
由于我们通过⽹络传输的任何的数据包都会经过运营商的⽹络设备(路由器,交换机等),那么运营商的⽹ 络设备就可以解析出你传输的数据内容并进⾏篡改.点击"下载按钮",其实就是在给服务器发送了⼀个HTTP请求,获取到的HTTP响应其实就包含了该 APP的下载链接.运营商劫持之后,就发现这个请求是要下载天天动听,那么就⾃动的把交给⽤⼾的响应 给篡改成"QQ浏览器"的下载地址了.
 为了能够改善上述问题,就引入了加密,因此HTTPS就应运而生了
为了能够改善上述问题,就引入了加密,因此HTTPS就应运而生了
对称加密
对称加密:只有一个密钥:key
明文+key==>密文
密文+key==>明文
加密解密使用同一个密钥,对称加密的特点就是算起来比较快速
客户端和服务器最开始通信的时候就得有一方生成唯一密钥通过网络传输给对方
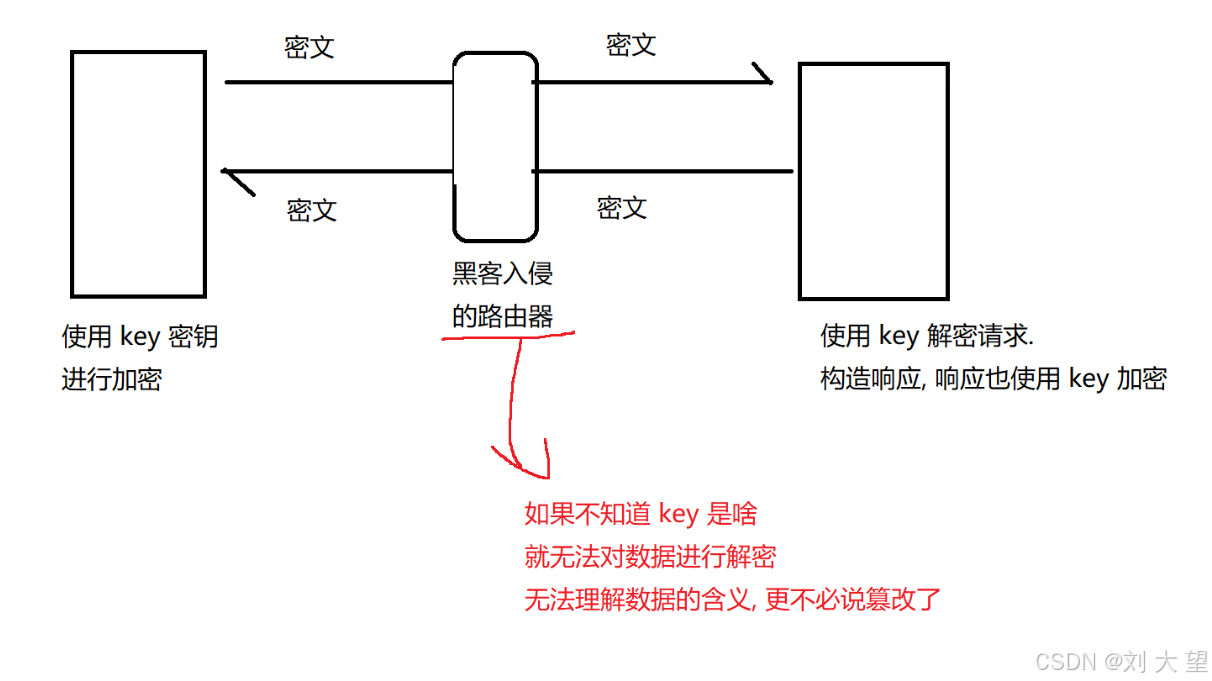
但是用来加密的密钥通过网络传输是明文传输的也很可能会被黑客获取
 此时我们就要对密钥加密
此时我们就要对密钥加密

那如何解决呢? 就需要用到非对称加密
非对称加密
非对称加密:需要两个密钥,一个是公钥(public),一个是私钥(private)
明文+public==>密文
密文+private==>明文
或者
明文+private==>密文
密文+public==>明文
