LobeChat知识库,小团队的选择,理解Embedding与向量数据库的关系
LobeChat
开源地址
https://github.com/lobehub/lobe-chat

部署目标
使用 Docker Compose 部署 LobeChat 服务端数据库版本,实现个人AI助手,局域网多端同步AI助手,局域网小团队共享AI助手。
系统兼容性说明
Note
Linux/macOS系统可直接运行。
Windows 用户需通过 WSL 2 运行
端口占用检查:确保 3210、8000、9000、9001 端口未被占用。
部署步骤
STEP 01
执行以下命令初始化部署目录 lobe-chat-db 将用于存放你的配置文件和后续的数据库文件。
mkdir lobe-chat-db && cd lobe-chat-db
STEP 02
获取并执行部署脚本:
bash <(curl -fsSL https://lobe.li/setup.sh) -l zh_CN
按提示完成配置,第一项选择1端口模式。IP填写内网地址。

脚本会生成安全密钥和访问地址,妥善保存。完成后即可访问Web界面进行初始化与多端登录。
网络配置后,团队其他成员也可以通过内网IP共享使用AI助手。
启动界面及功能分布如下:
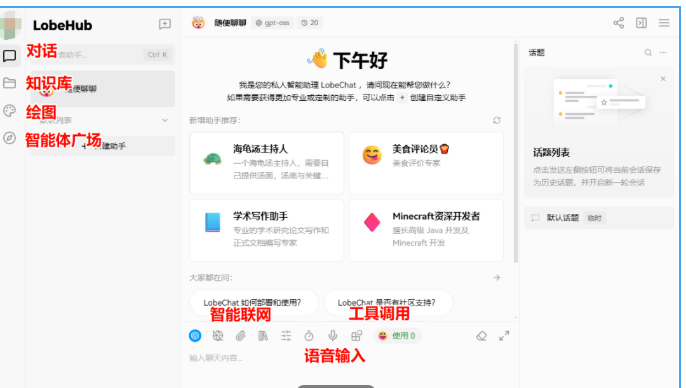
功能非常的全面,下面我们重点讲下知识库功能。
知识库功能
知识库是LobeChat的核心生产力模块。支持文档导入、自动切片、向量化、相似度召回、重排序与长上下文对话。演示中可见检索片段精准、引用清晰、上下文稳定,适合技术文档、标准规范、图纸说明、制度流程等材料的问答与写作辅助。
召回效果展示
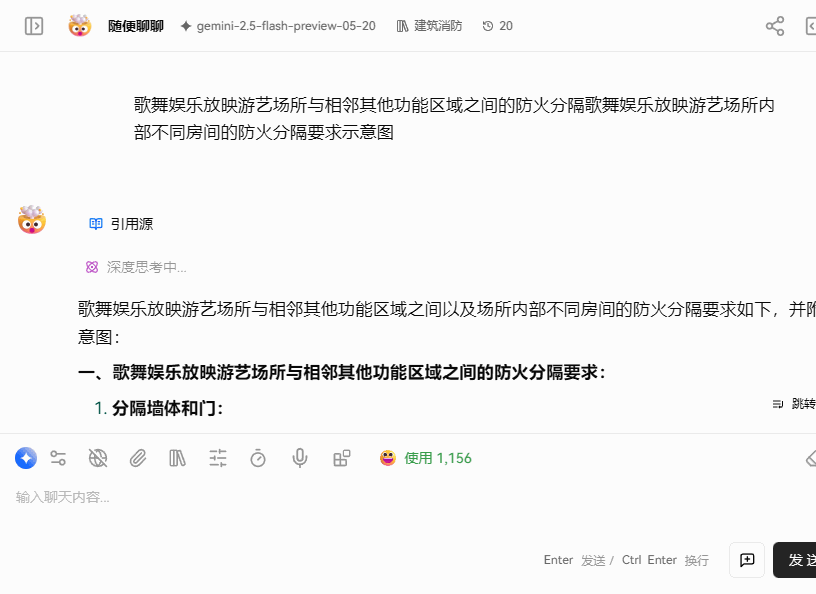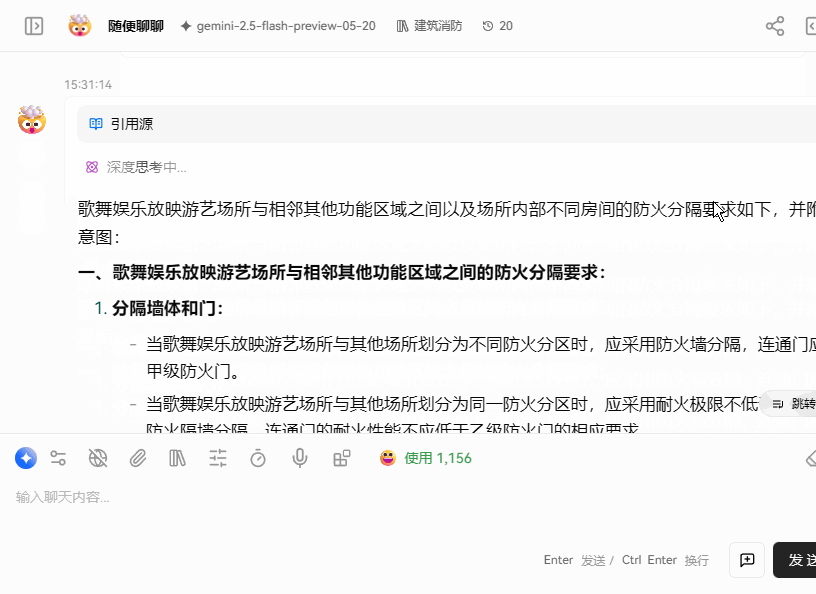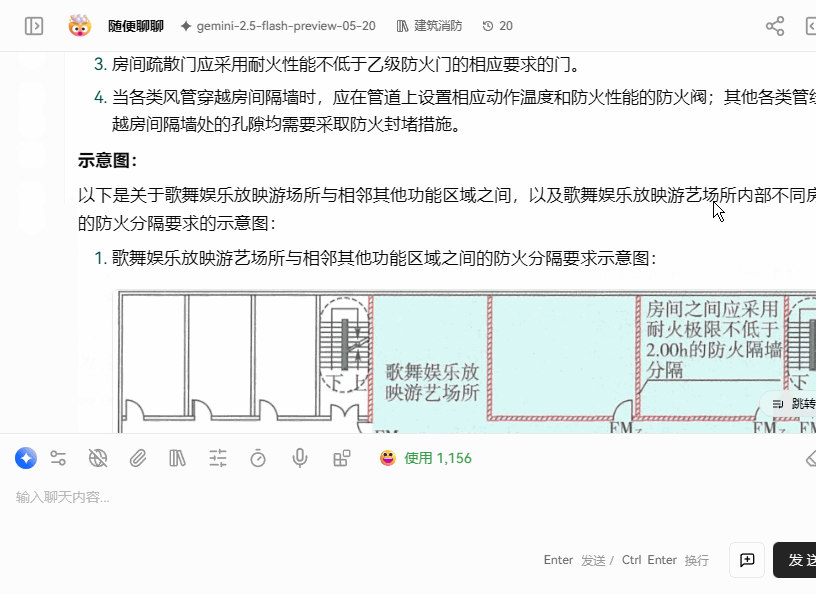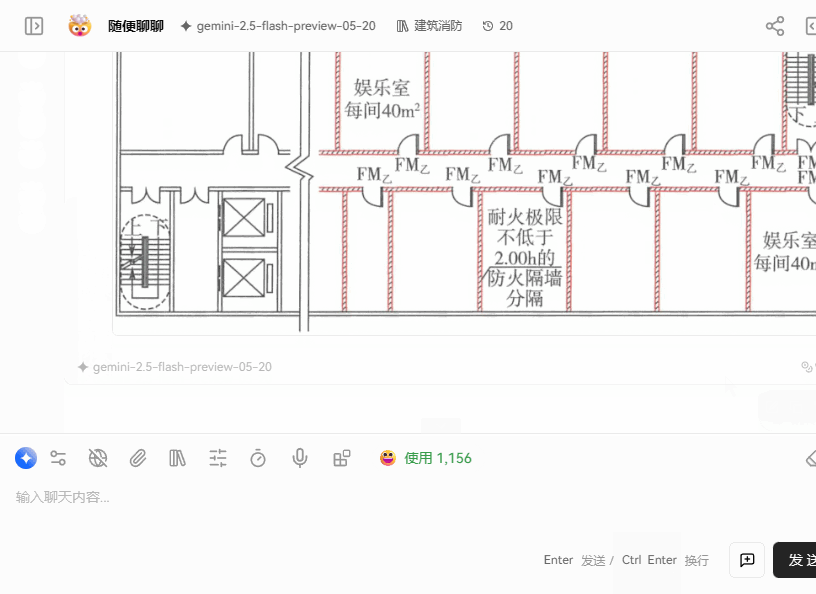
启用方式
左侧文件夹入口,新建知识库并命名即可。
