基于CotSegNet网络和机器学习的棉花点云器官分割和表型信息提取
一、引言
PointNet++作为点云处理领域的先驱与里程碑式深度学习模型,以其卓越的性能和对无序点云数据直接处理的能力而闻名。博主将分享1篇发表在《Computers and Electronics in Agriculture》(中科院1区TOP)的“Organ segmentation and phenotypic information extraction of cotton point clouds based on the CotSegNet network and machine learning”,说明PointNet++模型在植物器官分割和表现信息提取的应用。主要改进点如下:
(1)CotSegNet网络:提出了一种新的点云语义分割网络CotSegNet。具体来说,设计了一种改进的注意力机制,称为cgluconformer,以增强模型有效捕获关键信息的能力。此外,在CotSegNet中加入了SegNext注意机制,以改进特征表示并抑制不相关信息;
(2)改进的区域增长算法:本文提出了一种改进的区域增长算法,解决了相邻叶子之间的粘连和共平面导致的过度分割问题。这是通过引入距离限制来实现的。
论文原文:https://doi.org/10.1016/j.compag.2025.110466
欢迎大家交流、引用和分享,博文如需转载请注明来源。
二、研究背景
棉花作为全球最重要的经济作物之一,在农业经济和工业生产中占据核心地位。其纤维是纺织行业的主要原料,广泛应用于服装、家居用品及工业领域。此外,棉籽油和棉籽粕也是重要的食品与饲料来源。在作物生长过程中,植物表型发挥着关键作用。植物表型是指植物在生长发育过程中呈现的一套物理、生理及生化特征,这些特征由基因型与环境因素的动态相互作用所塑造,直观反映了植物的生长状况。
传统上,植物表型参数的提取依赖人工测量方法。尽管这些方法精度较高,但存在明显缺陷:效率低下、劳动强度大且可扩展性有限。更重要的是,它们可能对被测植物造成不可逆的损伤。例如,测量茎高时,使用卷尺或直尺等手动方式可能因操作不当导致茎秆弯曲或断裂;测量叶面积时,叶面积仪通常需要摘除叶片,这不仅会降低植物的光合能力,还可能显著影响幼苗生长;而测量叶片形态参数(如叶长、叶宽)时,使用游标卡尺或图像分析工具的手动操作可能损伤叶缘或叶脉。
因此,开发自动化、非损毁的植物表型参数测定技术势在必行。此类技术的进步将提高植物表型测量的效率,实现对植物生长与健康状况的有效监测,并最终推动植物育种实践的改进。
三、数据集
本研究使用知象光电生产的Revopoint Mini型精密蓝光三维扫描仪采集高分辨率点云数据。
部分数据集:https://pan.baidu.com/s/16pOAGeUHDH1ICuDVqrggYw.

图1 棉花原始点云数据

图2 棉花点云数据标注
四、模型改进
本文提出的CotSegNet模型采用编码器-解码器架构,用于点云语义分割任务,其结构如图5所示。该模型基于传统的PointNet++架构构建,并作为棉花苗期器官语义分割的基线模型。然而,PointNet++在处理高度弯曲表面的局部邻域信息时存在效率不足的问题。鉴于棉花具有复杂的几何特征,局部信息往往更为关键。为解决这一问题,CotSegNet在特征提取阶段整合了CGLUConvFormer和SegNext注意力机制,增强了邻域信息交互能力,并改进了原PointNet++结构。
本文设计了一种新型注意力机制——CGLUConvFormer。该模块融合了卷积门控线性单元(Convolutional Gated Linear Unit)、归一化层和逆分离卷积。其核心模块卷积门控线性单元通过门控机制动态调整特征图,不仅提升了模型捕捉关键信息的能力,还能有效减少噪声,显著增强模型的鲁棒性。在语义分割任务中,卷积门控线性单元擅长同时捕捉图像的局部和全局特征,并通过门控机制选择性传输这些特征,从而更精准地识别图像中的语义信息。通过结合深度卷积与逐点卷积,该模块在有效提取和重构特征的同时,减少了参数数量并提升了模型效率。其中,深度卷积用于提取空间特征,逐点卷积则将这些特征融合为更具表现力的特征图。此外,逆分离卷积不仅降低了计算复杂度,还提升了特征提取过程的效率。
SegNext注意力机制通过动态调整模型对输入数据不同区域的关注焦点,显著增强了关键特征的表示能力,同时抑制了无关信息。该机制通过计算每个特征位置的重要性权重,并对这些特征进行加权求和,生成更具代表性的特征表示。进一步地,SegNext整合了全局与局部注意力机制,有效捕捉图像中的上下文信息。全局注意力机制在整个图像范围内寻找相关信息,而局部注意力机制则聚焦于当前位置周围的特定区域。这种结合使模型能够更深入地理解复杂场景与对象之间的关系。在语义分割任务中,处理不同尺度的对象对提升性能至关重要。SegNext注意力机制通过动态调整不同尺度特征的权重,实现了多尺度特征的有效融合,使模型能够同时捕捉图像的细节信息与整体结构信息,从而提高了分割的准确率和鲁棒性。
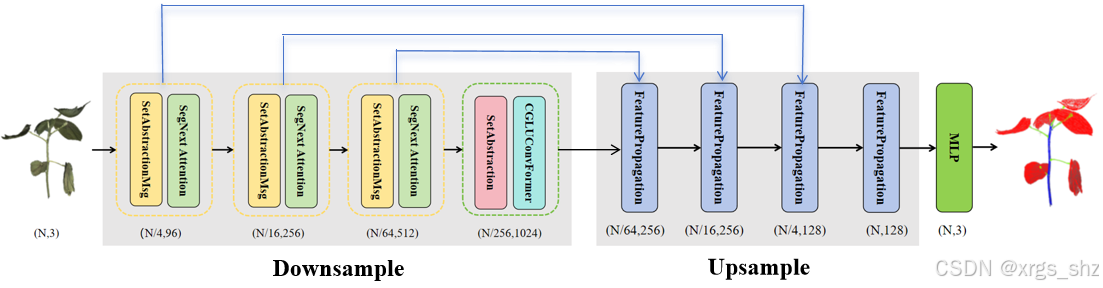
图3 CotSegNet网络架构
(一)CGLUConvFormer注意机制
