CorrectNav:用错误数据反哺训练的视觉语言导航新突破
导读
在机器人视觉语言导航中,一个长期困扰研究者的问题是:模型在执行自然语言指令时,一旦偏离正确轨迹,往往很难自行修正,最终导致失败。现有方法大多缺乏有效的错误纠正能力,这严重限制了模型在真实场景中的应用。
为解决这一难题,作者提出了一种全新的训练范式——自我纠错飞轮(Self-correction Flywheel)。这一方法并没有将模型在训练集上产生的错误轨迹视为缺陷,反而将其视为宝贵的学习资源。研究团队设计了自动化机制,能够从错误轨迹中识别偏差,并生成额外的感知与行动纠错数据,用于持续训练模型。随着迭代进行,模型会在新的训练集上暴露出新的错误轨迹,这些轨迹又被再次利用,形成一个不断加速的“飞轮效应”。
基于这一范式,作者训练了CorrectNav模型,并在 R2R-CE 和 RxR-CE 两大基准上取得了65.1% 和 69.3%的成功率,分别比此前最佳方法提升8.2% 和 16.4%。更重要的是,实地机器人实验显示,CorrectNav 能够在复杂的室内外环境中实现稳定的自我纠错、动态避障和长指令执行,显著提升了视觉语言导航的鲁棒性。

图1|CorrectNav 的多样化能力。该模型仅依靠单目 RGB 视频和语言指令作为输入,即可预测导航动作。在 自我纠错飞轮 后训练机制的加持下,CorrectNav 不仅保持了出色的多模态推理能力(蓝色),还展现出更强的偏差纠正(红色)、障碍物规避(绿色)以及复杂动作执行(黄色)能力
论文出处:arXiv2025
论文标题:CorrectNav: Self-Correction Flywheel EmpowersVision-Language-Action Navigation Model
论文作者:Zhuoyuan Yu, Yuxing Long, Zihan Yang, Chengyan Zeng,Hongwei Fan, Jiyao Zhang, Hao Dong

在视觉语言导航(Vision-and-Language Navigation, VLN)任务中,用户通过自然语言指令控制机器人在未知环境中移动至目标位置,例如“向前走,然后右转进入客厅,在沙发旁边等待”。由于交互方式自然直观,VLN 已成为具身智能的重要基础能力,并引起了广泛的研究关注。
然而,在导航过程中,模型不可避免地会预测出错误的运动动作,从而导致机器人偏离正确路径。这类偏离会造成环境与指令之间的错位。以刚才的指令为例,如果机器人直接在当前位置右转,而不是先向前移动,它将进入厨房而无法找到沙发。此时,机器人容易因指令与环境不匹配而产生混乱,最终无法到达目标。
现有的 VLN 模型主要集中在提升视觉感知和多模态推理能力,方法包括改进特征表示或扩充训练数据。这些方法的目标是尽可能保证模型在每一步都能正确预测。但现实情况是,仅仅几步不完美的预测就可能导致显著的路径偏差,并最终造成失败。缺乏自我纠错能力,使得现有模型在出错后难以恢复,从而限制了整体导航性能。这一不足引发了一个关键问题:是否可以让机器人在导航过程中学会自我纠错?
