中农具身导航赋能智慧农业!AgriVLN:农业机器人的视觉语言导航

作者:Xiaobei Zhao, Xingqi Lyu, Xiang Li
单位:中国农业大学
论文标题:AgriVLN: Vision-and-Language Navigation for Agricultural Robots
论文链接:https://arxiv.org/pdf/2508.07406v1
代码链接:https://github.com/AlexTraveling/AgriVLN
主要贡献
提出了A2A基准测试,这是一个覆盖6种常见农业场景(农场、温室、森林、山区、花园和村庄)的视觉语言导航(VLN)基准测试,包含1560个episode,所有真实RGB视频都是由四足机器人前端摄像头在0.38米高度拍摄的,与实际部署条件一致。
提出了视觉语言导航农业机器人(AgriVLN)基线方法,基于视觉语言模型(VLM),通过精心设计的模板提示,能够理解给定的指令和农业环境,为机器人控制生成适当的低级动作。
提出了子任务列表(STL)指令分解模块,并将其集成到AgriVLN中,在A2A基准测试上,与基线相比,完整模型将成功率(SR)从0.305提高到0.417,并且进一步与其他现有VLN方法进行比较,证明了其在农业领域视觉语言导航方面的最新性能。
研究背景

农业机器人在农业任务中发挥着重要作用,但目前大多数农业机器人的移动仍然依赖于人工操作或固定的轨道,这限制了它们的机动性和适应性。
视觉语言导航(VLN)能够使机器人根据自然语言指令导航到目标位置,并且在多个领域表现出色,但现有的基准测试和方法都没有专门针对农业场景设计。
现有的VLN基准测试主要集中在室内环境或城市街道等场景,而农业场景具有其独特性,如不同的地形、植被分布和光照条件等,因此需要一个专门针对农业场景的VLN基准测试来评估农业机器人的导航能力。

A2A基准
任务定义
视觉语言导航(VLN)在农业机器人中的任务定义如下:在每个实验场景(episode)中,模型被赋予一条自然语言指令 ,其中 是单词的数量。在每个时间步 ,模型接收前向RGB图像 。模型的目标是理解指令 和图像 ,从而选择最佳的低级动作 (动作空间包括:前进、左转、右转、停止),引导机器人从起点导航到目标位置。
数据集收集
数据收集涵盖了6种不同的农业场景分类:农场、温室、森林、山脉、花园和村庄,这些场景涵盖了所有常见的农业场景。