公钥和私钥是对称出现的,用一个加密就用另一个解密
非对称加密相比对称加密消耗的资源更多,效率更低
公钥私钥是服务器来生成的, 服务器保存自己的私钥, 任何客户端都能拿到公钥
也可以想象成公钥就是一把锁, 私钥就是钥匙
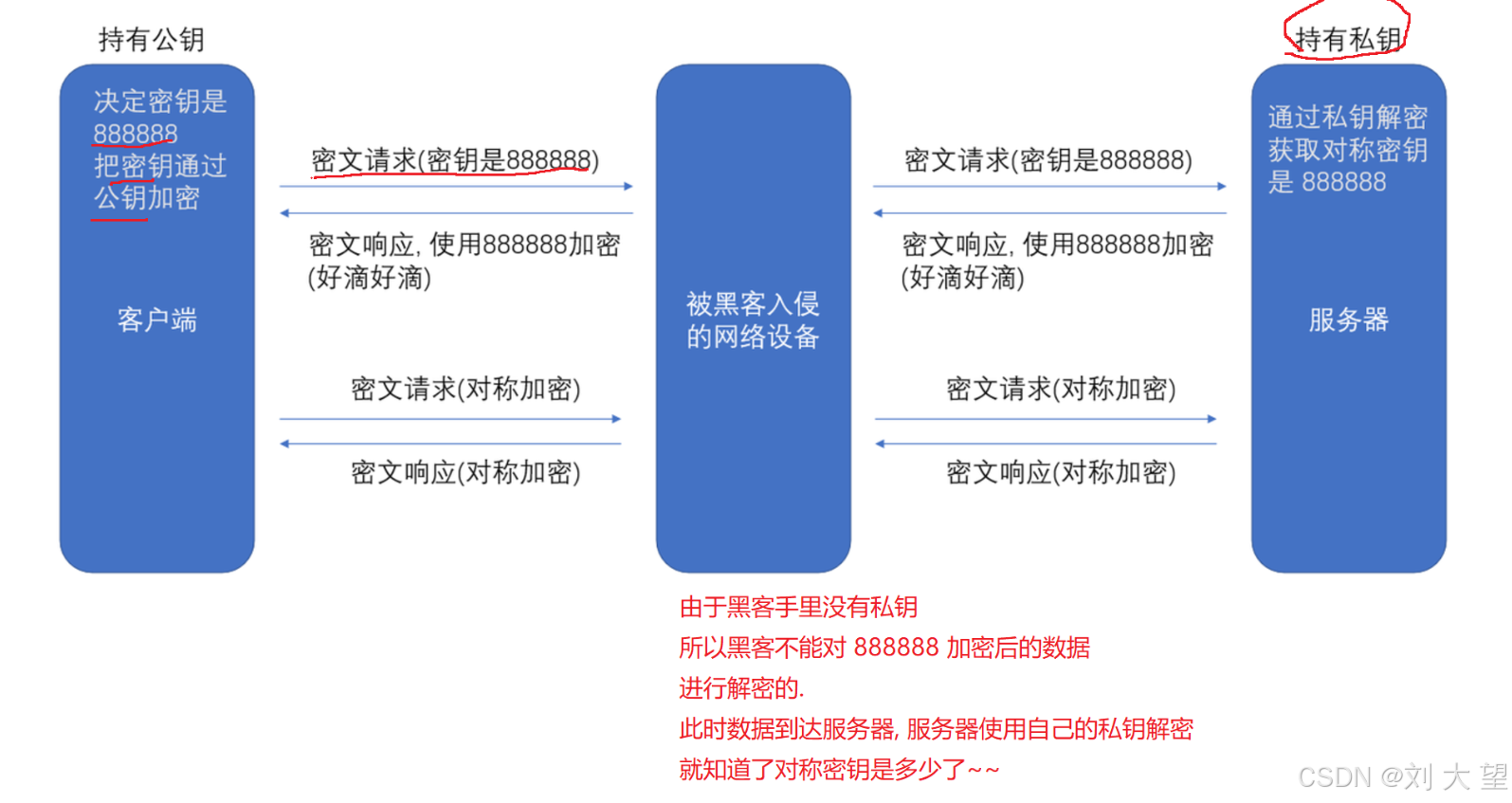
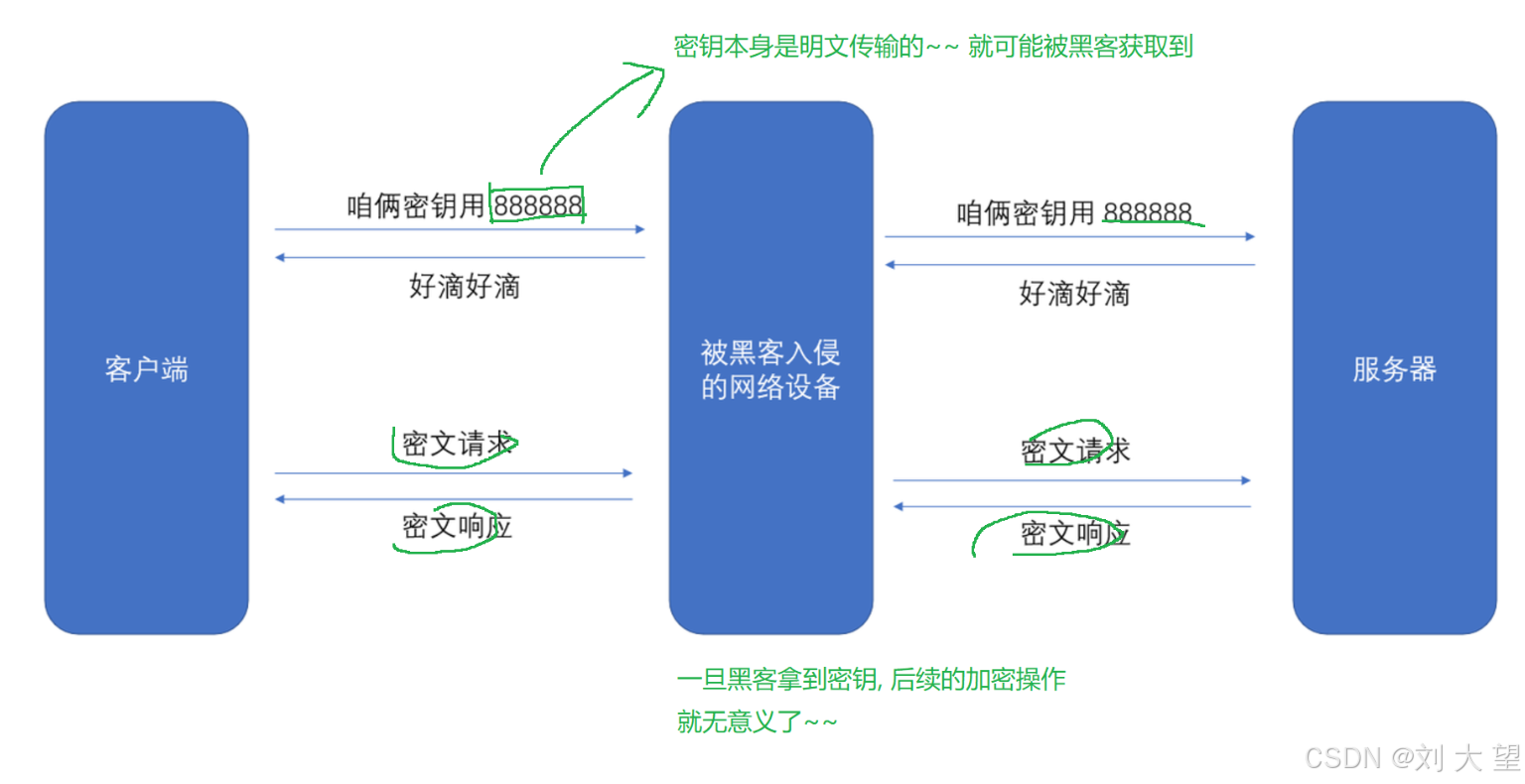
上述第一次密文请求是用非对称密钥来加密对称密钥(888888) 这样对称密钥就不会被黑客劫持 后面的加密请求和响应就可以通过对称密钥来加密, 之所以不全都使用非对称密钥还是因为非对称密钥消耗的资源更多,效率更低