本研究提出了一个更通用的框架——MetaFormer。该模型由两个核心模块构成:Token Mixer(令牌混合器),用于整合空间位置信息;以及Channel MLP(通道多层感知机),用于融合通道信息。根据Token Mixer的具体实现方式不同,MetaFormer可以演变为多种不同类型的模型。
为提升点云特征提取能力,本文设计了一种创新的点云处理注意力机制——CGLUConvFormer。该机制采用倒置分离卷积(Inverted Separable Convolution)作为Token Mixer模块,通过一系列卷积操作有效提取点云的空间特征。同时,它以卷积门控线性单元(Convolutional Gated Linear Unit)作为Channel MLP模块,通过动态调整特征图的重要性实现通道信息的精准融合。
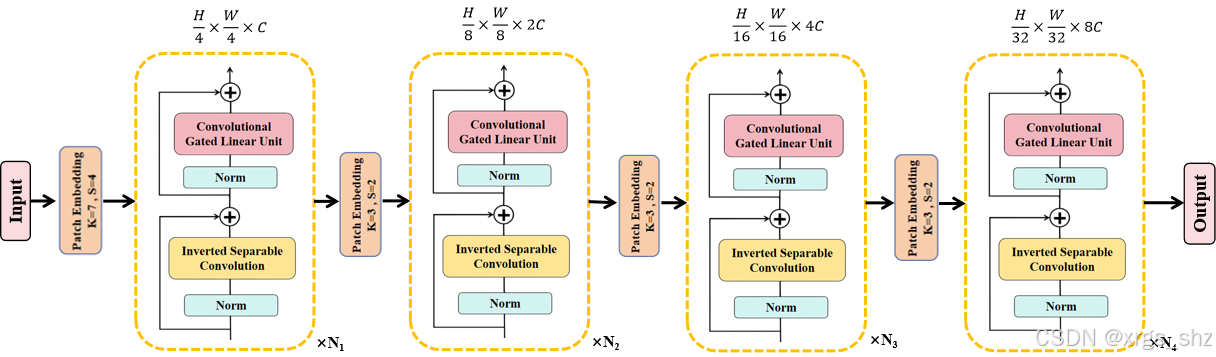
图4 CGLUConvFormer注意机制结构
CGLUConvFormer.py
from functools import partial
import torch
import torch.nn as nn
import torch.nn.functional as Ffrom timm.layers import DropPath, to_2tuple__all__ = ['MF_Attention', 'RandomMixing', 'SepConv', 'Pooling', 'MetaFormerBlock', 'MetaFormerCGLUBlock', 'LayerNormGeneral']class Scale(nn.Module):"""Scale vector by element multiplications."""def __init__(self, dim, init_value=1.0, trainable=True):super().__init__()self.scale = nn.Parameter(init_value * torch.ones(dim), requires_grad=trainable)def forward(self, x):return x * self.scaleclass SquaredReLU(nn.Module):"""Squared ReLU: https://arxiv.org/abs/2109.08668"""def __init__(self, inplace=False):super().__init__()self.relu = nn.ReLU(inplace=inplace)def forward(self, x):return torch.square(self.relu(x))class StarReLU(nn.Module):"""StarReLU: s * relu(x) ** 2 + b"""def __init__(self, scale_value=1.0, bias_value=0.0,scale_learnable=True, bias_learnable=True, mode=None, inplace=False):super().__init__()self.inplace = inplaceself.relu = nn.ReLU(inplace=inplace)self.scale = nn.Parameter(scale_value * torch.ones(1),requires_grad=scale_learnable)self.bias = nn.Parameter(bias_value * torch.ones(1),requires_grad=bias_learnable)def forward(self, x):return self.scale * self.relu(x)**2 + self.biasclass MF_Attention(nn.Module):"""Vanilla self-attention from Transformer: https://arxiv.org/abs/1706.03762.Modified from timm."""def __init__(self, dim, head_dim=32, num_heads=None, qkv_bias=False,attn_drop=0., proj_drop=0., proj_bias=False, **kwargs):super().__init__()self.head_dim = head_dimself.scale = head_dim ** -0.5self.num_heads = num_heads if num_heads else dim // head_dimif self.num_heads == 0:self.num_heads = 1self.attention_dim = self.num_heads * self.head_dimself.qkv = nn.Linear(dim, self.attention_dim * 3, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop)self.proj = nn.Linear(self.attention_dim, dim, bias=proj_bias)self.proj_drop = nn.Dropout(proj_drop)def forward(self, x):B, H, W, C = x.shapeN = H * Wqkv = self.qkv(x).reshape(B, N, 3, self.num_heads, self.head_dim).permute(2, 0, 3, 1, 4)q, k, v = qkv.unbind(0) # make torchscript happy (cannot use tensor as tuple)attn = (q @ k.transpose(-2, -1)) * self.scaleattn = attn.softmax(dim=-1)attn = self.attn_drop(attn)x = (attn @ v).transpose(1, 2).reshape(B, H, W, self.attention_dim)x = self.proj(x)x = self.proj_drop(x)return xclass RandomMixing(nn.Module):def __init__(self, num_tokens=196, **kwargs):super().__init__()self.random_matrix = nn.parameter.Parameter(data=torch.softmax(torch.rand(num_tokens, num_tokens), dim=-1), requires_grad=False)def forward(self, x):B, H, W, C = x.shapex = x.reshape(B, H*W, C)x = torch.einsum('mn, bnc -> bmc', self.random_matrix, x)x = x.reshape(B, H, W, C)return xclass LayerNormGeneral(nn.Module):r""" General LayerNorm for different situations.Args:affine_shape (int, list or tuple): The shape of affine weight and bias.Usually the affine_shape=C, but in some implementation, like torch.nn.LayerNorm,the affine_shape is the same as normalized_dim by default. To adapt to different situations, we offer this argument here.normalized_dim (tuple or list): Which dims to compute mean and variance. scale (bool): Flag indicates whether to use scale or not.bias (bool): Flag indicates whether to use scale or not.We give several examples to show how to specify the arguments.LayerNorm (https://arxiv.org/abs/1607.06450):For input shape of (B, *, C) like (B, N, C) or (B, H, W, C),affine_shape=C, normalized_dim=(-1, ), scale=True, bias=True;For input shape of (B, C, H, W),affine_shape=(C, 1, 1), normalized_dim=(1, ), scale=True, bias=True.Modified LayerNorm (https://arxiv.org/abs/2111.11418)that is idental to partial(torch.nn.GroupNorm, num_groups=1):For input shape of (B, N, C),affine_shape=C, normalized_dim=(1, 2), scale=True, bias=True;For input shape of (B, H, W, C),affine_shape=C, normalized_dim=(1, 2, 3), scale=True, bias=True;For input shape of (B, C, H, W),affine_shape=(C, 1, 1), normalized_dim=(1, 2, 3), scale=True, bias=True.For the several metaformer baslines,IdentityFormer, RandFormer and PoolFormerV2 utilize Modified LayerNorm without bias (bias=False);ConvFormer and CAFormer utilizes LayerNorm without bias (bias=False)."""def __init__(self, affine_shape=None, normalized_dim=(-1, ), scale=True, bias=True, eps=1e-5):super().