华为云OBS+HMS+EMRonEC2+HiveSparkFlink+GaussDB
华为云OBS+HMS+EMRonEC2+HiveSparkFlink+GaussDB
一句话定位“这是华为云版的 AWS 数据湖方案:OBS 当 S3 存数据,LakeFormation(HMS) 做统一元数据,MRS on ECS 托管 Spark/Flink/Hive,GaussDB(DWS) 当云数仓。”
| 层级 | 华为云组件 | 对应 AWS 组件 | 核心能力一句话 |
|---|---|---|---|
| 存储层 | OBS | Amazon S3 | 对象存储,支持标准/低频/归档/深度归档四级存储,单桶 EB 级,跨域复制,WORM,生命周期 |
| 元数据层 | LakeFormation(HMS) | AWS Glue Catalog | 托管 Hive Metastore,统一 Schema;Catalog 固定名 hive,支持 IAM+桶策略双重权限 |
| 计算层 | MRS on ECS | EMR on EC2 | 一键部署 Hadoop/Spark/Flink 集群;Spot 混合、弹性伸缩;元数据直连 LakeFormation |
| 数仓层 | GaussDB(DWS) | Amazon Redshift | MPP 云数仓,支持列存、物化视图、结果缓存;可通过外表直接查询 OBS,亦支持 Flink 实时 sink |
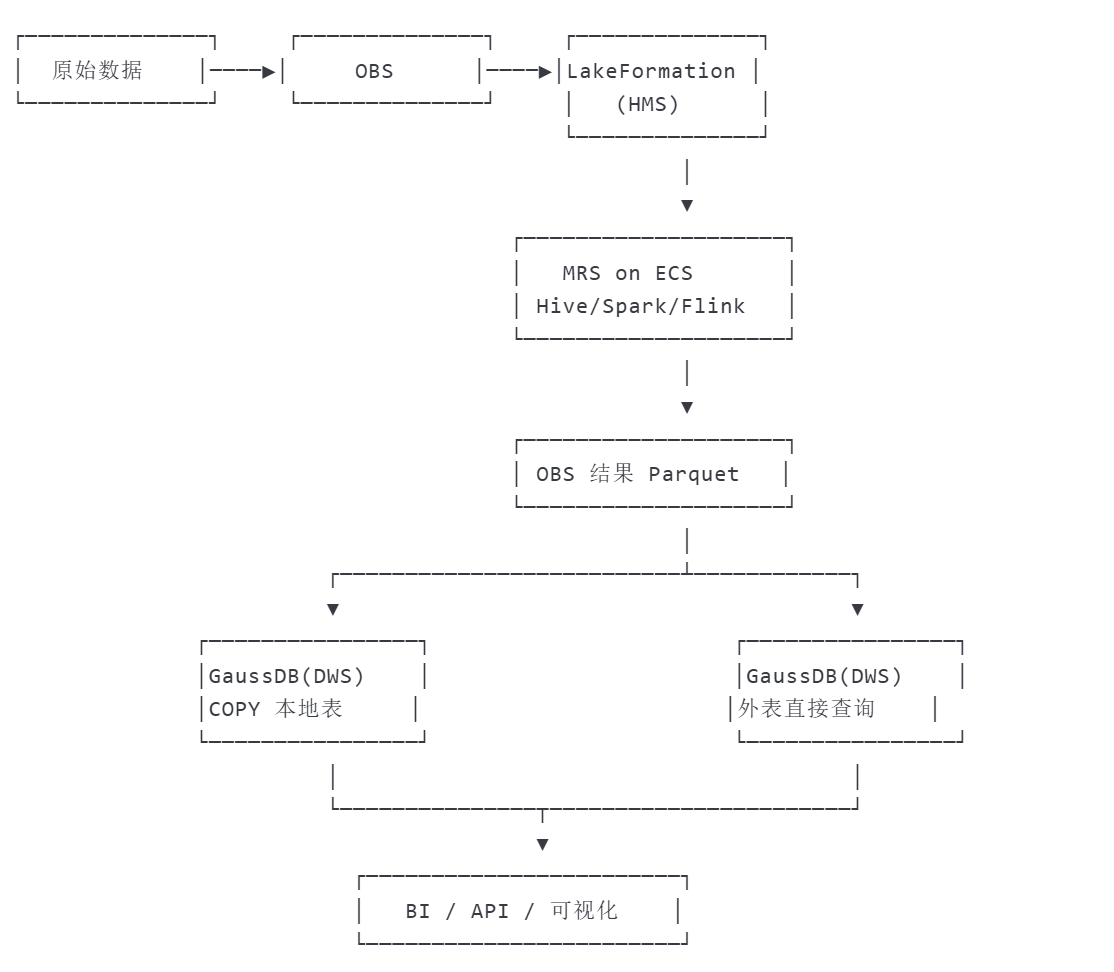
华为云的 OBS + HMS + EMR on ECS + Hive/Spark/Flink + GaussDB 组合,构成了一套完整的国产化大数据处理与分析架构,覆盖数据存储(数据湖)、元数据管理、分布式计算到数据仓库的全流程。这套架构与 AWS 的 “S3+Glue+EMR+Redshift” 逻辑相似,但基于华为云生态实现,尤其适合对国产化、数据安全合规有要求的企业。
核心组件及角色
1. 华为云 OBS(对象存储服务):数据湖底座
定位:对应 AWS S3,是整个架构的 “数据湖”,用于存储全量原始数据。
功能:
支持结构化(CSV、JSON)、半结构化(日志、XML)、非结构化数据(图片、视频)的无限存储,兼容标准 S3 API。
提供多存储类别(标准、低频访问、归档),可根据数据访问频率自动切换,平衡成本与性能。
具备高持久性(99.999999999%)和高可用性,通过多可用区冗余存储保障数据安全。
场景:接收来自业务系统、IoT 设备、日志服务等的原始数据,例如电商的用户行为日志、订单数据、商品图片等,统一存储在obs://my-datalake/raw-data/路径下。
2. 华为云 HMS(Hive Metastore):元数据管理中心
定位:对应 AWS Glue Data Catalog,负责集中管理数据湖的元数据(表结构、存储位置、分区信息等)。
