深度学习周报(8.25~8.31)
目录
摘要
Abstract
1 RNN学习意义
2 RNN基础知识
2.1 核心思想
2.2 传播
2.3 优缺点
2.4 变体结构与应用场景
3 RNN结构代码示例
4 总结
摘要
本周主要学习了循环神经网络的学习意义与基础知识,重点了解了RNN循环连接的核心思想、前向传播与反向传播过程,认识了其优缺点与应用场景,对它的变体结构也进行了拓展,最后还通过代码加深了对循环神经网络结构以及使用的了解。
Abstract
This week, I primarily studied the significance and fundamental concepts of Recurrent Neural Networks (RNNs). I focused on understanding the core idea of recurrent connections, the processes of forward and backward propagation, and learned about the advantages, disadvantages, and application scenarios of RNNs. I also explored its variant architectures and deepened my understanding of the structure and usage of RNNs through coding.
1 RNN学习意义
循环神经网络(Recurrent Neural Network, RNN) 是一类专门用于处理序列数据、解决序列式问题的神经网络。它的核心特点是具备“记忆”能力,能够捕捉序列中元素之间的时序依赖关系。
序列数据就是指按时间或其他顺序排列的一组数据点,其中每个数据点不仅自身有意义,其位置和先后关系可能也蕴含着信息,故而它的关键特征包括有序性、可变长度、时序依赖(当前状态可能依赖于之前多个时刻的状态)以及动态性(序列通常是动态生成的,如实时语音流、传感器数据流)。常见的序列数据类型包括文本、语音信号、时间序列、用户行为日志、视频帧和DNA序列等。
序列式问题就是指那些输入、输出或两者都是序列的任务,模型需要理解或生成具有顺序结构的数据,这种问题的核心通常是对序列中的依赖关系进行建模。序列式问题可能包括一个输入对应多个输出(图像描述生成)、一个输出对应多个输入(情感分析)、非实时的多个输入对应多个输出(词性标注)以及实时的多个输入对应多个输出(实时翻译)。
这揭示RNN与普通神经网络的主要区别以及学习RNN的原因及意义。一方面,普通的神经网络只能处理固定长度的数据,而对变长数据无能为力;另一方面,普通的神经网络基本上是对给定的某个输入输出某个特定的值(一对一),例如图像分类或者图像检测。而RNN就能够很好地弥补这些不足。
下图从左至右分别为普通神经网络(一个输入对应一个输出),一个输入对应多个输出,一个输出对应多个输入,非实时的多个输入对应多个输出,实时的多个输入对应多个输出。
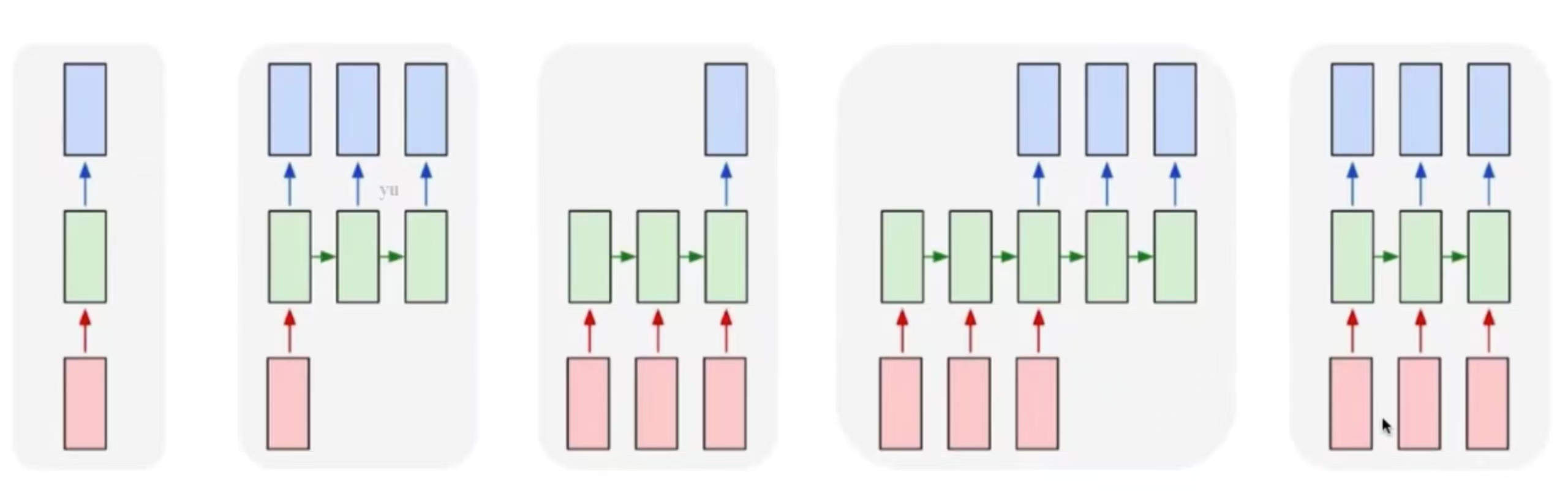
2 RNN基础知识
2.1 核心思想
与传统的前馈神经网络不同,RNN 引入了循环连接(Recurrent Connection),使得网络在处理当前输入时,可以利用之前时刻的信息。
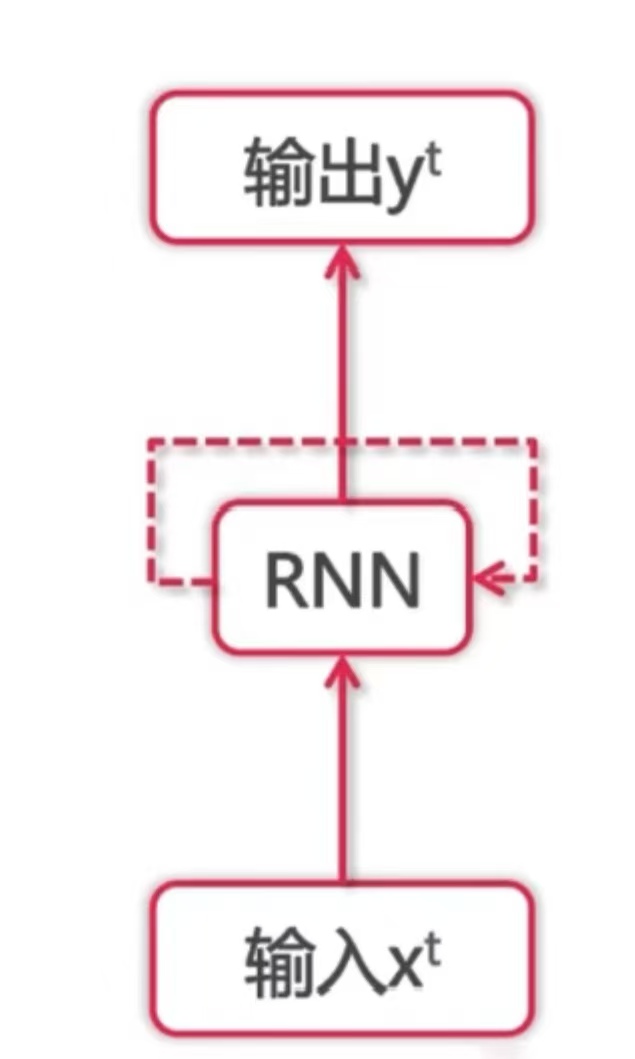