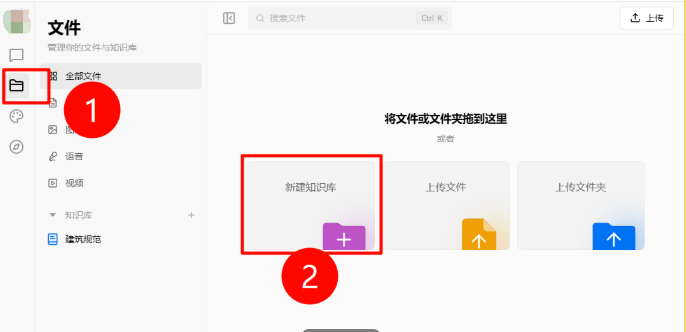
导入文档后,可选择向量化处理。
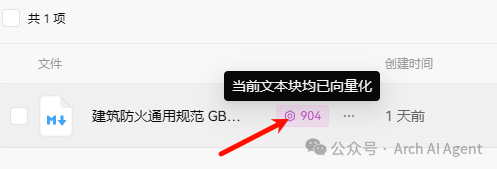
处理完成可查看向量化结果及段落切片效果。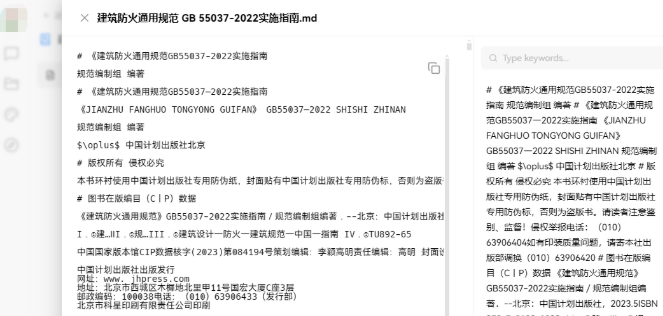
知识库这样就建好了。
向量模型配置
默认用的是OpenAI 的Embedding模型(text-embedding-3-small),需要有相应的API Key。
如果需要用其他向量模型,需要手动配置向量模型,需要修改环境变量。
以硅基流动的BAAI/bge-m3模型为例,其他配置参照修改就好。
SILICONCLOUD_API_KEY=sk-xxxxxx...
SILICONCLOUD_PROXY_URL=https://api.siliconflow.cn/v1/
DEFAULT_FILES_CONFIG="embedding_model=siliconcloud/BAAI/bge-m3"