上述过程看似天衣无缝但是还是存在一个重大漏洞:中间人攻击
中间人攻击
举个例子:一个缉毒警察和三个毒贩ABC 毒贩A和BC认识但是BC不互相认识, 一天毒贩A落网了,为了能立功减罪, 就配合警察抓捕BC,在A的指使下BC要完成一单交易由于不互相认识对方必须要分别跟A对接, 此时缉毒警察就可以代替A分别跟BC对接, 就可以掌握具体的交易时间地点,随后就一锅端了, 上述虽然BC看似完成了对接,但是中间有内鬼
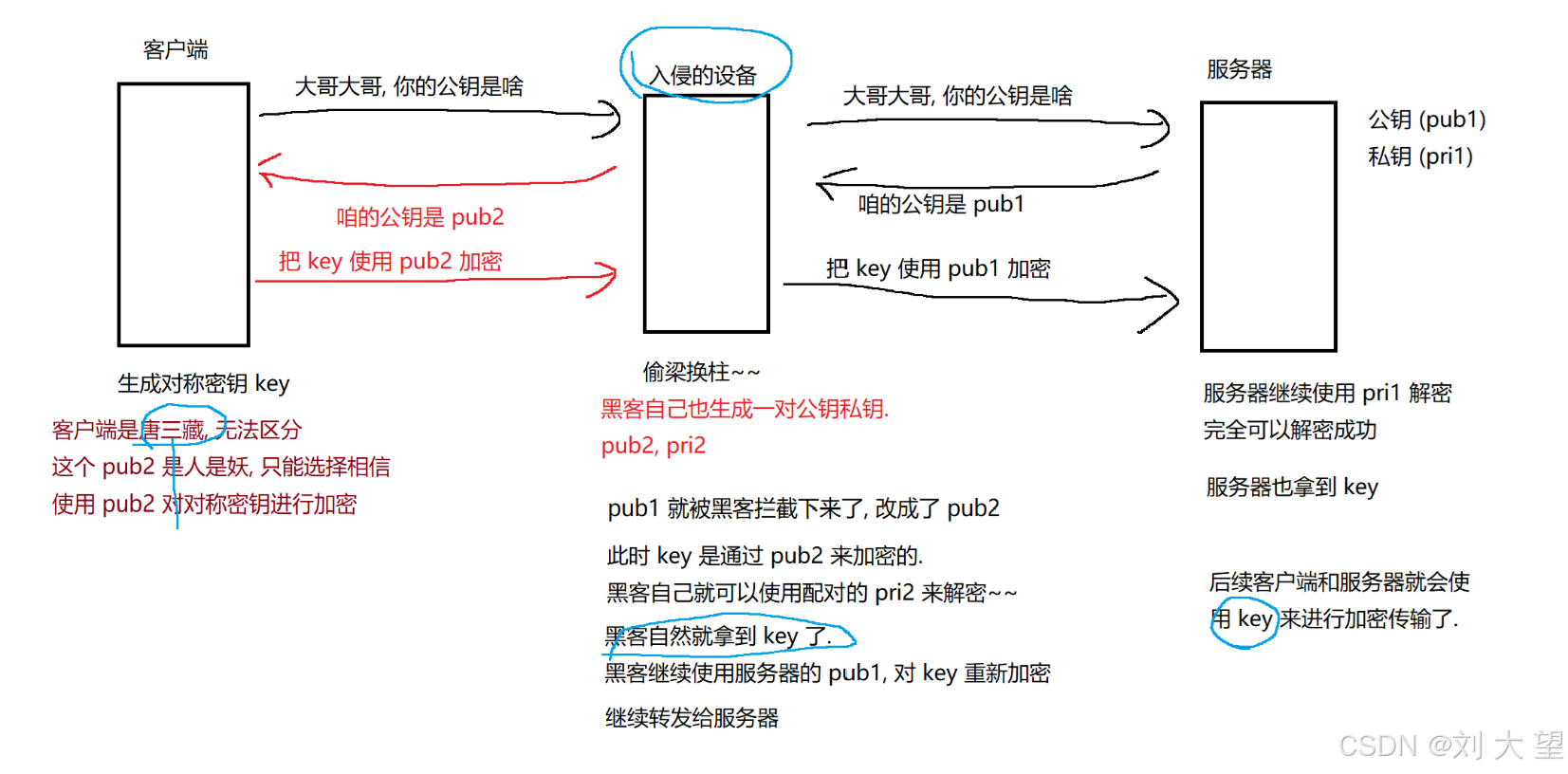
上述情况,黑客在中间的操作,客户端和服务器都是感知不到的,我们把这样的操作就叫做中间人攻击
