基于SQL大型数据库的智能问答系统优化
一、食用指南
基于SQL数据库的智能问答系统设计与实现介绍了在数据库中创建表格数据问答系统的基本方法,我们可以向该系统提出关于数据库数据的问题,最终获得自然语言答案。
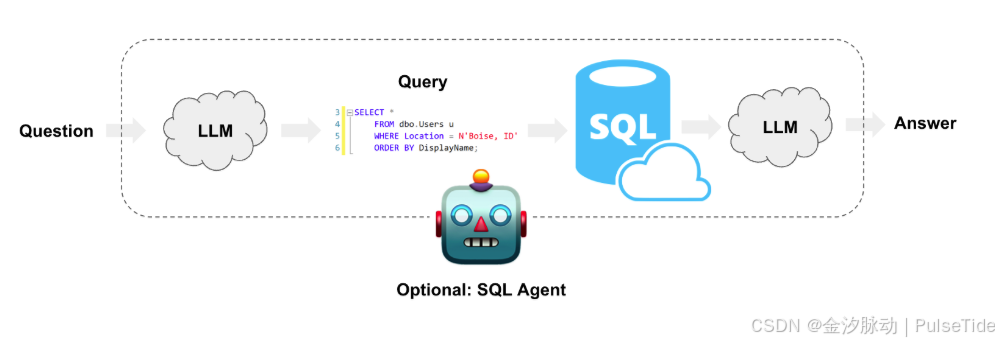
为了针对数据库编写有效的查询,我们需要向模型提供表名、表结构和特征值以供其查询。当存在许多表、列和/或高基数列时,我们不可能在每个提示中倾倒关于数据库的全部信息,相反,我们必须找到一种方法,仅将最相关的信息动态地插入到提示中。
本文介绍识别此类相关信息并将其输入到查询生成步骤中的方法,我们将涵盖:
- 识别相关的表子集;
- 识别相关的列值子集。
二、安装依赖
%pip install --upgrade --quiet langchain langchain-community langchain-openai
三、示例数据
# 下载sql脚本
wget https://raw.githubusercontent.com/lerocha/chinook-database/master/ChinookDatabase/DataSources/Chinook_Sqlite.sql
sqlite3 Chinook.db
.read Chinook_Sqlite.sql
SELECT * FROM Artist LIMIT 10;
$ sqlite3 Chinook.db
SQLite version 3.45.3 2024-04-15 13:34:05
Enter ".help" for usage hints.
sqlite> .read Chinook_Sqlite.sql
sqlite> SELECT * FROM Artist LIMIT 10;
1|AC/DC
2|Accept
3|Aerosmith
4|Alanis Morissette
5|Alice In Chains
6|Antônio Carlos Jobim
7|Apocalyptica
8|Audioslave
9|BackBeat
10|Billy Cobham
sqlite> .quit
现在,Chinook.db 位于我们的目录中,我们可以使用 SQLAlchemy 驱动的 SQLDatabase 类与之交互:
from langchain_community.utilities import SQLDatabasedb = SQLDatabase.from_uri("sqlite:///Chinook.db")
print(db.dialect)
print(db.get_usable_table_names())
print(db.run("SELECT * FROM Artist LIMIT 10;"))
sqlite
['Album', 'Artist', 'Customer', 'Employee', 'Genre', 'Invoice', 'InvoiceLine', 'MediaType', 'Playlist', 'PlaylistTrack', 'Track']
[(1, 'AC/DC'), (2, 'Accept'), (3, 'Aerosmith'), (4, 'Alanis Morissette'), (5, 'Alice In Chains'), (6, 'Antônio Carlos Jobim'), (7, 'Apocalyptica'), (8, 'Audioslave'), (9, 'BackBeat'), (10, 'Billy Cobham')]
四、LLM
%pip install langchain-openai
import osos.environ["OPENAI_BASE_URL"] = "https://api.siliconflow.cn/v1/"
os.environ["OPENAI_API_KEY"] = "sk-xxx"from langchain.chat_models import init_chat_modelllm = init_chat_model("Qwen/Qwen3-8B", model_provider="openai")
# llm = init_chat_model("THUDM/GLM-Z1-9B-0414", model_provider="openai")
# llm = init_chat_model("deepseek-ai/DeepSeek-R1-0528-Qwen3-8B", model_provider="openai")
这里使用硅基流动的免费模型服务,以上代码中使用 Qwen/Qwen3-8B 模型,当然也可以使用其他免费模型,直接复制官网上的模型名称即可,点击这里直达官网,注册完成后创建一个 API 密钥就能使用模型了。

五、相关表
我们需要在提示中包含的主要信息之一是相关表的结构,当我们有非常多的数据表时,无法将所有表都放入一个提示中。在这种情况下,我们可以先提取与用户输入最相关的表名,一种简单可靠的方法是使用工具调用,agent 通过工具获取符合查询所需格式的输出(在本例中为表名list),我们使用聊天模型的 .bind_tools 方法绑定一个 Pydantic 格式的工具,并将其输入到输出解析器中,以从模型的响应中重建对象。
from langchain_core.output_parsers.openai_tools import PydanticToolsParser
