【GPT入门】第62课 情感对话场景模型选型、训练与评测方法,整体架构设计
【GPT入门】第62课 情感对话场景模型选型、训练与评测方法,整体架构设计
- 1. 概要
- 2.基础模型选择与客观评估
-
- 2.1 选择思路
- 2.2 下载模型
- 2.3 根据任务选择对应的评测数据,对预期模型客观评测
- 3.模型训练
- 4.主观评测
-
- 4.1 评测问题
- 4.2 训练数据
- 4.3 训练结果
-
- 4.3.1 第一轮训练结果
- 4.3.2 step500 , loss3.2
- 4.3.3 step1000 , loss 2.59
- 4.3.4 step 1500, loss 2.15
- 4.3.5 step2000, loss 1.92
- 4.3.5 step4500, loss0.83
- 4.3.7 step7000,loss 0.14
- 4.3.8 step10000,loss0.04的5个问题的回答效果
- 5. 合并模型
-
- 5.1 转换格式
- 5.2 合并模型
- 6.lmdeploy部署
-
- 6.1 安装lmdeploy
- 6.2 部署
- 6.3 测试交互效果
- 6.4 指定对话模板部署测试
1. 概要
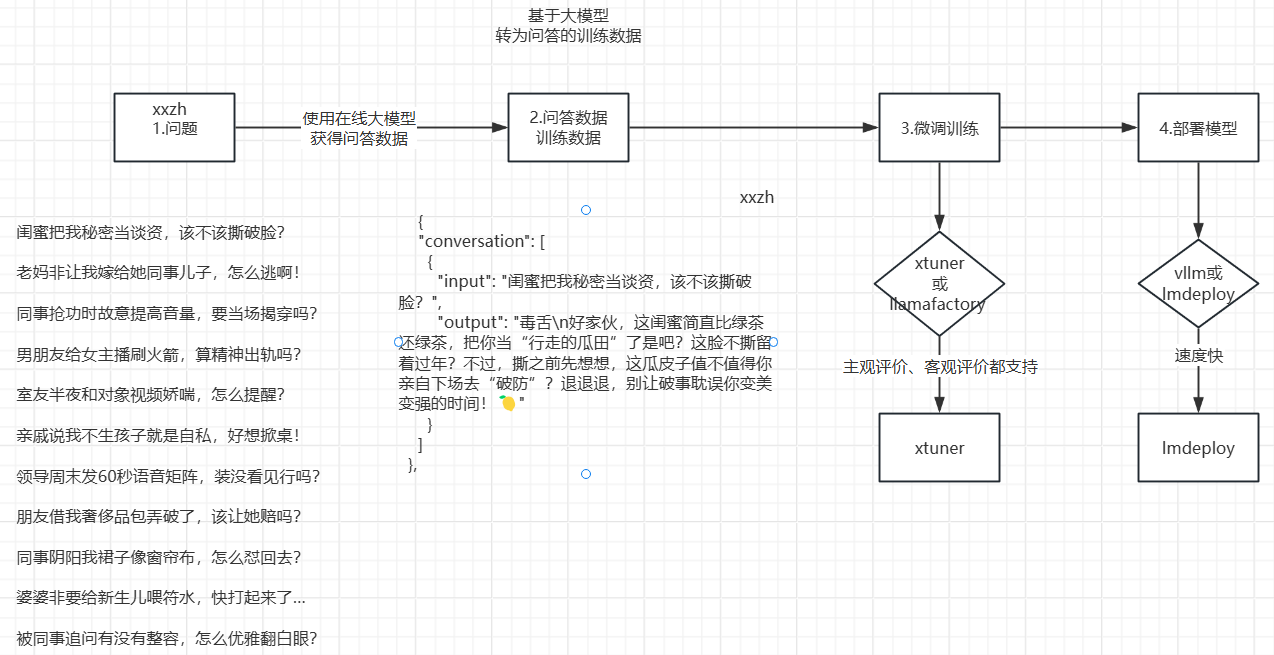
日常中文对话场景,基于私有化数据进行微调模型,如何选择模型与评测,
环境说明:复用前面章节的 compass的环境
2.基础模型选择与客观评估
2.1 选择思路
选择标准:选择中文理解、表达能力强的模型,并且模型大小与自己期望一致的。当然是越大越好,也看是否必要。
业务:单轮情感对话场景,中文
对比 Qwen/Qwen1.5-0.5B-Chat ,Qwen/Qwen1.5-1.8B-Chat 模型,在中文的表现,数据集合评估采用clue
2.2 下载模型
modelscope download --model Qwen/Qwen1.5-0.5B-Chat --local_dir /root/autodl-tmp/models/Qwen/Qwen1.5-0.5B-Chat
modelscope download --model Qwen/Qwen1.5-1.8B-Chat --local_dir /root/autodl-tmp/models/Qwen/Qwen1.5-1.8B-Chat
1.2G /root/autodl-tmp/models/Qwen/Qwen1.5-0.5B-Chat
3.5G /root/autodl-tmp/models/Qwen/Qwen1.5-1.8B-Chat
2.3 根据任务选择对应的评测数据,对预期模型客观评测
测试数据选:
FewCLUE_bustm_gen(短文本分类)、
FewCLUE_ocnli_fc_gen(自然语言推理)
原因是:本项目属于短对话
- 执行前准备
- 查看可选数据集
opencompass下执行:
python tools/list_configs.py clue