修改后重启docker生效。
LobeChat知识库技术详解
下面详解一下LobeChat知识库的工作原理,
LobeChat知识库的核心架构包含以下几个关键组件:
文档存储层
负责管理上传的各类文档文件,支持PDF、Word、Markdown等常见格式。文档以原始格式保存,便于后续的文本提取和处理。
文本处理引擎
将上传的文档解析为纯文本,并按照预设策略进行切片分段。每个文档片段保留原始的上下文信息和元数据,确保检索时能够准确定位来源。
向量化模块
集成Embedding模型将文本片段转换为向量表示。默认使用OpenAI的text-embedding-3-small模型,也支持通过环境变量配置切换为其他模型,如硅基流动的BAAI/bge-m3。
向量数据库
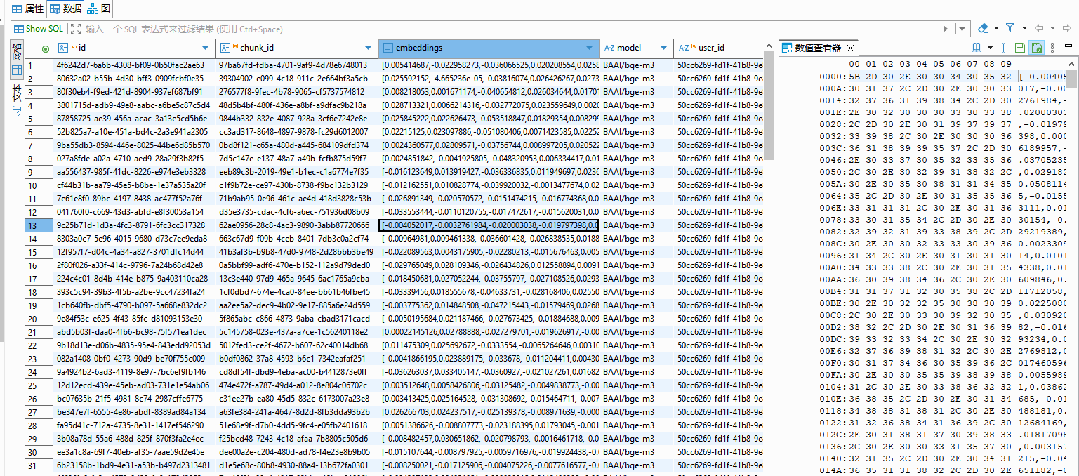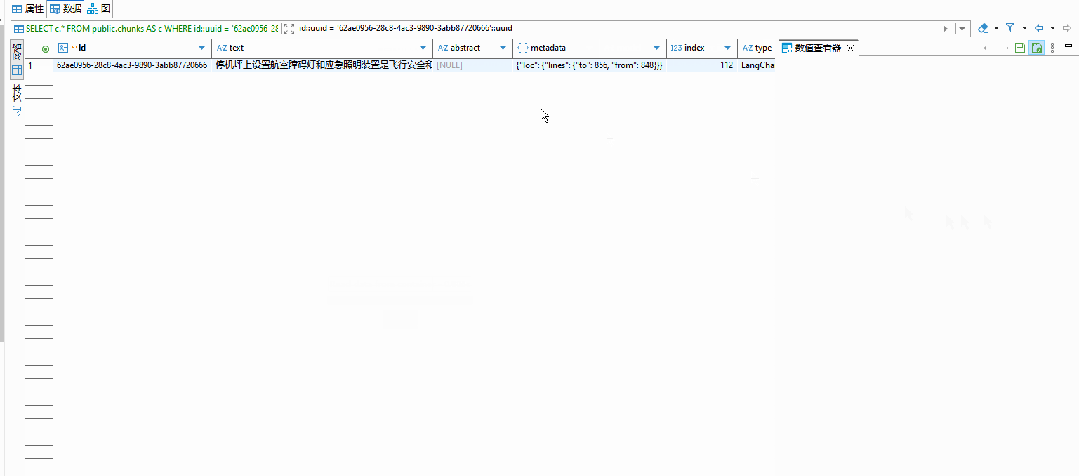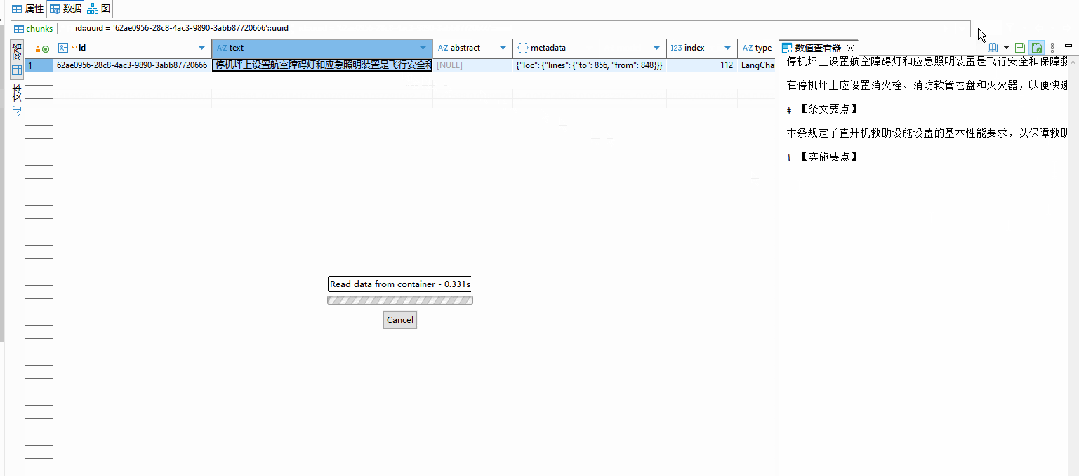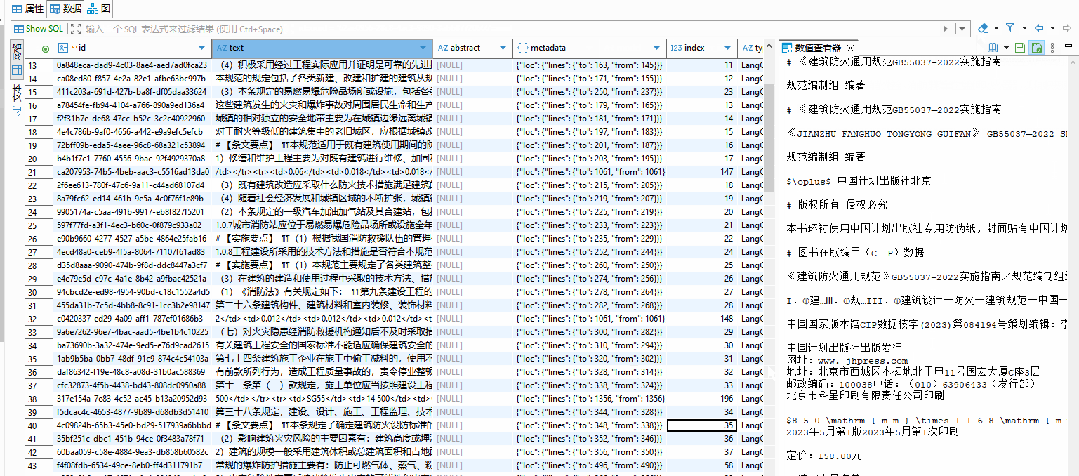
