大模型应用总结
写在前面
好久没更新博客了,不知不觉,已经工作2年了,,,,
今天主要对 大模型应用架构进行总结,后续会补充
1、大模型应用架构
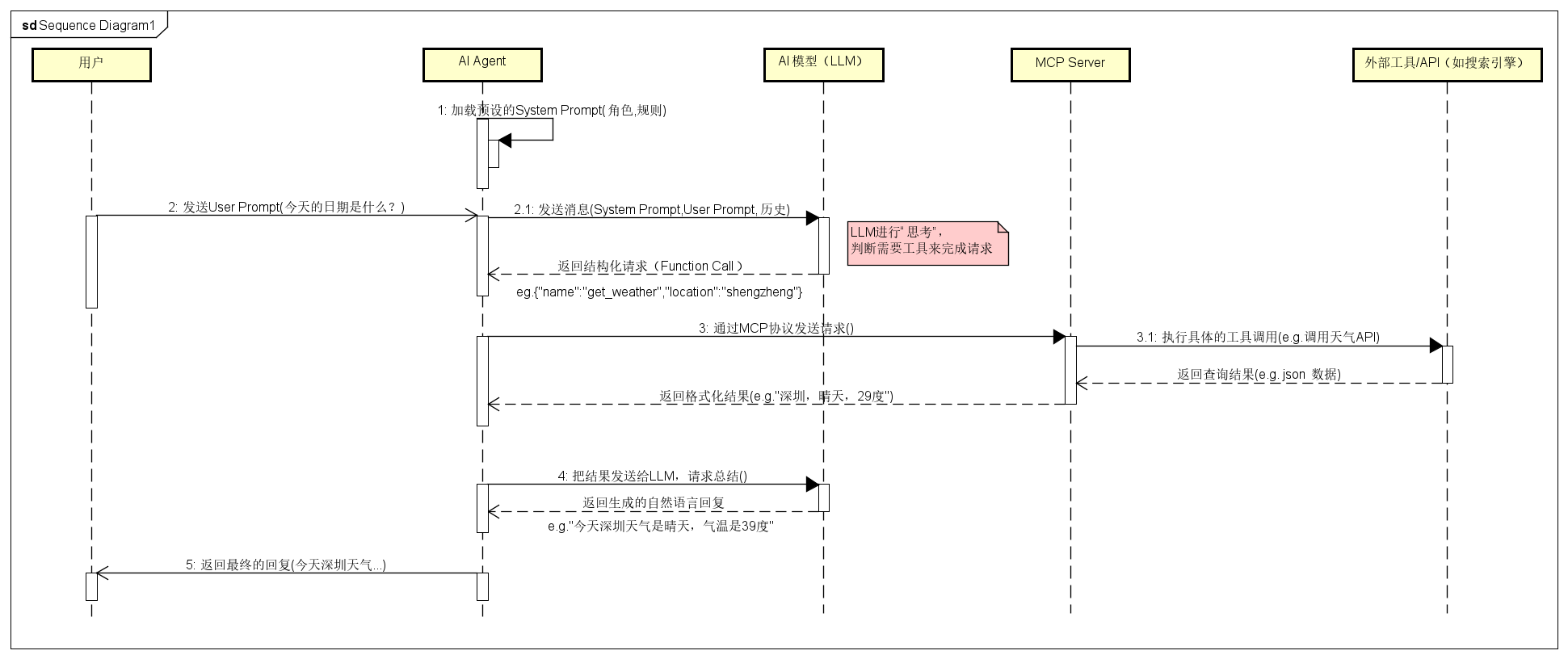
- User Prompt:用户自己写的提示,用于引导大模型进行回答;
- System Prompt:避免用户写提示(AI的角色身份),提前预设的提示
- AI Agent:负责在用户、模型、大模型之间对话的代理者
- Function Calling:AI Agent和大模型之间沟通的协议,目的是统一格式,规范描述;可以用于校验大模型返回的格式是否正确,同时避免用户的自然语言描述不够标准化
- MCP Server:负责在Agent和Tool之间的通信,MCP是规定的协议
2、如何理解RAG?
2.1、一句话概括
RAG(检索增强生成)是一种将**信息检索(IR)系统与大语言模型(LLM)**相结合的技术,它让LLM在生成答案之前,先从外部知识库检索相关信息,从而生成更准确、更可靠、且能回溯的答案,有效解决了LLM的“幻觉”问题。
2.2、为什么需要RAG?LLM的局限性
1、信息的滞后性:LLM的知识来自训练数据,训练截止日期之后的事件、新闻、研究进展,模型并不知道。重新训练一个LLM成本极高。
2、产生幻觉:当被问到一些训练数据中不存在或者不明确的信息时,LLM可能会“编造”一个听起来合理但实际上是错误的答案。
3、无法溯源:LLM提供的答案像一个“黑箱”,我们很难知道这个答案是基于哪些信息源得到的,缺乏透明度和可信度。
4、处理内部/私有数据困难:LLM无法访问公司内部的文档、数据库、个人笔记等非公开信息。
2.3、RAG的工作流程
RAG的工作流程可以清晰地分为两个阶段:检索(Retrieval)和增强生成(Augmented Generation)。
阶段一:检索(Retrieval)

阶段二:增强生成(Augmented Generation)
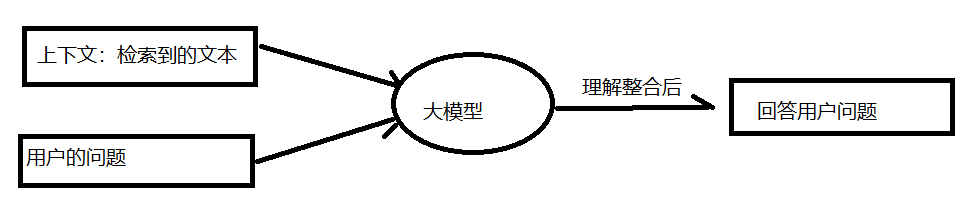
1、增强提示(Augmented Prompt):将检索到的最相关的文本块(作为上下文)和用户的原始问题一起组合成一个新的、增强版的提示(Prompt),发送给LLM。
2、生成答案:LLM根据这个提供了确切证据(上下文)的增强提示来生成答案。由于答案所需的材料已经提供,LLM更像是一个“信息整合与表述者”,而不是一个“凭记忆答题者”。
注:传统的LLM相当于闭卷考试,RAG相当于开卷考试。RAG吗,面临的问题包括:考生是否可以快速准备找到参考书上资料的位置(检索质量),找到后如何能够重新整合组织正确的答案(生成质量)。