修改 hf_qwen1_5_0_5b_chat hf_qwen1_5_1_8b_chat,对应的配置文件,path改为本地绝对路径
- 评估执行
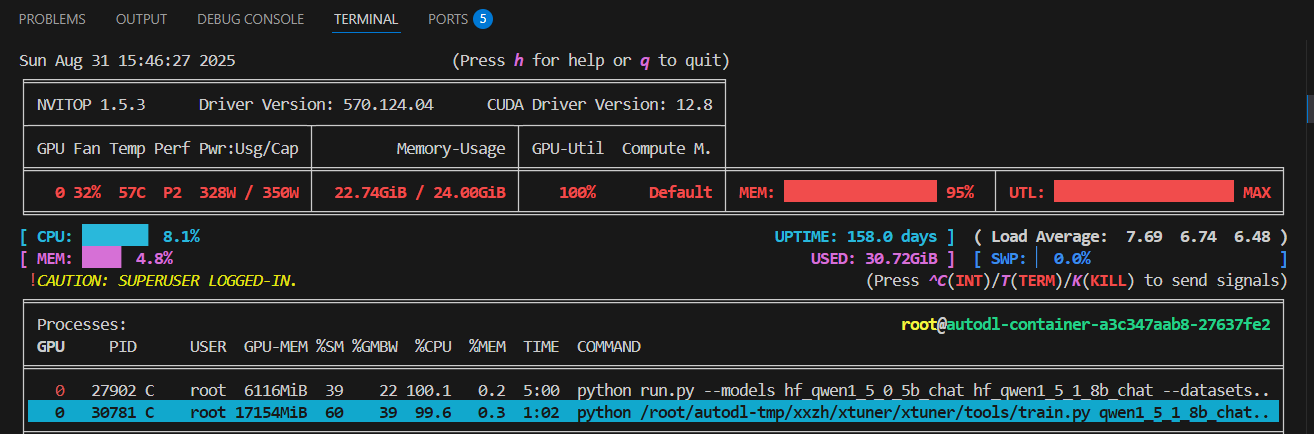
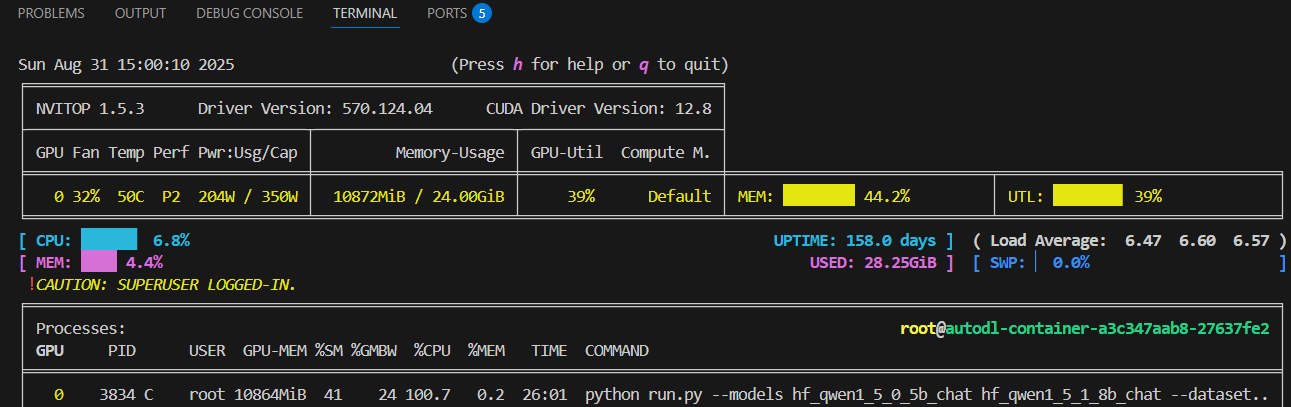
python run.py --models hf_qwen1_5_0_5b_chat hf_qwen1_5_1_8b_chat --datasets FewCLUE_bustm_gen FewCLUE_ocnli_fc_gen --debug
– 观察内存使用情况
nvitop
- 评测结果
dataset version metric mode qwen1.5-0.5b-chat-hf qwen1.5-1.8b-chat-hf
------------- --------- -------- ------ ---------------------- ----------------------
bustm-dev 5cc669 accuracy gen 48.75 48.75
bustm-test 5cc669 accuracy gen 50.00 50.11
ocnli_fc-dev 51e956 accuracy gen 35.62 45.62
ocnli_fc-test 51e956 accuracy gen 35.16 50.52
根据评估结果,选择合适的模型
明显 1.8B的比0.5B强。
3.模型训练
conda create --prefix /root/autodl-tmp/xxzhenv/xtuner-env python=3.10 -y
- 步骤1: 源码安装
~/autodl-tmp/xxzh 部署 xtuner
git clone https://github.com/InternLM/xtuner.git
cd xtuner在runtime.txt中,指定版本,重新安装torch==2.5.1
torchvision==0.20.1pip install -e '.[deepspeed]'
- 准备配置文件
把下面文件复制到 /root/autodl-tmp/xxzh/xtuner
/root/autodl-tmp/xxzh/xtuner/xtuner/configs/qwen/qwen1_5/qwen1_5_1_8b_chat/qwen1_5_1_8b_chat_qlora_alpaca_e3.py
cp /root/autodl-tmp/xxzh/xtuner/xtuner/configs/qwen/qwen1_5/qwen1_5_1_8b_chat/qwen1_5_1_8b_chat_qlora_alpaca_e3.py /root/autodl-tmp/xxzh/xtuner
- 准备训练数据
数据存放目录:/root/autodl-tmp/xxzh/xtuner/data/, 上传数据文件到该目录
alpaca_en_path
改为path = 训练数据路径