指令生成:在每个实验场景中,专家重现实际的农业活动,并提取人类移动的轨迹,然后精心设计一条准确的指令来描述该轨迹。与传统VLN基准测试中精致简洁的指令不同,A2A中的指令更加随意且冗长,包含许多无意义和误导性的内容,以更真实地还原农业工人说话的语气。
机器人控制:选择Unitree Go2Air四足机器狗作为实验农业机器人。在每个实验场景中,专家手动控制机器人沿着从起点到终点的最佳路径行走,以完成相应的指令。
视频录制:使用Unitree Go2Air四足机器狗内置的前向RGB摄像头作为视频录制设备。在每个实验场景中,专家手动控制摄像头记录整个时间线的前向视图。每个视频流以1280×720的分辨率、约14FPS的帧率和约1100kbps的码率进行捕获。
数据标注:对于每个时间步 ,专家根据机器人的实际行走状态手动标注机器人的真值动作。将相邻相同的动作序列 ({a_{t1}, a_{t1+1}, \dots, a_{t2}}) 聚合成一个时间间隔,并以字典格式保存。每个实验场景由多个这样的时间间隔组成,以JSON格式存储。
数据集评估
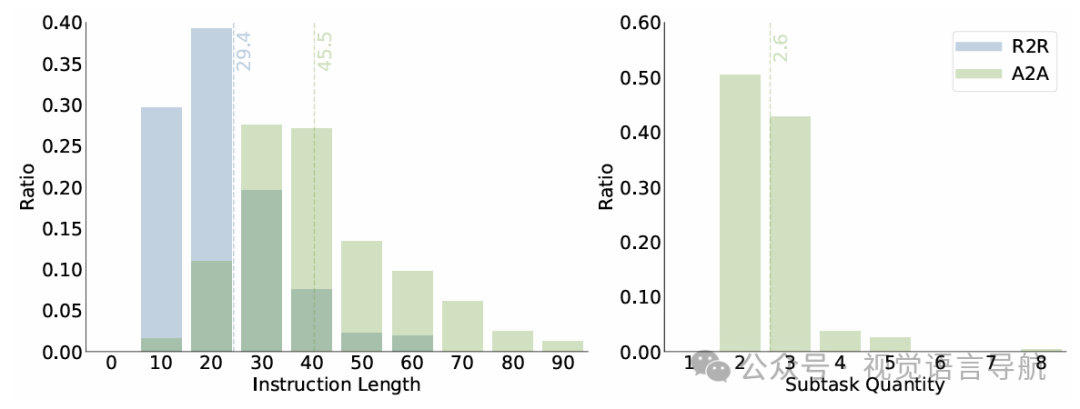
数据规模与分布:A2A基准测试共收集了1560个实验场景,分布在6种不同的场景分类中,包括农场372个、温室258个、森林384个、山脉198个、花园258个和村庄90个。指令长度从10到99不等,平均长度为45.5,子任务数量从2到8不等,平均为2.6。

词汇分布:A2A中的指令词汇包含893个单词,其中“front”、“camera”和“view”是常用的名词,而“go”、“stop”和“need”是常用的动词。这些词汇都是日常生活中常见的,证明了A2A指令与农业工人对话的语气一致性。
与其他基准测试的比较:A2A在多个方面与其他主流VLN基准测试进行了比较,包括场景多样性、图像质量和数据规模。A2A涵盖了所有常见的农业场景,图像采集条件与实际农业机器人一致,并且提供了更长的指令以更好地评估模型对长文本的理解能力。
评估指标
成功率(SR):成功完成任务的实验场景比例。
导航误差(NE):机器人最终位置与目标位置之间的距离。
独立成功率(ISR):每个子任务的成功率,计算公式为:其中 和 分别是实验场景 中成功的子任务数量和总子任务数量, 是评估实验场景的集合。
方法
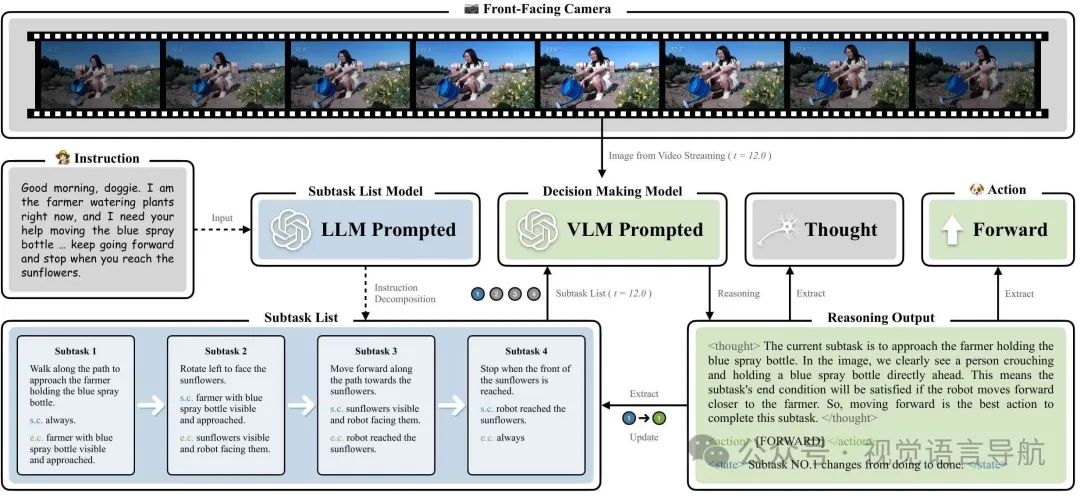
子任务列表
子任务列表模块将指令分解为一系列子任务,使模型能够逐步完成复杂的导航任务。具体步骤如下:
指令分解:将指令 分解为子任务列表 ,每个子任务 包含四个参数:步骤顺序(ID)、具体描述(D)、开始条件(SC)、结束条件(EC)和当前状态(σ)。