功能:
作为 Hadoop 生态的元数据服务,记录 OBS 中数据的 schema(字段名、类型)、存储路径(如obs://my-datalake/raw-data/logs/)、分区规则(如按日期分区)。
支持与 Hive、Spark 等计算引擎集成,让引擎无需重复解析数据格式,直接通过 HMS 获取元数据,提升处理效率。
可通过数据治理工具(如华为云 DataArts Studio)自动扫描 OBS 数据,生成元数据并同步到 HMS,减少手动维护成本。
场景:当新的用户行为日志上传到 OBS 后,HMS 自动记录日志的字段(如user_id、action、timestamp)和格式(JSON),供后续 Spark 任务直接调用。
3. 华为云 EMR on ECS(弹性 MapReduce):分布式计算引擎
定位:对应 AWS EMR on EC2,基于华为云 ECS(弹性云服务器)构建托管的 Hadoop 集群,提供分布式计算能力。
核心框架(运行在 EMR 上):
Hive:通过类 SQL(HQL)查询 OBS 中的数据,适合离线批处理(如每日销售报表统计)。
Spark:支持批处理、流处理、机器学习(MLlib),内存计算性能优异,适合复杂数据处理(如用户画像构建、推荐算法训练)。
Flink:专注实时流处理,低延迟高吞吐,适合实时监控(如电商大促实时订单监控)。
优势:
全托管模式:无需手动部署 Hadoop/Spark 集群,支持按需创建、弹性扩缩容(根据任务负载增减 ECS 节点)。
深度集成 OBS:直接读取 OBS 中的数据(无需同步到本地 HDFS),避免数据迁移开销。
场景:通过 EMR 的 Spark 集群处理 OBS 中存储的近 1 年用户行为数据,计算用户留存率、复购率等指标,结果写回 OBS 的obs://my-datalake/processed-data/路径。
4. 华为云 GaussDB(数据仓库版):企业级数据仓库
定位:对应 AWS Redshift,是华为自研的分布式数据仓库,专为 PB 级数据的高效分析设计。
功能:
采用 MPP(大规模并行处理)架构和列式存储,支持复杂 SQL 查询和高并发分析,查询性能比传统数据库提升 10 倍以上。
无缝对接 OBS 和 EMR:可通过COPY命令从 OBS 加载 EMR 处理后的结构化数据(如 Parquet 格式),或直接查询 OBS 中的数据(类似 Redshift Spectrum)。
支持与 BI 工具(如华为云 DataArts Insight、Tableau)集成,快速生成可视化报表。
场景:将 EMR 计算后的 “用户复购率”“地区销售额” 等指标数据加载到 GaussDB,业务团队通过 BI 工具查询并生成 “季度销售分析报告”,支撑决策。
完整流程:以电商用户行为分析为例
数据采集与存储(OBS)