它维护一个状态作为下一步的额外输入,比如,输入一个 经过RNN的网络结构得到
,这个
一方面经过某种变化成为最终输出的
,一方面又和下一步输入的
一起经过RNN的网络结构得到
,并以此类推 。这个状态也被称为隐藏状态(Hidden State)。
它在不同时间步上使用同样的激活函数与参数。其公式为:
其中 是当前时间步的隐藏状态,
是上一个时间步的隐藏状态,
是当前时间步的输入,
是二者最终得到
所经过的变换。
对 进行展开,公式可能如下:
其中 tanh 为选用的激活函数,W 为前一步隐藏状态到当前隐藏状态的权重,U 为当前输入到当前隐藏状态的权重。
当前输出的概率分布可能为:
2.2 传播
由上,循环神经网络对于一个序列的的前向传播过程--以字符语言模型(给定上下文以预测下一字符,例如输入法)为例--可能如下所示:
(词典为 ,样本为 jeep)
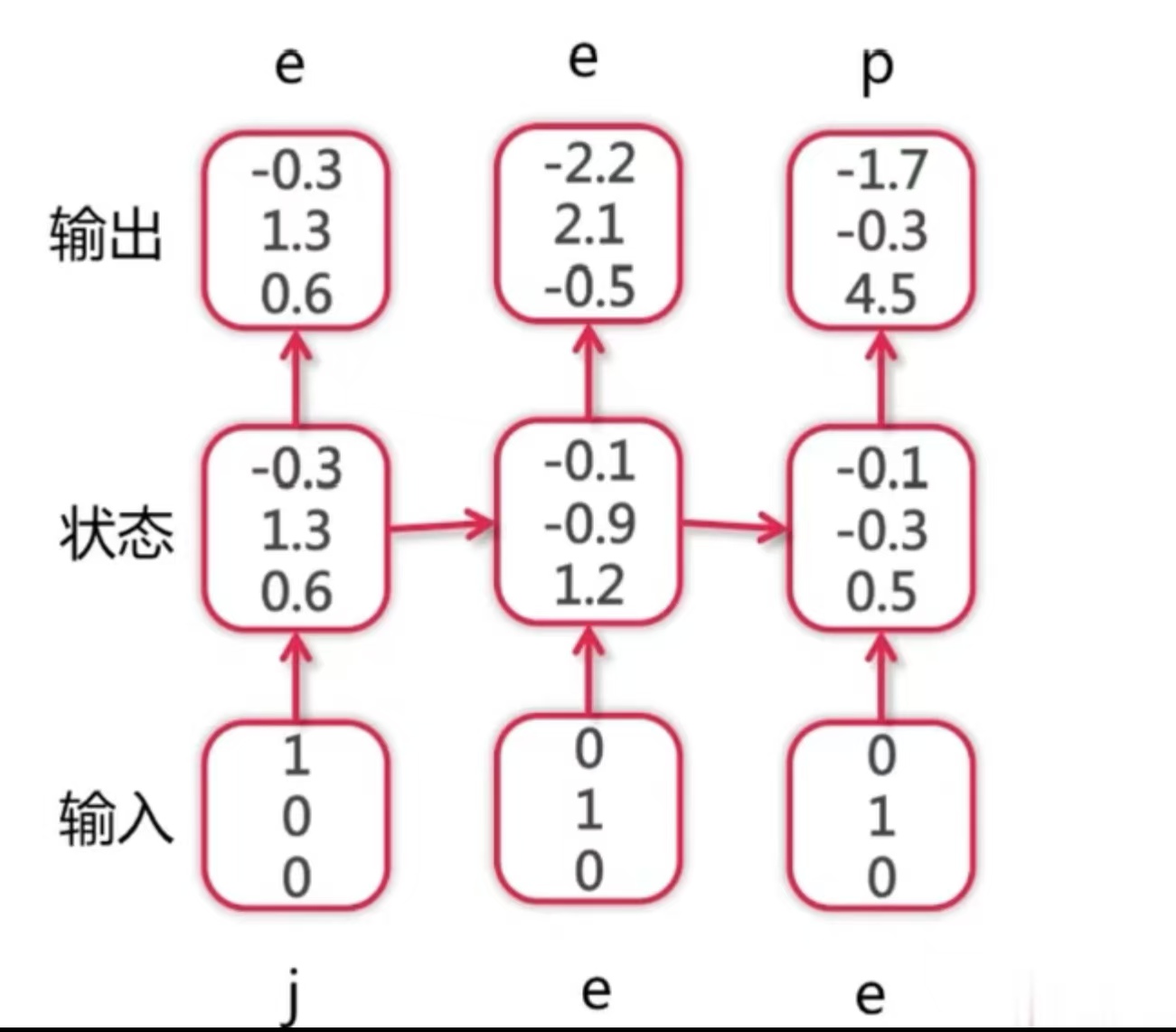
由于,RNN 在时间上有依赖关系,其反向传播被称为随时间反向传播(Backpropagation Through Time, BPTT),具体而言就是将 RNN 在时间上展开成一个深层网络,然后像普通神经网络一样进行反向传播。损失函数通常是各时间步损失之和:
其中 T 代表序列长度,t 代表当前时间索引, 代表目标值,
代表当前时间的预测输出。
反向传播需要计算损失 对所有参数的梯度,并统一更新参数。由于参数在所有时间步共享,总梯度是各时间步梯度之和。
1. 输出层权重 V:
2. 循环权重 W:
对于单个时间步的损失值,它关于循环权重 W 的梯度计算就相当于先计算损失对于预测输出的梯度,再计算预测输出对于当前隐藏状态的梯度,最后计算当前隐藏状态对于上一步隐藏状态的梯度:
其循环性体现在最后一步,因为当前隐藏状态对于上一步隐藏状态是一个递归过程(可见上一小节),故上式可以进一步展开得到:
进行简化得到:
3. 输入权重 U:
在测试时,由于只知道最初的输入,所以需要用到上一步的输出来作为下一步的输入。如果中间某一步有预测错误的情况发生,很可能此后的预测都会出现错误。不过如果数据量足够大,模型训练得好,理论上也可能训练出兼容性,即使中间某一步发生了错误,后面依然能预测准确。
2.3 优缺点
RNN 的优点包括可以接受不同长度的输入序列;能够捕捉时序依赖,即通过隐藏状态建模序列中的前后关系;参数共享,同一组参数用于所有时间步,可以适当减少模型复杂度。
RNN 的缺点主要是两方面。一方面,由于在训练长序列时,反向传播过程中梯度可能变得极小或极大,出现梯度消失与梯度爆炸问题,导致模型难以学习长期依赖。这也是标准 RNN 最大的局限。相应的解决办法包括使用其他的激活函数、忽略较远的步骤以及分批次进行梯度计算(靠后的步骤对于第一步的梯度计算贡献可能有限)。另一方面,由于每个时间步依赖前一个状态,无法像 CNN 那样高效并行计算,训练速度较慢,难以并行化。
2.4 变体结构与应用场景
为了解决标准 RNN 的问题,研究者提出了多种改进结构:
首先就是长短期记忆网络(Long Short-Term Memory,LSTM)。它引入了门控机制(遗忘门、输入门、输出门)和细胞状态(Cell State),能有效缓解梯度消失问题,适合处理长序列,广泛应用于机器翻译、语音识别等任务,是使用最广泛的RNN变体网络结构。
然后是门控循环单元(Gated Recurrent Unit,GRU)。它相当于LSTM的简化版本,只有两个门(更新门、重置门),参数更少,训练更快,表达能力相对LSTM稍弱,但在许多任务中性能与其相当。