__init__()self.normalized_dim = normalized_dimself.use_scale = scaleself.use_bias = biasself.weight = nn.Parameter(torch.ones(affine_shape)) if scale else Noneself.bias = nn.Parameter(torch.zeros(affine_shape)) if bias else Noneself.eps = epsdef forward(self, x):c = x - x.mean(self.normalized_dim, keepdim=True)s = c.pow(2).mean(self.normalized_dim, keepdim=True)x = c / torch.sqrt(s + self.eps)if self.use_scale:x = x * self.weightif self.use_bias:x = x + self.biasreturn xclass LayerNormWithoutBias(nn.Module):"""Equal to partial(LayerNormGeneral, bias=False) but faster, because it directly utilizes otpimized F.layer_norm"""def __init__(self, normalized_shape, eps=1e-5, **kwargs):super().__init__()self.eps = epsself.bias = Noneif isinstance(normalized_shape, int):normalized_shape = (normalized_shape,)self.weight = nn.Parameter(torch.ones(normalized_shape))self.normalized_shape = normalized_shapedef forward(self, x):return F.layer_norm(x, self.normalized_shape, weight=self.weight, bias=self.bias, eps=self.eps)class SepConv(nn.Module):r"""Inverted separable convolution from MobileNetV2: https://arxiv.org/abs/1801.04381."""def __init__(self, dim, expansion_ratio=2,act1_layer=StarReLU, act2_layer=nn.Identity, bias=False, kernel_size=7, padding=3,**kwargs, ):super().__init__()med_channels = int(expansion_ratio * dim)self.pwconv1 = nn.Linear(dim, med_channels, bias=bias)self.act1 = act1_layer()self.dwconv = nn.Conv2d(med_channels, med_channels, kernel_size=kernel_size,padding=padding, groups=med_channels, bias=bias) # depthwise convself.act2 = act2_layer()self.pwconv2 = nn.Linear(med_channels, dim, bias=bias)def forward(self, x):x = self.pwconv1(x)x = self.act1(x)x = x.permute(0, 3, 1, 2)x = self.dwconv(x)x = x.permute(0, 2, 3, 1)x = self.act2(x)x = self.pwconv2(x)return xclass Pooling(nn.Module):"""Implementation of pooling for PoolFormer: https://arxiv.org/abs/2111.11418Modfiled for [B, H, W, C] input"""def __init__(self, pool_size=3, **kwargs):super().