Spark云原生流处理实战与风控应用
更多推荐阅读
Spark性能调优的道与术:从理论到实践的精髓-CSDN博客
PySpark性能优化与多语言选型讨论-CSDN博客
Spark SQL:用SQL玩转大数据-CSDN博客
Spark初探:揭秘速度优势与生态融合实践-CSDN博客
Spark与Flink深度对比:大数据流批一体框架的技术选型指南_spark流批一体-CSDN博客
目录
一、Kubernetes集成:弹性计算的终极解决方案
1.1 Spark on K8s架构演进
1.2 动态扩缩容实战配置
二、Structured Streaming:端到端Exactly-Once实现
2.1 流处理语义级别对比
2.2 Exactly-Once实现机制
2.3 端到端Exactly-Once实现
三、实战案例:Kafka+Spark实时风控系统
3.1 业务场景与挑战
3.2 系统架构设计
3.3 关键优化策略
四、云原生流处理的未来趋势
结语
在云原生时代,Spark已完成从传统大数据框架到云原生流处理平台的蜕变。本文将深入探讨Spark在Kubernetes环境下的动态扩缩容、Structured Streaming的精确一次处理机制,并通过真实案例解析实时风控系统架构实现。
一、Kubernetes集成:弹性计算的终极解决方案
1.1 Spark on K8s架构演进
Spark 3.0+的Kubernetes原生支持彻底改变了资源管理范式:
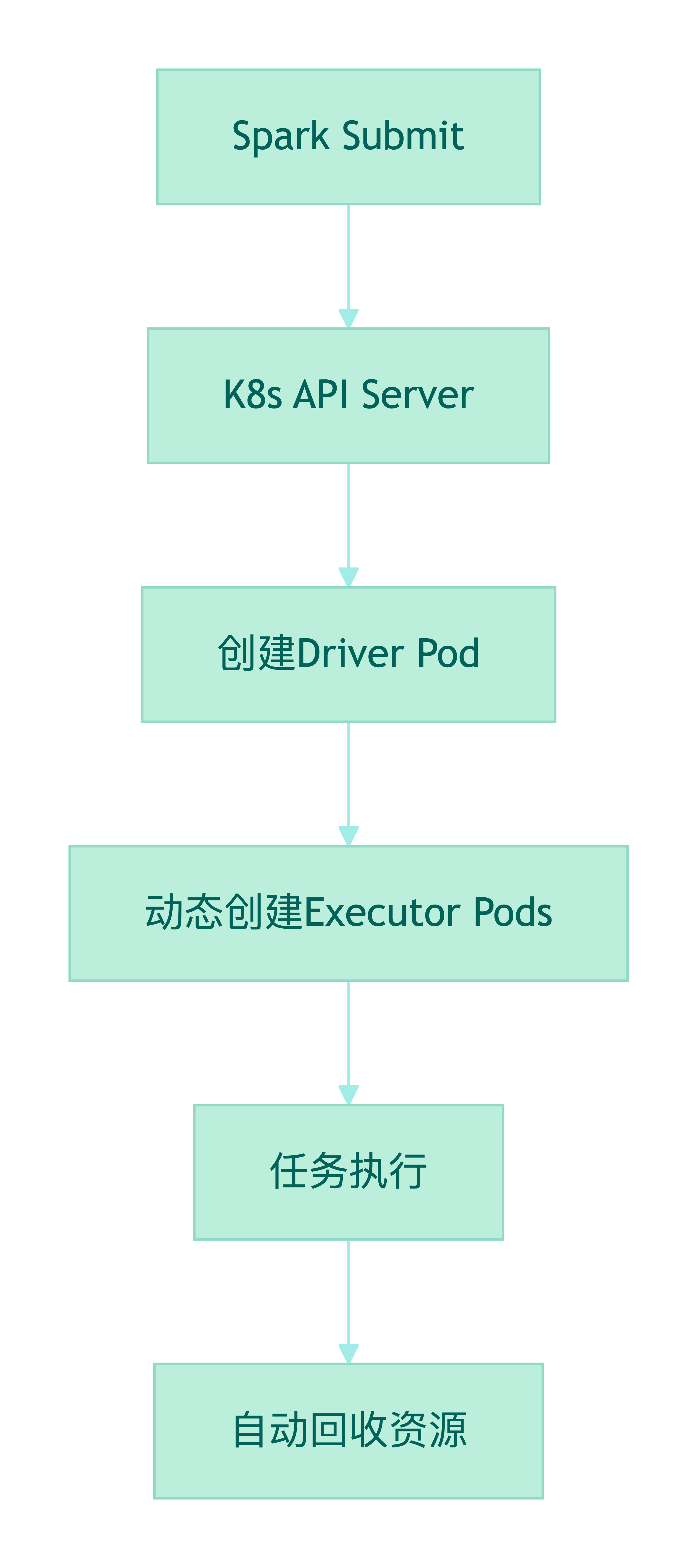
1.2 动态扩缩容实战配置
纵向扩缩容(Vertical Scaling):
# 动态调整Executor资源
spark.executor.instances=5
spark.executor.memory=8G
spark.executor.cores=4
# 启用动态分配
spark.dynamicAllocation.enabled=true
spark.dynamicAllocation.shuffleTracking.enabled=true
横向扩缩容(Horizontal Scaling):
# K8s水平自动伸缩配置
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:name: spark-streaming-hpa
