雪花算法生成分布式ID
参考
https://zhuanlan.zhihu.com/p/687957959
分布式唯一 ID 生成算法笔记 | 羽殇之舞的个人博客
雪花算法
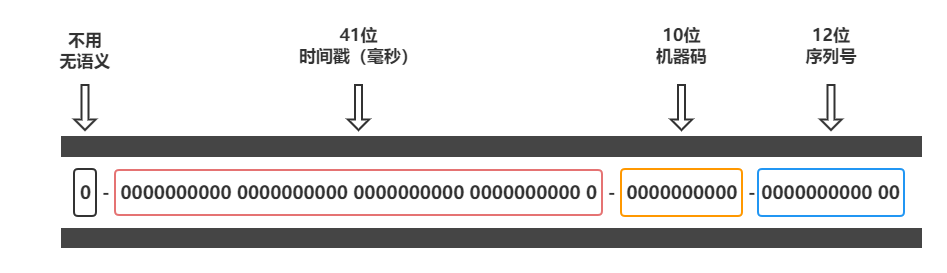
64Bit,强依赖时间戳,所以整体趋势会随着时间递增。
- 1bit 不用:因为二进制中最高位是符号位,1 表示负数,0 表示正数,生成的 id 一般都是用整数,所以最高位固定为 0
- 41bit 时间戳:这里采用的就是当前系统的具体时间,单位为毫秒
- 10bit 工作机器 ID(workerId):每台机器分配一个 id,这样可以标示不同的机器,但是上限为 1024(2^10次方),标示一个集群某个业务最多部署的机器个数上限
- 12bit 序列号(自增域):表示在某一毫秒下,这个自增域最大可以分配的 bit 个数,在当前这种配置下,每个节点每毫秒可以分配 2^12 = 4096 个不同的ID,当达到最大值时会从0重新开始。
时间回拨
当出现虚拟机、容器时间矫正或手动调整时间、硬件故障时会出现时间回拨,即系统时间被调整到一个比之前时间更早的时刻。
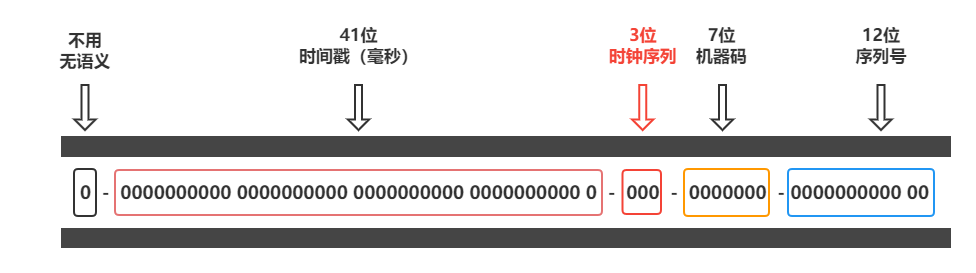
将原本 10 位的机器码拆分成 3 位时钟序列及 7 位机器码。发生时间回拨的时候,时间已经发生了变化,那么这时将时钟序列新增 1 位,重新定义整个雪花 Id。为了避免实例重启引起时间序列丢失,因此时钟序列最好通过 DB 存储起来。
这当然会导致分布式实例规模由 210(1024)2^{10}(1024)210(1024) 降至 27(128)2^7(128)27(128),同时每个分布式实例支持最多 23(8)2^3(8)23(8) 次时间回拨。