针对这一问题,作者分析了需要纠正的错误类型以及如何让模型学会纠错。作为一个视觉-语言-动作任务,VLN 要求模型动态感知环境并跟随指令完成导航。错误通常来源于两方面:一是地标感知错误,二是对指令中动作的误解。这些错误会沿着决策链传播,进一步影响运动预测。因此,研究应聚焦于感知和动作两个层面的错误。此外,实际应用要求推理必须高效,因此自我纠错能力应在训练中隐式融入,而不是依赖额外的推理模块或复杂结构。
为此,作者提出了自我纠错飞轮(Self-correction Flywheel) 这一新颖的后训练范式。其灵感来自于观察到:即使是训练充分的导航模型,在训练集上依然会产生错误轨迹。作者并没有将这些错误视为缺陷,而是视为进一步优化的机会。整个范式包含四个步骤:(1) 在训练集上评估模型并收集错误轨迹;(2) 设计自动化方法检测偏差,并精确定位错误发生的位置;(3) 基于动作与感知两个视角生成自我纠错数据,其中动作层面收集能成功恢复的轨迹,感知层面则利用大规模多模态模型分析与错误相关的关键帧;(4) 使用生成的自我纠错数据继续训练导航模型。完成这四个步骤构成一次“飞轮循环”。当经过一次自我纠错训练后的模型再次在训练集上评估时,会暴露出新的错误轨迹,从而生成新的纠错数据并推动进一步训练。此时,飞轮开始转动,模型的性能在多次迭代中不断提升。
此外,作者还设计了一系列导航微调策略,包括观测随机化、指令生成和跨模态数据回调。基于这些后训练与微调策略,作者提出了一个新的单目 RGB 输入的 VLA 导航模型 CorrectNav。在 R2R-CE 和 RxR-CE 两大基准上,CorrectNav 的成功率分别达到 65.1% 和 69.3%,比此前最优模型提升了 8.2% 和 16.4%。进一步的真实机器人实验表明,CorrectNav 具备强大的错误纠正能力,能够实现动态避障和长指令执行,在复杂的室内外环境中均表现出优越的鲁棒性,显著超越现有方法。

CorrectNav 模型结构
