STL常见容器介绍
在 C++ 标准模板库(STL)中,容器的底层数据结构决定了其核心特性(如访问效率、插入 / 删除效率、内存开销等)。STL 容器分为三大类:序列式容器(按插入顺序存储)、关联式容器(按键有序 / 无序存储)、适配器容器(基于其他容器封装,改变接口或行为)。
一. 序列式容器
核心是 “按插入顺序保存元素”,不依赖元素值排序,支持通过索引 / 迭代器直接访问元素。
1. vector 动态数组
- 底层数据结构:连续的动态数组(基于固定大小的数组扩容实现)。
- 初始化时分配一块固定大小的 “初始内存”,当元素数量超过当前容量(capacity)时,会触发 “扩容”:
- 分配一块2 倍于当前容量的新内存(不同编译器可能为 1.5 倍,如 GCC);
- 将旧内存中的元素拷贝 / 移动到新内存;
- 释放旧内存,更新指针指向新内存。
- 初始化时分配一块固定大小的 “初始内存”,当元素数量超过当前容量(capacity)时,会触发 “扩容”:
- 核心特性:
- 随机访问效率极高:
operator[]和at()操作的时间复杂度为 O(1); - 尾部插入 / 删除(
push_back()/pop_back())效率高:O (1)(无扩容时); - 中间 / 头部插入 / 删除效率低:需移动后续元素,时间复杂度 O(n);
- 内存连续:缓存命中率高,但扩容可能导致内存碎片,且迭代器可能因扩容失效(旧内存释放后迭代器悬空)。
- 随机访问效率极高:
- 适用场景:频繁随机访问、尾部增删,且能预估元素数量(减少扩容)的场景(如存储列表数据、缓存数据)。
2. deque 双端队列
- 底层数据结构:分段连续的动态数组 + 中控数组(“块链表” 结构)。
- 核心设计:用一个 “中控数组”(指针数组)管理多个 “固定大小的连续内存块”(每个块存储实际元素);
- 头部 / 尾部插入时,若当前块已满,直接分配新块并更新中控数组,无需移动现有元素;
- 迭代器设计:需同时记录 “当前块指针” 和 “块内偏移”,因此迭代器比
vector复杂。
- 核心特性:
- 头部 / 尾部插入 / 删除效率高:O(1)(无需扩容时);
- 随机访问效率较高:O(1)(通过中控数组定位块,再通过偏移定位元素,比
vector多一次指针跳转); - 中间插入 / 删除效率低:O(n)(需移动块内或跨块的元素);
- 无扩容拷贝问题:元素分散在多个块中,新增块无需移动旧元素,迭代器仅在 “跨块操作” 时可能失效(比
vector稳定)。
- 适用场景:需要频繁在头部和尾部增删,且偶尔随机访问的场景(如实现队列、滑动窗口)。
3. list(双向链表)
- 底层数据结构:双向循环链表(每个节点包含 “前驱指针”“后继指针” 和 “元素值”)。
- 节点不连续存储,通过指针串联;链表尾部节点的 “后继指针” 指向头部节点,形成循环(便于首尾操作)。
- 核心特性:
- 任意位置插入 / 删除效率高:只需修改指针指向,时间复杂度 O(1)(前提是已通过迭代器定位到目标位置);
- 无随机访问能力:无法通过索引访问,需从头 / 尾遍历,时间复杂度 O(n);