spec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: spark-streamingminReplicas: 3maxReplicas: 20metrics:- type: Resourceresource:name: cputarget:type: UtilizationaverageUtilization: 70扩缩容策略优化:
- 基于背压的扩容:监控processingRate与inputRate比例
- 事件驱动扩缩容:通过Keda对接Kafka Lag指标
- 分级伸缩策略:不同时段设置不同扩缩容阈值
二、Structured Streaming:端到端Exactly-Once实现
2.1 流处理语义级别对比
| 语义级别 | 数据丢失风险 | 数据重复风险 | 典型场景 |
| At-Most-Once | 高 | 低 | 监控数据采集 |
| At-Least-Once | 低 | 高 | 日志处理 |
| Exactly-Once | 无 | 无 | 金融交易 |
2.2 Exactly-Once实现机制
核心技术组合:
1.检查点机制(Checkpointing):
val query = streamingDF.writeStream
.outputMode("update")
.option("checkpointLocation", "/delta/checkpoints/")
.start()- 定期保存偏移量(offset)和状态数据
- 故障恢复时精确回放
2.幂等写入(Idempotent Sinks):
// Delta Lake实现示例
df.writeStream
.format("delta")
.outputMode("append")
.option("txnVersion", monotonically_increasing_id())
.option("txnAppId", query.id)
.start("/delta/events")- 通过事务版本号避免重复写入
3.事务性源(Transactional Sources):