from langchain_core.prompts import ChatPromptTemplate
from pydantic import BaseModel, Fieldclass Table(BaseModel):"""Table in SQL database."""name: str = Field(description="Name of table in SQL database.")table_names = "\n".join(db.get_usable_table_names())
system = f"""返回可能与用户问题相关的所有SQL表名称。表包括:{table_names}。请记住包含所有可能相关的表,即使不确定是否需要它们。"""prompt = ChatPromptTemplate.from_messages([("system", system),("human", "{input}"),]
)
llm_with_tools = llm.bind_tools([Table])
output_parser = PydanticToolsParser(tools=[Table])table_chain = prompt | llm_with_tools | output_parsertable_chain.invoke({"input": "Alanis Morissette 歌曲的所有流派是什么"})
[Table(name='Artist'), Table(name='Track'), Table(name='Genre')]
效果很好,返回的三个表名中,Genre 是真正所需要的。实际上,我们还需要一些其他表才能把信息链打通,但仅根据用户问题,模型很难知道这些。在这种情况下,我们可以考虑通过将表分组来简化模型的工作,只要求模型在“音乐”和“业务”类别之间进行选择所有相关表。
system = """返回与用户问题相关的SQL表名。可用的表有:
1. 音乐(Music)
2. 业务(Business)
"""prompt = ChatPromptTemplate.from_messages([("system", system),("human", "{input}"),]
)category_chain = prompt | llm_with_tools | output_parser
category_chain.invoke({"input": "Alanis Morissette 歌曲的所有流派是什么"})
[Table(name='Music')]
根据返回结果再做细分处理:
from typing import Listdef get_tables(categories: List[Table]) -> List[str]:tables = []for category in categories:if category.name == "Music":tables.extend(["Album","Artist","Genre","MediaType","Playlist","PlaylistTrack","Track",])elif category.name == "Business":tables.extend(["Customer", "Employee", "Invoice", "InvoiceLine"])return tablestable_chain = category_chain | get_tables
table_chain.invoke({"input": "Alanis Morissette 歌曲的所有流派是什么"})
['Album', 'Artist', 'Genre', 'MediaType', 'Playlist', 'PlaylistTrack', 'Track']
现在我们有了一个可以为任何查询输出相关表的 Chain,将其与 create_sql_query_chain 连接起来,该 Chain 可以接受一个 table_names_to_use 列表来确定提示中包含哪些表:
from operator import itemgetterfrom langchain.chains import create_sql_query_chain
from langchain_core.runnables import RunnablePassthroughquery_chain = create_sql_query_chain(llm, db)
# Convert "question" key to the "input" key expected by current table_chain.
table_chain = {"input": itemgetter("question")} | table_chain
# Set table_names_to_use using table_chain.
full_chain = RunnablePassthrough.assign(table_names_to_use=table_chain) | query_chain
query_chain
RunnableAssign(mapper={input: RunnableLambda(...),table_info: RunnableLambda(...)