- 内存开销大:每个元素额外存储 2 个指针(前驱 + 后继),且节点分散导致缓存命中率低;
- 迭代器稳定性强:插入 / 删除操作仅影响目标节点的前后指针,其他迭代器不会失效(除非指向被删除的节点)。
- 适用场景:频繁在任意位置插入 / 删除,且无需随机访问的场景(如实现链表、邻接表)。
4. forward_list(单向链表)
- 底层数据结构:单向链表(每个节点仅包含 “后继指针” 和 “元素值”,非循环)。
- 比
list更精简,仅支持从头部向后遍历。
- 比
- 核心特性:
- 头部插入 / 删除效率高:O(1);中间 / 尾部插入需先遍历到目标位置,效率 O(n);
- 内存开销比
list小:每个节点仅 1 个指针; - 不支持反向遍历(无
rbegin()/rend()),也不支持size()(需遍历计数,O (n)); - 迭代器仅支持单向移动(
++操作,无--)。
- 适用场景:内存受限、仅需单向遍历且频繁头部操作的场景(如实现简单的栈、单向依赖列表)。
5. array(固定大小数组)
- 底层数据结构:静态连续数组(与 C 语言的原生数组
int arr[5]本质一致,但封装了 STL 容器接口)。- 大小在编译时确定(模板参数指定,如
array<int, 10>),不支持动态扩容 / 缩容。
- 大小在编译时确定(模板参数指定,如
- 核心特性:
- 随机访问效率极高:O(1),与原生数组性能一致;
- 无内存 overhead:不额外存储容量、指针等信息(比
vector更轻量); - 大小固定:无法动态添加 / 删除元素(
push_back()等操作不存在); - 迭代器稳定:内存地址固定,迭代器永不失效(除非数组本身被销毁)。
- 适用场景:需要固定大小、高性能随机访问,且避免动态内存分配的场景(如嵌入式开发、底层数据存储)。
二、关联式容器(Associative Containers)
关联式容器的核心是 “按键(key) 组织元素”,分为 “有序” 和 “无序” 两类:有序容器基于平衡树实现(按键排序),无序容器基于哈希表实现(按哈希值存储)。
(一)有序关联式容器(基于平衡二叉搜索树)
所有有序关联式容器的底层均为红黑树(一种自平衡二叉搜索树,保证树的高度为 O (log n),避免极端情况下退化为链表)。红黑树的特性:
- 节点按键的比较规则(默认
less<Key>,即升序)有序排列; - 插入 / 删除 / 查找操作的时间复杂度均为 O(log n);
- 支持通过迭代器遍历有序元素(中序遍历红黑树即可得到升序序列)。
1. set(有序集合)
- 核心特性:
- 存储 “键 = 值” 的元素(键即元素本身),不允许重复键;
- 元素按键有序排列(默认升序),无索引,只能通过迭代器或
find(key)访问; - 插入重复元素会被忽略(
insert()返回pair<iterator, bool>,bool表示是否插入成功)。
- 适用场景:需要有序存储唯一元素,且频繁按键查找、遍历的场景(如去重 + 排序、统计唯一值)。
2. multiset(有序多重集合)
- 核心特性:
- 与
set一致,但允许重复键(多个元素可拥有相同的键); - 插入操作总是成功(返回指向新元素的迭代器);