val kafkaDF = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1")
.option("subscribe", "topic1")
.option("isolation.level", "read_committed") // 关键配置
.load()2.3 端到端Exactly-Once实现
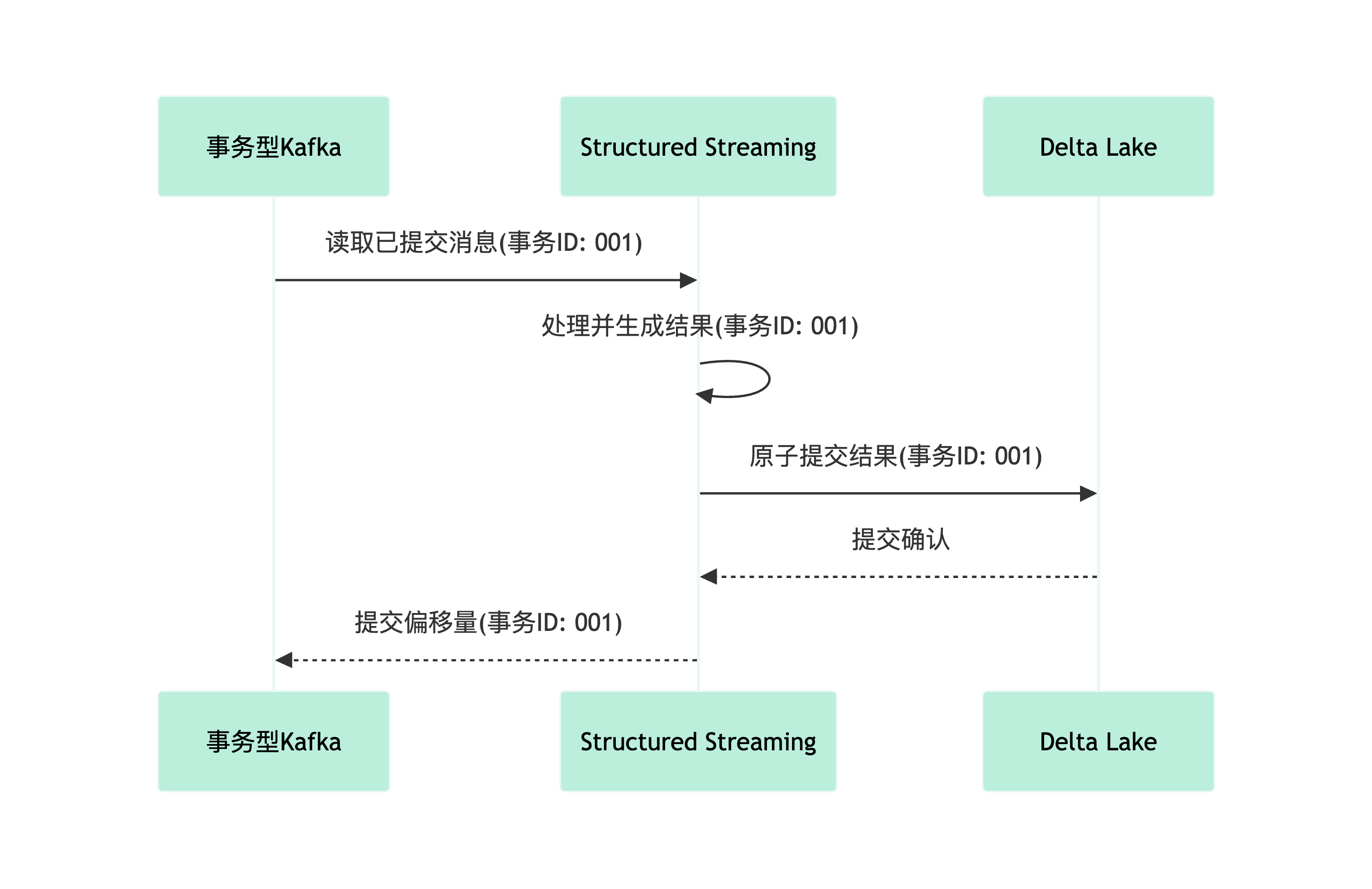
三、实战案例:Kafka+Spark实时风控系统
3.1 业务场景与挑战
电商平台风险场景:
- 信用卡盗刷检测(100ms内响应)
- 羊毛党识别(秒级聚合)
- 异常行为模式识别(复杂CEP规则)
每秒处理需求:
- 输入流量:50,000+ events/s
- 处理延迟:< 500ms(P95)
- 99.99%可用性
3.2 系统架构设计
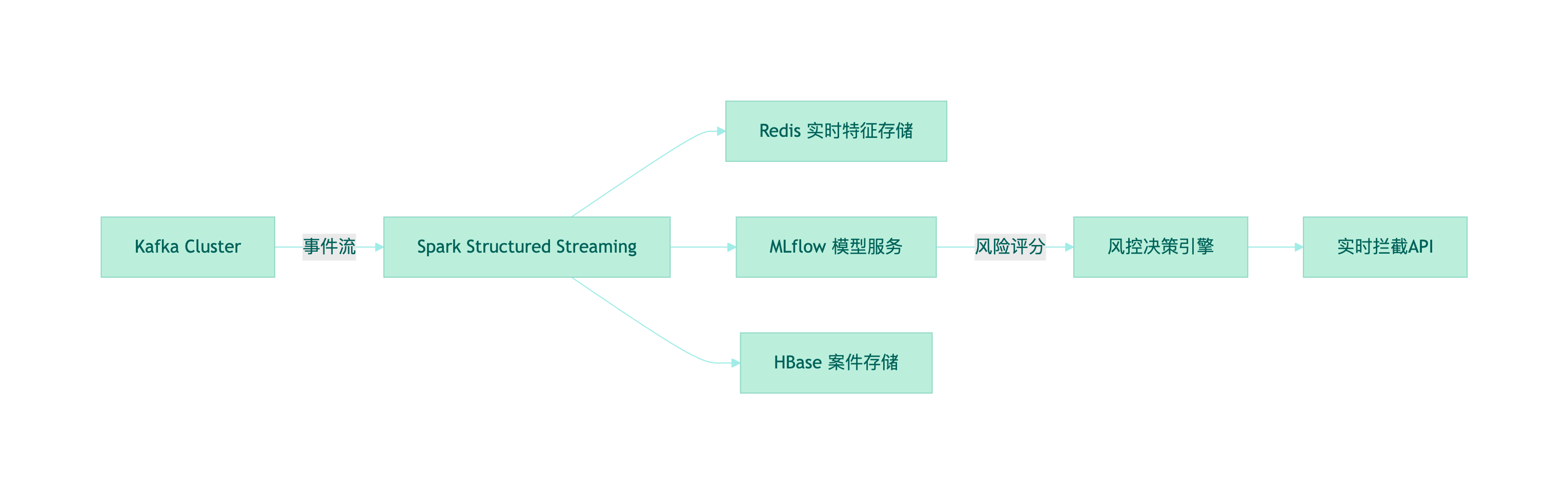
核心组件说明:
1.输入层:
- Kafka分区策略:user_id%100
- 消息压缩:Snappy
- 数据格式:Avro with Schema Registry
2.处理层:
- 窗口聚合(1s滑动窗口)
val aggDF = inputDF
.withWatermark("event_time", "5 seconds")
.groupBy(
window($"event_time", "1 second"),
$"user_id"
).agg(count("*").alias("event_count"))- CEP复杂事件处理(Flink-like Pattern API)
val pattern = Pattern.begin[Event]("start")
.where(_.eventType == "login")
.next("failure").where(_.eventType == "login_fail")
.times(3).within(5.minutes)3.输出层:
- 高风险事件:写入HBase+推送Kafka告警
- 特征数据:实时更新Redis
- 模型特征:同步至Feature Store
3.3 关键优化策略
Kafka调优:
# Spark消费端优化
spark.streaming.kafka.consumer.cache.enabled=false
spark.streaming.kafka.maxRatePerPartition=5000
状态管理优化:
// RocksDB状态存储配置
spark.conf.set("spark.sql.streaming.stateStore.providerClass",
"org.apache.spark.sql.execution.streaming.state.RocksDBStateStoreProvider"
)容错机制:
# 检查点配置
spark.checkpoint.dir=hdfs:///checkpoints
spark.sql.streaming.minBatchesToRetain=100性能指标(生产环境):
- 吞吐量:65,000 events/s
- P99延迟:420ms
- 故障恢复时间:< 30s(10亿级状态恢复)
四、云原生流处理的未来趋势
随着Spark 3.4+版本的演进,以下方向值得关注:
1.无服务器Spark:
- K8s Event-Driven Autoscaling (KEDA)
- 按毫秒级使用量计费
2.统一批流处理:
// 同一API处理批流
val streamingDF = spark.readStream.format("rate").load()
val batchDF = spark.read.format("parquet").load("/data")
val unionDF = streamingDF.union(batchDF)3.AI集成流水线:
- 实时特征工程 → 在线模型推理 → 动态规则更新
- 使用MLflow管理模型生命周期
结语
Spark在云原生和流处理领域的深度演进,使其成为现代数据架构的核心引擎。通过Kubernetes实现资源弹性、利用Structured Streaming保证精确一次处理,并在实时风控等关键场景验证其能力,Spark正重新定义实时计算的边界。随着无服务器架构和AI集成的深入,Spark在云原生时代的价值将愈加凸显。
作者:道一云低代码
作者想说:喜欢本文请点点关注~
更多资料分享