__init__()self.pool = nn.AvgPool2d(pool_size, stride=1, padding=pool_size//2, count_include_pad=False)def forward(self, x):y = x.permute(0, 3, 1, 2)y = self.pool(y)y = y.permute(0, 2, 3, 1)return y - xclass Mlp(nn.Module):""" MLP as used in MetaFormer models, eg Transformer, MLP-Mixer, PoolFormer, MetaFormer baslines and related networks.Mostly copied from timm."""def __init__(self, dim, mlp_ratio=4, out_features=None, act_layer=StarReLU, drop=0., bias=False, **kwargs):super().__init__()in_features = dimout_features = out_features or in_featureshidden_features = int(mlp_ratio * in_features)drop_probs = to_2tuple(drop)self.fc1 = nn.Linear(in_features, hidden_features, bias=bias)self.act = act_layer()self.drop1 = nn.Dropout(drop_probs[0])self.fc2 = nn.Linear(hidden_features, out_features, bias=bias)self.drop2 = nn.Dropout(drop_probs[1])def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.drop1(x)x = self.fc2(x)x = self.drop2(x)return xclass ConvolutionalGLU(nn.Module):def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.) -> None:super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featureshidden_features = int(2 * hidden_features / 3)self.fc1 = nn.Conv2d(in_features, hidden_features * 2, 1)self.dwconv = nn.Sequential(nn.Conv2d(hidden_features, hidden_features, kernel_size=3, stride=1, padding=1, bias=True, groups=hidden_features),act_layer())self.fc2 = nn.Conv2d(hidden_features, out_features, 1)self.drop = nn.Dropout(drop)# def forward(self, x):# x, v = self.fc1(x).chunk(2, dim=1)# x = self.dwconv(x) * v# x = self.drop(x)# x = self.fc2(x)# x = self.drop(x)# return xdef forward(self, x):x_shortcut = xx, v = self.fc1(x).chunk(2, dim=1)x = self.dwconv(x) * vx = self.drop(x)x = self.fc2(x)x = self.drop(x)return x_shortcut + xclass MetaFormerBlock(nn.Module):"""Implementation of one MetaFormer block."""def __init__(self, dim,token_mixer=nn.Identity, mlp=Mlp,norm_layer=partial(LayerNormWithoutBias, eps=1e-6),drop=0., drop_path=0.,layer_scale_init_value=None, res_scale_init_value=None):super().__init__()self.norm1 = norm_layer(dim)self.token_mixer = token_mixer(dim=dim, drop=drop)self.drop_path1 = DropPath(drop_path) if drop_path > 0. else nn.Identity()self.layer_scale1 = Scale(dim=dim, init_value=layer_scale_init_value) \if layer_scale_init_value else nn.Identity()self.res_scale1 = Scale(dim=dim, init_value=res_scale_init_value) \if res_scale_init_value else