电商 APP 的用户点击日志(JSON 格式)、订单数据库备份(CSV 格式)通过 SDK 上传至 OBS,存储路径为obs://ecommerce-raw/logs/和obs://ecommerce-raw/orders/。
元数据管理(HMS)
华为云 DataArts Studio 的爬虫工具扫描 OBS 路径,自动解析日志和订单数据的 schema,将元数据(如orders表包含order_id、user_id、amount字段)写入 HMS,供计算引擎调用。
数据处理(EMR on ECS)
通过 EMR 的 Hive 查询 OBS 中的原始订单数据,过滤无效订单(如金额≤0),结果存为 Parquet 格式到obs://ecommerce-processed/valid-orders/。
启动 EMR 的 Spark 集群,读取 HMS 中的用户行为日志元数据,结合有效订单数据,计算 “用户购买转化率”(点击商品→最终购买的比例),结果写回 OBS。
数据分析(GaussDB)
通过 GaussDB 的COPY命令,将 OBS 中处理后的 “用户转化率” 数据加载到数仓表user_conversion_rate。
业务人员通过 DataArts Insight 连接 GaussDB,查询不同地区、不同商品类别的转化率,生成可视化图表,优化商品推荐策略。
架构优势
全栈国产化:从存储(OBS)、计算(EMR)到数据库(GaussDB)均为华为自研,满足政企客户的数据安全与合规要求。
深度协同:各服务无缝集成(如 EMR 直接读写 OBS、GaussDB 快速加载 OBS 数据),避免数据孤岛。
弹性高效:OBS 无限存储、EMR 按需扩缩容、GaussDB 并行计算,适配从 GB 到 PB 级的业务增长。
(华为云数据处理全流程)

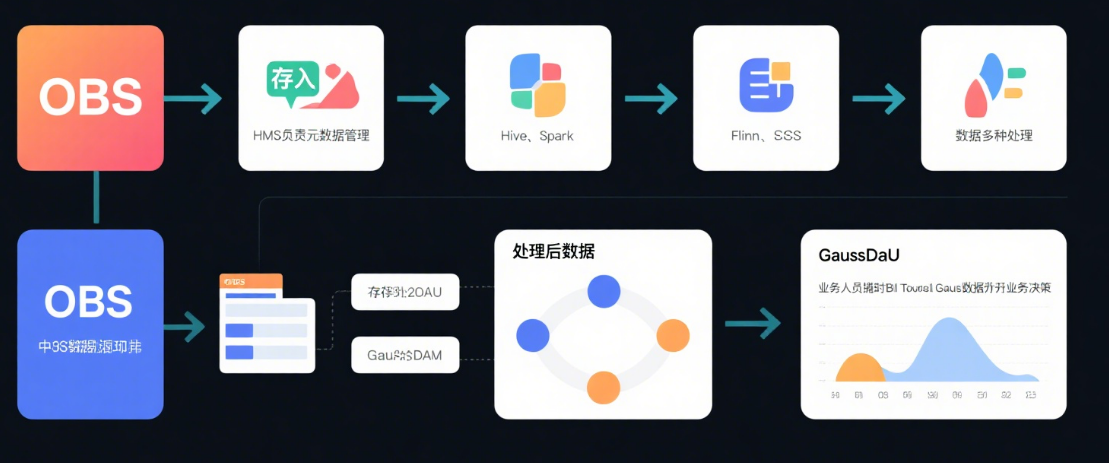
(用户行为数据分析流程)
上篇说到AWS,顺便讲讲区别~
AWS和华为云的区别
AWS和华为云的区别
AWS 适合全球化、轻量级、纯开源场景;华为云适合国内业务、大规模、国产化适配场景
一、核心组件对应关系
| 能力分类 | AWS 组件 | 华为云组件 | 核心作用 |
|---|---|---|---|
| 数据湖存储 | Amazon S3 | 华为云 OBS | 存原始数据、支持无限扩展 |
| 元数据管理 | AWS Glue Data Catalog | 华为云 HMS(或 DataArts Studio) | 管数据 schema、对接计算引擎 |
| 分布式计算集群 | EMR on EC2(Hive/Spark/Flink) | EMR on ECS(Hive/Spark/Flink) | 跑批处理、流计算、机器学习 |
| 数据仓库 | Amazon Redshift | 华为云 GaussDB (DWS) | 复杂分析、BI 报表 |