- 查找时返回第一个匹配键的元素(可通过
equal_range(key)获取所有相同键的元素范围)。
- 与
- 适用场景:需要有序存储且允许重复元素的场景(如按分数排序的学生列表、统计重复值的频次)。
3. map(有序键值对)
- 核心特性:
- 存储 “键值对(key-value)”,键唯一,按键有序排列;
- 通过
key快速查找对应的value(map[key]或find(key)); - 键不可修改(修改键会破坏有序性),但值可修改(通过迭代器或
operator[])。
- 适用场景:需要通过唯一键关联数据,且需按键有序访问的场景(如字典、用户信息查询)。
4. multimap(有序多重键值对)
- 核心特性:
- 与
map一致,但允许重复键(多个键值对可拥有相同的键); - 无
operator[](无法确定返回哪个value),需通过find()或equal_range()获取值; - 键不可修改,值可修改。
- 与
- 适用场景:需要通过重复键关联多个数据的场景(如按部门分组的员工列表、多对一映射)。
(二)无序关联式容器(基于哈希表)
C++11 引入的无序关联式容器,底层均为哈希表(Hash Table) + 链表 / 红黑树(解决哈希冲突),核心是 “通过键的哈希值快速定位元素”。
哈希表的核心设计:
- 哈希函数:将键(key)映射为 “哈希值”,再通过 “取模” 得到哈希表的 “桶(bucket)索引”;
- 哈希冲突解决:STL 中默认用 “链地址法”(每个桶对应一个链表 / 红黑树,冲突的元素存入同一个桶的链表 / 树中);
- 负载因子:当 “元素数量 / 桶数量” 超过阈值(默认 0.75)时,触发 “重哈希(rehash)”—— 分配更多桶,重新计算所有元素的桶索引,保证查找效率。
1. unordered_set(无序集合)
- 核心特性:
- 存储 “键 = 值” 的唯一元素,无顺序(元素顺序由哈希值决定,不固定);
- 插入 / 删除 / 查找效率极高:平均 O(1),最坏 O(n)(哈希冲突严重时,桶的链表退化为线性结构);
- 不支持按顺序遍历(迭代器遍历顺序无意义),不支持
lower_bound()/upper_bound()(有序容器特有的范围查询)。
- 适用场景:需要快速去重、高频查找,且不关心元素顺序的场景(如缓存判断、快速去重)。
2. unordered_multiset(无序多重集合)
- 核心特性:
- 与
unordered_set一致,但允许重复键; - 插入效率平均 O (1),查找相同键的元素需遍历桶内的链表 / 树(平均 O (k),k 为相同键的元素数)。
- 与
- 适用场景:需要快速存储重复元素,且不关心顺序的场景(如统计元素频次、快速批量查找)。
3. unordered_map(无序键值对)
- 核心特性:
- 存储 “键值对”,键唯一,无顺序;
- 通过键查找值的效率极高:平均 O (1),最坏 O (n);
- 支持
operator[](不存在的键会自动插入默认构造的value,需注意误插入问题)。
- 适用场景:需要高频键值对查询,且不关心键顺序的场景(如缓存、哈希表、快速数据映射)。