作者提出的 CorrectNav 模型由三个主要模块组成:视觉编码器(Vision Encoder)、投影器(Projector)和大语言模型(LLM)。其中,视觉编码器采用 SigLIP,从输入的视频帧中提取视觉特征;投影器为一个两层 MLP,将视觉特征映射到 LLM 的语义空间,形成视觉 token;最后,Qwen2 模型作为 LLM,结合视觉 token 和任务指令编码的文本 token,基于自回归方式进行预测。整个模型在导航微调之前,初始化自 LLaVA-Video 7B。
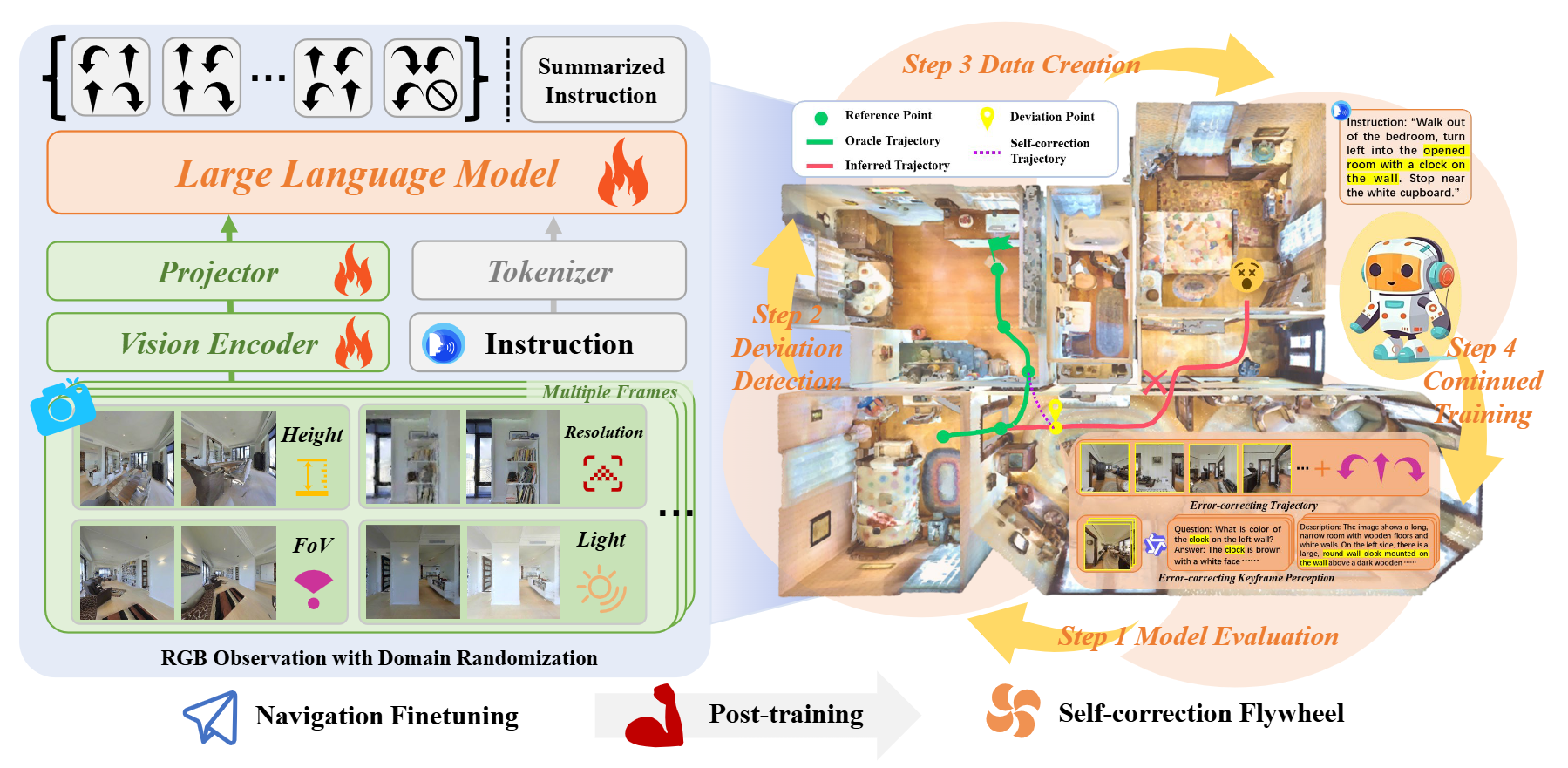
图2|CorrectNav 训练流程概览。首先,CorrectNav 在导航任务上进行微调(左侧),包括动作预测与指令生成。为了增强视觉多样性,训练中引入了一系列域随机化策略。随后,CorrectNav 通过所提出的 自我纠错飞轮 范式进行后训练(右侧)。该范式在模型评估、偏差检测、数据生成和持续训练之间形成一个连续循环。特别是,在数据生成环节中,系统能够自动收集 纠错轨迹 和 关键帧感知数据。经过多轮训练迭代,CorrectNav 逐步学会如何从偏差中恢复
导航微调
在导航微调阶段,作者从 VLN-CE R2R 和 RxR 数据集中收集了大量的专家轨迹。这些轨迹包括导航指令、逐步的 RGB 观测和对应的动作。为提升视觉多样性,训练过程中引入了域随机化策略,例如相机高度、视野角度、分辨率和光照条件的变化。最终,构建了一个包含超过 210 万条逐步导航样本的数据集,其中 R2R 提供了 52.7 万条,RxR 提供了 158 万条。模型的任务是输入指令和逐步的 RGB 图像,并预测接下来的动作序列。
除了动作预测,作者还训练模型进行 基于轨迹的指令生成。在这一任务中,模型输入完整的轨迹观测,目标是生成对应的语言指令。该部分利用了 1 万条 R2R 和 2 万条 RxR 的完整轨迹数据。此外,为避免因只在导航任务上训练而导致多模态能力的遗忘,作者引入了 LLaVA-Video 数据集中的一部分视频任务,特别是强调时间和空间理解的 Activitynet-QA 与 NextQA,共采样了 24 万条实例,以保持模型的一般多模态能力。
自我纠错飞轮(Self-correction Flywheel)