})
| RunnableLambda(lambda x: {k: v for (k, v) in x.items() if k not in ('question', 'table_names_to_use')})
| PromptTemplate(input_variables=['input', 'table_info'], input_types={}, partial_variables={'top_k': '5'}, template='You are a SQLite expert. Given an input question, first create a syntactically correct SQLite query to run, then look at the results of the query and return the answer to the input question.\nUnless the user specifies in the question a specific number of examples to obtain, query for at most {top_k} results using the LIMIT clause as per SQLite. You can order the results to return the most informative data in the database.\nNever query for all columns from a table. You must query only the columns that are needed to answer the question. Wrap each column name in double quotes (") to denote them as delimited identifiers.\nPay attention to use only the column names you can see in the tables below. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table.\nPay attention to use date(\'now\') function to get the current date, if the question involves "today".\n\nUse the following format:\n\nQuestion: Question here\nSQLQuery: SQL Query to run\nSQLResult: Result of the SQLQuery\nAnswer: Final answer here\n\nOnly use the following tables:\n{table_info}\n\nQuestion: {input}')
| RunnableBinding(bound=ChatOpenAI(client=<openai.resources.chat.completions.completions.Completions object at 0x74101c7aacb0>, async_client=<openai.resources.chat.completions.completions.AsyncCompletions object at 0x74101c7a9de0>, root_client=<openai.OpenAI object at 0x74101e9b24a0>, root_async_client=<openai.AsyncOpenAI object at 0x74101c2af100>, model_name='Qwen/Qwen3-8B', model_kwargs={}, openai_api_key=SecretStr('**********')), kwargs={'stop': ['\nSQLResult:']}, config={}, config_factories=[])
| StrOutputParser()
| RunnableLambda(_strip)
full_chain
RunnableAssign(mapper={table_names_to_use: {input: RunnableLambda(itemgetter('question'))}| ChatPromptTemplate(input_variables=['input'], input_types={}, partial_variables={}, messages=[SystemMessagePromptTemplate(prompt=PromptTemplate(input_variables=[], input_types={}, partial_variables={}, template='返回与用户问题相关的SQL表名。可用的表有:\n1. 音乐(Music)\n2. 业务(Business)\n'), additional_kwargs={}), HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['input'], input_types={}, partial_variables={}, template='{input}'), additional_kwargs={})])| RunnableBinding(bound=ChatOpenAI(client=<openai.resources.chat.completions.completions.Completions object at 0x74101c7aacb0>, async_client=<openai.resources.chat.completions.completions.AsyncCompletions object at 0x74101c7a9de0>, root_client=<openai.OpenAI object at 0x74101e9b24a0>, root_async_client=<openai.AsyncOpenAI object at 0x74101c2af100>, model_name='Qwen/Qwen3-8B', model_kwargs={}, openai_api_key=SecretStr('**********')), kwargs={'tools': [{'type': 'function', 'function': {'name': 'Table', 'description': 'Table in SQL database.', 'parameters': {'properties': {'name': {'description': 'Name of table in SQL database.', 'type': 'string'}}, 'required': ['name'], 'type': 'object'}}}]}, config={}, config_factories=[])| PydanticToolsParser(tools=[<class '__main__.Table'>])| RunnableLambda(get_tables)