4. unordered_multimap(无序多重键值对)
- 核心特性:
- 与
unordered_map一致,但允许重复键; - 无
operator[](无法确定返回哪个value),需通过find()或equal_range()获取值。
- 与
- 适用场景:需要高频多键值映射,且不关心顺序的场景(如多关键词索引、批量键值查询)。
三、适配器容器(Container Adapters)
适配器容器不直接存储元素,而是基于其他容器(底层容器)封装接口,改变其行为或限制访问方式(如仅允许栈的 “先进后出”)。
1. stack(栈)
- 底层容器:默认
deque,也可指定vector或list(需支持push_back()/pop_back()/back())。 - 核心特性:
- 遵循 “先进后出(LIFO)” 原则,仅允许访问栈顶元素;
- 支持
push()(栈顶插入)、pop()(栈顶删除)、top()(访问栈顶),时间复杂度由底层容器决定(默认 O (1)); - 无迭代器,不支持随机访问或遍历。
- 适用场景:需要 LIFO 逻辑的场景(如函数调用栈、表达式求值、回溯算法)。
2. queue(队列)
- 底层容器:默认
deque,也可指定list(需支持push_back()/pop_front()/front()/back())。 - 核心特性:
- 遵循 “先进先出(FIFO)” 原则,仅允许访问队首(出队)和队尾(入队)元素;
- 支持
push()(队尾插入)、pop()(队首删除)、front()(访问队首)、back()(访问队尾),时间复杂度默认 O (1); - 无迭代器,不支持随机访问或遍历。
- 适用场景:需要 FIFO 逻辑的场景(如任务队列、消息队列、广度优先搜索(BFS))。
3. priority_queue(优先队列)
- 底层容器:默认
vector,也可指定deque(需支持随机访问,因为底层要构建 “堆”)。 - 核心特性:
- 基于 “二叉堆(默认大根堆)” 实现,每次
pop()都返回 “优先级最高” 的元素; - 核心操作:
push()(插入元素并调整堆,O (log n))、pop()(删除堆顶并调整堆,O (log n))、top()(访问堆顶,O (1)); - 优先级可通过自定义比较函数修改(如
priority_queue<int, vector<int>, greater<int>>实现小根堆)。
- 基于 “二叉堆(默认大根堆)” 实现,每次
- 适用场景:需要按优先级处理元素的场景(如任务调度、霍夫曼编码、迪杰斯特拉算法)。
四. 总结
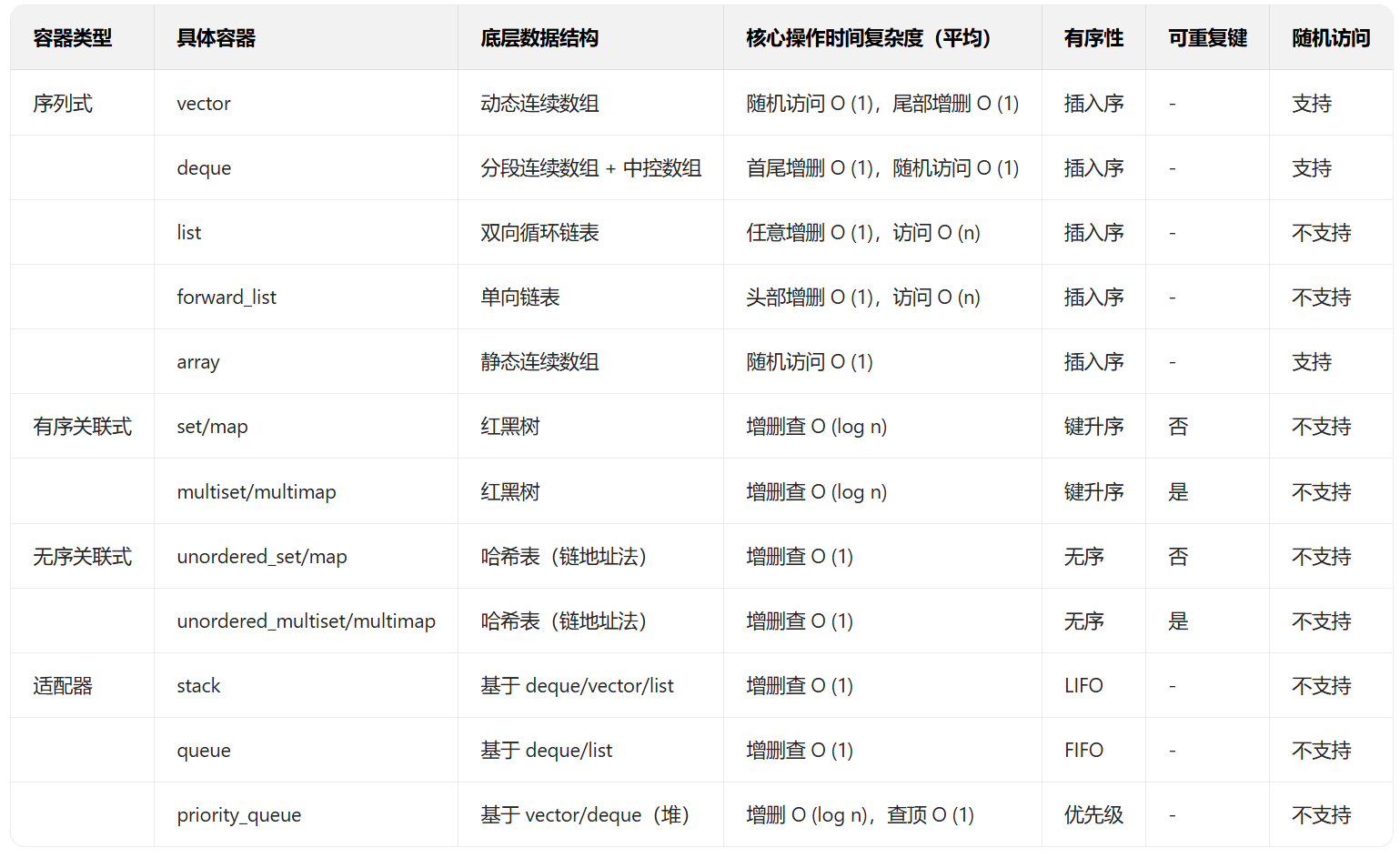
心得:学习过程特别要注意哪些容器有哪些方法没有,像关联式容器自己实现了find和count方法,可以自己调用,其他容易可以通过调用algorithm库中的API来实现;同时只有序列式的容器才能调用push类的方法插入,其他的没有,当然通用的是insert。
----- 以上为本人学习STL总结出的一些知识点,有错误或者疑问可以评论区交流,欢迎指正!!!