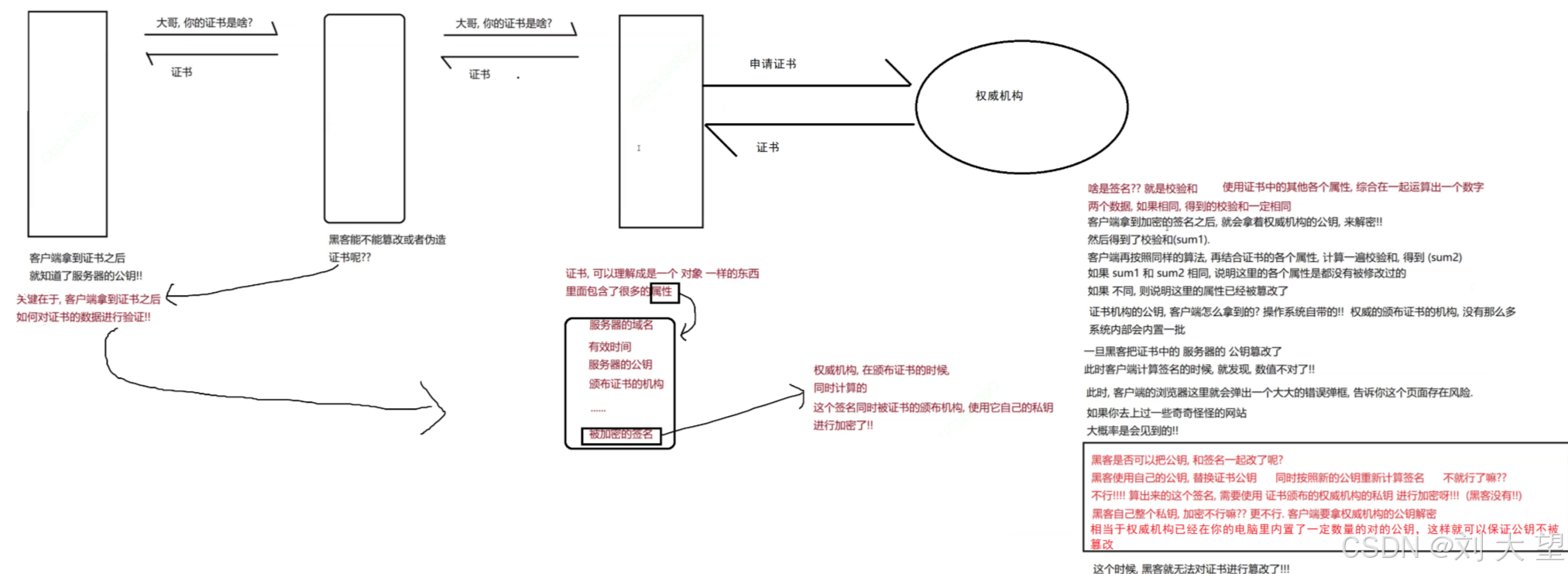
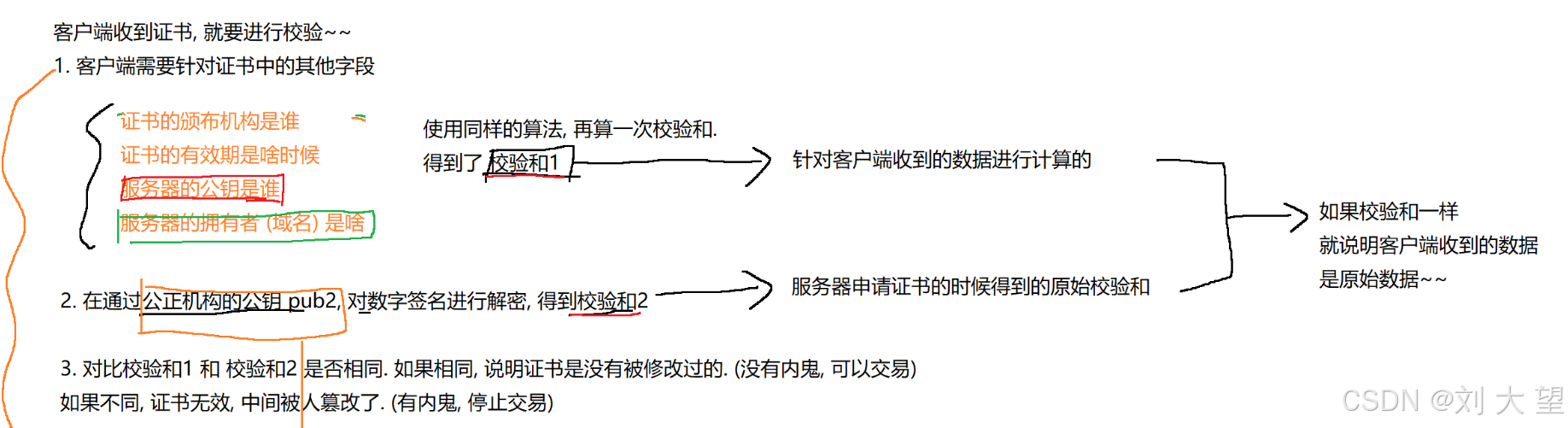
而中间人攻击,破解的关键就是要让客户端能够信任公钥!如果客户端能够识别出这个公钥是不是服务器本身的,那么问题不就迎刃而解了嘛 ,我们就要引入证书
引入证书
个证书不是纸质的证书,而是一串数据(类似于一个对象,里面有很多属性),是一个数字证书。
假如我现在有一个服务器,我就需要去这个机构里申请证书,申请的时候,当然要提交一些材料(甚至要交钱),机构进行审核,审核通过了,就颁发证书。
提交资料的时候,服务器的公钥,也一起提交过去,此时,
证书中就包含了服务器的公钥