大型语言模型(LLM):使用LLM 实现指令分解,公式为:其中 是LLM的提示,遵循以下三个原则:
颗粒原则:任何子任务都不能进一步分解为更细的子任务。
同义词原则:子任务列表传达的语义必须与原始指令等价,确保不遗漏或添加任何信息。
连接原则:下一个子任务的开始条件必须与上一个子任务的结束条件对齐。
决策制定
决策制定模块使用视觉语言模型(VLM) 来实现,具体步骤如下:
输入与输出:在每个时间步 ,VLM接收当前摄像头视图 和子任务列表 ,并输出最佳低级动作 、状态转换 和推理过程 :其中 是VLM的提示。
状态转换机制:子任务的状态分为三种:待处理(pending)、进行中(doing)和已完成(done)。状态转换遵循以下原则:
待处理 → 进行中:当且仅当上一个子任务已完成,并且VLM认为当前子任务应该开始。
进行中 → 已完成:当且仅当当前子任务处于进行中状态,并且VLM认为当前子任务已完成。
注意力聚焦:在每个时间步 ,VLM只需要关注一个子任务,具体如下:
如果存在一个子任务 的状态为进行中,则VLM关注该子任务。
如果没有子任务的状态为进行中,则VLM关注第一个待处理的子任务 。
实验
实验设置
为了确保实时处理能力,论文选择了轻量级的 GPT-4.1mini 作为指令分解的大型语言模型(LLM)和决策模型的视觉语言模型(VLM),并通过API访问。这种选择是为了确保模型在实际农业机器人上的实时性和高效性。
定性实验
为了帮助读者更好地理解AgriVLN方法,论文通过一个具体的实验场景进行了定性实验。实验中,AgriVLN将指令分解为子任务列表,然后按顺序完成每个子任务,从而实现整个指令的导航任务。具体步骤如下:
指令分解:将复杂的指令分解为多个子任务,每个子任务都有明确的开始和结束条件。
逐步执行:模型依次执行每个子任务,直到完成所有子任务,从而实现从起点到目标位置的导航。

上图展示了定性实验的一个代表性场景,其中AgriVLN成功地将指令分解为子任务,并按顺序完成每个子任务。论文还提供了五个更多的例子,以展示AgriVLN在不同场景下的表现。
比较实验
论文将AgriVLN与多种基线方法和最新方法进行了比较,以验证其性能。具体设置如下:
基线方法:
Random:随机选择动作。
GPT-4.1mini with prompt:仅使用GPT-4.1mini进行决策,不使用子任务列表。
Human:人类专家的性能,作为参考标准。
最新方法:
SIA-VLN(Hong et al. 2020):基于规则的指令分解方法。