其次是双向 RNN(Bi-RNN),它包含前向和后向两个 RNN 层,同时利用过去和未来两个状态拼接输出,模型表达能力得到了提升,但实时性变差,常用于命名实体识别、语音识别等需要双向信息的任务。
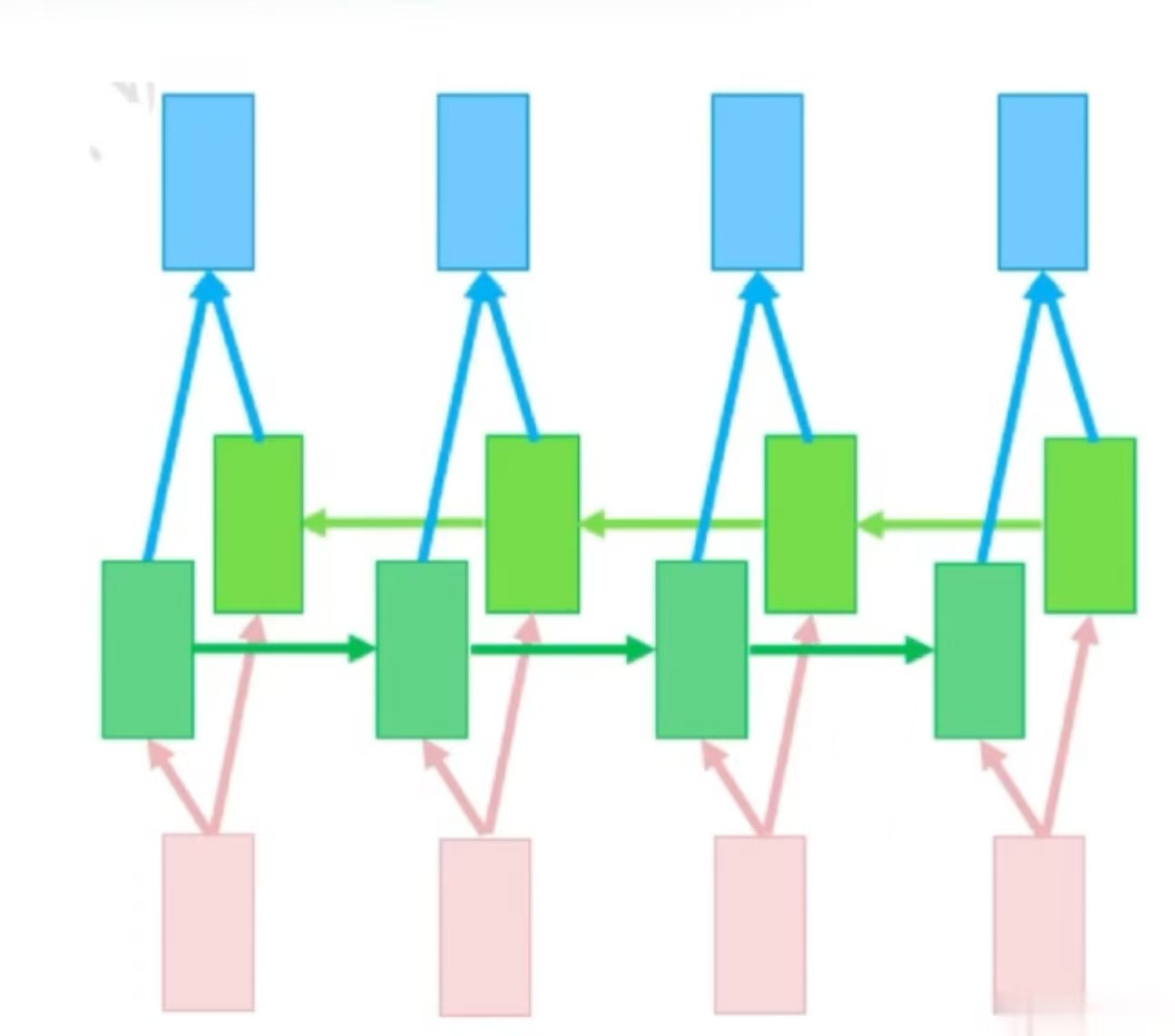
最后是多层网络,也称深度RNN。它在垂直方向上堆叠多个 RNN 层,每一层的输出作为下一层的输入,同层之间依旧递归,形成一个深层循环结构,这增加了网络的拟合能力。
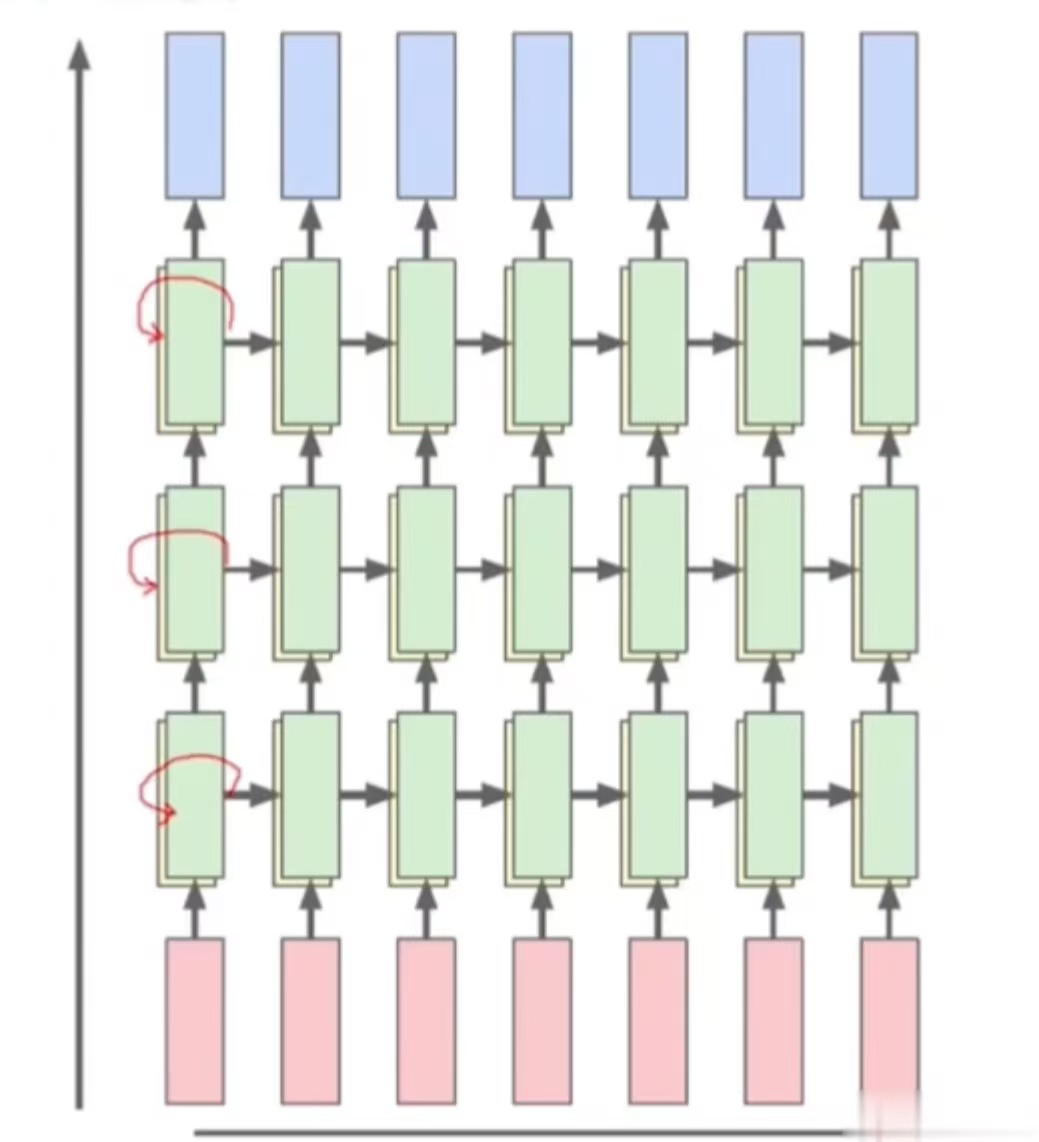
RNN 的应用场景包括自然语言处理(语言建模、机器翻译、情感分析、文本生成)、语音处理(语音识别(Speech-to-Text)、语音合成(Text-to-Speech))、时间序列预测(股票价格预测、天气预报、用户行为预测)以及视频分析(动作识别、视频字幕生成)等等。
3 RNN结构代码示例
class SimpleRNN(nn.Module):# input_size代表每个输入向量的维度, hidden_size代表隐藏状态的维度,## num_layers代表RNN层数(大于1,则代表是深层RNN), output_size代表输出维度def __init__(self, input_size=1, hidden_size=50, num_layers=1, output_size=1):super(SimpleRNN, self).