为了让模型具备从错误中恢复的能力,作者提出了一个全新的后训练范式——自我纠错飞轮。该过程包含四个步骤,每次迭代都形成一个闭环,从而推动模型的自我修复能力不断增强:
1. 模型评估(Model Evaluation)在 R2R-CE 和 RxR-CE 的训练集上,作者发现即使是训练过的模型依然会产生错误轨迹。利用这些错误轨迹,可以收集宝贵的纠错数据。
2. 轨迹偏差检测(Deviation Detection)错误轨迹通常没有标注出偏差发生的位置。为此,作者提出了一种基于轨迹距离的检测方法:通过比较模型生成轨迹与专家轨迹之间的距离,来定位模型开始偏离的时刻。偏差附近的观测帧被标记为纠错关键帧。
3. 自我纠错数据生成(Data Creation)错误主要来自动作和感知两个方面。
● 动作纠错:通过检测偏差点,生成一条“纠错轨迹”,即从偏差点重新规划路径直至目标位置。这样可以教会模型如何在偏差发生后调整动作。
● 感知纠错:在偏差点附近的关键帧上,利用多模态大模型 Qwen-VL-Plus 生成视觉分析数据,包括对潜在导航地标的描述,以及关于物体位置、颜色和机器人朝向的问答对。这类数据帮助模型理解“为什么出错”,提升感知层面的纠错能力。
4. 模型继续训练(Continued Training)将纠错数据与部分原始轨迹数据混合,用于进一步训练 CorrectNav。每轮训练完成后,模型在训练集上的新评估又会产生新的错误轨迹,从而生成新的纠错数据,进入下一轮训练。通过多轮迭代,飞轮不断加速运转,模型的自我纠错能力逐渐增强。

图3|算法训练流程
实现细节
CorrectNav 的训练在 8 张 A100 GPU 上完成,导航微调阶段耗时约 80 小时,而自我纠错飞轮每次迭代耗时约 20 小时。在推理阶段,CorrectNav 输入 16 帧 RGB 图像,并预测一个包含 4 步动作的序列。

本研究围绕以下四个问题展开实验评估:(1)CorrectNav 与现有最优模型在 VLN-CE 基准上的对比表现如何?(2)自我纠错飞轮迭代能带来哪些性能提升?(3)不同的自我纠错训练技术对性能提升的单独作用是什么?(4)CorrectNav 在真实环境中的效果如何?
环境与评估指标验