DILLM-VLN(Wang et al. 2025a):基于LLM的指令分解方法。
结果分析
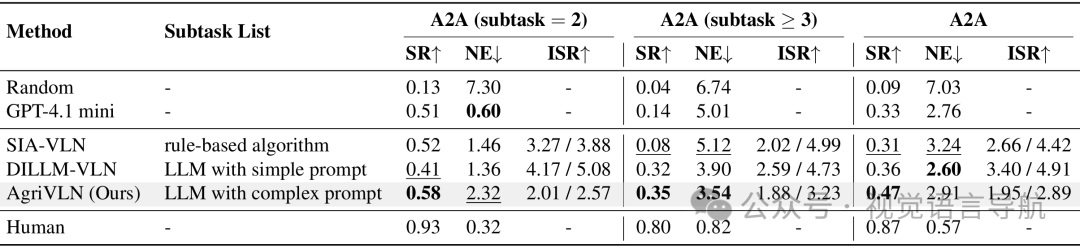
Random:随机方法的性能极差,证明了基准测试的有效性和公平性。
Human:人类专家的性能接近完美,证明了基准测试的合理性。
GPT-4.1mini with prompt:仅使用GPT-4.1mini进行决策时,成功率(SR)为0.33,导航误差(NE)为2.76。
SIA-VLN:在简单指令(子任务数量为2)时表现良好,但在复杂指令(子任务数量≥3)时性能下降。
DILLM-VLN:在简单指令时表现良好,但在复杂指令时性能保持稳定,证明了LLM在指令分解中的有效性。
AgriVLN:在所有实验场景中,AgriVLN的SR为0.47,NE为2.91,综合性能超过了所有现有方法,尽管与人类表现仍有差距,但已展现出在农业领域视觉语言导航中的最佳性能。
消融实验
不同视觉语言模型的影响
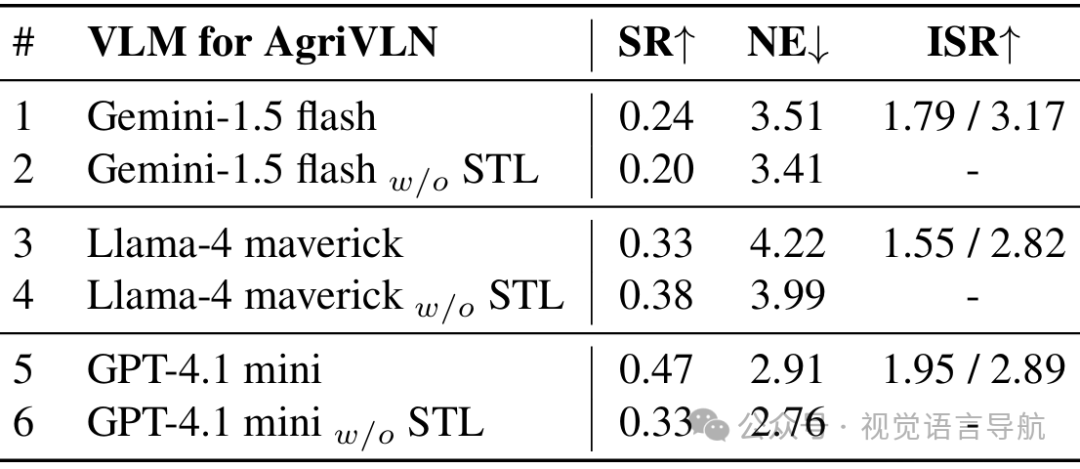
论文测试了三种轻量级VLM:Gemini-1.5 flash、Llama-4 maverick 和 GPT-4.1mini。结果表明,GPT-4.1mini在成功率(SR)和导航误差(NE)上均优于其他两种VLM,因此被选为AgriVLN的VLM。
子任务列表模块的影响
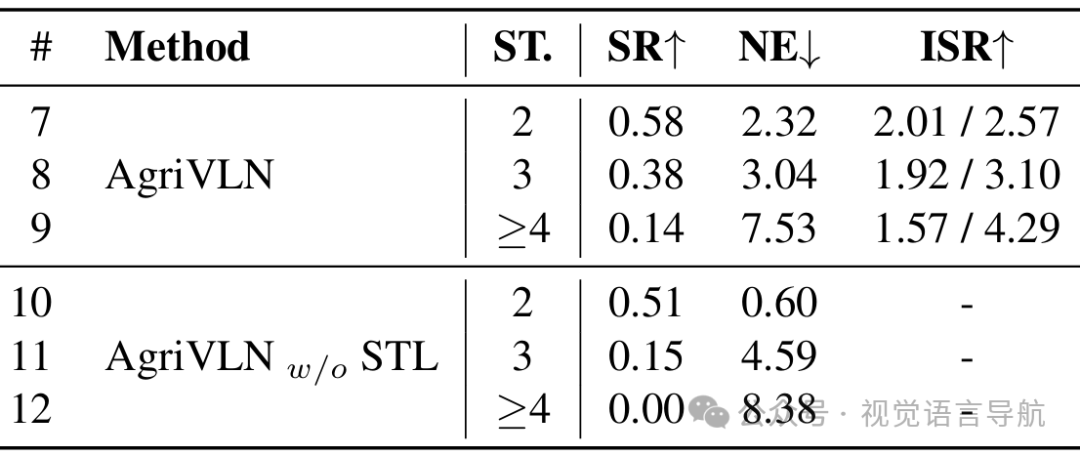
论文通过消融实验验证了子任务列表(STL)模块的重要性。实验结果表明,当子任务数量增加时,STL模块对性能的提升作用愈发明显。
不同场景分类下的性能
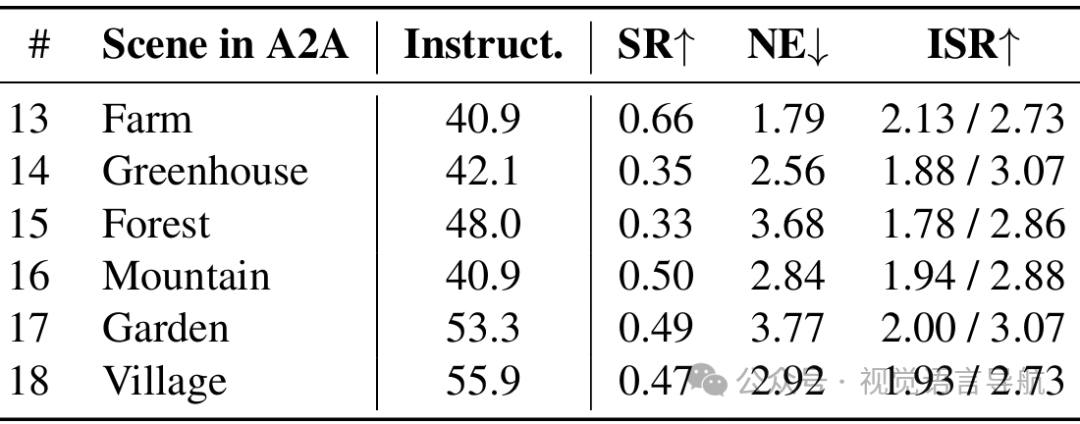
论文还统计了AgriVLN在A2A不同场景分类下的性能,发现尽管不同场景的指令平均长度相对一致,但AgriVLN在不同场景下的表现存在显著差异。这可能是由于场景分类之间的细微差异(如背景杂乱、障碍物密度和光照条件)对模型的视觉感知能力提出了不同程度的挑战。
结论与未来工作
结论:
该论文提出了A2A基准测试和AgriVLN方法,通过引入子任务列表(STL)模块,有效地提高了农业机器人在视觉语言导航任务中的性能,特别是在处理长指令时。
然而,AgriVLN仍然存在一些不足之处,如对模糊指令的理解不准确和对空间距离的识别不准确。
未来工作:
未来的工作将致力于改进这些缺点,并进一步探索在实际农业场景中部署该方法,以提高农业机器人的自主性和适应性。
