【嵌入式】【调用函数图】手动绘制函数调用状态机
文章目录
- 模块设计
- 转化流程
- 文件格式说明
- 功能示例
- 输入配置
- 输出图示
- 代码部署
- JSON文件操作模式
- CSV文件操作模块
- 函数调用状态绘制
- 主函数调用入口
模块设计
转化流程
- 在CSV文件中标明函数调用流程
- 将CSV文件转化为JSON标识文件
- 将JSON文件转化为函数STATE
- 将函数STATE绘制成PLANTUML
- 将PLANTUML图转为markdown文件
文件格式说明
见下文示例。
功能示例
输入配置
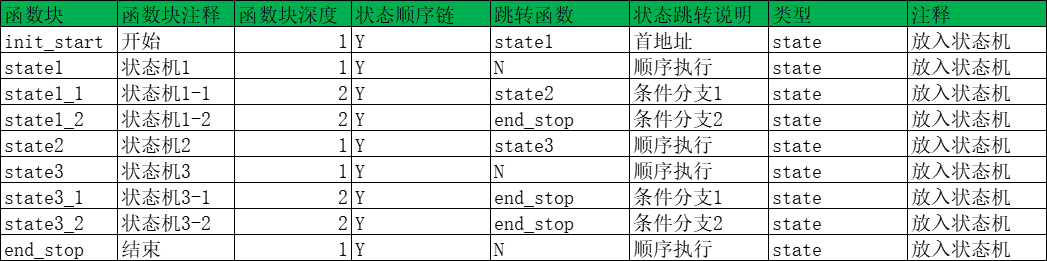
输出图示
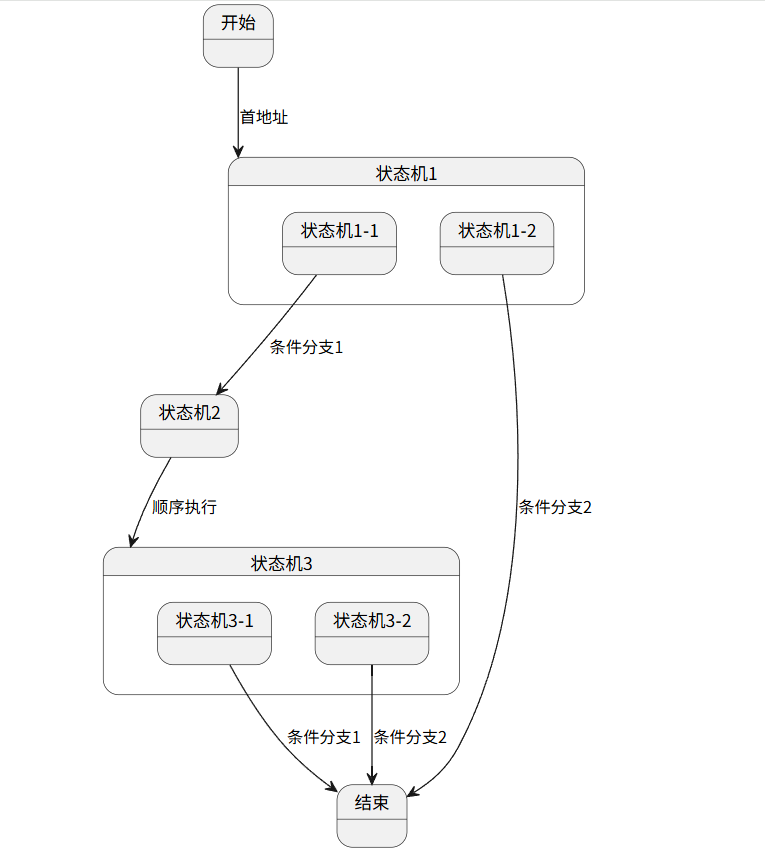
代码部署
JSON文件操作模式
import os
import sys
import jsondef load_json(filepath, filename):# 打开并读取 JSON 文件filetotal = os.path.join(filepath, filename)with open(filetotal, 'r', encoding='utf-8') as jsonfile: # 指定编码避免乱码data = json.load(jsonfile) # 解析为 Python 对象(字典/列表)jsonfile.close()return datadef save_json(data, filepath, filename):filetotal = os.path.join(filepath, filename)with open(filetotal, 'w+', encoding='utf-8') as jsonfile: # 指定编码避免乱码json.dump(data, jsonfile, indent=4, ensure_ascii=False) # 格式化+支持中文[1,4,7](@ref)jsonfile.close()return data
CSV文件操作模块
import csv
import jsondef csv_to_json(csv_path, json_path):with open(csv_path, 'r', encoding='utf-8') as csv_file:csv_reader = csv.DictReader(csv_file) # 自动解析表头为键data = [row for row in csv_reader] # 逐行转为字典列表with open(json_path, 'w', encoding='utf-8') as json_file:json.dump(data, json_file, indent=4, ensure_ascii=False) # 美化输出并支持非ASCII字符# 调用示例
if __name__ == "__main__":print(__file__)csv_to_json('input.csv', 'output.json')print("end")
函数调用状态绘制
import os
import sys
import jsonFUNC_NAME = "函数块"
FUNC_NOTE = "函数块注释"
FUNC_DEPT = "函数块深度"
FUNC_CHAIN_TYPE = "状态顺序链"
FUNC_JUMP_NOTE = "状态跳转说明"
FUNC_TYPE = "类型"
FUNC_LINE_NOTE = "注释"
FUNC_JUMP_TARGET = "跳转函数"FUNC_CHAIN_TYPE_TRUE = "Y"
FUNC_CHAIN_TYPE_FALSE = "N"ROOT = "ROOT"class State:def __init__(self):self.body = {}self.body[FUNC_NAME] = ""self.body[FUNC_NOTE] = ""self.body[FUNC_DEPT] = ""self.body[FUNC_CHAIN_TYPE] = ""self.body[FUNC_NOTE] = ""self.body[FUNC_TYPE] = ""self.body[FUNC_LINE_NOTE] = ""passdef update_dept(self, state_new):self.body[FUNC_DEPT] = str(int(eval(self.body[FUNC_DEPT], eval(state_new.body[FUNC_DEPT]))))passdef __str__(self):print(self.body)return ""depth_cnt = 0
def print_plantuml_init(stateTree, stateArray, note, umlfile):global depth_cntfor sonnode in stateTree[note[0]]:if sonnode[1] != FUNC_CHAIN_TYPE_TRUE:continuedepth_cnt +=1print(" "*depth_cnt, " ".join(["state \"", stateArray[sonnode[0]][FUNC_NOTE], "\" as", stateArray[sonnode[0]][FUNC_NAME], "{"]), file = umlfile)print_plantuml_init(stateTree, stateArray, sonnode, umlfile = umlfile)print(" "*depth_cnt, "}", file = umlfile)depth_cnt -= 1returndef print_plantuml_jump(jsonArray, stateArray, umlfile):for linek in jsonArray:if linek[FUNC_JUMP_TARGET] in stateArray.keys():print(" ", linek[FUNC_NAME], "-down->", linek[FUNC_JUMP_TARGET], ":", "", linek[FUNC_JUMP_NOTE], "", file = umlfile)passreturnclass StateArray:def __init__(self, jsonArray, filename):self.jsonArray = jsonArrayself.stateArray = {}self.stateTree = {}for arrk in jsonArray:func_name = arrk[FUNC_NAME]if func_name in self.stateArray.keys():passelse:self.stateArray[arrk[FUNC_NAME]] = arrkpassself.update_state_chain()with open(filename, "w+", encoding="utf-8") as umlfile:print("```plantuml", file= umlfile)print("@startuml", file= umlfile)print_plantuml_init(self.stateTree, self.stateArray, (ROOT, FUNC_CHAIN_TYPE_TRUE, "ROOT"), umlfile = umlfile)print_plantuml_jump(self.jsonArray, self.stateArray, umlfile=umlfile)print("@enduml", file= umlfile)print("```", file= umlfile)passdef update_state_chain(self):last_state_stack = []# 遍历所有函数for statek in self.stateArray.keys():if not last_state_stack:last_state_stack.append(statek)if statek in self.stateTree.keys():print(statek, self.stateArray[statek], "duplitate state line")else:self.stateTree[statek] = []pass# 建立根结点self.stateTree[ROOT] = []state_top_depth = eval(self.jsonArray[0][FUNC_DEPT])for idxk in range(0, len(self.jsonArray)):statek = self.jsonArray[idxk][FUNC_NAME]statek_depth = eval(self.jsonArray[idxk][FUNC_DEPT])if statek_depth == state_top_depth:self.stateTree[ROOT].append((statek, self.jsonArray[idxk][FUNC_CHAIN_TYPE], self.jsonArray[idxk][FUNC_JUMP_NOTE]))pass# 建立子结点for idxk in range(0, len(self.jsonArray)):statek = self.jsonArray[idxk][FUNC_NAME]statek_depth = eval(self.jsonArray[idxk][FUNC_DEPT])for idxm in range(idxk+1, len(self.jsonArray)):statem = self.jsonArray[idxm][FUNC_NAME]statem_depth = eval(self.jsonArray[idxm][FUNC_DEPT])if statek_depth + 1 == statem_depth:self.stateTree[statek].append((statem, self.jsonArray[idxm][FUNC_CHAIN_TYPE], self.jsonArray[idxm][FUNC_JUMP_NOTE]))if statek_depth >= statem_depth:breakpasspassreturndef __str__(self):for statek in self.stateArray.keys():print(statek, self.stateArray[statek])print(self.stateTree)return ""
主函数调用入口
import os
import sys
import time
import json
import csv
import globimport module.module_json as mdjson
import module.module_csv as mdcsv
import module.module_state as mdstatedef create_csv2json(filepath, filename):totalname = os.path.join(filepath, filename)jsonname = filename+".json"jsontotalname = os.path.join(filepath, jsonname)mdcsv.csv_to_json(totalname, jsontotalname)return filepath, jsonnamedef create_json2state(filepath, filename):totalname = os.path.join(filepath, filename)jsonarray = mdjson.load_json(filepath, filename)print(mdstate.StateArray(jsonArray=jsonarray, filename=totalname + ".md"))return jsonarrayif __name__ == "__main__":filepath = r".\statecsv"filename = r"demo.csv"jsonpath, jsonname = create_csv2json(filepath=filepath, filename=filename)create_json2state(jsonpath, jsonname)