实验在 VLN-CE 基准上进行,该基准为重建的真实感室内场景提供了连续环境,用于执行导航动作。评估重点放在 R2R(Room-to-Room)和 RxR(Room-across-Room)的 Val-Unseen 分割集,这两个数据集是视觉语言导航领域最具代表性的基准。仿真平台采用 Habitat 3.0。评价指标包括:
● Navigation Error (NE):表示最终位置与目标之间的平均距离;
● Success Rate (SR):NE 小于 3 米的轨迹比例;
● Oracle Success Rate (OSR):在理想停止策略下的成功率;
● SPL:成功率加权的路径效率;
● nDTW:基于时间对齐的轨迹相似度度量。
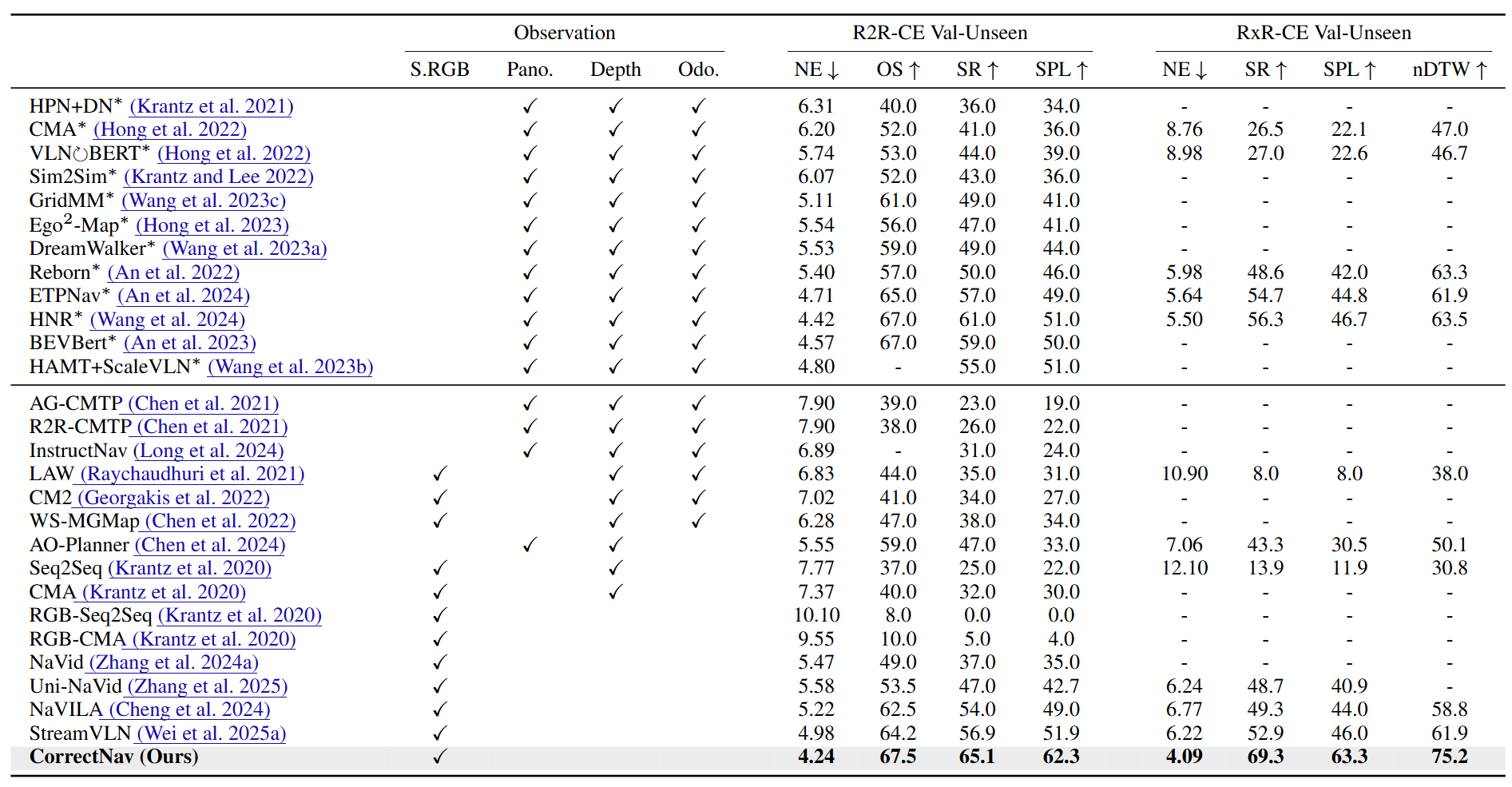
图4|模拟实验量化结果
与其他 VLN-CE 模型的比较
在 R2R-CE 和 RxR-CE 上,CorrectNav 与现有多种模型进行了对比,包括基于航路点预测的方法和导航大模型(见图4)。从结果来看,尽管 CorrectNav 仅依赖单目 RGB 图像输入,它依然超越了所有现有模型。在成功率指标上,CorrectNav 相比最优导航大模型 StreamVLN,分别在 R2R-CE 和 RxR-CE 上提升了 8.2% 和 16.4%。同时,相比最佳的航路点预测模型 HNR,CorrectNav 也分别提升了 4.1% 和 13.0%,显示出强大的导航性能。
消融实验
为了研究不同自我纠错训练技术对性能的贡献,作者进行了消融实验(见图5),在第一轮自我纠错飞轮中逐一移除各项技术。结果显示,无论移除哪项,CorrectNav 的性能都会下降,其中移除 导航轨迹纠错 的影响最大。这表明各项训练技术在整体性能提升中都发挥了关键作用。
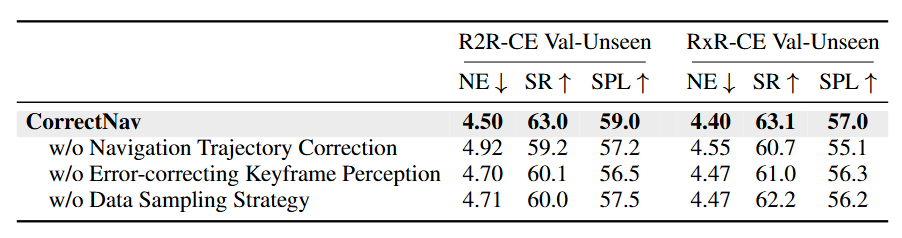
图5|消融实验结果
自我纠错飞轮迭代的效果
进一步分析 CorrectNav 在多轮飞轮迭代后的表现(见图6)。实验结果显示,在前三次迭代中,模型在 R2R-CE 和 RxR-CE 的成功率持续提升,导航误差不断下降,证明了飞轮机制的有效性。在第四次迭代中性能出现下降,因而作者选择停止训练。定性分析结果(如图示)也表明,经过飞轮后训练的 CorrectNav 具备了显著的错误修复能力,相较于未使用飞轮的版本在轨迹纠偏方面更为出色。