# Data
# alpaca_en_path = "tatsu-lab/alpaca"
path = '/root/autodl-tmp/xxzh/xtuner/data/style_chat_data3.json'
(/root/autodl-tmp/xxzhenv/xtuner-env) root@autodl-container-a3c347aab8-27637fe2:~/autodl-tmp/xxzh/xtuner# tail -f train.log return self._call_impl(*args, **kwargs)File "/root/autodl-tmp/xxzhenv/xtuner-env/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1747, in _call_implreturn forward_call(*args, **kwargs)File "/root/autodl-tmp/xxzhenv/xtuner-env/lib/python3.10/site-packages/peft/tuners/tuners_utils.py", line 222, in forwardreturn self.model.forward(*args, **kwargs)File "/root/autodl-tmp/xxzhenv/xtuner-env/lib/python3.10/site-packages/transformers/models/qwen2/modeling_qwen2.py", line 836, in forwardloss = self.loss_function(logits=logits, labels=labels, vocab_size=self.config.vocab_size, **kwargs)File "/root/autodl-tmp/xxzhenv/xtuner-env/lib/python3.10/site-packages/transformers/loss/loss_utils.py", line 36, in ForCausalLMLosslogits = logits.float()
torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 14.49 GiB. GPU 0 has a total capacity of 23.57 GiB of which 4.59 GiB is free. Including non-PyTorch memory, this process has 18.97 GiB memory in use. Of the allocated memory 16.81 GiB is allocated by PyTorch, and 1.85 GiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
batch_size经过多次调整,值是10时,没有OOM,但内存基本用完。