存储文档片段的向量表示,支持高效的相似度检索。当用户提问时,系统将问题也转换为向量,通过计算向量相似度快速找到最相关的文档片段。
数据库结构: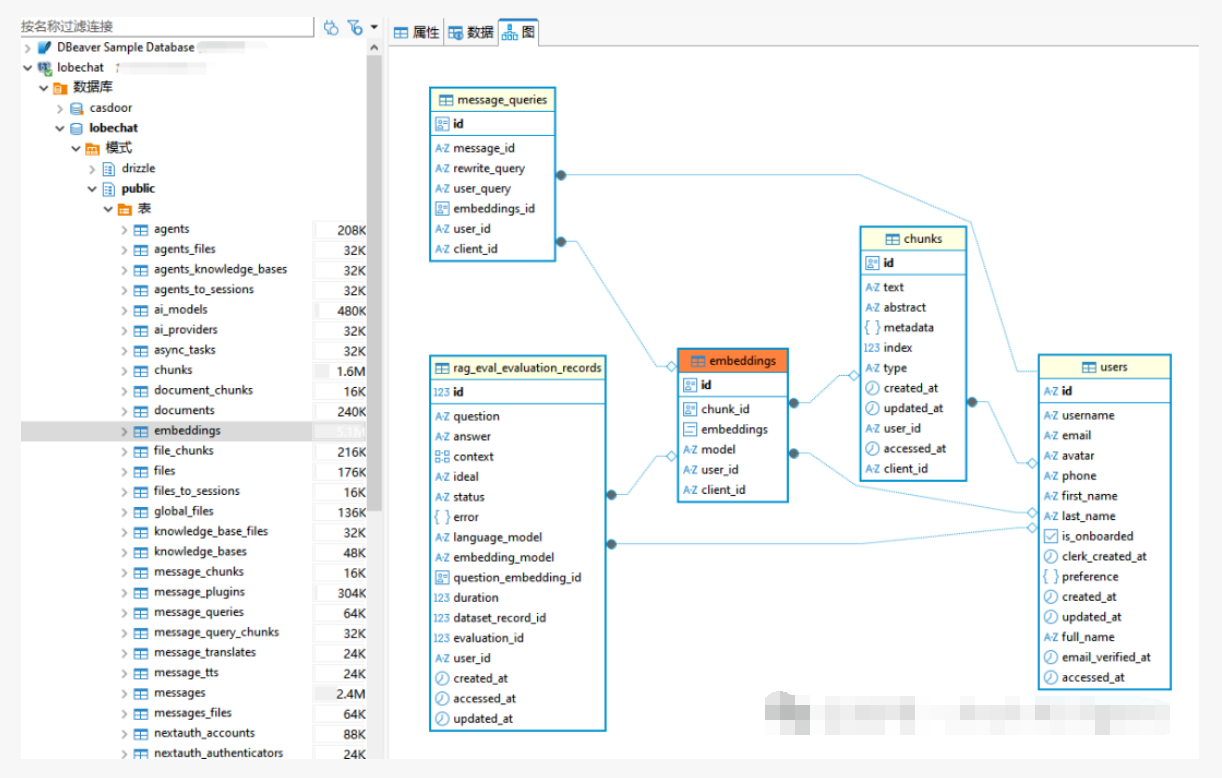
检索召回引擎
基于向量相似度计算,从知识库中召回与用户问题最相关的文档片段,并按相关度排序,为后续的答案生成提供证据支持。
对话生成模块
将检索到的相关文档片段作为上下文,结合用户的问题,通过LLM生成准确的回答,并在回答中标注引用来源。
知识库功能支持基础模块:
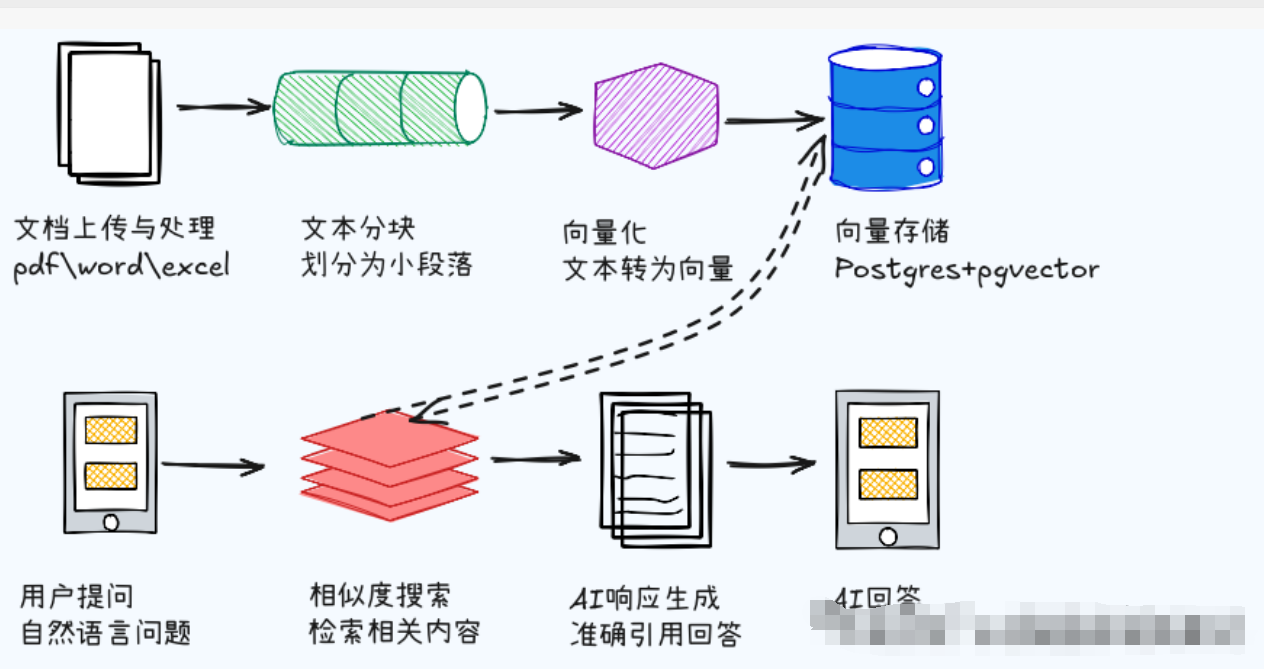
整个知识库问答的完整流程可以分为以下几个步骤:
1. 文档导入与预处理
用户通过Web界面上传文档后,系统自动解析文档内容,提取文本信息,并按照语义或段落进行切片处理,每个切片保留必要的元数据信息。
2. 向量化入库
系统调用配置的Embedding模型,将每个文档切片转换为高维向量表示,并将向量和原始文本一同存储到向量数据库中,建立索引以支持快速检索。
3. 用户问题向量化
当用户在对话中提出问题时,系统使用相同的Embedding模型将问题转换为向量表示,确保问题向量和文档向量在同一向量空间中。
4. 相似度检索召回
系统在向量数据库中计算问题向量与所有文档片段向量的相似度,选出相似度最高的若干个文档片段作为候选答案的证据材料。
5. 上下文构建与生成
将检索到的相关文档片段按相关度排序,构建为提示上下文,结合用户的原始问题一同发送给LLM进行答案生成。
6. 答案输出与引用标注
LLM基于提供的文档片段和问题生成回答,系统自动在回答中添加引用标注,显示答案来源的具体文档片段,确保答案的可追溯性和可信度。
知识库功能工作流程:
总结一下
LobeChat知识库功能实现了从文档上传到智能问答的全链路自动化,用户只需要上传相关文档并进行向量化处理,就能获得基于文档内容的准确问答服务。
整个过程中,向量化是核心环节,决定了检索的准确性,而LLM的生成能力则决定了最终答案的质量和可读性。