})
| RunnableAssign(mapper={input: RunnableLambda(...),table_info: RunnableLambda(...)})
| RunnableLambda(lambda x: {k: v for (k, v) in x.items() if k not in ('question', 'table_names_to_use')})
| PromptTemplate(input_variables=['input', 'table_info'], input_types={}, partial_variables={'top_k': '5'}, template='You are a SQLite expert. Given an input question, first create a syntactically correct SQLite query to run, then look at the results of the query and return the answer to the input question.\nUnless the user specifies in the question a specific number of examples to obtain, query for at most {top_k} results using the LIMIT clause as per SQLite. You can order the results to return the most informative data in the database.\nNever query for all columns from a table. You must query only the columns that are needed to answer the question. Wrap each column name in double quotes (") to denote them as delimited identifiers.\nPay attention to use only the column names you can see in the tables below. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table.\nPay attention to use date(\'now\') function to get the current date, if the question involves "today".\n\nUse the following format:\n\nQuestion: Question here\nSQLQuery: SQL Query to run\nSQLResult: Result of the SQLQuery\nAnswer: Final answer here\n\nOnly use the following tables:\n{table_info}\n\nQuestion: {input}')
| RunnableBinding(bound=ChatOpenAI(client=<openai.resources.chat.completions.completions.Completions object at 0x74101c7aacb0>, async_client=<openai.resources.chat.completions.completions.AsyncCompletions object at 0x74101c7a9de0>, root_client=<openai.OpenAI object at 0x74101e9b24a0>, root_async_client=<openai.AsyncOpenAI object at 0x74101c2af100>, model_name='Qwen/Qwen3-8B', model_kwargs={}, openai_api_key=SecretStr('**********')), kwargs={'stop': ['\nSQLResult:']}, config={}, config_factories=[])
| StrOutputParser()
| RunnableLambda(_strip)
测试:
query = full_chain.invoke({"question": "Alanis Morissette 歌曲的所有流派是什么"}
)
print(query)
SQLQuery: SELECT DISTINCT "Genre"."Name" FROM "Track" JOIN "Album" ON "Track"."AlbumId" = "Album"."AlbumId" JOIN "Artist" ON "Album"."ArtistId" = "Artist"."ArtistId" JOIN "Genre" ON "Track"."GenreId" = "Genre"."GenreId" WHERE "Artist"."Name" = 'Alanis Morissette' LIMIT 5;
执行 SQL:
db.run(query.replace("SQLQuery: ",""))
"[('Rock',)]"
至此,我们实现了在 Chain 中动态地在提示词中提供相关表。
解决此问题的另一种可能方法是让 Agent 通过调用工具来决定何时查找表,这个过程可能会需要多次调用查询工具,具体细节可参考:基于SQL数据库的智能问答系统设计与实现中的 Agent 部分。
六、高基数列
为了过滤包含专有名词(如地址、歌曲名称或艺术家)的列,我们首先需要仔细检查拼写,以正确过滤数据。我们可以通过创建一个包含数据库中所有不同专有名词的向量存储来实现这一点,然后,每当用户在问题中包含专有名词时,让 agent 查询该向量存储,以找到该词的正确拼写。通过这种方式,agent 可以确保在构建目标查询之前,它理解用户指的是哪个实体。
首先,将结果解析为元素列表:
import ast