nn.Identity()self.norm2 = norm_layer(dim)self.mlp = mlp(dim=dim, drop=drop)self.drop_path2 = DropPath(drop_path) if drop_path > 0. else nn.Identity()self.layer_scale2 = Scale(dim=dim, init_value=layer_scale_init_value) \if layer_scale_init_value else nn.Identity()self.res_scale2 = Scale(dim=dim, init_value=res_scale_init_value) \if res_scale_init_value else nn.Identity()def forward(self, x):x = x.permute(0, 2, 3, 1)x = self.res_scale1(x) + \self.layer_scale1(self.drop_path1(self.token_mixer(self.norm1(x))))x = self.res_scale2(x) + \self.layer_scale2(self.drop_path2(self.mlp(self.norm2(x))))return x.permute(0, 3, 1, 2)class MetaFormerCGLUBlock(nn.Module):"""Implementation of one MetaFormer block."""def __init__(self, dim,token_mixer=nn.Identity, mlp=ConvolutionalGLU,norm_layer=partial(LayerNormWithoutBias, eps=1e-6),drop=0., drop_path=0.,layer_scale_init_value=None, res_scale_init_value=None):super().__init__()self.norm1 = norm_layer(dim)self.token_mixer = token_mixer(dim=dim, drop=drop)self.drop_path1 = DropPath(drop_path) if drop_path > 0. else nn.Identity()self.layer_scale1 = Scale(dim=dim, init_value=layer_scale_init_value) \if layer_scale_init_value else nn.Identity()self.res_scale1 = Scale(dim=dim, init_value=res_scale_init_value) \if res_scale_init_value else nn.Identity()self.norm2 = norm_layer(dim)self.mlp = mlp(dim, drop=drop)self.drop_path2 = DropPath(drop_path) if drop_path > 0. else nn.Identity()self.layer_scale2 = Scale(dim=dim, init_value=layer_scale_init_value) \if layer_scale_init_value else nn.Identity()self.res_scale2 = Scale(dim=dim, init_value=res_scale_init_value) \if res_scale_init_value else nn.Identity()def forward(self, x):x = x.permute(0, 2, 3, 1)x = self.res_scale1(x) + \self.layer_scale1(self.drop_path1(self.token_mixer(self.norm1(x))))x = self.res_scale2(x.permute(0, 3, 1, 2)) + \self.layer_scale2(self.drop_path2(self.mlp(self.norm2(x).permute(0, 3, 1, 2))))return x(二)SegNext_Attention注意力机制
本文引用的SegNext注意力机制能够更精准地识别棉花点云的边界和细节特征。该机制通过增强模型对点云数据内部特征的表征能力,有效提升了点云处理的精度。该机制基于编码器-解码器框架构建:编码器部分引入了多尺度卷积注意力模块(MSCA),专注于挖掘点云数据中的深层特征以提升特征提取效率;解码器部分则采用轻量化的Hamburger模块,进一步整合全局上下文信息,并将特征转化为精确的分割结果。
SegNext注意力机制的核心在于其显著增强空间注意力的能力。MSCA模块由三个关键组件构成:深度卷积层用于聚合局部特征信息,多分支深度条带卷积层专门捕捉不同尺度的上下文信息,以及1×1卷积层用于建模通道间相关性。通过这种精心设计,MSCA模块在几乎不增加参数量的前提下,显著提升了模型捕获和利用多尺度特征的能力。