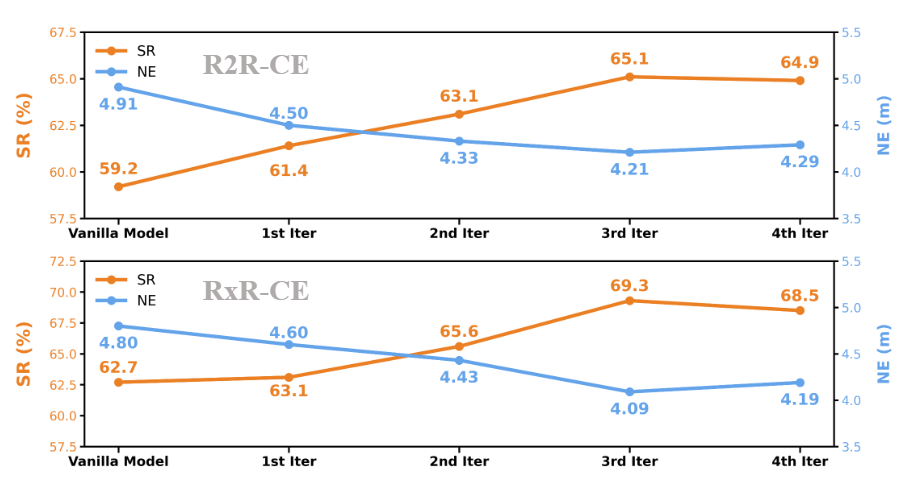
图6|不同迭代次数下CorrectNav在两个数据集上的综合导航性能
真实机器人实验
在真实环境中,作者采用四足机器人 AgiBot Lingxi D1 作为平台,每台机器人搭载单目 RGB 相机和运动控制 API。机器人在接收自然语言导航指令后,将图像上传至部署在远程服务器上的 CorrectNav 模型(配备 A100 GPU)。CorrectNav 输出包含四步动作的指令序列,并通过运动 API 执行。
作者在办公室、家庭和校园三类场景中测试了 CorrectNav,并与两种先进导航大模型 NaVID 和 NaVILA 进行了对比。每个场景均测试 20 条简单指令和 20 条复杂指令,复杂指令涉及长距离、多建筑结构、拥挤障碍和动态场景变化。

图7|真实环境机器人部署实验可视化

本文提出了 Self-correction Flywheel,一种新颖的后训练范式,核心思想是把模型在训练集上的“错误轨迹”视为宝贵的数据源,而不是缺陷。通过 偏差检测—纠错数据生成—持续训练 构成的闭环机制,模型在多轮迭代中逐步增强了自我纠错能力。
在此基础上,作者设计了单目 RGB 输入的导航模型 CorrectNav,结合视觉编码器、投影器和大语言模型,配合飞轮机制实现感知与动作层面的自适应修复。
实验结果显示:
● 在 R2R-CE 与 RxR-CE 基准上,CorrectNav 成功率分别提升 8.2% 和 16.4%,超越所有现有模型。
● 消融实验验证了 导航轨迹纠错 和 关键帧感知修复 等技术的有效性。
● 多轮飞轮迭代带来持续性能提升,证明了闭环纠错机制的长期价值。
● 在真实机器人实验中,CorrectNav 展现出 更强的偏差修复、动态避障和长指令跟随能力,远超其他导航大模型。
整体而言,本研究开辟了一条全新路径:通过“错误驱动学习”,让导航模型具备类似人类的 自我反思与纠正 能力,为具身智能的稳健发展提供了重要思路。