import redef query_as_list(db, query):res = db.run(query)res = [el for sub in ast.literal_eval(res) for el in sub if el]res = [re.sub(r"\b\d+\b", "", string).strip() for string in res]return resproper_nouns = query_as_list(db, "SELECT Name FROM Artist")
proper_nouns += query_as_list(db, "SELECT Title FROM Album")
proper_nouns += query_as_list(db, "SELECT Name FROM Genre")
len(proper_nouns)
proper_nouns[:5]
['AC/DC', 'Accept', 'Aerosmith', 'Alanis Morissette', 'Alice In Chains']
现在我们可以将所有值嵌入并存储在向量数据库中:
# %pip install faiss-gpu
%pip install faiss-cpu
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddingsvector_db = FAISS.from_texts(proper_nouns, OpenAIEmbeddings(model="BAAI/bge-m3",base_url="http://localhost:8000/v1", api_key="EMPTY"))
retriever = vector_db.as_retriever(search_kwargs={"k": 15})
向量查询:
retriever.invoke("elanis Morisset")
[Document(id='0a7ad312-dbba-4a56-883a-7cf90edfbdf5', metadata={}, page_content='Alanis Morissette'),Document(id='9176353f-7047-4c9a-8780-b24174fb1f3d', metadata={}, page_content='Elis Regina'),Document(id='9a876473-aaea-4b86-8467-132008632795', metadata={}, page_content='Volume Dois'),Document(id='17298f91-b479-4447-9480-9712ef722412', metadata={}, page_content='Xis'),Document(id='0f7d044d-290d-4b43-b436-ab8e82b86688', metadata={}, page_content='Handel: Music for the Royal Fireworks (Original Version )'),Document(id='ef588f64-b5bf-40f0-9b06-f55ef7927435', metadata={}, page_content='LOST, Season'),Document(id='5bd80286-6b27-44af-b8a5-d5f52de2e125', metadata={}, page_content='Garage Inc. (Disc )'),Document(id='405229d7-a098-4425-ad97-7afb4d3a459a', metadata={}, page_content='Garage Inc. (Disc )'),Document(id='a108b0fc-e7ab-4095-9f6f-9a1a359717e1', metadata={}, page_content='Surfing with the Alien (Remastered)'),Document(id='36f7c22d-a4a1-4644-a026-a283f78dd761', metadata={}, page_content="Christopher O'Riley"),Document(id='71563ff6-ee38-439b-b743-c7e187bf34d5', metadata={}, page_content='Speak of the Devil'),Document(id='d254a91f-9745-4a69-ac07-39ae4b1655c1', metadata={}, page_content='The Police'),Document(id='5b74ec24-428a-42b8-99fb-9c1442ca47c0', metadata={}, page_content='Vs.'),Document(id='1a1ce9a3-3b28-4c73-a1ba-443e11051672', metadata={}, page_content='Elis Regina-Minha História'),Document(id='4679d89e-e1a8-46fb-884d-0ddf7b4e9953', metadata={}, page_content='Blue Moods')]
组合一个查询 Chain,该 Chain 首先从数据库中检索值并将其插入到提示词中:
from operator import itemgetterfrom langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthroughsystem = """您是SQLite专家。根据输入问题生成语法正确的SQLite查询,除非另有说明,返回不超过{top_k}行结果。仅返回SQL查询语句,不要包含任何标记或解释。相关表信息:{table_info}以下是可能特征值的非穷举列表。若需按特征值筛选,请先核对拼写:{proper_nouns}
"""prompt = ChatPromptTemplate.from_messages([("system", system), ("human", "{input}")])query_chain = create_sql_query_chain(llm, db, prompt=prompt)
retriever_chain = (itemgetter("question")| retriever| (lambda docs: "\n".join(doc.page_content for doc in docs))
)
chain = RunnablePassthrough.assign(proper_nouns=retriever_chain) | query_chain
query_chain
RunnableAssign(mapper={input: RunnableLambda(...),table_info: RunnableLambda(...)