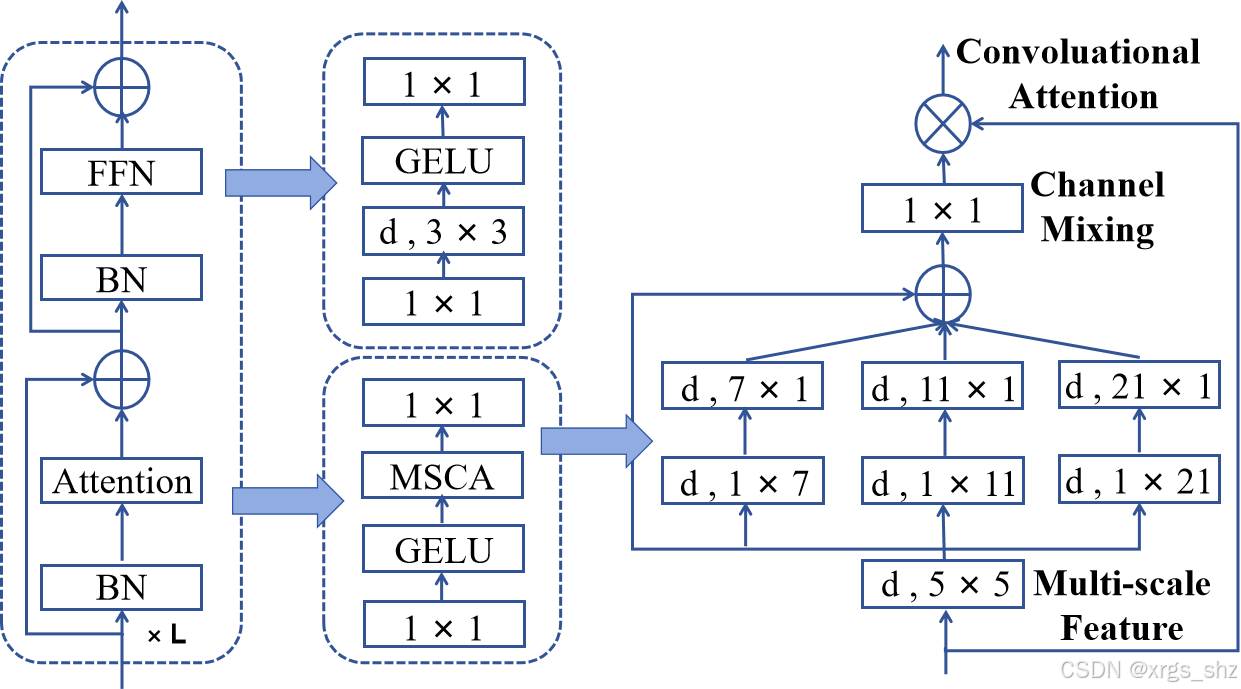
图5 SegNext_Attention注意机制结构
SegNext_Attention.py
import torch
from torch import nn, Tensor, LongTensor
from torch.nn import init
import torch.nn.functional as F
import torchvisionclass SegNext_Attention(nn.Module):# SegNext NeurIPS 2022# https://github.com/Visual-Attention-Network/SegNeXt/tree/maindef __init__(self, dim):super().__init__()self.conv0 = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)self.conv0_1 = nn.Conv2d(dim, dim, (1, 7), padding=(0, 3), groups=dim)self.conv0_2 = nn.Conv2d(dim, dim, (7, 1), padding=(3, 0), groups=dim)self.conv1_1 = nn.Conv2d(dim, dim, (1, 11), padding=(0, 5), groups=dim)self.conv1_2 = nn.Conv2d(dim, dim, (11, 1), padding=(5, 0), groups=dim)self.conv2_1 = nn.Conv2d(dim, dim, (1, 21), padding=(0, 10), groups=dim)self.conv2_2 = nn.Conv2d(dim, dim, (21, 1), padding=(10, 0), groups=dim)self.conv3 = nn.Conv2d(dim, dim, 1)def forward(self, x):u = x.clone()attn = self.conv0(x)attn_0 = self.conv0_1(attn)attn_0 = self.conv0_2(attn_0)attn_1 = self.conv1_1(attn)attn_1 = self.conv1_2(attn_1)attn_2 = self.conv2_1(attn)attn_2 = self.conv2_2(attn_2)attn = attn + attn_0 + attn_1 + attn_2attn = self.conv3(attn)return attn * u(三)改进的区域生长算法
本文提出了一种改进的区域生长算法,专为将不同叶片的点云分割为独立实例而设计。通过引入距离约束,该算法有效解决了相邻叶片因粘连和平面特性导致的过分割问题。
改进区域生长算法的核心原理是:从种子点出发,逐步扩展区域,纳入满足几何约束(基于法向量角度、曲率及距离阈值)的邻近点,从而实现粘连叶片结构的精准分割。
具体流程如下:首先对输入点云进行预处理,包括法向量计算和KD树构建以加速邻域搜索。随后计算每个点的局部邻域协方差矩阵,并通过奇异值分解(SVD)获取曲率值。选择曲率最低的点作为初始种子点,因其通常位于叶片平面区域,可有效减少生成的分段数量。通过引入法向量角度阈值,算法增强了对叶片几何与拓扑特征的适应性,确保叶片的准确识别与分离。算法通过判断相邻点法向量的角度和曲率是否满足预设阈值,来决定是否将邻近点归入当前区域。若角度和曲率条件均满足,则选择最近邻点作为新种子点,并继续迭代;若仅满足法向量角度阈值,则将该点分类但不设为新种子。
然而,当叶片轴两侧的叶片相互粘连时,传统区域生长方法难以有效分割。虽然增大法向量角度阈值可部分缓解此问题,但也可能导致不同位置点簇因法向量角度相似而出现过分割。为此,算法在传统区域生长方法中引入距离约束。改进后的算法对粘连且共面的叶片点云部分施加距离约束,动态调整平面距离以精准分离共面但空间上独立的粘连叶片,显著提升分割精度,并实现更精确的边界点云提取。
五、结论
本文提出了一种基于点云语义分割框架的CotSegNet网络,用于精准提取棉花茎、叶等关键表型特征。通过综合模块设计与消融实验,CotSegNet被应用于本研究构建的棉花点云数据集,在器官分割任务中展现出卓越的性能和高效的推理速度。CotSegNet的核心在于提出的CGLUConvFormer注意力机制和引入的SegNext注意力机制。其中,CGLUConvFormer利用倒置深度可分离卷积高效捕捉棉花器官的局部几何特征(如叶片边缘、茎秆走向),并结合卷积门控线性单元动态筛选通道特征,显著提升了对苗期棉花顶部新叶等小器官的敏感性,实现了茎、叶、叶柄等器官的精准分割。SegNext注意力机制则通过空间-通道双路径注意力进一步增强模型的全局上下文感知能力:在空间路径中,采用空洞卷积金字塔捕捉多尺度上下文信息,确保模型能理解器官间的空间关系;在通道路径中,通过可学习的通道权重动态调整特征图,抑制背景噪声干扰的同时强化关键区域(如茎叶连接处)的特征表达。