__init__()self.hidden_size = hidden_sizeself.num_layers = num_layers# 定义 RNN 层self.rnn = nn.RNN(input_size=input_size,hidden_size=hidden_size,num_layers=num_layers,# 输入形状: (batch, seq, feature)# batch代表一次处理的独立序列数量, seq代表序列长度(每条序列时间步数量), feature代表每个时间步输入的向量维度batch_first=True,nonlinearity='tanh')# 输出层,将最后一个时间步的隐藏状态映射到输出self.fc = nn.Linear(hidden_size, output_size)def forward(self, x):# 输入形状 (batch_size, seq_len, input_size),可与上面对应batch_size = x.size(0)# 初始化隐藏状态为零向量h0 = torch.zeros(self.num_layers, batch_size, self.hidden_size).to(x.device)# 前向传播,隐式执行循环out, hn = self.rnn(x, h0) # 取最后一个时间步的输出out = self.fc(out[:, -1, :]) return out若同一批次的序列长度不同,可以先将所有序列填充到一个长度,并对序列原始长度进行记录,然后再使用 pack_padded_sequence和 pad_packed_sequence工具忽略掉填充部分,避免它们影响隐藏状态。
4 总结
本周主要了解了RNN的相关知识,包括学习意义、传播过程以及变体等,并通过代码加深了对RNN网络的理解。下周计划深入学习LSTM(长短期记忆网络)的相关知识。