})
| RunnableLambda(lambda x: {k: v for (k, v) in x.items() if k not in ('question', 'table_names_to_use')})
| ChatPromptTemplate(input_variables=['input', 'proper_nouns', 'table_info'], input_types={}, partial_variables={'top_k': '5'}, messages=[SystemMessagePromptTemplate(prompt=PromptTemplate(input_variables=['proper_nouns', 'table_info', 'top_k'], input_types={}, partial_variables={}, template='您是SQLite专家。根据输入问题生成语法正确的SQLite查询,除非另有说明,返回不超过{top_k}行结果。\n\n仅返回SQL查询语句,不要包含任何标记或解释。\n\n相关表信息:{table_info}\n\n以下是可能特征值的非穷举列表。若需按特征值筛选,请先核对拼写:\n\n{proper_nouns}\n'), additional_kwargs={}), HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['input'], input_types={}, partial_variables={}, template='{input}'), additional_kwargs={})])
| RunnableBinding(bound=ChatOpenAI(client=<openai.resources.chat.completions.completions.Completions object at 0x74101c7aacb0>, async_client=<openai.resources.chat.completions.completions.AsyncCompletions object at 0x74101c7a9de0>, root_client=<openai.OpenAI object at 0x74101e9b24a0>, root_async_client=<openai.AsyncOpenAI object at 0x74101c2af100>, model_name='Qwen/Qwen3-8B', model_kwargs={}, openai_api_key=SecretStr('**********')), kwargs={'stop': ['\nSQLResult:']}, config={}, config_factories=[])
| StrOutputParser()
| RunnableLambda(_strip)
chain
RunnableAssign(mapper={proper_nouns: RunnableLambda(itemgetter('question'))| VectorStoreRetriever(tags=['FAISS', 'OpenAIEmbeddings'], vectorstore=<langchain_community.vectorstores.faiss.FAISS object at 0x7410111f3b80>, search_kwargs={'k': 15})| RunnableLambda(...)
})
| RunnableAssign(mapper={input: RunnableLambda(...),table_info: RunnableLambda(...)})
| RunnableLambda(lambda x: {k: v for (k, v) in x.items() if k not in ('question', 'table_names_to_use')})
| ChatPromptTemplate(input_variables=['input', 'proper_nouns', 'table_info'], input_types={}, partial_variables={'top_k': '5'}, messages=[SystemMessagePromptTemplate(prompt=PromptTemplate(input_variables=['proper_nouns', 'table_info', 'top_k'], input_types={}, partial_variables={}, template='您是SQLite专家。根据输入问题生成语法正确的SQLite查询,除非另有说明,返回不超过{top_k}行结果。\n\n仅返回SQL查询语句,不要包含任何标记或解释。\n\n相关表信息:{table_info}\n\n以下是可能特征值的非穷举列表。若需按特征值筛选,请先核对拼写:\n\n{proper_nouns}\n'), additional_kwargs={}), HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['input'], input_types={}, partial_variables={}, template='{input}'), additional_kwargs={})])
| RunnableBinding(bound=ChatOpenAI(client=<openai.resources.chat.completions.completions.Completions object at 0x74101c7aacb0>, async_client=<openai.resources.chat.completions.completions.AsyncCompletions object at 0x74101c7a9de0>, root_client=<openai.OpenAI object at 0x74101e9b24a0>, root_async_client=<openai.AsyncOpenAI object at 0x74101c2af100>, model_name='Qwen/Qwen3-8B', model_kwargs={}, openai_api_key=SecretStr('**********')), kwargs={'stop': ['\nSQLResult:']}, config={}, config_factories=[])
| StrOutputParser()
| RunnableLambda(_strip)
现在可以测试效果,看看在不使用检索和使用检索的情况下,尝试在歌手名字拼写错误提问时会返回什么。
# Without retrieval
query = query_chain.invoke({"question": "elanis Morissette歌曲的所有流派是什么", "proper_nouns": ""}
)
print(query)
db.run(query)
SELECT Genre.Name
FROM Track
JOIN Genre ON Track.GenreId = Genre.GenreId
WHERE Track.Composer LIKE '%Elanis Morissette%';
''
# With retrieval
query = chain.invoke({"question": "Alanis Morissett歌曲的所有流派是什么"})
print(query)
db.run(query)
SELECT DISTINCT g.Name
FROM Track t
JOIN Genre g ON t.GenreId = g.GenreId
WHERE t.Composer LIKE '%Alanis Morissette%' OR t.Name LIKE '%Alanis Morissette%';
"[('Rock',)]"
我们可以看到,通过检索能够将错误的拼写纠正并获得有效结果。
参考资料
- https://python.langchain.ac.cn/docs/how_to/sql_large_db/