二、四大核心差异对比
1. 生态适配性(选 AWS 还是华为云?看业务底座)
| 维度 | AWS 优势 | 华为云优势 |
|---|---|---|
| 全球化业务 | 全球节点覆盖,海外业务无需额外适配 | 国内节点深度优化,政企 / 本地化业务合规性更好 |
| 生态兼容性 | 完美对接 AWS 全系服务(如 Redshift+Athena) | 深度整合华为生态(如鸿蒙数据、昇腾 AI 加速) |
| 开源生态 | 原生支持 Hadoop/Spark 社区版,兼容性更广泛 | 对开源框架做了国产化优化(如 Spark 性能增强) |
场景化说明:
- 做跨境电商 → 选 AWS(海外节点多,数据传输快)
- 做政务 / 国企项目 → 选华为云(合规性 + 国产化适配)
2. 成本控制(谁更省钱?看数据规模和使用方式)
| 维度 | AWS 特点 | 华为云特点 |
|---|---|---|
| 存储成本 | 分层存储(S3 Standard→IA→Glacier)细致 | OBS 存储分层更贴合国内用户习惯(低频访问更便宜) |
| 计算成本 | 按需付费灵活,但海外节点流量费用高 | 国内节点流量费用低,长期大集群更划算 |
| 隐性成本 | 海外技术支持响应慢(时差问题) | 国内团队支持,响应速度快(小时级 vs 天级) |
场景化说明:
- 小数据量 + 短期项目 → AWS(按需付费灵活)
- 大数据量 + 长期运营 → 华为云(存储 + 流量成本更低)
3. 技术特性(核心功能谁更强?看业务需求)
| 能力 | AWS 优势场景 | 华为云优势场景 |
|---|---|---|
| 实时计算 | Kinesis+Flink 组合,流处理延迟 <100ms | MRS Flink + 云原生流引擎,国内网络延迟更低 |
| 元数据管理 | Glue Data Catalog 自动发现元数据,无需手动维护 | HMS+DataArts 支持更细粒度的数据血缘追踪 |
| 国产化适配 | 无(纯海外架构) | 支持信创环境(如龙芯、鲲鹏服务器) |
| AI 融合 | SageMaker 无缝对接,机器学习流程更简化 | 深度整合昇腾 AI,训练推理速度更快(国产化芯片) |
场景化说明:
- 做实时风控(如金融) → AWS(Kinesis 生态成熟)
- 做国产化 AI 分析(如政务) → 华为云(昇腾芯片加速)
4. 运维复杂度(谁更省心?看团队能力)
| 维度 | AWS 体验 | 华为云体验 |
|---|---|---|
| 托管服务 | 全托管(Glue/EMR 无需操心集群运维) | 托管深度更高(如自动备份、故障自愈) |
| 监控告警 | CloudWatch 配置灵活,但需手动设置规则 | 自带智能监控(自动识别异常,推送告警) |
| 技术文档 | 英文文档为主,社区案例多 | 中文文档齐全,国内案例更贴近实际业务 |